
ホームページ >テクノロジー周辺機器 >AI >Googleはゴミの分別を支援する強化学習を使用して23台のロボットを構築するのに2年かかった
Googleはゴミの分別を支援する強化学習を使用して23台のロボットを構築するのに2年かかった

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-09 15:01:091100ブラウズ
強化学習 (RL) を使用すると、ロボットが試行錯誤を通じて対話し、複雑な動作を学習し、時間の経過とともにより優れたものになることができます。 Google のこれまでの研究では、RL によってロボットが物をつかむ、マルチタスクの学習、さらには卓球をするなどの複雑なスキルを習得できるようにする方法が検討されてきました。ロボットの強化学習は大きく進歩しましたが、強化学習を備えたロボットを日常の環境で目にすることはまだありません。現実の世界は複雑かつ多様で、時間の経過とともに常に変化しているため、ロボット システムにとって大きな課題となります。しかし、強化学習はこれらの課題に対処するための優れたツールであるはずです。実際に仕事で練習、改善、学習することで、ロボットは絶えず変化する世界に適応できるはずです。
Google の論文「Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators」では、研究者が最新の大規模実験を通じてこの問題を解決する方法を模索しています。彼らは 2 年間にわたって 23 台の RL 対応ロボットを導入し、Google のオフィスビルでゴミの分別とリサイクルを行いました。使用されるロボット システムは、実世界のデータからのスケーラブルな深層強化学習と、シミュレーション トレーニングからのガイド付きおよび補助的なオブジェクト認識入力を組み合わせて、エンドツーエンドのトレーニングの利点を維持しながら一般化を向上させます。

論文アドレス: https://rl-at-scale.github.io/assets/rl_at_scale .pdf
##問題設定#人々が廃棄物を適切に分別しないと、リサイクル可能なバッチが汚染され、堆肥が不適切に埋め立て地に廃棄される可能性があります。 Googleの実験では、ロボットがオフィスビルの周りを歩き回り、「ゴミ箱」(リサイクル箱、堆肥箱、その他のゴミ箱)を探した。ロボットのタスクは、各ゴミステーションに到着して廃棄物を分別し、すべてのリサイクル可能なアイテム (缶、ボトル) をリサイクル可能なビンに、すべての堆肥化可能なアイテム (段ボール容器、紙コップ) を堆肥ビンに入れるために、アイテムを異なるビン間で輸送することです。他のすべては他のビンにあります。
実際、この作業は思ったほど簡単ではありません。人々がゴミ箱に捨てたさまざまなアイテムを拾うというサブタスクだけでも、すでに大きな課題です。また、ロボットは各オブジェクトに適切なビンを識別し、できるだけ迅速かつ効率的にそれらを分類する必要があります。現実の世界では、ロボットは次のような実際のオフィスビルの例など、さまざまなユニークな状況に遭遇します。
さまざまな経験から学ぶ職場での継続的な学習が役立ちます。 , しかし、その点に到達する前に、基本的なスキルのセットでロボットをガイドする必要があります。この目的を達成するために、Google は 4 つの経験のソースを使用します: (1) 成功率は低いが、初期の経験を提供するのに役立つ単純な手作業で設計された戦略、(2) シミュレーションから現実への移行を使用して、ある程度の経験を提供するシミュレーション トレーニング フレームワーク(3) ロボットが代表的なゴミステーションを使用して継続的に練習する「ロボット教室」、(4) 実際の導入環境、実際のゴミのあるオフィスビルでロボットが練習する。
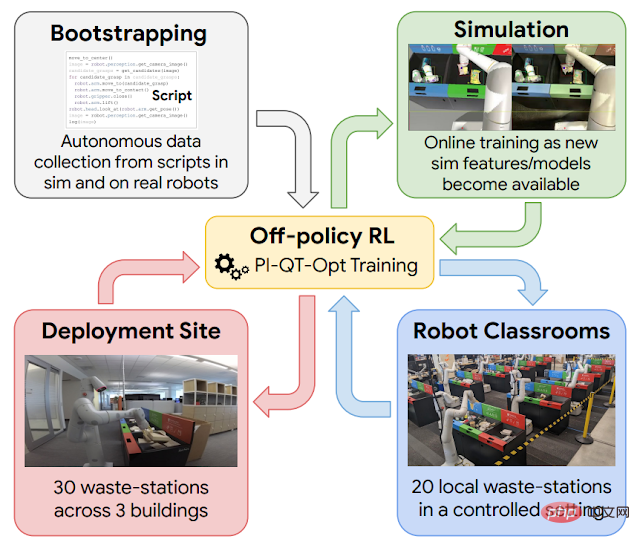
# この大規模アプリケーションにおける強化学習の概略図。スクリプトで生成されたデータを使用して、ポリシーの起動をガイドします (左上)。次に、シミュレーションから実際のモデルへのトレーニングが行われ、シミュレーション環境で追加のデータが生成されます (右上)。各導入サイクル中に、「ロボット教室」 (右下) で収集されたデータを追加します。オフィスビルでのデータの展開と収集 (左下)。
ここで使用される強化学習フレームワークは QT-Opt に基づいており、実験室環境やその他の一連のスキルでさまざまなゴミを捕捉するためにも使用されます。シミュレーション環境をガイドする簡単なスクリプト戦略から始めて、強化学習を適用し、CycleGAN ベースの転送方法を使用して、RetinaGAN を使用してシミュレーション画像をより現実的に見せます。ここからが「ロボット教室」の始まりです。実際のオフィスビルは最もリアルな体験を提供しますが、データ収集のスループットには限界があります。分別すべきゴミが大量にある日もあれば、それほど多くない日もあります。ロボットはその経験のほとんどを「ロボット教室」で蓄積してきました。以下に示す「ロボット教室」では、20 台のロボットがゴミの分別作業を練習しています。 #これらのロボットが「ロボット教室」で訓練されるとき同時に、他のロボットも 3 つのオフィスビルにある 30 個のゴミ箱で同時に学習していました。 研究者らは最終的に、「ロボット教室」から 540,000 件の実験データと、実際の展開環境での 325,000 件の実験データを収集しました。データが増加し続けると、システム全体のパフォーマンスが向上します。研究者らは、制御された比較を可能にするために「ロボット教室」で最終システムを評価し、実際の展開でロボットが目にするものに基づいてシナリオを設定しました。最終的なシステムは平均約 84% の精度を達成し、データが追加されるにつれてパフォーマンスは着実に向上しました。現実世界では、研究者らは 2021 年から 2022 年にかけて実際に導入された統計を文書化し、このシステムがゴミ箱内の汚染物質を重量で 40 ~ 50 パーセント削減できることを発見しました。 Google の研究者は論文の中で、テクノロジーの設計、さまざまな設計上の決定の減衰に関する研究、および実験からのより詳細な統計についてのより深い洞察を提供しています。 実験結果は、強化学習ベースのシステムにより、ロボットが実際のオフィス環境で実際のタスクを処理できることを示しています。オフライン データとオンライン データを組み合わせることで、ロボットは現実世界のさまざまな状況に適応できるようになります。同時に、シミュレーション環境や実際の環境を含む、より制御された「教室」環境での学習は、強化学習の「はずみ車」が回転し始める強力な開始メカニズムを提供し、それによって適応性を実現できます。 重要な結果は達成されましたが、やるべきことはまだたくさんあります。最終的な強化学習戦略が常に成功するとは限らず、パフォーマンスを向上させるにはより強力なモデルが必要です。これを次のように拡張します。より幅広いタスク。さらに、他のタスク、他のロボット、さらにはインターネットビデオなどの他の経験源が、シミュレーションや「教室」から得られるスタートアップの経験をさらに補足する可能性があります。これらは今後取り組むべき課題です。 
分類パフォーマンス
結論と今後の展望
以上がGoogleはゴミの分別を支援する強化学習を使用して23台のロボットを構築するのに2年かかったの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。