



1.LLaMA
LLaMA プロジェクトには、70 億から 650 億のパラメーターのサイズの基本的な言語モデルのセットが含まれています。これらのモデルは数百万のトークンでトレーニングされ、すべて公開されているデータセットでトレーニングされます。その結果、LLaMA-13B は GPT-3 (175B) を上回りましたが、LLaMA-65B は Chinchilla-70B や PaLM-540B などの最高のモデルと同様のパフォーマンスを示しました。

LLaMA からの画像
出典:
- 研究論文: 「LLaMA: オープンで効率的な基盤言語モデル (arxiv. org)" [https://arxiv.org/abs/2302.13971]
- GitHub: facebookresearch/llama [https://github.com/facebookresearch/llama]
- デモ: Baize Lora 7B [https://huggingface.co/spaces/project-baize/Baize-7B]
2.Alpaca
スタンフォード大学の Alpaca は、ChatGPT と競合でき、誰でも 600 ドル未満でコピーできると主張しています。 Alpaca 7B は、52K 命令フォロー デモンストレーションで LLaMA 7B モデルから微調整されています。 トレーニング コンテンツ | スタンフォード大学 CRFM の写真 リソース:- ブログ: スタンフォード大学 CRFM。 [https://crfm.stanford.edu/2023/03/13/alpaca.html]
- GitHub:tatsu-lab/stanford_alpaca [https://github.com/tatsu-lab/stanford_alpaca]
- デモ: Alpaca-LoRA (公式デモは失われています。これは Alpaca モデルのレンダリングです) [https://huggingface.co/spaces/tloen/alpaca-lora]
3.Vicuna
#Vicuna は、ShareGPT から収集されたユーザー共有会話の LLaMA モデルに基づいて微調整されています。 Vicuna-13B モデルは、OpenAI ChatGPT および Google Bard の品質の 90% 以上に達しています。また、90% の確率で LLaMA モデルと Stanford Alpaca モデルを上回りました。ビクーニャの訓練にかかる費用は約 300 ドルです。

Vicuna からの画像
出典:
- ブログ投稿: 「Vicuna: GPT-4 を印象付けるオープンソースのチャットボット」 90%* ChatGPT 品質」 [https://vicuna.lmsys.org/]
- GitHub: lm-sys/FastChat [https://github.com/lm-sys/FastChat#fine-tuning ]
- デモ: FastChat (lmsys.org) [https://chat.lmsys.org/]
4.OpenChatKit
OpenChatKit: ChatGPT に代わるオープン ソースの代替ツールであり、チャットボットを作成するための完全なツールキットです。ユーザー自身の指示調整をトレーニングするための大規模な言語モデル、微調整されたモデル、ボットの応答を更新するためのスケーラブルな検索システム、質問のボット レビューをフィルタリングするための指示が提供されます。

一緒に撮った写真
GPT-NeoXT-Chat-Base-20B モデルは、Basic モードの GPT-NoeX よりも優れたパフォーマンスを発揮していることがわかります。
リソース:
- ブログ投稿:「OpenChatKit の発表」—TOGETHER [https://www.together.xyz/blog/openchatkit]
- GitHub: togethercomputer /OpenChatKit [https://github.com/togethercomputer/OpenChatKit]
- デモ: OpenChatKit [https://huggingface.co/spaces/togethercomputer/OpenChatKit]
- モデル カード: togethercomputer/ GPT-NeoXT-Chat-Base-20B [https://huggingface.co/togethercomputer/GPT-NeoXT-Chat-Base-20B]
#5.GPT4ALL
GPT4ALL はコミュニティ主導のプロジェクトであり、コード、ストーリー、説明、複数回の対話を含む補助インタラクションの大規模なコーパスでトレーニングされています。チームは、オープンソースを促進するために、データセット、モデルの重み、データ管理プロセス、トレーニング コードを提供しました。さらに、ラップトップで実行できるモデルの量子化 4 ビット バージョンもリリースしました。 Python クライアントを使用してモデル推論を実行することもできます。

GPT4ALL の写真
リソース:
- 技術レポート: GPT4All [https://s3.amazonaws.com/static.nomic.ai/gpt4all/2023_GPT4All_Technical_Report.pdf]
- GitHub: nomic-ai/gpt4al [https:/ /github.com/nomic-ai/gpt4all]
- デモ: GPT4All (非公式)。 [https://huggingface.co/spaces/rishiraj/GPT4All]
- モデルカード: nomic-ai/gpt4all-lora · ハグフェイス [https://huggingface.co/nomic-ai/gpt4all-lora] ]
6.Raven RWKV
Raven RWKV 7B は、RWKV 言語モデルによって駆動されるオープンソースのチャット ロボットです。結果は ChatGPT と同様です。このモデルは RNN を使用しており、品質とスケーラビリティの点でトランスに匹敵すると同時に、より高速で VRAM を節約できます。 Raven は、Stanford Alpaca、code-alpaca、その他のデータセットに基づいて微調整されています。

Raven RWKV 7Bからの画像
出典:
- GitHub: BlinkDL/ChatRWKV [https://github.com] /BlinkDL/ChatRWKV]
- デモ: Raven RWKV 7B [https://huggingface.co/spaces/BlinkDL/Raven-RWKV-7B]
- モデル カード: BlinkDL/rwkv-4-レイブン [https://huggingface.co/BlinkDL/rwkv-4-raven]
7.OPT
OPT: Open Pre-trained Transformer 言語モデルは、ChatGPT ほど強力ではありませんが、ゼロショット学習および少数ショット学習とステレオタイプ バイアス分析において優れた機能を示します。より良い結果を得るために、Alpa、Colossal-AI、CTranslate2、FasterTransformer と統合することもできます。 注: このリストに載っている理由は、テキスト生成カテゴリで月間 624,710 ダウンロードされているため、その人気が理由です。

(arxiv.org) からの画像
出典:
- 研究論文: 「OPT: Open Pre-trained Transformer」言語モデル (arxiv.org)」 [https://arxiv.org/abs/2205.01068]
- GitHub: facebookresearch/metaseq [https://github.com/facebookresearch/metaseq] # #デモ: LLM 用のウォーターマーク [https://huggingface.co/spaces/tomg-group-umd/lm-watermarking]
- モデル カード: facebook/opt-1.3b [https://huggingface. co/facebook/opt-1.3b]
##8.Flan-T5-XXLFlan-T5-XXL T5 モデル命令の形で表現されたデータセットに基づいて微調整されます。命令の微調整により、PaLM、T5、U-PaLM などのさまざまなモデル クラスのパフォーマンスが大幅に向上しました。 Flan-T5-XXL モデルは、1,000 を超える追加タスクで微調整され、より多くの言語をカバーします。
 Flan-T5-XXL
Flan-T5-XXL
からの画像出典:
研究論文: 「スケーリング命令 - 微調整された言語モデル」 [https://arxiv.org/pdf/2210.11416.pdf]- GitHub: google-research/t5x [https://github.com/google-research/t5x]
- デモ: Chat Llm ストリーミング [https://huggingface.co/spaces/olivierdehaene/chat-llm-streaming]
- モデル カード: google/flan-t5-xxl [https://huggingface.co/google /flan-t5-xxl?text=Q: ( False or not False or False ) は? A: ステップごとに考えてみましょう]
概要##オープンソースの大規模モデルの中から選択できるものは数多くあります。この記事では、最も人気のある 8 つの大規模モデルについて説明します。
以上がChatGPT と Bard は高価すぎるため、8 つの無料のオープンソースの大規模モデル ソリューションを紹介します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


 GPT-4被曝作弊!LeCun呼吁谨慎在训练集上测试,吉娃娃or松饼的顺序混乱导致错误Nov 13, 2023 pm 08:17 PM
GPT-4被曝作弊!LeCun呼吁谨慎在训练集上测试,吉娃娃or松饼的顺序混乱导致错误Nov 13, 2023 pm 08:17 PMGPT-4解决网络名梗“吉娃娃or蓝莓松饼”,一度惊艳无数人。然而,如今它被指控为“作弊”!图片全用原题中出现的图,只是打乱顺序和排列方式。最新版本的GPT-4以其全模式合一的特点而闻名。然而,令人惊讶的是,它在识别图片数量方面出现了错误,而且连原本能够正确识别的吉娃娃也出现了识别错误图片GPT-4在原图上表现出色的原因是什么呢?根据UCSC助理教授XinEricWang的猜测,搞这项测试的原因是因为互联网上的原图太受欢迎了。他认为GPT-4在训练过程中多次遇到过原始答案,并成功地记住了它们图灵
 令人惊艳的4个ChatGPT项目,开源了!Mar 30, 2023 pm 02:11 PM
令人惊艳的4个ChatGPT项目,开源了!Mar 30, 2023 pm 02:11 PM自从 ChatGPT、Stable Diffusion 发布以来,各种相关开源项目百花齐放,着实让人应接不暇。今天,着重挑选几个优质的开源项目分享给大家,对我们的日常工作、学习生活,都会有很大的帮助。
 Word文档拆分后的子文档字体格式变了怎么办Feb 07, 2023 am 11:40 AM
Word文档拆分后的子文档字体格式变了怎么办Feb 07, 2023 am 11:40 AMWord文档拆分后的子文档字体格式变了的解决办法:1、在大纲模式拆分文档前,先选中正文内容创建一个新的样式,给样式取一个与众不同的名字;2、选中第二段正文内容,通过选择相似文本的功能将剩余正文内容全部设置为新建样式格式;3、进入大纲模式进行文档拆分,操作完成后打开子文档,正文字体格式就是拆分前新建的样式内容。
 vscode配置中文插件,带你无需注册体验ChatGPT!Dec 16, 2022 pm 07:51 PM
vscode配置中文插件,带你无需注册体验ChatGPT!Dec 16, 2022 pm 07:51 PM面对一夜爆火的 ChatGPT ,我最终也没抵得住诱惑,决定体验一下,不过这玩意要注册需要外国手机号以及科学上网,将许多人拦在门外,本篇博客将体验当下爆火的 ChatGPT 以及无需注册和科学上网,拿来即用的 ChatGPT 使用攻略,快来试试吧!
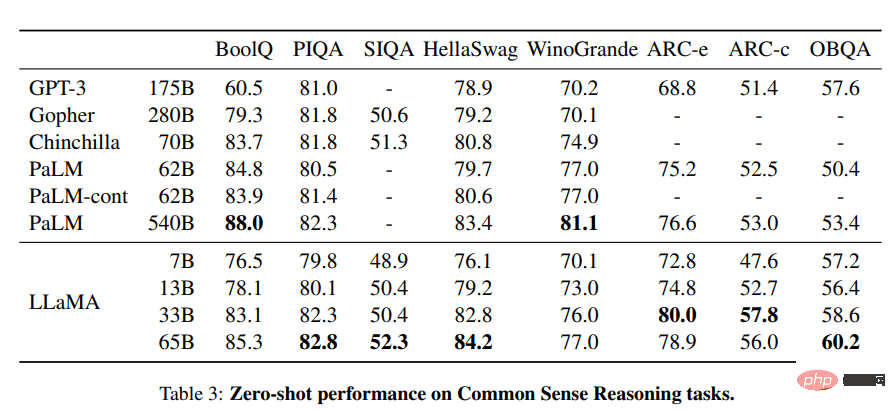 介绍八种免费开源的大模型解决方案,因为ChatGPT和Bard价格太高。May 08, 2023 pm 10:13 PM
介绍八种免费开源的大模型解决方案,因为ChatGPT和Bard价格太高。May 08, 2023 pm 10:13 PM1.LLaMALLaMA项目包含了一组基础语言模型,其规模从70亿到650亿个参数不等。这些模型在数以百万计的token上进行训练,而且它完全在公开的数据集上进行训练。结果,LLaMA-13B超过了GPT-3(175B),而LLaMA-65B的表现与Chinchilla-70B和PaLM-540B等最佳模型相似。图片来自LLaMA资源:研究论文:“LLaMA:OpenandEfficientFoundationLanguageModels(arxiv.org)”[https://arxiv.or
 用ChatGPT秒建大模型!OpenAI全新插件杀疯了,接入代码解释器一键getApr 04, 2023 am 11:30 AM
用ChatGPT秒建大模型!OpenAI全新插件杀疯了,接入代码解释器一键getApr 04, 2023 am 11:30 AMChatGPT可以联网后,OpenAI还火速介绍了一款代码生成器,在这个插件的加持下,ChatGPT甚至可以自己生成机器学习模型了。 上周五,OpenAI刚刚宣布了惊爆的消息,ChatGPT可以联网,接入第三方插件了!而除了第三方插件,OpenAI也介绍了一款自家的插件「代码解释器」,并给出了几个特别的用例:解决定量和定性的数学问题;进行数据分析和可视化;快速转换文件格式。此外,Greg Brockman演示了ChatGPT还可以对上传视频文件进行处理。而一位叫Andrew Mayne的畅销作
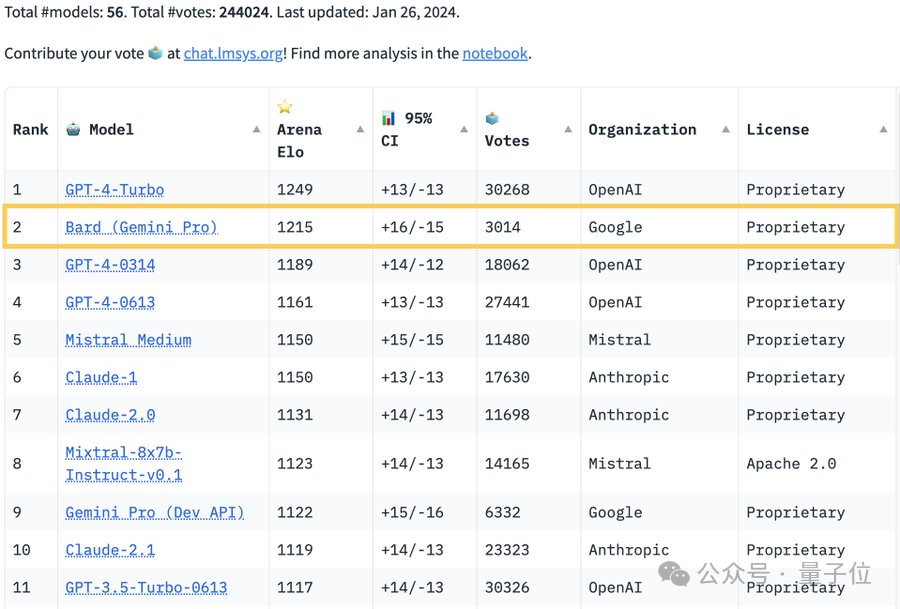 GPT-4不服被Bard反超:最新模型已入场Feb 01, 2024 pm 05:39 PM
GPT-4不服被Bard反超:最新模型已入场Feb 01, 2024 pm 05:39 PM“大模型排位赛”权威榜单ChatbotArena刷新:谷歌Bard超越GPT-4,排名位居第二,仅次于GPT-4Turbo。然鹅,众多网友对此却表示“不服”、“不公平”。原来,谷歌AI掌门人JeffDean透露,Bard性能大幅提升,是因为搭载了新版大模型——GeminiPro-scale。这也就意味着,打“排位赛”的Bard具备了联网功能。网友的质疑正是围绕着这一点展开:在同一个排行榜上混合在线和离线大模型,是极易引起误解的。HuggingFace的“首席羊驼官”OmarSanseviero也


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境
ホットトピック
 7445
7445 15137252
15137252