
ホームページ >テクノロジー周辺機器 >AI >改良されたドロップアウトを使用すると、アンダーフィッティングの問題を軽減できます。
改良されたドロップアウトを使用すると、アンダーフィッティングの問題を軽減できます。

- 王林転載
- 2023-05-07 23:43:061421ブラウズ
2012 年、Hinton らは論文「特徴検出器の同時適応を防止することによるニューラル ネットワークの改善」でドロップアウトを提案しました。同年、AlexNet の出現によりディープラーニングの新時代が開かれました。 AlexNet はドロップアウトを使用して過剰適合を大幅に削減し、ILSVRC 2012 コンテストでの勝利に重要な役割を果たしました。脱落者がいなかったら、私たちが現在見ている深層学習の進歩は何年も遅れていたかもしれないと言えば十分でしょう。
ドロップアウトの導入以来、ニューラル ネットワークの過学習を軽減するための正則化手段として広く使用されてきました。ドロップアウトは確率 p で各ニューロンを非活性化し、異なる特徴が互いに適応するのを防ぎます。ドロップアウトを適用すると、通常、テスト誤差が減少する一方でトレーニング損失が増加し、モデルの汎化ギャップが解消されます。ディープラーニングの開発により、新しいテクノロジーとアーキテクチャが導入され続けていますが、ドロップアウトは依然として存在します。 AlphaFold タンパク質予測、DALL-E 2 画像生成などの最新の AI 成果において役割を果たし続け、多用途性と有効性を実証しています。
ドロップアウトの人気は続いているにもかかわらず、その強度 (ドロップ率 p として表される) は年々低下しています。最初のドロップアウトの取り組みでは、デフォルトのドロップ率 0.5 を使用しました。ただし、近年では 0.1 などのより低いドロップ率が使用されることが多く、これに関連する例は BERT や ViT のトレーニングで見られます。この傾向の主な要因は、利用可能なトレーニング データが爆発的に増加し、過剰学習がますます困難になっていることです。他の要因と組み合わせると、すぐに過剰適合の問題よりも過小適合の問題が発生する可能性があります。
最近、「ドロップアウトによるアンダーフィッティングの軽減」という論文で、メタ AI、カリフォルニア大学バークレー校、その他の機関の研究者が、ドロップアウトを使用してアンダーフィッティングの問題を解決する方法を実証しました。
論文アドレス: https://arxiv.org/abs/2303.01500
彼らは最初に勾配基準を通過しました私たちは、いくつかの興味深い観察結果を使用してドロップアウトのトレーニングのダイナミクスを調べ、重要な経験的発見を導き出します。トレーニングの初期段階では、ドロップアウトによってミニバッチの勾配の分散が減少し、モデルがより一貫した方向に更新できるようになります。これらの方向は、以下の図 1 に示すように、データセット全体にわたる勾配の方向ともより一致しています。
結果として、モデルは個々のミニバッチの影響を受けることなく、トレーニング セット全体のトレーニング損失をより効果的に最適化できます。つまり、ドロップアウトは確率的勾配降下法 (SGD) に対抗し、トレーニングの初期段階でサンプリングされたミニバッチのランダム性によって引き起こされる過剰な正則化を防ぎます。
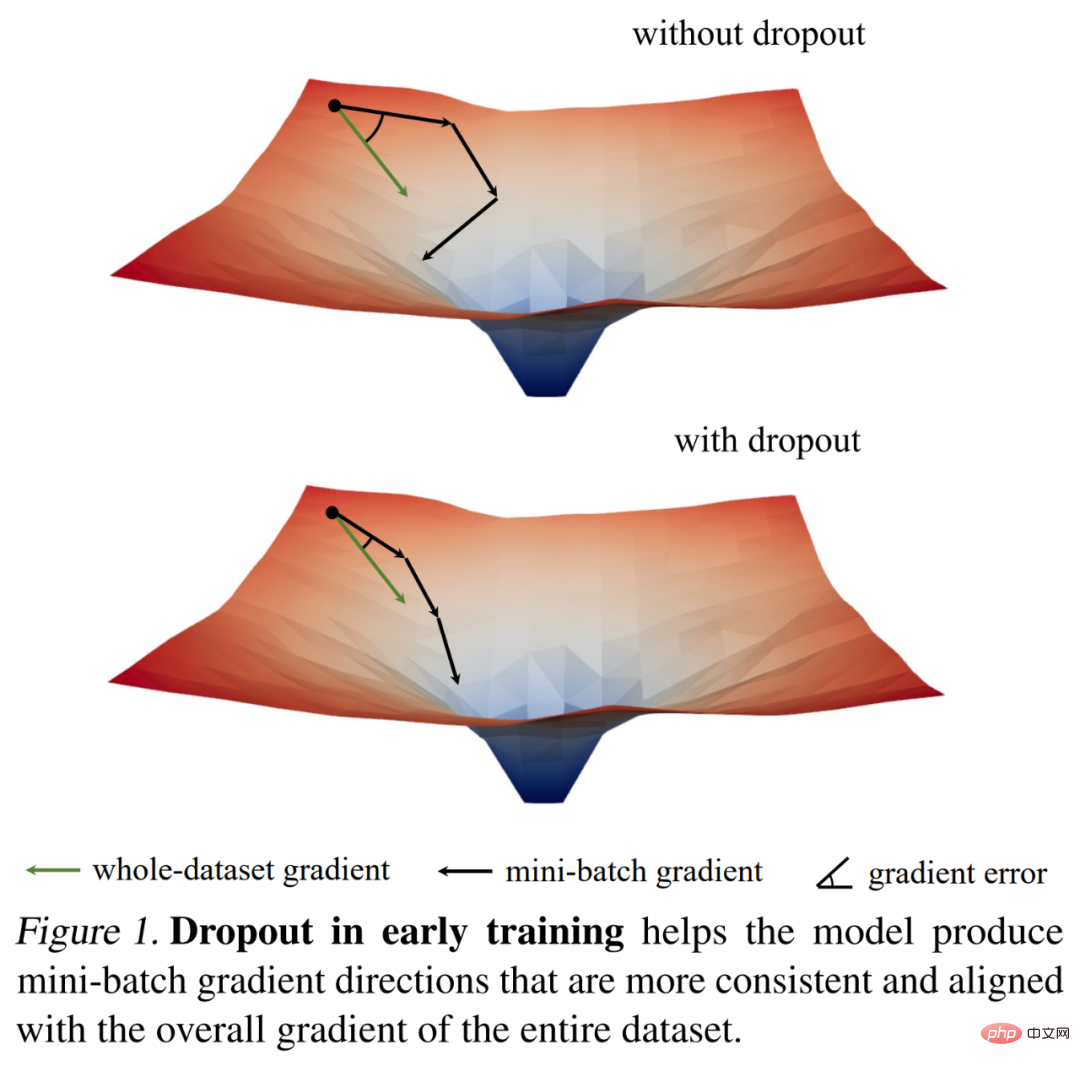
この発見に基づいて、研究者は早期ドロップアウトを提案しました(つまり、ドロップアウトはトレーニングの初期段階でのみ使用されます) ) 過小適合モデルの適合を促進します。早期ドロップアウトは、ドロップアウトなしおよび標準ドロップアウトと比較して、最終的なトレーニングの損失を軽減します。対照的に、すでに標準ドロップアウトを使用しているモデルの場合、研究者は、過学習を減らすために、初期のトレーニング エポックでドロップアウトを削除することを推奨しています。彼らはこの方法を遅延ドロップアウトと呼び、大規模モデルの汎化精度を向上できることを示しました。下の図 2 は、標準的な中退、早期中退、および後期中退を比較しています。

研究者は、画像分類と下流タスクでの早期ドロップアウトと後期ドロップアウトを評価するためにさまざまなモデルを使用し、結果は両方を示しました。標準的なドロップアウトまたはドロップアウトなしよりも、一貫して優れた結果が得られました。彼らは、その発見がドロップアウトと過学習に関する新たな洞察を提供し、ニューラル ネットワーク正則化器のさらなる開発を促すことを期待しています。
分析と検証
この研究では、早期ドロップアウトと後期ドロップアウトを提案する前に、アンダーフィッティングを軽減するツールとしてドロップアウトを使用できるかどうかを検討しました。この研究では、提案されたツールとメトリクスを使用してドロップアウトのトレーニングダイナミクスの詳細な分析を実行し、ImageNet 上の 2 つの ViT-T/16 のトレーニング プロセスを比較しました (Deng et al., 2009)。他の 1 つは、トレーニング全体を通じてドロップアウト率が 0.1 でした。
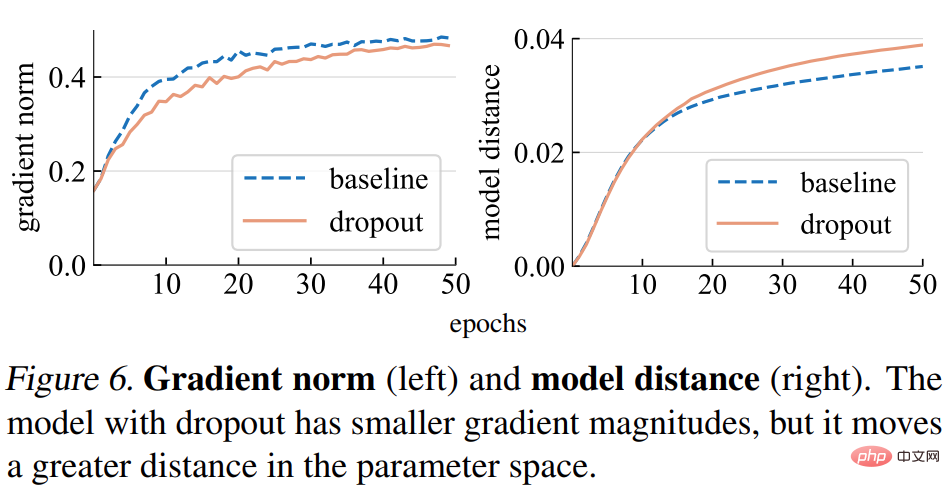
勾配ノルム (ノルム)。この研究ではまず、勾配 g の強度に対するドロップアウトの影響を分析します。下の図 6 (左) に示すように、ドロップアウト モデルはより小さいノルムの勾配を生成します。これは、勾配の更新ごとに小さなステップが必要であることを示しています。
モデルの距離。勾配ステップ サイズが小さいため、ドロップアウト モデルはベースライン モデルよりも初期点に対して相対的に小さい距離を移動すると予想されます。以下の図 6 (右) に示すように、この調査では、ランダムな初期化からの各モデルの距離がプロットされています。しかし、驚くべきことに、勾配ノルムに基づいて研究が当初予想していたものに反して、ドロップアウト モデルは実際にはベースライン モデルよりも大きな距離を移動しました。
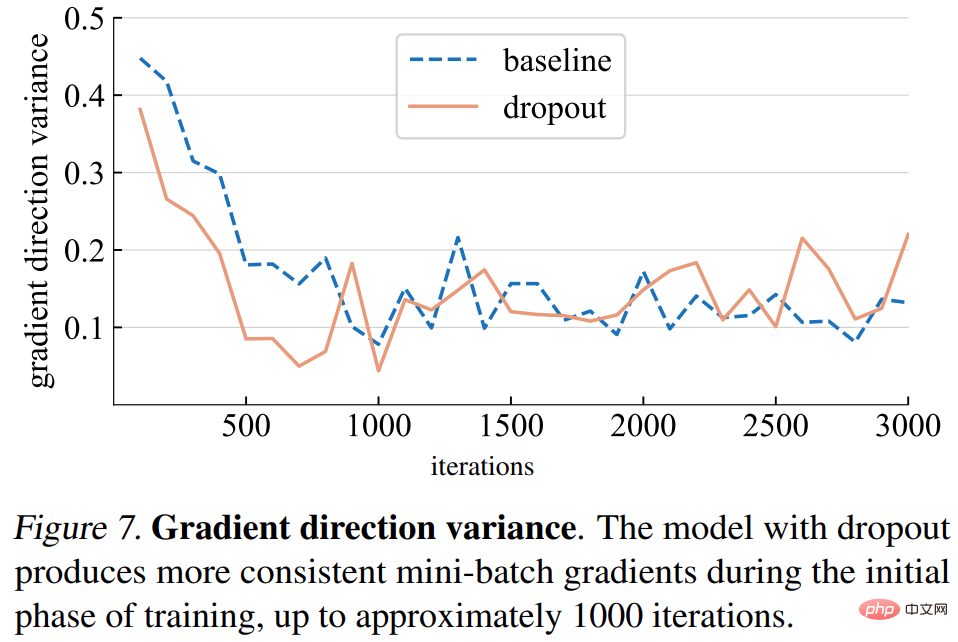
勾配方向の分散。研究ではまず、ドロップアウト モデルがミニバッチ全体でより一貫した勾配方向を生成するという仮説を立てています。以下の図 7 に示す分散は、概ね仮定と一致しています。一定の反復回数 (約 1000 回) までは、ドロップアウト モデルとベースライン モデルの両方の勾配分散は低いレベルで変動します。
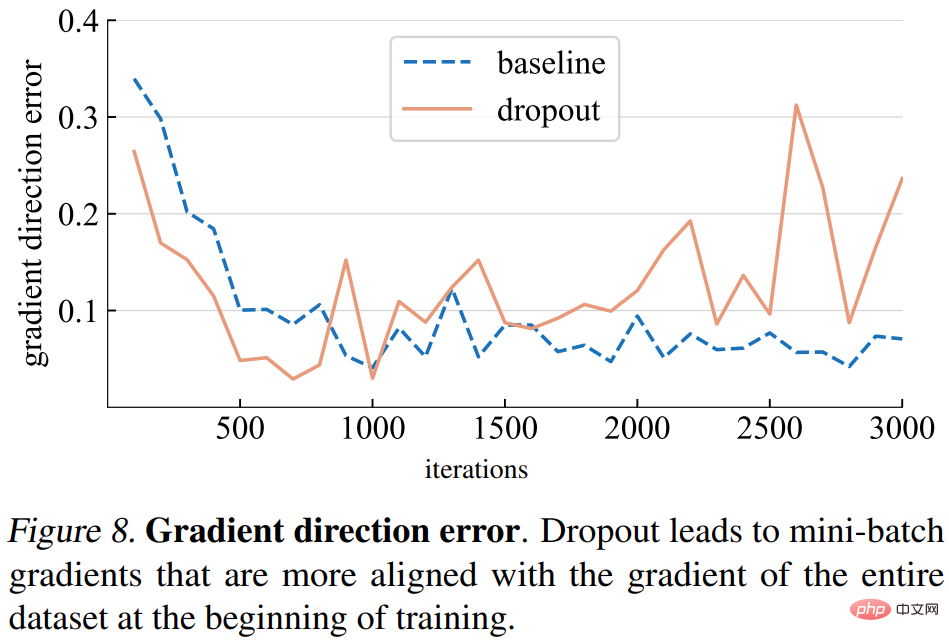
#グラデーション方向エラー。しかし、正しいグラデーションの方向はどうあるべきでしょうか?トレーニング データを適合させるための基本的な目標は、1 つのミニバッチの損失だけでなく、トレーニング セット全体の損失を最小限に抑えることです。このスタディでは、モデル全体の勾配を取得するためにドロップアウトを推論モードに設定して、トレーニング セット全体にわたる特定のモデルの勾配を計算します。勾配方向の誤差を以下の図 8 に示します。
上記の分析に基づいて、この研究では、できるだけ早期にドロップアウトを使用すると、モデルの能力を向上させる可能性があることがわかりました。トレーニングデータを当てはめます。トレーニング データにより適切に適合する必要があるかどうかは、モデルが過小適合しているか過適合しているかによって決まりますが、これを正確に定義するのは難しい場合があります。研究では次の基準を使用しました:
- #モデルが標準ドロップアウトの下でよりよく一般化する場合、それは過学習していると見なされます;
- ドロップアウトなしでモデルのパフォーマンスが向上した場合、そのモデルは適合不足であるとみなされます。
#モデルの状態は、モデル アーキテクチャだけでなく、使用されるデータセットやその他のトレーニング パラメーターにも依存します。
そして、この研究では、早期ドロップアウトと後期ドロップアウトという 2 つの方法が提案されました。
早期ドロップアウト。デフォルトでは、アンダーフィットモデルはドロップアウトを使用しません。トレーニング データに適応する能力を向上させるために、この研究では早期ドロップアウトを提案しています。つまり、特定の反復の前にドロップアウトを使用し、残りのトレーニング プロセスではドロップアウトを無効にするというものです。研究実験では、早期ドロップアウトにより最終的なトレーニングの損失が軽減され、精度が向上することが示されています。
後期中退。標準ドロップアウトは、過学習モデルのトレーニング設定にすでに含まれています。トレーニングの初期段階では、ドロップアウトにより誤って過剰適合が引き起こされる可能性があり、これは望ましくないことです。過学習を減らすために、この研究では後期ドロップアウトを提案しています。ドロップアウトは特定の反復の前には使用されませんが、残りのトレーニングでは使用されます。
この研究で提案された方法は、図 2 に示すように、概念と実装が単純です。実装には 2 つのハイパーパラメータが必要です: 1) ドロップアウトをオンまたはオフにする前に待機するエポック数、2) 標準のドロップアウト率に似たドロップ率 p。この研究は、これら 2 つのハイパーパラメータが提案された方法の堅牢性を保証できることを示しています。
実験と結果研究者らは、1000 クラスと 120 万枚のトレーニング画像を含む ImageNet-1K 分類データセットに対して実証的評価を実施し、トップ 1 の検証精度を報告しました。 。
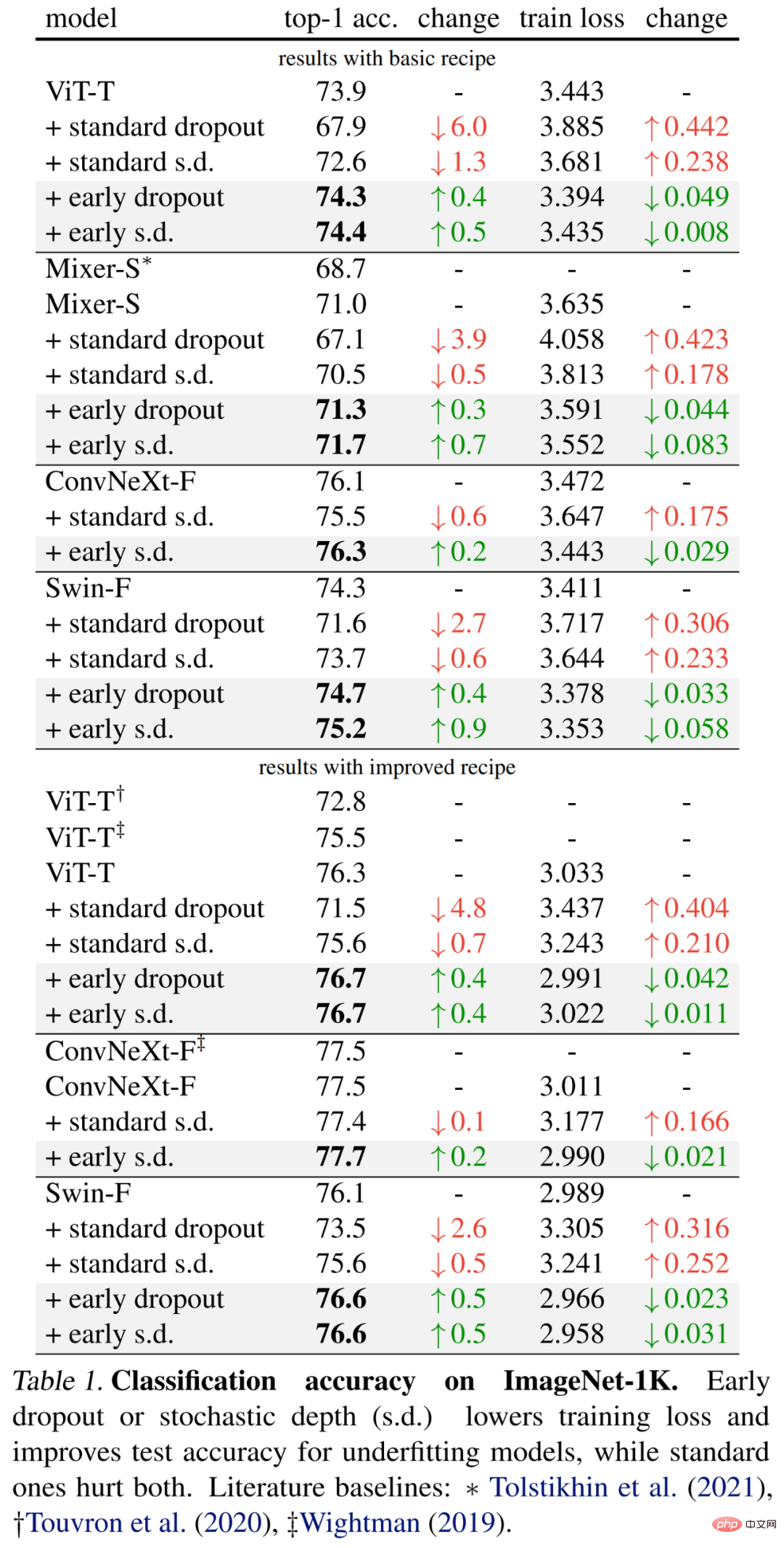
#具体的な結果は、以下の表 1 (上部) に最初に示されています。早期ドロップアウトによりテストの精度が向上し、トレーニング損失が減少し続けます。これは、初期段階でのドロップアウトがモデルの適合に役立つことを示しています。より良いデータ。研究者らはまた、ドロップ率 0.1 を使用した標準的なドロップアウトおよび確率的深さ (s.d.) との比較も示していますが、どちらもモデルに悪影響を及ぼします。さらに、研究者らは、トレーニング エポックを 2 倍にし、ミックスアップとカットミックスの強度を減らすことで、これらの小さなモデルの方法を改善しました。以下の表 1 (下) の結果は、ベースライン精度の大幅な向上を示しており、場合によっては以前の研究結果を大幅に上回っています。
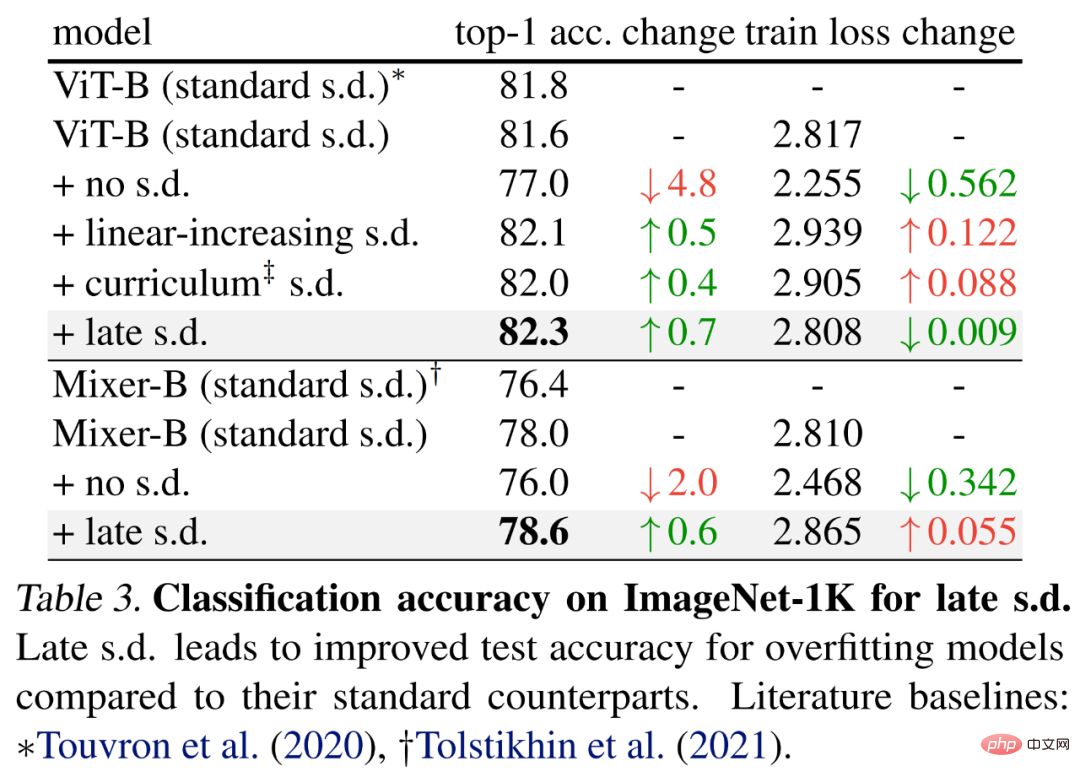
後期ドロップアウトを評価するために、研究者らは、基本的なパラメータを使用して、それぞれ 59M と 86M のパラメータを持つ ViT-B と Mixer-B というより大きなモデルを選択しました。トレーニング方法。
結果は以下の表 3 に示されており、標準 s.d. と比較して、後期 s.d. の方が検査精度が向上しています。この改善は、ViT-B を維持するか、Mixer-B トレーニング損失を増加させながら達成されており、後期 SD が過剰学習を効果的に軽減することを示しています。
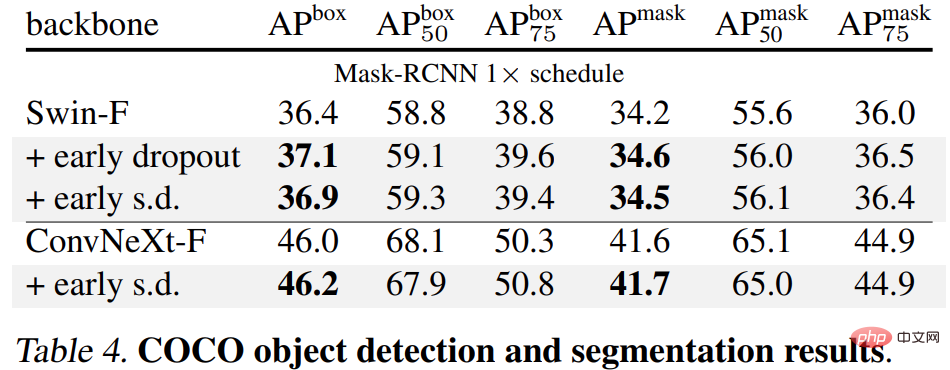
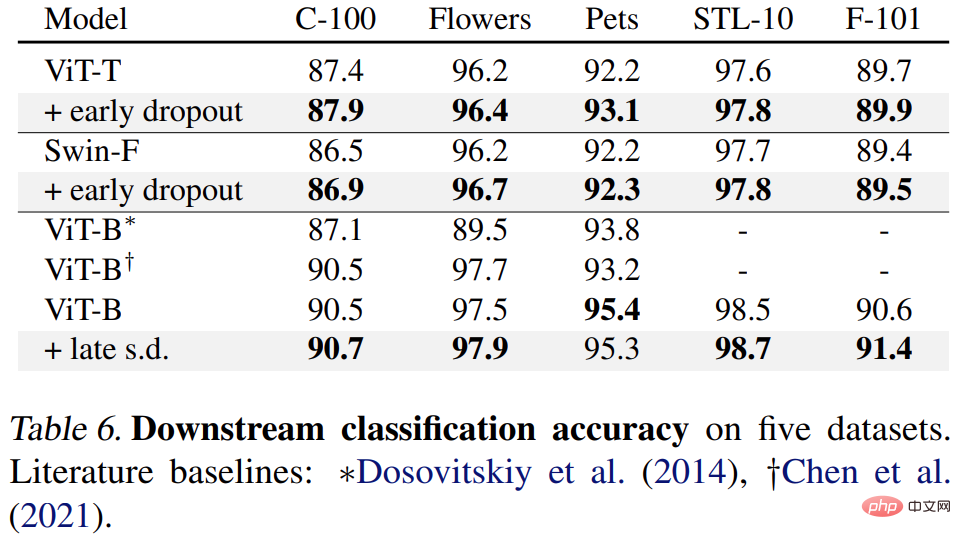
最後に、研究者らは、下流タスクで事前トレーニングされた ImageNet-1K モデルを微調整し、評価しました。下流タスクには、COCO オブジェクトの検出とセグメンテーション、ADE20K セマンティック セグメンテーション、C-100 を含む 5 つのデータセットの下流分類が含まれます。目標は、早期ドロップアウトや後期ドロップアウトを使用せずに、微調整フェーズ中に学習された表現を評価することです。
結果は以下の表 4、5、6 に示されています。まず、COCO で微調整すると、早期ドロップアウトまたは SD を使用して事前トレーニングされたモデルが常に優位性を維持します。
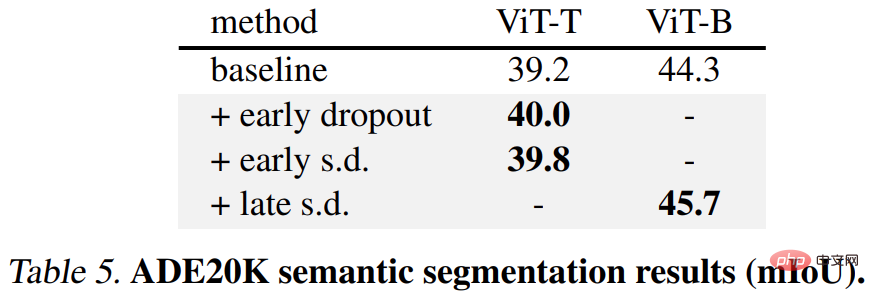
第 2 に、ADE20K セマンティック セグメンテーション タスクの場合、この方法を使用して事前トレーニングされたモデルはベースライン モデルよりも優れています。 。
#最後に、下流の分類タスクがあります。この方法により、ほとんどの分類タスクで汎化パフォーマンスが向上します。
以上が改良されたドロップアウトを使用すると、アンダーフィッティングの問題を軽減できます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。