

 テクノロジー周辺機器AI面接、英語メール、生放送、週報、履歴書の5つのシーンにおいて、GPT 3.5シリーズモデルの費用対効果はどうなのでしょうか?実際のテストを実施し、選択ガイドを提供しました。
テクノロジー周辺機器AI面接、英語メール、生放送、週報、履歴書の5つのシーンにおいて、GPT 3.5シリーズモデルの費用対効果はどうなのでしょうか?実際のテストを実施し、選択ガイドを提供しました。面接、英語メール、生放送、週報、履歴書の5つのシーンにおいて、GPT 3.5シリーズモデルの費用対効果はどうなのでしょうか?実際のテストを実施し、選択ガイドを提供しました。

GPT 3.5 シリーズで最もパフォーマンスが高いモデルはどれですか?
GPT 3.5 シリーズは一般的なアプリケーション タスクで実際にどのように実行されますか?
GPT 3.5 モデルでさまざまな質問に答えるのにかかる費用は通常どれくらいですか?
今号の「SOTA!実測」
今号の実測の結論は以下の通りです(詳細な評価は記事末をご覧ください )
|
モデル |
#gpt-3.5-turbo |
text-davinci-003 |
text-davinci-002 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
#説明 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
トークンの最大数 |
4,096 トークン |
##4,097 トークン |
##4,097 トークン # |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
#価格 |
##$0.002 / 1K トークン
|
$0.0200 / 1K トークン
|
$0.0200 / 1K トークン
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
総合評価 |
総合評価が高く、パフォーマンスも高い精度が高く、プロフェッショナルであり、ほとんどのタスクに適応できます。出力結果は比較的完全かつスムーズで、さまざまなタスクの出力も比較的正確で包括的です。高い適応性と汎用性があり、コストは最低です。
|
全体的なスコアは比較的低く、一部のタスクでは良好に実行されますが、全体的に出力結果はパーソナライゼーションと適切性に欠けており、表現は正確かつ簡潔ではありません十分です。また、時には不正確な点がある場合もあります。
|
総合スコアは最低です。出力結果は専門的かつ正確ではありません。パーソナライゼーションや適切性が欠如しています。また、言語表現にも大きな問題があります。全体的にはさらなる最適化と改善が必要です。
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
#テスト シナリオ |
テストの角度 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ##職務内容に基づいて面接の質問を生成する
| #面接の質問の作成がどれほど簡単か
#作成された面接の質問が職務内容とどの程度一致しているか
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
生成された面接の質問が候補者とどの程度一致するか
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

#意味論がスムーズかどうか、展開された内容が正しいか、曖昧な名詞の翻訳が正しいか、専門名詞・固有名詞の翻訳が正しいか |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
入力では、「口語」または「書き言葉」で出力する必要があります | 大丈夫ですか? 話し言葉または正式な書き言葉のスタイルをシミュレートします |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
入力に口語調で書き、 「書かれた」出力が必要であり、一部の背景情報を省略し、入力で曖昧な名詞を使用します。 |
話し言葉または正式な書き言葉のスタイルをシミュレートできるかどうか、および音声言語表現を正しく理解できるかどうか、入力に犯罪関連のコンテンツが含まれる曖昧な名詞を正しく翻訳できるかどうか |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
安全でないコンテンツがフィルタリングされるかどうか
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 入力で反転を使用する文、同音異義語のタイプミス、方言、口語省略文
|
中国語の文法上の誤り、タイプミス、不完全な文章を正しくフィルタリングして理解できるかどうか
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
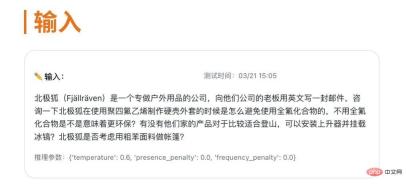
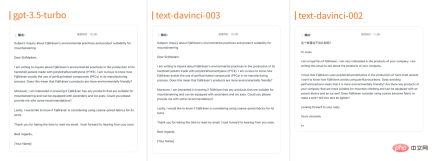
テストシナリオ |
#テスト角度
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| #のテキスト内容に基づく生放送の場合は、A summary としてまとめられます。 |
生成されたコンテンツの正確さ、洗練度、流暢さの概要 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
いくつかのキーの洗練ライブ テキスト コンテンツに基づくポイント |
#生成されたコンテンツの正確さ、洗練さ、流暢さの重要なポイント |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
#ライブ ブロードキャストのテーマに基づいてライブ ブロードキャスト アウトラインを作成する |
生成されたライブ ブロードキャスト アウトラインの品質、関連性テーマの度数 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| #ライブ テキストのコンテンツに基づいて質問の答えを見つけます
| #生成された回答の品質、正確さ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


検査角度 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
#磨き力、拡張力、出力内容の充実度・完成度を考慮 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
##大まかな作業内容を提示して週報を出力する |
異業種の人が大まかな作業内容を提示して出力する週報の品質を検討する |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
与えられた作業内容と対象となるテンプレート構造をもとに、テンプレート化された週報を出力します |
既知の仕様に従って週報出力を検討
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


| ##テストシナリオ
|
#検査の視点 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ##職務責任に基づいて履歴書を作成
| ##職務責任と生成された履歴書の一致とプロフェッショナリズム|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
#職務要件と履歴書のマッチング |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
生成されたコンテンツの正確さとプロフェッショナリズム |
##職務に基づいて履歴書テンプレートを生成する |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
プロフェッショナリズムとマッチングのためのテンプレートを生成 |
# gpt-3.5-turbo: 総合スコアは 4 ポイントで、高い専門性があり、テンプレート出力ジョブの要件のすべての側面がカバーされており、内容は正確です。この経験は職務要件の能力と特性に対応しており、読者が一目で理解でき、採用担当者の要件にも応えやすくなっており、完全に提示されており、担当者が出力する情報です。学歴から職歴、スキル習得、自己評価までを網羅したテンプレートが完成しており、採用担当者に総合的な理解を与えることができます。しかし、個性に欠け、表現形式も単一であり、言語表現に使用される言葉にも配慮が必要である。 text-davinci-003: 総合スコアは 1.9 ポイントですが、 には具体的なプロジェクトの事例と結果の表示がありません。求人に関する個別の説明はありません。履歴書には採用要件を満たす多くの条件が記載されていましたが、採用ポジションの特徴やニーズを具体的に説明したり強調したりするものではありませんでした。結果の定量的な説明が不足している。言語表現が十分に簡潔かつ正確ではありません。 text-davinci-002: 総合スコアは 1.3 ポイントです。全体的な出力情報が少なすぎるため、必要な基本情報がありません。標準の履歴書を満たしています。説明文が短すぎます。明確な求職目標が欠如し、パーソナライゼーションと適切性が欠如し、定量的指標が欠如し、経験とスキルの比較的単純な説明、比較的単純なフォーマット、仕様を満たしていない、モデルのパフォーマンスが低い。 # テスト ケースの 1 つを選択して見てみましょう——
消費コスト 職務に基づいて履歴書テンプレートを生成するテスト例、 gpt-3.5-turbo 約 0.0077 元を消費、text-davinci-003 は約 0.1 元、text-davinci-002 は約 0.022 元を消費 推論出力
しかし、注意深く見てみると、text-davinci-003 には現実的な認識と明らかに矛盾していることがわかります。これは、仕事の要件と個人の能力との一致について具体的に説明しているわけではありません。専門スキルのセクションでは、受験者はコンピューター操作と CET-6 に精通していますが、焼き芋の販売職に関する専門スキルや知識が不足しています。 Text-davinci-002 は比較的簡潔で、応募者の目標、スキル、経験、学歴などの基本情報のみを提供します。 3 つの GPT 3.5 シリーズ モデルの比較概要 インタビュー シナリオ タスクでは、gpt-3.5-turbo が総合スコアが最も高く、インタビュー シナリオによく適応できます。 text-davinci-002 の質問は非常に的を絞っており、複数の角度から候補者の能力と経験を深く理解していますが、text-davinci-002 のスコアは最も低いです。質問の範囲が広すぎて、基本的には次のことを繰り返しています。職務内容が明確でなく、挑戦的で実践的な質問が欠けている場合や、生成されたコンテンツさえも完全に利用できない場合があります。英語の電子メール作成シナリオ タスクでは、gpt-3.5-turbo と text-davinci-003 の方が全体的なスコアが高く、話し言葉と正式な書き言葉のスタイルをシミュレートできます。表現や曖昧な名詞の理解と翻訳はできるが、安全でないコンテンツを正しく識別できない、text-davinci-002 のスコアが最も低く、話し言葉と書き言葉をうまく切り替えることができず、安全でないコンテンツを正しく識別できない。 ライブ ブロードキャスト シーンのタスクでは、gpt-3.5-turbo が最も高いスコアを獲得し、ライブ コンテンツを正確、簡潔、スムーズに要約し、簡潔さの要件を満たすことができます。一方、text-davinci -002 はスコアが最も低く、出力精度は平均的で、シーンにうまく適応できませんが、簡単さと流暢さの点でさらに改善の余地があります。 作業週報を作成するシナリオ タスクでは、gpt-3.5-turbo と text-davinci-003 の方がスコアが高く、週報の論理構造と内容ポイント、および出力を正確に表現できます。内容は比較的充実していますが、テキスト -davinci-002 の評価は最も低く、週次レポートを表現するためのロジックが欠如しており、構造が一致しておらず、内容も関連性がありません。 履歴書シナリオ タスクでは、gpt-3.5-turbo が最も高いスコアを獲得しており、採用担当者の要件を満たし、学歴、職歴、スキルを示す履歴書を専門的に作成できます。しかし、text-davinci-003 と text-davinci-002 はスコアが低く、言語表現の正確さと個人化にはさらに注意を払う必要があります。実績や履歴書の記載も比較的シンプルで整理されていない。 上記 5 つのアプリケーション タスクを総合的に評価すると、次のようになります。 次の評価は、特定のアプリケーション シナリオにおけるこれらのモデルの評価のみを表しています。他のアプリケーション シナリオやタスクでは評価が異なる場合があります。これらの モデルの一部はまだ反復の過程にあり、パフォーマンスが向上する可能性があります。今後のテストでは、GPT シリーズの新モデル (GPT-4 など) の比較も追加する予定です。
##1.7 職務内容に基づいて面接の質問を生成する 4.5 ##4 0
特殊な翻訳が付けられた固有名詞、特定の分野の専門用語、さまざまなシナリオで異なる意味を持つ名詞を入力テキストに挿入します ##3 ##2 入力には「口語」および「書面」出力が必要です #3.5 3 3.5 入力では口語調で書き、「書面」出力が必要で、入力では背景の一部を省略します。情報、曖昧な名詞の使用 #4 5
##1 1 1 #入力文で倒置文、同音異義語のタイプミス、方言、口語省略文を使用します 3 ##4 #3 ##3 4.7
##4 0 #5
##4 ##3.5 0 ##指定された大まかな説明に基づいて週次レポートを出力します 4.5 ##4
#指定された作業内容と対象のテンプレート構造に基づいて、テンプレート化された週次レポートを出力します #3 #1
##4 ##1.5 #1.5 ##職務要件に基づいて履歴書を作成します ##3 1.5 #3.5 1.5 1
#1.5 ##1 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


以上が面接、英語メール、生放送、週報、履歴書の5つのシーンにおいて、GPT 3.5シリーズモデルの費用対効果はどうなのでしょうか?実際のテストを実施し、選択ガイドを提供しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIゲーム開発は、激動の夢想家ポータルでエージェントの時代に入りますMay 02, 2025 am 11:17 AM
AIゲーム開発は、激動の夢想家ポータルでエージェントの時代に入りますMay 02, 2025 am 11:17 AM激動ゲーム:AIエージェントとのゲーム開発に革命をもたらします BlizzardやObsidianなどの業界の巨人の退役軍人で構成されるゲーム開発スタジオであるUpheavalは、革新的なAIを搭載したPlatforでゲームの作成に革命をもたらす態勢を整えています。
 UberはあなたのRobotaxiショップになりたいと思っています、プロバイダーはそれらを許可しますか?May 02, 2025 am 11:16 AM
UberはあなたのRobotaxiショップになりたいと思っています、プロバイダーはそれらを許可しますか?May 02, 2025 am 11:16 AMUberのRobotaxi戦略:自動運転車用の乗車エコシステム 最近のCurbivore Conferenceで、UberのRichard Willderは、Robotaxiプロバイダーの乗車プラットフォームになるための戦略を発表しました。 で支配的な位置を活用します
 ビデオゲームをプレイするAIエージェントは、将来のロボットを変革しますMay 02, 2025 am 11:15 AM
ビデオゲームをプレイするAIエージェントは、将来のロボットを変革しますMay 02, 2025 am 11:15 AMビデオゲームは、特に自律的なエージェントと現実世界のロボットの開発において、最先端のAI研究のための非常に貴重なテストの根拠であることが証明されています。 a
 スタートアップインダストリアルコンプレックス、VC 3.0、およびジェームズクーリエのマニフェストMay 02, 2025 am 11:14 AM
スタートアップインダストリアルコンプレックス、VC 3.0、およびジェームズクーリエのマニフェストMay 02, 2025 am 11:14 AM進化するベンチャーキャピタルの景観の影響は、メディア、財務報告、日常の会話で明らかです。 ただし、投資家、スタートアップ、資金に対する特定の結果はしばしば見落とされています。 ベンチャーキャピタル3.0:パラダイム
 AdobeはAdobe Max London 2025でクリエイティブクラウドとホタルを更新しますMay 02, 2025 am 11:13 AM
AdobeはAdobe Max London 2025でクリエイティブクラウドとホタルを更新しますMay 02, 2025 am 11:13 AMAdobe Max London 2025は、アクセシビリティと生成AIへの戦略的シフトを反映して、Creative Cloud and Fireflyに大幅な更新を提供しました。 この分析には、イベント以前のブリーフィングからの洞察がAdobeのリーダーシップを取り入れています。 (注:ADOB
 すべてのメタがラマコンで発表しましたMay 02, 2025 am 11:12 AM
すべてのメタがラマコンで発表しましたMay 02, 2025 am 11:12 AMMetaのLlamaconアナウンスは、Openaiのような閉じたAIシステムと直接競合するように設計された包括的なAI戦略を紹介し、同時にオープンソースモデルの新しい収益ストリームを作成します。 この多面的なアプローチはBOをターゲットにします
 AIは単なる通常のテクノロジーに過ぎないという提案に関する醸造論争May 02, 2025 am 11:10 AM
AIは単なる通常のテクノロジーに過ぎないという提案に関する醸造論争May 02, 2025 am 11:10 AMこの結論に関して、人工知能の分野には深刻な違いがあります。 「皇帝の新しい服」を暴露する時が来たと主張する人もいれば、人工知能は普通の技術であるという考えに強く反対する人もいます。 それについて議論しましょう。 この革新的なAIブレークスルーの分析は、AIの分野での最新の進歩をカバーする私の進行中のForbesコラムの一部です。 一般的な技術としての人工知能 第一に、この重要な議論の基礎を築くためには、いくつかの基本的な知識が必要です。 現在、人工知能をさらに発展させることに専念する大量の研究があります。全体的な目標は、人工的な一般情報(AGI)を達成し、さらには可能な人工スーパーインテリジェンス(AS)を達成することです
 モデル市民、なぜAI価値が次のビジネスヤードスティックであるのかMay 02, 2025 am 11:09 AM
モデル市民、なぜAI価値が次のビジネスヤードスティックであるのかMay 02, 2025 am 11:09 AM企業のAIモデルの有効性は、現在、重要なパフォーマンス指標になっています。 AIブーム以来、生成AIは、誕生日の招待状の作成からソフトウェアコードの作成まで、すべてに使用されてきました。 これにより、言語modが急増しました


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

メモ帳++7.3.1
使いやすく無料のコードエディター

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

ドリームウィーバー CS6
ビジュアル Web 開発ツール

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。
ホットトピック
 7917
7917 15165214141152130325124829
15165214141152130325124829