
ホームページ >Java >&#&チュートリアル >ExcelデータをJavaでツリー構造に変換するにはどうすればよいですか?
ExcelデータをJavaでツリー構造に変換するにはどうすればよいですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-08 08:49:072452ブラウズ
はじめに
本日、Excel データをデータベースに保存するインポート タスクを受け取りました。通常のインポートとは異なり、インポートされたデータは次のようなツリー構造になっています:
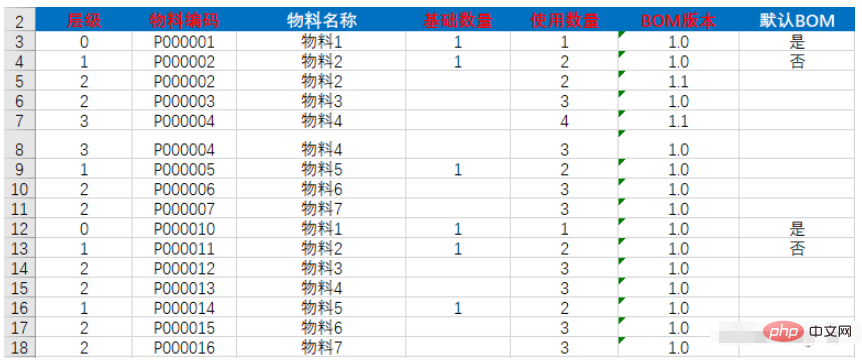
データ内の階層列を観察すると、テーブル データが 3 番目、4 番目、5 番目、6 番目、7 番目、8 番目、9 番目、10 番目、11 番目、12 番目の 2 つのツリーで構成されていることがわかりました。 13,14,15,16,17,18 では、0 をツリーのルート ノードとして、1 を 0 の子ノードとして、2 を隣接する 1 の子ノードとして使用します。これから、最初のツリーの構造が得られます。
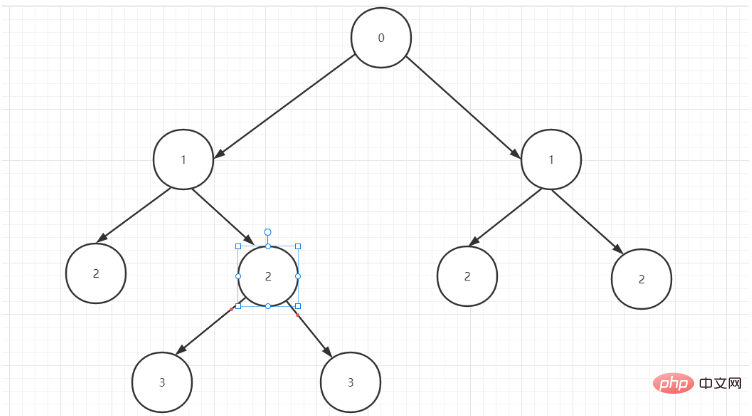
元のデータを分割します
1. エンティティ クラスを作成します
解析されたデータを受け取る vo を作成します。ここでは、次の点のみを考慮します。階層属性
@Excel(name = "层级")
private String hierarchy;
@Excel(name = "物料编码")
private String materialCode;
@Excel(name = "物料名称")
private String materialName;
@Excel(name = "基础数量")
private BigDecimal materialNum;
@Excel(name = "使用数量")
private BigDecimal useAmount;
@Excel(name = "BOM版本")
private String version;
@Excel(name = "默认BOM")
private String isDefaults;2. データの処理
データ ソースを複数のツリー データ セットに分割します
コードは次のとおりです (例):
/**
* 将集合对象按指定元素分割存储
*
* @param materialVos 原始集合
* @param s 分割元素(这里是当集合对象层级为0时则分割,也就是树的根节点为0)
* @return 每棵树的结果集
*/
private List<List<MatMaterialBomImportVo>> subsection(List<MatMaterialBomImportVo> materialVos, String s) {
List<List<MatMaterialBomImportVo>> segmentedData = new ArrayList<>();
if (materialVos != null) {
//获取指定元素的数量,判断出最终将拆分为多少段
List<MatMaterialBomImportVo> collect = materialVos.stream().filter(bom -> s.equals(bom.getHierarchy())).collect(Collectors.toList());
int count = 0;
for (int i = 0; i < collect.size(); i++) {
List<MatMaterialBomImportVo> bomImportVo = new ArrayList<>();
boolean num = false;
//遍历数据源
for (; count < materialVos.size(); count++) {
//第一个必然为树的根节点,直接获取并跳过
if (count == 0) {
bomImportVo.add(materialVos.get(count));
continue;
}
//当数据源第n个等于根节点并且已经成功添加过数据时判断为一段数据的结束,跳出循环,
if (s.equals(materialVos.get(count).getHierarchy()) && num) {
break;
}
bomImportVo.add(materialVos.get(count));
num = true;
}
segmentedData.add(bomImportVo);
}
}
return segmentedData;
}手動設定 各ツリーの各ノードのIDと親ID
コードは次のとおりです(例):
for (List<MatMaterialBomImportVo> segmentedDatum : subsection(materialVos, "0")) {
//设置id以及父id
int i = 0;
for (MatMaterialBomImportVo vo : segmentedDatum) {
BeanTrim.beanAttributeValueTrim(vo);
vo.setPrimaryKey(i);
getParentId(vo, segmentedDatum);
i++;
}
}
/**
* 设置父id
*
* @param vo
* @param segmentedDatum
*/
private void getParentId(MatMaterialBomImportVo vo, List<MatMaterialBomImportVo> segmentedDatum) {
for (int j = vo.getPrimaryKey(); j >= 0; j--) {
if (Integer.parseInt(segmentedDatum.get(j).getHierarchy()) == Integer.parseInt(vo.getHierarchy()) - 1) {
vo.setForeignKey(segmentedDatum.get(j).getPrimaryKey());
break;
}
if (j == 0) {
vo.setForeignKey(-1);
}
}
}手順: 複数のツリーに分割した後、それぞれの仮想IDを設定します。データの一部を独自のインデックスとして使用し、各ツリーの ID は互いに分離されています。
テーブル データの規則によれば、子ノードは、それ自体のノードの下位および上位にのみ存在できると結論付けることができます。このルールに従って、各ノードの親 ID を設定します
ツリー構造への再帰カプセル化
##コードは次のとおりです (例):/**
* 递归遍历为树形结构
*
* @param vo 当前处理的元素
* @param segmentedDatum 每棵树的数据集
*/
private void treeData(MatMaterialBomImportVo vo, List<MatMaterialBomImportVo> segmentedDatum) {
for (int i = vo.getPrimaryKey(); i < segmentedDatum.size(); i++) {
if (i + 1 == segmentedDatum.size()) {
if (vo.getForeignKey() == null) {
getParentId(vo, segmentedDatum);
}
break;
}
int v = Integer.parseInt(vo.getHierarchy());
int vs = Integer.parseInt(segmentedDatum.get(i + 1).getHierarchy());
if (vs == v + 1) {
if (v > 1) {
vo.setForeignKey(segmentedDatum.get(i).getPrimaryKey());
for (int j = vo.getPrimaryKey(); j > 0; j--) {
if (Integer.parseInt(segmentedDatum.get(j).getHierarchy()) == Integer.parseInt(vo.getHierarchy()) - 1) {
vo.setForeignKey(segmentedDatum.get(j).getPrimaryKey());
}
}
}
vo.getImportVoList().add(segmentedDatum.get(i + 1));
}
if (vs <= v) {
if (vo.getForeignKey() == null) {
for (int j = vo.getPrimaryKey(); j > 0; j--) {
if (Integer.parseInt(segmentedDatum.get(j).getHierarchy()) == Integer.parseInt(vo.getHierarchy()) - 1) {
vo.setForeignKey(segmentedDatum.get(j).getPrimaryKey());
break;
}
}
}
break;
}
}
if (vo.getImportVoList() != null && vo.getImportVoList().size() > 0) {
for (MatMaterialBomImportVo matMaterialBomImportVo : vo.getImportVoList()) {
treeData(matMaterialBomImportVo, segmentedDatum);
}
}
}説明: ここで渡した vo には ID と親 ID が設定されておらず、データ ソースのみが設定されています。ツリー分割プロセスが完了しました。ビジネス要件により、この再帰メソッドのセットは後でツリーを組み立てるのに使用されませんでした。再帰コードにはエラーが含まれる可能性があります。参照のみを目的としています。以上がExcelデータをJavaでツリー構造に変換するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事はyisu.comで複製されています。侵害がある場合は、admin@php.cn までご連絡ください。