
ホームページ >テクノロジー周辺機器 >AI >ChatGPT を合理的に扱う方法: 10 年間の象徴主義研究者による詳細な議論。
ChatGPT を合理的に扱う方法: 10 年間の象徴主義研究者による詳細な議論。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-08 19:28:071663ブラウズ
過去 10 年間、コネクショニストは、さまざまなディープラーニング モデルのサポートを受けて、ビッグ データの力と高いコンピューティング能力を活用して、人工知能の分野における象徴主義をリードしてきました。
しかし、最近人気のChatGPTなど、新しい深層学習モデルがリリースされるたびに、その強力な性能を賞賛した後、その研究方法そのものやモデル自体の抜け穴や欠陥について激しい議論が巻き起こります。も議論されます。
最近、北明研究所のQian Xiaoyi博士は、10年間記号学派を支持してきた科学者兼起業家として、ChatGPTモデルの比較的冷静かつ客観的な評価を発表しました。
全体として、ChatGPT は画期的なイベントだと考えています。
事前トレーニング モデルは 1 年前に強力な効果を示し始めました。今回は新たなレベルに達し、より多くの注目を集めました。このマイルストーンの後、人間の自然言語に関連する多くの作業モデルが開始されます。 、そしてその多くは機械に置き換えられています。
テクノロジーは一夜にして達成されるものではありません。科学者はその欠点を見るよりも、その可能性にもっと敏感であるべきです。
象徴主義と接続主義の境界
私たちのチームが今回 ChatGPT に特別な注意を払うのは、一般に見られる驚くべき効果のためではなく、一見驚くべき効果の多くを一度に理解できるからです。技術レベルです。
私たちの感覚に本当に影響を与えるのは、そのタスクの一部が記号的ジャンルと神経的ジャンルの間の境界を突破することです。つまり、論理的能力です。ChatGPT は、セルフコーディングや評価コードなどのいくつかのタスクでこの能力を具体化しているようです。 。
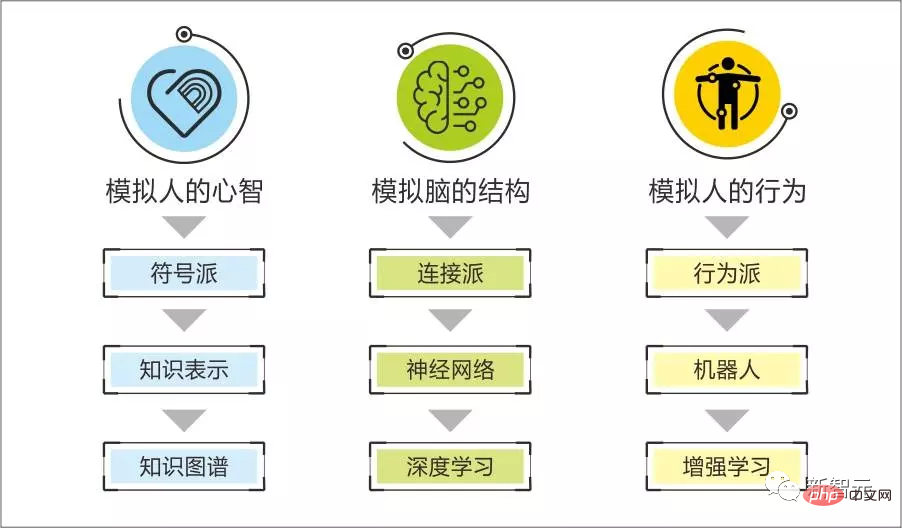
私たちは、記号ジャンルは、問題を解決する方法、問題の原因を分析する方法、問題を作成する方法など、人間の強力な論理的知性を再現するのが得意であると常に信じてきました。ツールなど;
コネクショニズムの本質は統計的アルゴリズムであり、人間の十分な会話を通じて次の文で何を言うかというパターンを見つけるなど、サンプルから滑らかなパターンを見つけるために使用されます。説明文による対応 画像認識と生成のルール...
私たちはこれらの能力を理解し、大規模なモデル、より高品質のデータ、強化学習ループの強化を通じて非常に優れた能力を発揮することができます。
私たちは、人間はすべての内省的認知プロセス、知識学習と応用プロセス、多数の内省的思考、行動、表現パターン、内省的動機、および内省的動機など、象徴的および神経的技術経路の両方の特性を備えていると信じています。感情は、象徴的な表現に基づいて体系的に簡単に説明され、再現されます。
外国人の顔を十分に見ると、外国人の顔を認識できるようになりますが、その理由は説明できません;
最初の作品を見た後は、自然に外国人の顔を認識できるようになりますテレビシリーズ 男性主人公のスピーチを真似する能力;
十分な会話を経験した後、何も考えずにおしゃべりができるようになるのは、すべて神経学的特性です。
強い論理的な部分は骨の成長に、「非論理的法則把握能力」は肉の成長にたとえることができます。
シンボルの「骨格の成長」能力で「肉の成長」は難しく、神経の「肉の成長」能力で「骨格の成長」も難しい。
私たちが AI 構築プロセスに付随するのと同じように、シンボル システムは、対話者の情報の特定の側面を把握し、その背後にある意図を分析し、関連するイベントを推測し、正確な提案を与えることに優れていますが、スムーズで自然な会話を生み出すのが苦手。
また、GPT に代表される対話生成モデルはスムーズな対話を作成できますが、一貫した仲間関係を築き、合理的な感情的動機を生成し、対話である程度の深みのある論理的推論を完成させるために長期記憶を使用することもわかります。これらの側面において分析的な提案を実行することは困難です。
大規模なモデルの「巨大さ」は利点ではありませんが、表面データに固有の強力なロジック主導のルールの一部を把握しようとするために統計アルゴリズムが支払う代償です。これは、シンボルとシンボルの間の境界を具体化します。神経。
ChatGPT の原理をより深く理解した結果、ChatGPT は比較的単純な論理演算のみを通常のトレーニング生成としてみなしており、元の統計アルゴリズムの範囲を超えていないことがわかりました。論理タスクの深さが増すにつれて、システム消費量は幾何級数的に増加します。
しかし、なぜ ChatGPT は元の大規模モデルの限界を突破できるのでしょうか?
ChatGPT が通常の大規模モデルの技術的限界を突破する方法
ChatGPT が他の大規模モデルの限界を突破する仕組みについて、非技術的な言語で説明しましょう。
GPT3 は、登場と同時に他の大型モデルを上回るエクスペリエンスを実証しました。これは自己監視、つまりデータの自己ラベル付けに関連しています。
引き続き対話生成を例に挙げます。60 ラウンドの対話と次の文のルールを習得するために、大規模なモデルが大量のデータでトレーニングされました。
なぜこれほど多くのデータが必要なのでしょうか?なぜ人間はテレビシリーズを見た後、男性主人公のスピーチを真似できるのでしょうか?

なぜなら、人間は次の文で何を言うべきかというルールを把握するための入力として、前のラウンドの対話を使用するのではなく、主観的な対話プロセス中に文脈の理解を形成するからです。彼の現在の感情、モチベーション、それに関連する知識の種類、さらに次の文で何を言うべきかのルールを把握するためのこれまでの対話ラウンド。
大規模なモデルが最初に対話のコンテキスト要素を識別し、それを次の文のルールの生成に使用する場合、元の対話を使用する場合と比較して、同じ効果を達成するにはデータ要件が必要になることが想像できます。大幅に削減できます。したがって、自己監視がどの程度適切に行われるかが、大規模モデルの「モデル効率」に影響を与える重要な要素となります。
大規模なモデル サービスがトレーニング中に特定の種類のコンテキスト情報に自己ラベルを付けたかどうかを調べるには、ダイアログの生成がそのようなコンテキスト情報に敏感かどうか (生成されたダイアログがこのコンテキスト情報の考慮事項を反映しているかどうか) を調べることができます。裁判官。
必要な出力を手動で作成することが 2 番目のポイントになります。
ChatGPT は、対話生成の一般的なルールを学習した GPT3.5 の大規模モデルを微調整するために、数種類のタスクで手動で書かれた出力を使用します。
これは事前トレーニング モデルの精神です。閉じたシーンの対話ルールは、人間の対話生成の一般的なルールの 99% 以上を実際に反映している可能性がありますが、シーン固有のルールは 1 未満です。 %。したがって、人間の対話の一般的なルールを把握するためにトレーニングされた大規模なモデルと、閉じたシーン用の追加の小さなモデルを使用して効果を実現することができ、シーンの特定のルールをトレーニングするために使用されるサンプルは非常に少なくて済みます。

次に機能するメカニズムは、ChatGPT が強化学習を統合することです。プロセス全体は大まかに次のようになります:
開始準備: 事前トレーニングモデル (GPT-3.5)、よく訓練されたラバーのグループ、一連のプロンプト (多数のユーザーの使用プロセスとラバーの設計から収集された指示または質問)。
ステップ 1: ランダムにサンプリングして多数のプロンプトを取得し、データ スタッフ (ラベル) がプロンプトに基づいて標準化された応答を提供します。データ サイエンティストは、GPT-3.5 にプロンプトを入力し、モデルの出力を参照して標準的な回答を提供することができます。
この方法でデータを収集でき、大量のデータがデータセットを形成します。
ChatGPT が送信する良いシグナルは、「モデルの効率」を向上させるために「人間の焦点」や「強化学習」などのアイデアをさらに使用できるということです。
"Big" は、モデルの機能に関連付けられた唯一の指標ではなくなりました。たとえば、13 億のパラメータを持つ InstructGPT は、175 億のパラメータを持つ GPT-3 よりも優れています。
これにもかかわらず、トレーニングによるコンピューティング リソースの消費は大規模モデルのしきい値の 1 つにすぎず、その後に高品質で大規模なデータが続くため、初期のビジネス環境は依然として次のとおりであると考えています。大手メーカーが大型モデルを提供するための設備建設、町工場はこれをベースにスーパーアプリケーションを作成します。巨大になった小さな工場は、その後、独自の大規模モデルをトレーニングすることになります。
シンボルと神経の組み合わせ
シンボルと神経の組み合わせの可能性は、「骨」で「肉」を鍛えることと、「骨」で「肉」を使うことの2点に反映されると考えています。 "骨格"。
対話トレーニングの前の例のように、表面サンプルの下に強力な論理コンテキスト (ボーン) がある場合、コンテキスト要素はボーンであるため、ボーンを含むルールを単純にトレーニングするのは非常にコストがかかります。これは、サンプルの需要と高等モデルのトレーニングのコスト、つまり大規模モデルの「大きさ」に反映されます。
シンボリック システムを使用してコンテキストを生成し、それをニューラル ネットワークのサンプル入力として使用する場合、それは強力な論理認識の背景条件からパターンを見つけて、「骨」に「肉」を訓練するのと同じです。 」。
大規模なモデルがこの方法でトレーニングされた場合、その出力は強い論理条件の影響を受けやすくなります。
たとえば、対話生成タスクでは、対話に参加する双方の現在の感情、動機、関連知識、関連イベントを入力し、大規模モデルによって生成される対話はこれらに対する応答を反映できます。一定の確率でコンテキスト情報が得られます。これは、強力なロジックの「骨」に「肉」を使用することです。
以前、私たちはコンパニオンレベルの AI の開発において、シンボルではスムーズな会話を生み出すことができないという問題に遭遇しました。ユーザーが AI と会話することに消極的であれば、AI の背後にあるすべての論理的および感情的機能はそれを実現できません。対話の滑らかさについては、上記と同様の学習済みモデルと組み合わせることで解決しました。
大規模モデルの観点から見ると、単に大規模モデルで AI を作成するだけでは整合性や立体性に欠けます。
「全体性」は主に、会話の生成において文脈関連の長期記憶が考慮されるかどうかに反映されます。
たとえば、前日のAIとユーザーのチャットでは、ユーザーが風邪をひいて病院に行って、さまざまな症状があり、それがどれくらい続いたかについて話していました... ; 翌日、ユーザーは突然「喉の痛みは大丈夫です。痛みがあります。」と言いました。
単純な大規模モデルでは、AI がコンテキスト内の内容に応答して、「喉が痛いのはなぜですか?」「病院には行きましたか?」などの表現をします。長期記憶と直接関連付けられる、長期記憶の不一致を反映する矛盾。
シンボルシステムと組み合わせることで、AIは「ユーザーは次の日も喉が痛い」から「ユーザーは昨日風邪を引いた」、そして「ユーザーは病院に行った」までを関連付けることができます。 「ユーザーには他の症状があります」... この情報をコンテキストに組み込むと、大規模モデルのコンテキスト一貫性機能を使用して、長期記憶の一貫性を反映できます。
「三次元感覚」はAIに執着があるかどうかに反映されます。
私たちが人間のように自分の感情、動機、アイデアに執着するかどうか。シンプルで大きなモデルで作成されたAIは、人付き合いの際に飲酒量を減らすようランダムに注意を促しますが、シンボルシステムと組み合わせると、ユーザーの肝臓の長期記憶が良くないことがわかり、一般的なデータと組み合わせることで、ユーザーの肝臓が悪くてお酒が飲めないことを感知すると、ユーザーの飲酒を防ぐための強力かつ継続的なメッセージが生成されます。ユーザーが社交後に飲酒するかどうかを追跡することをお勧めします。ユーザーの自制心の欠如は、雰囲気に影響を与え、その後の会話にも影響を与える、これは三次元感覚の反映です。
大きなモデルは一般的な人工知能ですか?
事前学習モデルの実装メカニズムから判断すると、これは統計アルゴリズムの「サンプル パターンを把握する」能力を突破するものではなく、コンピュータのキャリアを利用してこの能力を実現しているだけです。非常に高いレベルであり、ある論理的能力と解決能力があるかのような錯覚を反映しています。
単純な事前トレーニング済みモデルには、人間の創造性、詳細な論理的推論能力、複雑なタスクを解決する能力はありません。
したがって、事前トレーニングされたモデルは、特定のシナリオへの低コストの移行により、ある程度の汎用性を備えていますが、「常に変化する上位のインテリジェントな表現を一般化する」人間の一般的な知性を備えていません。限られた基盤となるインテリジェンス メカニズムを通じてレイヤーを構築します。」
2 番目に、「創発」について話したいと思います。大規模モデルの研究では、研究者は、モデルのパラメーター スケールとデータ スケールが特定の臨界値を超えると、いくつかの能力指標が急速に増加し、創発を示していることに気づきます。効果。 。
実際、抽象学習機能を備えたシステムはすべて「創発」を示します。
これは、抽象演算の性質、つまり「個々のサンプルや推測の正確さにこだわるのではなく、サンプル全体や推測全体の統計的な正確さに基づく」という性質に関連しています。
したがって、サンプルサイズが十分であり、モデルがサンプル内の詳細なパターンの発見をサポートできる場合、特定の能力が突然形成されます。
半記号的思考プロジェクトでは、記号AIの言語学習の過程も、人間の子どもの言語習得と同じように「出現」することがわかります。あなたの理解力と話す能力は飛躍的に向上します。
つまり、創発を現象として捉えるのは問題ありませんが、メカニズムが不明瞭なシステム機能の突然変異はすべて創発と解釈し、人類の全体的な知性が一定であれば、単純なアルゴリズムが出現できると期待すべきです。これは厳密な科学的態度ではありません。
一般人工知能
人工知能の概念は、コンピューターの出現とほぼ同時に登場しました。当時は、人間の知能をコンピューターに移植するという単純なアイデアでした。これが人工知能の概念です。知能 出発点、人工知能の初期の概念は「汎用人工知能」を指します。
人間の知能モデルが汎用知能であり、この知能モデルをコンピュータに移植したものが汎用人工知能です。
それ以来、人間の知性のメカニズムを再現しようとする多くの学派が現れましたが、どの学派も目立った成果を上げることができませんでした。過去 70 年間の人工知能研究から学べる最大の教訓は、研究者は短期間で結果を達成しようとするために人間の利用を好むということです。この分野の経験と知識(人間のメカニズムを模倣する)、長期的には、スケーラブルな一般的なコンピューティング手法を活用することが最終的に効果的です。
今日の大型モデルの傑出した成果は、彼の「アルゴリズム主義」という命題の正しさを証明していますが、「創造物を模倣して人間を創造する」ことで知的エージェントを生み出す道が必ずしも間違っているというわけではありません。
では、なぜ人間を模倣するこれまでの流派は次々と挫折を味わったのでしょうか?これは人間の知性の中核の完全性に関係しています。
簡単に言えば、人間の言語、認知、感情的な意思決定、学習能力によって形成されるサブシステムは、ほとんどのタスクの実現において相互にサポートしており、独立して実行できるサブシステムはありません。
高度に統合されたシステムとして、上位レベルの外観は多くの基礎となるメカニズムの連携によって実現され、いずれかに欠陥がある限り、この表面効果の外観に影響を及ぼします。
人体と同様に、それも非常に複雑なシステムであり、健康な人と病気の人の間にはわずかな違いがあるかもしれませんが、この微妙な病理学的違いがあらゆる面で人の機能を阻害します。
同様に、一般的な人工知能の場合、最初の 99 ステップの効果は非常に限定的である可能性があり、パズルの最後のピースが完成すると、最初の 99 ステップの機能が明らかになるでしょう。
これまでの学派は、人間の知性全体の一部を独自の視点で捉え、人間を模倣することで一定の成果を上げてきましたが、それはシステム全体が放出できるエネルギーに比べればほんの一部に過ぎません。
プロセスインテリジェンスと人類文明
人間のすべての局所的知性は、これまで、またはコンピュータによってはるかに超えられつつありますが、たとえすべての局所的知性がコンピュータに追い越されたとしても、私たちが断言できるのは次のことだけです。人間は文明を築くことができますが、コンピューターは単なる道具です。 ######なぜ?
なぜなら、文明の創造の背後には、人間のさまざまな知的活動のプロセスがあるからです。つまり、人類の文明は「プロセス知性」から来ているということです。これは現在非常に無視されている方向です。
「認知プロセス」はタスクではなく、プロセス内の多くのタスクの組織化です。
たとえば、AIが患者の症状を治したい場合、それは「目標解決」のタスクです。
まず、属性解決に切り替える必要があります。これは認知タスクです。考えられる原因を見つけた後、病気が発生している可能性があるかどうかを判断する「特定のイベントを解決する」タスクになります。再度タスクを継続する 分解して他のタスクに移す 途中で知識が不足している場合は「知識解決」のタスクになります。
調査、検索、読書を通じて既存の知識を取得することも、「統計的認知」を使用することもできます。統計的認知によって相関関係が発見された後、その背後にある因果関係の連鎖をさらに洞察して、より良い介入を実現することができます。このステップでは、知識不足により知識による解決に向かうことが多く、推測を検証するには、特定の事象の発生を解決するための実験を計画する必要があります...
因果連鎖を理解した後、もう一度目標を達成して、因果関係の連鎖を実行することができます。介入により、元の目標は、因果関係の連鎖内のイベントの作成、終了、防止、維持に変わります。これは、「目標解決」のプロセスに戻ります...
# この観点から、ChatGPT のようなテクノロジーはタスクの実装に使用され、部分シンボリックな汎用人工知能フレームワークがこれらのローカル タスク機能を組織して、人間のような知的活動のプロセスをサポートします。 。
一般的な人工知能は「人間」のオントロジーであり、内部化された能力と外部化されたツールを使用してタスクを完了し、これらのタスクを組織して知的活動のプロセスをサポートします。 
人間の全体的な知能をコンピュータ上で再現でき、コンピュータのキャリアアドバンテージを利用して、機械が独自に認知を探索し、ツールを作成し、問題を解決し、目標を達成するプロセスをサポートできるようになったら、全体的な知能が向上すると想像できます。人間の知能とプロセス知能が以前のように増幅されたときのみ、人工知能の力を真に解き放ち、人類の文明を新たな高みにサポートすることができます。
著者について

著者のQian Xiaoyi博士は、杭州の象徴的な人工知能科学者、上級エンジニア、高レベルの認定人材であり、ロジック バイオニック フレームワークの初期の開発者、エクスプローラー、M 言語記号学の初版の作成者。 Bei Mingxing Mou の創設者、CEO、会長。
上海交通大学で応用経済学の博士号、米国の CGU ドラッカー ビジネス スクールで金融工学の修士号、浙江大学の Qiu Chengtong 数学エリート クラスで数学と金融のダブル学士号を取得科鎮大学。彼は 11 年間一般 AI の分野で研究しており、7 年間エンジニアリング実践でチームを率いてきました。
以上がChatGPT を合理的に扱う方法: 10 年間の象徴主義研究者による詳細な議論。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。