
ホームページ >Java >&#&チュートリアル >Java でのブロックキューの例を分析する
Java でのブロックキューの例を分析する

- PHPz転載
- 2023-05-09 21:43:061420ブラウズ
1. ブロッキング キューとは
ブロッキング キューは特別なキューであり、データ構造内の通常のキューと同様に先入れ法に従います。同時に、ブロッキング キューはスレッドの安全性を確保できるデータ構造であり、次の 2 つの特徴があります。キューがいっぱいの場合、キューに要素を挿入し続けると、他のスレッドが実行されるまでキューがブロックされます。キューから要素を取得します。要素を削除します。キューが空の場合、デキューを続行すると、他のスレッドが要素をキューに挿入するまでキューがブロックされます。
補足: スレッドのブロックとは、コードが実行されないことを意味しますつまり、オペレーティング システムは、この時点でこのスレッドを CPU に実行するようスケジュールしません
2。ブロッキング キュー コードを使用します
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.BlockingDeque;
public class Test {
public static void main(String[] args) throws InterruptedException {
//不能直接newBlockingDeque,因为它是一个接口,要向上转型
//LinkedBlockingDeque内部是基于链表方式来实现的
BlockingDeque<String> queue=new LinkedBlockingDeque<>(10);//此处可以指定一个具体的数字,这里的的10代表队列的最大容量
queue.put("hello");
String elem=queue.take();
System.out.println(elem);
elem=queue.take();
System.out.println(elem);
}
}注: put メソッドには、ブロッキング機能はありますが、オファーはそうではないため、一般的には put メソッドが使用されます (オファーメソッドが使用できる理由は、BlockingDeque が Queue を継承しているためです)

結果を出力します。 上に示したように、hello が出力された後、キューは空になり、コードは elem=queue.take(); まで実行されません。 . この時点で、スレッドはブロッキング待機状態に入り、何も起こりません。他のスレッドが新しい要素をキューに入れるまで印刷されません
3. プロデューサー/コンシューマー モデル
プロデューサー / コンシューマー モデルは、サーバー開発およびバックエンド開発で開発されます。これは比較的一般的なプログラミング手法であり、通常、デカップリング、ピークシェービング、バレーフィリングに使用されます。
高結合: 2 つのコード モジュール間の関係が比較的高い
高凝集性: コード モジュール内の要素が互いに密接に結合している
したがって、一般に、高い凝集性と低い結合性を追求します。これにより、実行効率が向上し、生産者消費者モデルを使用して分離することができます
(1) アプリケーション 1: 分離
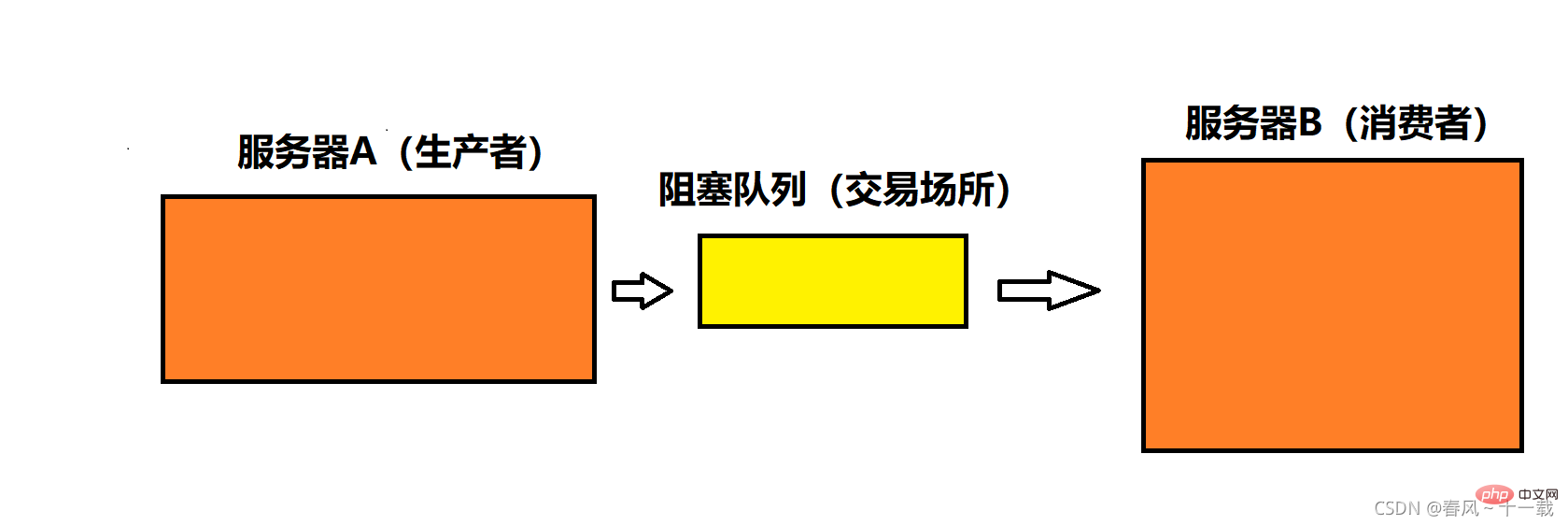
実際の状況を例として考えてみましょう。 2 つのサーバーがあります: A サーバーと B サーバーです。A サーバーが B にデータを送信するとき、それが直接送信される場合は、A がデータを B にプッシュするか、B が A からデータをプルします。どちらも A と B が直接対話する必要があります。つまり、AとBの間には依存関係があります(AとBの結合度は比較的高い)。 A が C にデータを送信できるようにするために C サーバーを追加するなど、将来サーバーを拡張する必要がある場合、変更はさらに複雑になり、効率が低下します。このとき、ブロッキングキューであるキューを追加することができます。A がキューにデータを書き込み、B がそこからデータを取得すると、キューは転送ステーション (または取引所) に相当し、A はプロデューサー (データの提供)、B はコンシューマー (データの受信) に相当します。この時点で、プロデューサーとコンシューマーのモデルが形成され、コードの結合が少なくなり、保守が容易になり、実行がより効率的になります。

ダムは川の非常に重要な部分です。ダムがない場合結果を想像してみましょう: 洪水期が来ると、上流域に大量の水が流れ込み、下流域に大量の水が流れ込み、洪水が発生し、農作物が浸水します。一方、乾期には、下流域では水が非常に少なくなり、干ばつが発生する可能性があります。ダムがある場合、出水期には余分な水をダムに貯め、ゲートを閉めて水を貯め、上流の水を一定の速度で下流に流すことで、突然の大雨による洪水を防ぎます。下流が氾濫しないように下流に流してください。干ばつ時にはダムが貯めていた水を放出し、下流での水不足を防ぐために一定の流量で水を下流に流すことで、出水期の洪水と乾期の干ばつの両方を回避することができます。
ピーク: 洪水期に相当
谷: 乾期に相当
コンピュータの場合
この状況は、コンピュータ、特にサーバー開発においても非常に一般的であり、通常、リクエストはゲートウェイに転送されます。ビジネス サーバー (一部の製品サーバー、ユーザー サーバー、販売者サーバー (販売者情報を保存)、およびライブ ブロードキャスト サーバーなど)。しかし、インターネットからのリクエストの数は制御できないため、上流に相当し、突然大きなリクエストの波が押し寄せると、たとえゲートウェイが対応できたとしても、多くのリクエストを受信した後、後続の多くのサーバーがダウンしてしまいます(1つのリクエストを処理する)。データベース関連の操作は効率が比較的低いため、リクエストには一連のデータベース操作が含まれます。リクエストが多すぎると処理できず、クラッシュします)
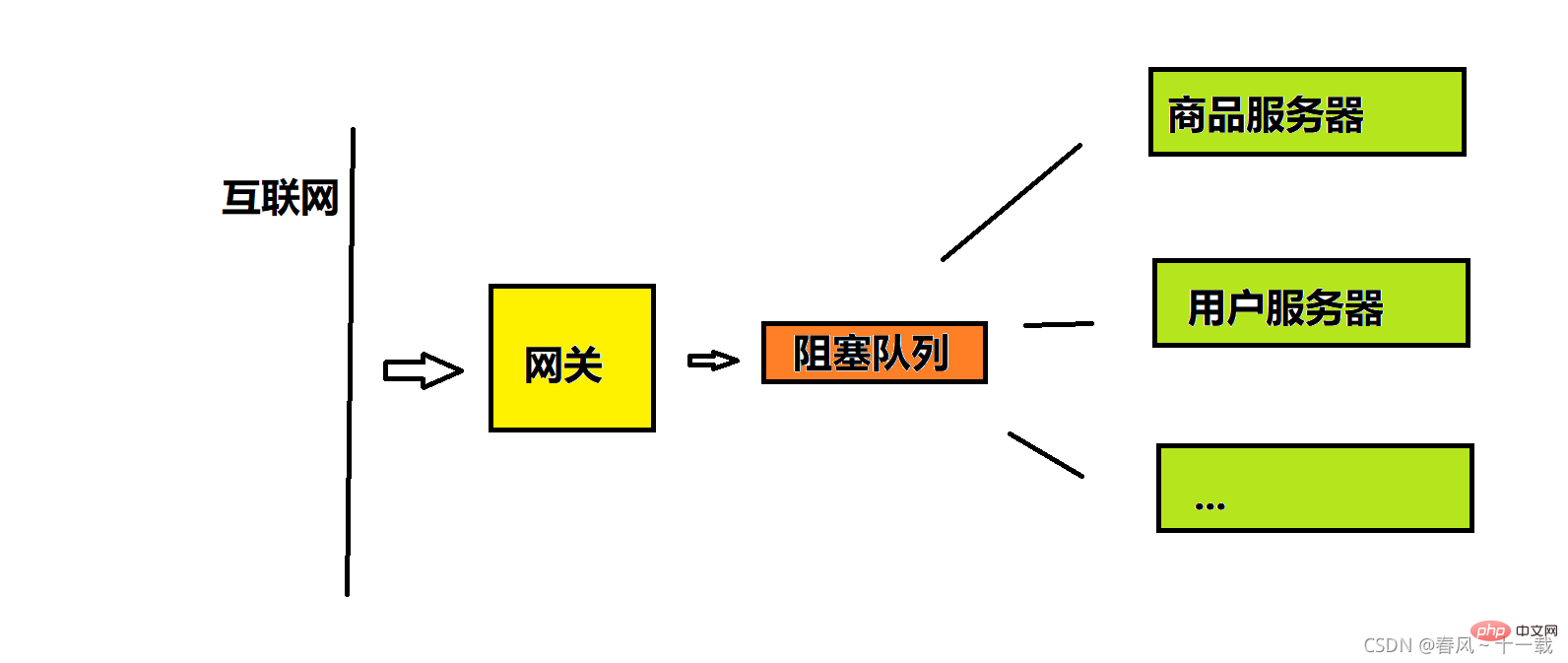
所以实际情况中网关和业务服务器之间往往用一个队列来缓冲,这个队列就是阻塞队列(交易场所),用这个队列来实现生产者(网关)消费者(业务服务器)模型,把请求缓存到队列中,后面的消费者(业务服务器)按照自己固定的速率去读请求。这样当请求很多时,虽然队列服务器可能会稍微受到一定压力,但能保证业务服务器的安全。
(3)相关代码
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class TestDemo {
public static void main(String[] args) {
// 使用一个 BlockingQueue 作为交易场所
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>();
// 此线程作为消费者
Thread customer = new Thread() {
@Override
public void run() {
while (true) {
// 取队首元素
try {
Integer value = queue.take();
System.out.println("消费元素: " + value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
customer.start();
// 此线程作为生产者
Thread producer = new Thread() {
@Override
public void run() {
for (int i = 1; i <= 10000; i++) {
System.out.println("生产了元素: " + i);
try {
queue.put(i);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
producer.start();
try {
customer.join();
producer.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}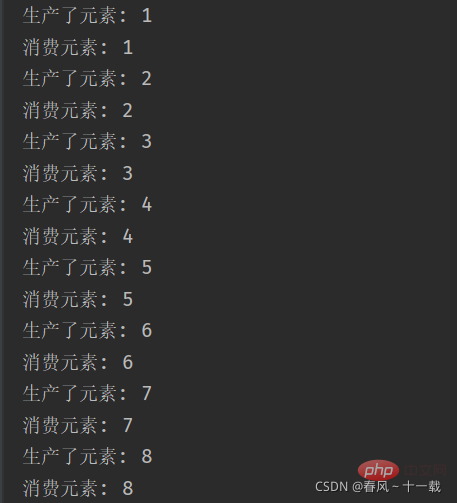
打印如上(此代码是让生产者通过sleep每过1秒生产一个元素,而消费者不使用sleep,所以每当生产一个元素时,消费者都会立马消费一个元素)
4.阻塞队列和生产者消费者模型功能的实现
在学会如何使用BlockingQueue后,那么如何自己去实现一个呢?
主要思路:
1.利用数组
2.head代表队头,tail代表队尾
3.head和tail重合后到底是空的还是满的判断方法:专门定义一个size记录当前队列元素个数,入队列时size加1出队列时size减1,当size为0表示空,为数组最大长度就是满的(也可以浪费一个数组空间用head和tail重合表示空,用tail+1和head重合表示满,但此方法较为麻烦,上一个方法较为直观,因此我们使用上一个方法)
public class Test2 {
static class BlockingQueue {
private int[] items = new int[1000]; // 此处的1000相当于队列的最大容量, 此处暂时不考虑扩容的问题.
private int head = 0;//定义队头
private int tail = 0;//定义队尾
private int size = 0;//数组大小
private Object locker = new Object();
// put 用来入队列
public void put(int item) throws InterruptedException {
synchronized (locker) {
while (size == items.length) {
// 队列已经满了,阻塞队列开始阻塞
locker.wait();
}
items[tail] = item;
tail++;
// 如果到达末尾, 就回到起始位置.
if (tail >= items.length) {
tail = 0;
}
size++;
locker.notify();
}
}
// take 用来出队列
public int take() throws InterruptedException {
int ret = 0;
synchronized (locker) {
while (size == 0) {
// 对于阻塞队列来说, 如果队列为空, 再尝试取元素, 就要阻塞
locker.wait();
}
ret = items[head];
head++;
if (head >= items.length) {
head = 0;
}
size--;
// 此处的notify 用来唤醒 put 中的 wait
locker.notify();
}
return ret;
}
}
public static void main(String[] args) throws InterruptedException {
BlockingQueue queue = new BlockingQueue();
// 消费者线程
Thread consumer = new Thread() {
@Override
public void run() {
while (true) {
try {
int elem = queue.take();
System.out.println("消费元素: " + elem);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
consumer.start();
// 生产者线程
Thread producer = new Thread() {
@Override
public void run() {
for (int i = 1; i < 10000; i++) {
System.out.println("生产元素: " + i);
try {
queue.put(i);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
producer.start();
consumer.join();
producer.join();
}
}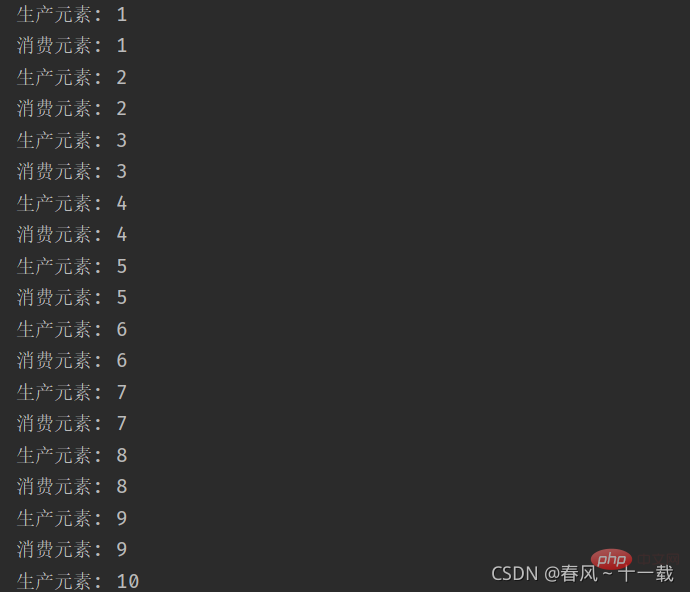
运行结果如上。
注意:
1.wait和notify的正确使用
2.put和take都会产生阻塞情况,但阻塞条件是对立的,wait不会同时触发(put唤醒take阻塞,take唤醒put阻塞)
以上がJava でのブロックキューの例を分析するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。