
ホームページ >Java >&#&チュートリアル >平均?さらに詳しい内容を提供してください。
平均?さらに詳しい内容を提供してください。

- 王林転載
- 2023-05-08 22:16:291477ブラウズ
1 プロセスの概要
プロセスはロジックの抽象化であり、オペレーティング システムの書籍からプロセスについてはよく理解していますが、プロセスの実装についてはあまり知らないかもしれません。この記事では、プロセス実装の一般原則を説明します。
処理の実装は実際には普段コードを書くときと同じで、例えば何かを表現したい場合にはデータ構造を定義します。プロセスも例外ではありません。したがって、プロセスの本質は、一連のデータを保存するデータ構造です。オペレーティング システムは、すべてのプロセスを配列またはリンク リストの形式で管理します。プロセスは 2 種類に分けられると言えます。
1 システム初期化時の最初のプロセスと
2 最初のプロセスを除く他のプロセスは、fork または forkexecute システムコールによって生成されます。
まず、プロセス構造内の情報を見てみましょう。
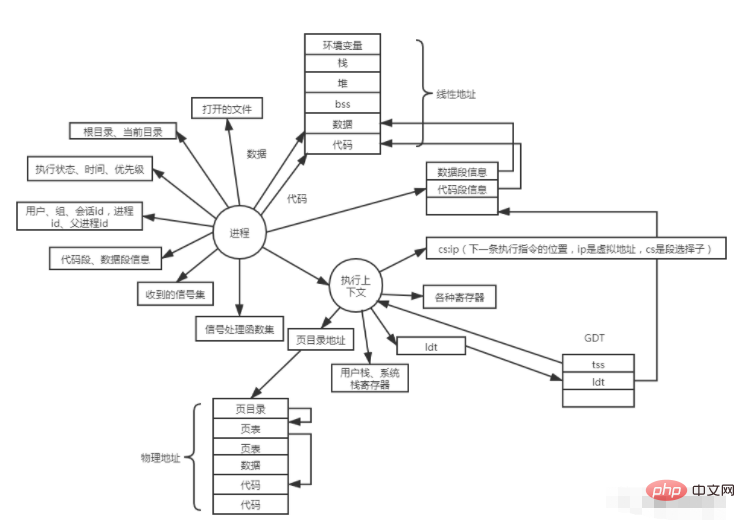
上記は、プロセスを表す構造内の主な情報です。そして、構造はプロセスを表します。 fork は親プロセスをモジュールとして使用し、親プロセスの構造をコピーして、特定のフィールドを変更することがわかっています。新しいプロセスになります。実行が呼び出されると、コピーされた構造内のフィールド (ページ テーブル、コード セグメント、データ セグメントなど) がさらに変更されます。そして、対応するデータをハードディスクからメモリにロードします。では、最初のプロセスはどのようにして生成されるのでしょうか?プロセスは単なる構造体であるため、構造体を事前に定義しておけば、フォークせずにプロセスを作成できます。
2 プロセスの実行
システムがプロセスを作成すると、cs:ip レジスタの値が設定されます。フォークの場合、ip はfork 関数の後のステートメント IP アドレス。実行の場合、IP アドレスはコンパイラによって指定されます。何があっても、プロセスの実行が開始されると、CPU は cs:ip を解析し、実行する命令を取得します。では、cs:ip はどのように解析されるのでしょうか?
プロセスが実行されると、tss セレクター (GDT インデックス) が tss レジスターにロードされ、その後 tss 内のコンテキストも、cr3、ldt セレクターなどの対応するレジスターにロードされます。 tss 情報の ldt インデックスに従って、まず GDT からプロセス ldt 構造データの最初のアドレスを見つけ、次にコード セグメントなどの現在のセグメントの属性に従って cs からセレクターを取得します。システムは次の結果を取得します。 ldt テーブルからのプロセス線形空間の最初のアドレス、アドレス、長さ制限、権限、その他の情報。リニア アドレスの最初のアドレスと IP 内のオフセットを使用してリニア アドレスを取得し、ページ ディレクトリとページ テーブルを通じて物理アドレスを取得します。物理アドレスが割り当てられていない場合、ページ フォルト例外やその他の処理が発生します。実行される。
3 プロセスの一時停止とウェイクアップ
プロセスの一時停止、ブロック、および複数のプロセス。これらの概念はよく耳にしますが、次にそれらがどのように実装されるかを見てみましょう。プロセスの一時停止またはブロックには 2 つのタイプがあります。 ###1積極的に一時停止します。スリープ中にプロセスを断続的にハングさせます。睡眠の原理については以前に分析したことがありますので、改めて分析するつもりはありません。一般原則は、タイマーを設定し、期限切れ後にプロセスを起動することです。
- プロセスを一時停止状態に変更し、復帰するまで待ちます。
- 2 パッシブサスペンション。
パッシブな一時停止のシナリオは数多くあります。主に、プロセスがリソースを申請したが、リソースが条件を満たさず、プロセスがオペレーティング システムによって一時停止される場合です。たとえば、パイプを読み取るとき。パイプから読み取るデータがない場合、プロセスは一時停止されます。パイプの待機キューに挿入します。
パイプにコンテンツが書き込まれると、プロセスが起動されます。プロセスの中断(シグナルで覚醒できるものとシグナルで覚醒できないものの2種類に分けられる)とウェイクアップの実施。
<code>// 当前进程挂载到睡眠队列p中,p指向队列头指针的地址<br>void sleep_on(struct task_struct **p)<br>{<br> struct task_struct *tmp;<br><br> if (!p)<br> return;<br> if (current == &(init_task.task))<br> panic("task[0] trying to sleep");<br> /*<br> *p为第一个睡眠节点的地址,即tmp指向第一个睡眠节点<br> 头指针指向当前进程,这个版本的实现没有采用真正链表的形式,<br> 他通过每个进程在栈中的临时变量形成一个链表,每个睡眠的进程,<br> 在栈里有一个变量指向后面一个睡眠节点,然后把链表的头指针指向当前进程,<br> 然后切换到其他进程执行,当被wake_up唤醒的时候,wake_up会唤醒链表的第一个<br> 睡眠节点,因为第一个节点里保存了后面一个节点的地址,所以他唤醒后面一个节点,<br> 后面一个节点以此类推,从而把整个链表的节点唤醒,这里的实现类似nginx的filter,<br> 即每个模块保存后面一个节点的地址,然后把全局指针指向自己。<br> */<br> tmp = *p;<br> *p = current;<br> // 不可中断睡眠只能通过wake_up唤醒,即使有信号也无法唤醒<br> current->state = TASK_UNINTERRUPTIBLE;<br> // 进程调度<br> schedule();<br> // 唤醒后面一个节点<br> if (tmp)<br> tmp->state=0;<br>}<br><br>// 唤醒队列中的第一个节点,并清空链表,因为第一个节点会向后唤醒其他节点<br>void wake_up(struct task_struct **p)<br>{<br> if (p && *p) {<br> (**p).state=0;<br> *p=NULL;<br> }<br>}</code>以上が平均?さらに詳しい内容を提供してください。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。