
ホームページ >Java >&#&チュートリアル >Javaでブルームフィルターを適用する方法
Javaでブルームフィルターを適用する方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-10 21:49:041394ブラウズ
ブルーム フィルターとは
ブルーム フィルターは、非常にスペース効率の高いランダム データ構造であり、ビット配列 (BitSet) を使用してセットを表し、一定数のハッシュ関数マップ要素を渡します。ビット配列内の位置に移動し、要素がこのセットに属しているかどうかを確認するために使用されます。
実装の中心的なアイデア
要素に対して、複数のハッシュ関数を通じて複数のハッシュ値が生成され、ビット配列内の対応するビットが 1 に設定されます。複数のハッシュ 値の対応するビットがすべて 1 の場合、その要素はセット内にある可能性があると見なされますが、ハッシュ値の少なくとも 1 つの対応するビットが 0 の場合、その要素はセット内に確実に存在しません。この方法では、より狭いスペースで効率的な検索を実現できますが、誤検知率が高くなる可能性があります。
理解方法
典型的なブルーム フィルターには、ビット配列のサイズ (つまり、格納されている要素の数)、ハッシュ関数の数、フィル ファクター (つまり、False) の 3 つのパラメーターが含まれています。正の比率)、つまりビット配列のサイズに対する要素の数の比率。
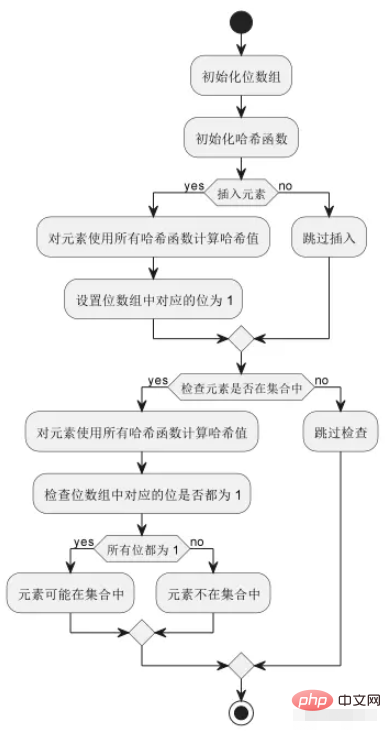
上図に示すように、ブルーム フィルターの基本的な演算プロセスには、ビット配列とハッシュ関数の初期化、要素の挿入、要素がセット内にあるかどうかの確認が含まれます。 、など。このうち、各要素は複数のハッシュ関数によってビット配列内の複数の位置にマッピングされます。要素がセット内にあるかどうかを確認する場合、要素が可能であるとみなされる前に、対応するすべてのビットが 1 に設定されていることを確認する必要があります。セット内、コレクション内にあります。
典型的なアプリケーション シナリオ
スパム フィルタリング: ブルーム フィルタ内のすべてのブラックリスト電子メールのハッシュ値の対応する位置を 1 に設定します。新しい電子メールごとに、チェックを入れます。ブルーム フィルタ内の対応する位置のハッシュ値が 1 であるかどうか。そうであれば、電子メールはスパムであると見なされ、そうでない場合は通常の電子メールである可能性があります。
# #URL deduplication: Setブルーム フィルタ内のクロールされた URL のハッシュ値の対応する位置を 1 にします。新しい URL ごとに、ブルーム フィルタ内のハッシュ値を設定します。対応する位置がすべて 1 かどうかを確認します。そうであれば、URL はクロールされている、そうでない場合はクロールする必要がある;
キャッシュの内訳: キャッシュ内に存在するすべてのデータに対応 ブルーム フィルター内のハッシュ値の対応する位置は 1 に設定されます。各クエリ キー値について、ブルーム フィルタ内の対応する位置のハッシュ値がすべて 1 であるかどうかを確認します。そうであれば、キー値がキャッシュに存在するとみなされます。それ以外の場合は、データベースからクエリを実行してキャッシュに追加する必要があります。 。
ブルーム フィルターの誤検知率はビット配列サイズが増加するにつれて減少しますが、メモリ オーバーヘッドと計算時間も増加することに注意してください。ブルーム フィルターの理解を容易にするために、以下では Java コードを使用して単純なブルーム フィルターを実装しています:import java.util.BitSet;
import java.util.Random;
public class BloomFilter {
private BitSet bitSet; // 位集,用于存储哈希值
private int bitSetSize; // 位集大小
private int numHashFunctions; // 哈希函数数量
private Random random; // 随机数生成器
// 构造函数,根据期望元素数量和错误率计算位集大小和哈希函数数量
public BloomFilter(int expectedNumItems, double falsePositiveRate) {
this.bitSetSize = optimalBitSetSize(expectedNumItems, falsePositiveRate);
this.numHashFunctions = optimalNumHashFunctions(expectedNumItems, bitSetSize);
this.bitSet = new BitSet(bitSetSize);
this.random = new Random();
}
// 根据期望元素数量和错误率计算最佳位集大小
private int optimalBitSetSize(int expectedNumItems, double falsePositiveRate) {
int bitSetSize = (int) Math.ceil(expectedNumItems * (-Math.log(falsePositiveRate) / Math.pow(Math.log(2), 2)));
return bitSetSize;
}
// 根据期望元素数量和位集大小计算最佳哈希函数数量
private int optimalNumHashFunctions(int expectedNumItems, int bitSetSize) {
int numHashFunctions = (int) Math.ceil((bitSetSize / expectedNumItems) * Math.log(2));
return numHashFunctions;
}
// 添加元素到布隆过滤器中
public void add(String item) {
// 计算哈希值
int[] hashes = createHashes(item.getBytes(), numHashFunctions);
// 将哈希值对应的位设置为 true
for (int hash : hashes) {
bitSet.set(Math.abs(hash % bitSetSize), true);
}
}
// 检查元素是否存在于布隆过滤器中
public boolean contains(String item) {
// 计算哈希值
int[] hashes = createHashes(item.getBytes(), numHashFunctions);
// 检查哈希值对应的位是否都为 true
for (int hash : hashes) {
if (!bitSet.get(Math.abs(hash % bitSetSize))) {
return false;
}
}
return true;
}
// 计算给定数据的哈希值
private int[] createHashes(byte[] data, int numHashes) {
int[] hashes = new int[numHashes];
int hash2 = Math.abs(random.nextInt());
int hash3 = Math.abs(random.nextInt());
for (int i = 0; i < numHashes; i++) {
// 使用两个随机哈希函数计算哈希值
hashes[i] = Math.abs((hash2 * i) + (hash3 * i) + i) % data.length;
}
return hashes;
}
}以上がJavaでブルームフィルターを適用する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。