
ホームページ >バックエンド開発 >Python チュートリアル >Python は Excel ファイルをどのように処理しますか?
Python は Excel ファイルをどのように処理しますか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-08 17:58:151981ブラウズ
『問題内容』
今回処理するExcelはシートが2枚あり、一方のシートのデータを元にもう一方のシートの値を計算する必要があります。問題は、計算対象のシートに数値だけでなく数式も含まれていることです。見てみましょう:
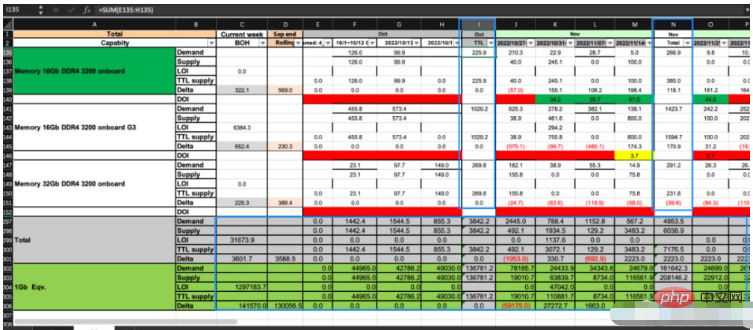
上の図に示すように、この Excel には CP と DS の合計 2 つのシートがあります。特定のビジネス ルールに従い、 CP のデータ DS の該当セルのデータを計算します。画像の青いボックスには数式が含まれており、他の領域には数値が含まれています。
見てみましょう。前述の処理ロジックに従い、Excel を一度にバッチでデータフレームに読み込み、それを一度にバッチで書き戻すと、何が問題になるでしょうか。コードのこの部分は次のとおりです。
import pandas as pd
import xlwings as xw
#要处理的文件路径
fpath = "data/DS_format.xlsm"
#把CP和DS两个sheet的数据分别读入pandas的dataframe
cp_df = pd.read_excel(fpath,sheet_name="CP",header=[0])
ds_df = pd.read_excel(fpath,sheet_name="DS",header=[0,1])
#计算过程省略......
#保存结果到excel
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()上記のコードの問題は、pd.read_excel() メソッドが Excel からデータフレームにデータを読み取るときに、数式が含まれるセルの場合、数式が直接読み取られることです。結果 (結果がない場合は Nan が返されます)、Excel に書き込むときは、データフレームを一度にバッチで直接書き戻すので、以前に数式が含まれていたセルは計算された値または計算値で書き戻されます。ナン、と捨てられる式。
さて、問題が発生しました。どう解決すればよいでしょうか?ここで 2 つのアイデアが思い浮かびます:
データフレームを Excel に書き戻すとき、一度にバッチで書き戻すのではなく、行と列を繰り返して計算されたデータのみを書き戻す。 . 数式が入ったセルが動かない;
エクセルを読んでいるときに、数式の計算結果を読むのではなく、数式が入っているセルの数式を読み取る方法はありますか?
上記の 2 つのアイデアをそれぞれ試してみました。見てみましょう。
「オプション 1」
次のコードは、データフレームを走査し、セルに従って対応する値を書き込もうとします。数式が含まれるセルは移動しません
#根据ds_df来写excel,只写该写的单元格
for row_idx,row in ds_df.iterrows():
total_capabity_val = row[('Total','Capabity')].strip()
total_capabity1_val = row[('Total','Capabity.1')].strip()
#Total和1Gb Eqv.所在的行不写
if total_capabity_val!= 'Total' and total_capabity_val != '1Gb Eqv.':
#给Delta和LOI赋值
if total_capabity1_val == 'LOI' or total_capabity1_val == 'Delta':
ds_worksheet.range((row_idx + 3 ,3)).value = row[('Current week','BOH')]
print(f"ds_sheet的第{row_idx + 3}行第3列被设置为{row[('Current week','BOH')]}")
#给Demand和Supply赋值
if total_capabity1_val == 'Demand' or total_capabity1_val == 'Supply':
cp_datetime_columns = cp_df.columns[53:]
for col_idx in range(4,len(ds_df.columns)):
ds_datetime = ds_df.columns.get_level_values(1)[col_idx]
ds_month = ds_df.columns.get_level_values(0)[col_idx]
if type(ds_datetime) == str and ds_datetime != 'TTL' and ds_datetime != 'Total' and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',f'{ds_datetime}')]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',f'{ds_datetime}')]}")
elif type(ds_datetime) == datetime.datetime and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',ds_datetime)]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',ds_datetime)]}")上記のコードは問題を解決します。問題は解決されます。つまり、数式が含まれるセルの数式は保持されます。ただし、記事の冒頭で述べた Python による Excel 処理に関するアドバイスによると、このコードは API を介して Excel のセルを頻繁に操作するため、パフォーマンスに重大な問題があり、書き込みが非常に遅くなります。私の古い Mac で実行するには時間がかかりました。 40 分という時間は到底受け入れられないため、計画は断念せざるを得ませんでした。
『プラン2』
このプランは、Excelで数式値が含まれるセルを読み込む際に、数式値を保持したいと考えています。これは、各 Python Excel ライブラリの API から、対応するメソッドがあるかどうかを確認するだけです。 Pandas の read_excel() メソッドを注意深く調べてみましたが、対応するパラメーターのサポートはありませんでした。 Openpyxl をサポートできる API を見つけました:
import openpyxl ds_format_workbook = openpyxl.load_workbook(fpath,data_only=False) ds_wooksheet = ds_format_workbook['DS'] ds_df = pd.DataFrame(ds_wooksheet.values)
ここでのキーは data_only パラメータです。True の場合はデータが返され、False の場合は数式の値が保持されます。
見つかったと思い、対応する解決策を見つけて大喜びしましたが、openpyxl で読み取られたデータフレーム内のデータ構造を見てショックを受けました。 Excel テーブルのヘッダーは比較的複雑な 2 レベルのヘッダーであるため、ヘッダー内でセルがマージされたり分割されたりする状況があり、そのようなヘッダーが openpyxl によってデータフレームに読み込まれた後、マルチレベルのヘッダーには従いません。パンダのヘッダー インデックスは処理されますが、単に数値インデックス 0123...
に処理されるだけですが、データフレームの計算はマルチレベル インデックスに依存するため、openpyxl のこの処理方法により、後続の計算を処理できません。
openpyxl は機能しません。xlwings はどうですか? xlwings API ドキュメントを検索した結果、以下に示すように実際に見つかりました。
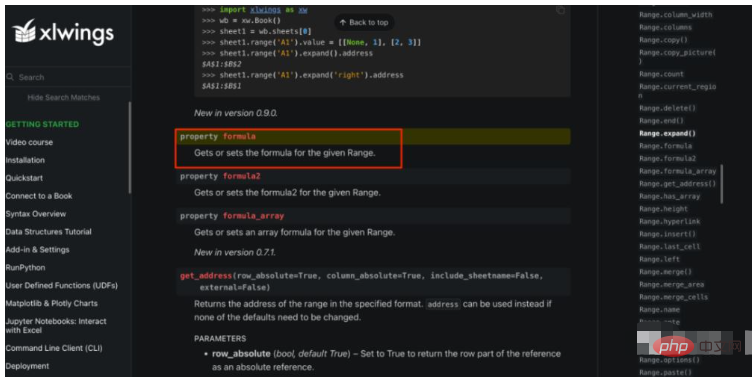
Range クラスには、formula を取得および設定できる Formula というプロパティが用意されています。
これを見たとき、宝物を見つけたような気分になり、すぐにコードを練習し始めました。おそらく惰性からか、あるいは過去に Excel を行、列、セルごとに操作する効率性に恐怖を感じていたのかもしれませんが、私が最初に思いついた解決策は、それを一度にバッチで実行する、つまりすべての数式を読み取ることでした。戻って、私の最初のコードは次のようなものでした:
#使用xlwings来读取formula app = xw.App(visible=False,add_book=False) ds_format_workbook = app.books.open(fpath) ds_worksheet = ds_format_workbook.sheets["DS"] #先把所有公式一次性读取并保存下来 formulas = ds_worksheet.used_range.formula #中间计算过程省略... #一次性把所有公式写回去 ds_worksheet.used_range.formula = formulas
しかし私の考えは間違っており、ds_worksheet.used_range.formula によって数式は返されるだけであると誤解しました。 Excel で数式が含まれるセルですが、実際にはすべてのセルが返され、数式が含まれるセルについては数式のみが保持されます。したがって、数式を書き直すと、データフレームを通じて計算して Excel に書き込んだ他の値が上書きされます。
この場合、数式を含むセルは一度にすべて処理するのではなく個別に処理することしかできないため、コードは次のように記述する必要があります。
#使用xlwings来读取formula
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
#保留excel中的formula
#找到DS中Total所在的行,Total之后的行都是formula
row = ds_df.loc[ds_df[('Total','Capabity')]=='Total ']
total_row_index = row.index.values[0]
#获取对应excel的行号(dataframe把两层表头当做索引,从数据行开始计数,而且从0开始计数。excel从表头就开始计数,而且从1开始计数)
excel_total_row_idx = int(total_row_index+2)
#获取excel最后一行的索引
excel_last_row_idx = ds_worksheet.used_range.rows.count
#保留按日期计算的各列的formula
I_col_formula = ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula
N_col_formula = ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula
T_col_formula = ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula
U_col_formula = ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula
Z_col_formula = ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula
AE_col_formula = ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula
AK_col_formula = ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula
AL_col_formula = ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula
#保留Total行开始一直到末尾所有行的formula
total_to_last_formula = ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula
#中间计算过程省略...
#保存结果到excel
#直接把ds_df完整赋值给excel,会导致excel原有的公式被值覆盖
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
#用之前保留的formulas,重置公式
ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula = I_col_formula
ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula = N_col_formula
ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula = T_col_formula
ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula = U_col_formula
ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula = Z_col_formula
ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula = AE_col_formula
ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula = AK_col_formula
ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula = AL_col_formula
ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula = total_to_last_formula
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()テスト後、上記のコードで問題は解決しました。完璧に私のニーズを満たしており、パフォーマンスはまったく問題ありません。
以上がPython は Excel ファイルをどのように処理しますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。