



短編ビデオ レコメンデーション システムの中核的な目標は、ユーザー維持率を向上させて DAU の増加を促進することです。したがって、リテンションは各 APP の中核となるビジネス最適化指標の 1 つです。ただし、リテンションはユーザーとシステムの間の複数のインタラクションを経た後の長期的なフィードバックであり、それを単一の項目または単一のリストに分解することは困難であるため、従来のポイント単位およびリスト単位のモデルでは、直接フィードバックを取得することが困難です。保持を最適化します。
強化学習 (RL) 手法は、環境と対話することで長期的な報酬を最適化し、ユーザー維持率を直接最適化するのに適しています。この研究では、リテンション最適化問題を、無限のホライズン要求粒度を備えたマルコフ決定プロセス (MDP) としてモデル化しています。ユーザーが推奨システムにアクションを決定するよう要求するたびに、複数の異なる短期フィードバック推定値 (視聴期間、視聴時間、いいね、注目、コメント、リツイートなど)ランキングモデルのスコアリング。この作業の目標は、ポリシーを学習し、複数のユーザー セッション間の累積時間間隔を最小限に抑え、アプリを開く頻度を増やし、それによってユーザー維持率を高めることです。
ただし、保持された信号の特性により、既存の RL アルゴリズムを直接適用するには次の課題があります。 1) 不確実性: 保持された信号は推奨アルゴリズムだけによって決定されるわけではありません。 、しかし、多くの外部要因によっても干渉されます; 2) バイアス: 保持シグナルには、さまざまな期間およびさまざまなレベルのアクティビティを持つユーザー グループによって偏差があります; 3) 不安定性: 報酬がすぐに返されるゲーム環境とは異なり、保持シグナルは通常数時間以内に返されます。これにより、RL アルゴリズムがオンラインになり、トレーニングが不安定になる問題が発生します。
この研究では、上記の課題を解決し、ユーザー維持を直接最適化するためのユーザー維持のための強化学習 (RLUR) アルゴリズムを提案します。 RLUR アルゴリズムは、オフラインおよびオンライン検証を通じて、最先端のベースラインと比較して二次保持指数を大幅に向上させることができます。 RLUR アルゴリズムは Kuaishou アプリに完全に実装されており、継続的に大幅な二次リテンションと DAU 収益を達成することができます。RL テクノロジーが実際の運用環境でのユーザー リテンションの向上に使用されたのは業界初です。この作品は WWW 2023 Industry Track に採用されました。

著者: Cai Qingpeng、Liu Shuchang、Wang Xueliang、Zuo Tianyou、Xie Wentao、Yang Bin、Zheng Dong、Jiang Peng
#論文アドレス: https://arxiv.org/pdf/2302.01724.pdf##問題モデリング
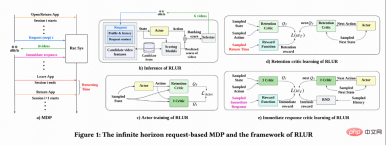
図 1(a) に示すように、この研究では、リテンション最適化問題を無限の地平線リクエストベースのマルコフ決定プロセスとしてモデル化します。このプロセスでは、推奨システムがエージェントであり、ユーザーが環境です。ユーザーがアプリを開くたびに、新しいセッション i が開かれます。図 1(b) に示すように、ユーザーが をリクエストするたびに、推奨システムはユーザーのステータス この研究では、最初に累積再訪問時間を推定する方法について説明し、次に、保持された信号のいくつかの重要な課題を解決する方法を提案します。これらの手法は、ユーザー維持のための強化学習アルゴリズム (RLUR と略称) にまとめられています。 #再訪問時間の推定 図 1(d) に示すように、動作は連続的であるため、この研究では、DDPG アルゴリズムの時間差 (TD) 学習方法を採用して再訪問時間を推定します。 各セッションの最後のリクエストのみに再訪問時間報酬があり、中間報酬は 0 であるため、作成者は割引係数 に基づいてパラメータ ベクトル
に基づいてパラメータ ベクトル  を決定します。 、n さまざまな短期指標 (視聴時間、いいね!、注目など) を推定するランキング モデルにより、各候補ビデオ j
を決定します。 、n さまざまな短期指標 (視聴時間、いいね!、注目など) を推定するランキング モデルにより、各候補ビデオ j がスコア付けされます。次に、並べ替え関数が各ビデオのアクションとスコア ベクトルを入力して各ビデオの最終スコアを取得し、最高スコアを持つ 6 つのビデオを選択してユーザーに表示します。ユーザーは即時にフィードバックを返します
がスコア付けされます。次に、並べ替え関数が各ビデオのアクションとスコア ベクトルを入力して各ビデオの最終スコアを取得し、最高スコアを持つ 6 つのビデオを選択してユーザーに表示します。ユーザーは即時にフィードバックを返します 。ユーザーがアプリを離れると、このセッションは終了します。次にユーザーがアプリを開いたときに、セッション i 1 が開きます。前のセッションの終了と次のセッションの開始の間の時間間隔は、復帰時間 (復帰時間) と呼ばれます。 )、
。ユーザーがアプリを離れると、このセッションは終了します。次にユーザーがアプリを開いたときに、セッション i 1 が開きます。前のセッションの終了と次のセッションの開始の間の時間間隔は、復帰時間 (復帰時間) と呼ばれます。 )、 。この研究の目標は、複数のセッションのコールバック時間の合計を最小限に抑える戦略をトレーニングすることです。
。この研究の目標は、複数のセッションのコールバック時間の合計を最小限に抑える戦略をトレーニングすることです。 
RLUR アルゴリズム

 各セッションの最後のリクエストの値は
各セッションの最後のリクエストの値は  で、他のリクエストの値は 1 です。この設定により、再訪問時間の指数関数的な減衰を回避できます。そして、損失 (1) が 0 の場合、Q は実際に複数のセッションの累積復帰時間
で、他のリクエストの値は 1 です。この設定により、再訪問時間の指数関数的な減衰を回避できます。そして、損失 (1) が 0 の場合、Q は実際に複数のセッションの累積復帰時間  を推定することが理論的に証明できます。
を推定することが理論的に証明できます。
報酬遅延の問題を解決する
再訪問時間は次の時点でのみ発生するため、各セッションの終了が遅くなり、学習効率が低下するという問題が生じます。したがって、著者らはヒューリスティック報酬を使用してポリシー学習を強化します。短期フィードバックは定着率にプラスの関係があるため、著者は短期フィードバックを最初のヒューリスティック報酬として使用します。そして著者は、ランダム ネットワーク蒸留 (RND) ネットワークを採用して、2 番目のヒューリスティック報酬として各サンプルの固有報酬を計算します。具体的には、RND ネットワークは 2 つの同一のネットワーク構造を使用しており、一方のネットワークはランダムに固定に初期化され、もう一方のネットワークは固定ネットワークに適合し、フィッティング損失が固有の報酬として使用されます。図 1(e) に示すように、保持報酬に対するヒューリスティック報酬の干渉を減らすために、この研究では別の批評家ネットワークを学習して、短期フィードバックと本質的報酬の合計を推定します。今すぐ #########。 
復帰時期により多くの推奨事項を受け取りました訪問 要因の影響により不確実性が高く、学習効果に影響を与えます。この研究では、分散を減らすための正則化方法を提案しています。最初に分類モデル
を推定して、再診時間の確率、つまり、推定された再診時間が より短いかどうかを推定します。  ; 次に、マルコフの不等式を使用して再診時間の下限を取得します。
; 次に、マルコフの不等式を使用して再診時間の下限を取得します。  ; 最後に、実際の再診時間/推定再診時間の下限を正規化された再診報酬として使用します。 。
; 最後に、実際の再診時間/推定再診時間の下限を正規化された再診報酬として使用します。 。 
アクティブなグループごとに行動習慣が大きく異なるため、非常にアクティブなユーザー 維持率が高く、トレーニング サンプルの数が低アクティブ ユーザーよりも大幅に多いため、モデル学習が高アクティブ ユーザーによって支配されることになります。この問題を解決するために、この研究では、高アクティビティと低アクティビティの異なるグループに対して 2 つの独立した戦略を学習し、トレーニングに異なるデータ ストリームを使用し、アクターは補助報酬を最大化しながら再訪問時間を最小限に抑えます。図 1(c) に示すように、高アクティビティ グループを例にとると、アクターの損失は次のようになります。

#不安定性の問題の解決
リターン信号遅延による訪問時間は通常、数時間から数日以内に戻ります。これにより、RL オンライン トレーニングが不安定になる可能性があります。既存の動作複製手法を直接使用すると、学習速度が大幅に制限されるか、安定した学習が保証されません。したがって、この研究では、新しいソフト正則化方法、つまりアクター損失にソフト正則化係数を乗算する方法を提案します。 #この正則化手法は本質的にブレーキ効果です。現在の学習戦略とサンプル戦略が大きく乖離している場合、損失は小さくなり、学習は安定する傾向があります。学習速度が安定している傾向がある場合、損失は減少します。大きくなればなるほど、学ぶのは早くなります。
の場合、学習プロセスに制限がないことを意味します。
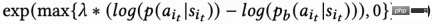
この研究では、RLUR と最先端の強化学習アルゴリズム TD3、およびブラックボックス最適化手法クロス エントロピー法 ( CEM) の公開データセット KuaiRand が比較に使用されます。この作業では、最初に KuaiRand データ セットに基づいてリテンション シミュレーターを構築します。これには、ユーザーの即時フィードバック、ユーザーのセッションからの退出、ユーザーのアプリへの再訪問という 3 つのモジュールが含まれており、次にリテンション シミュレーターのメソッドを評価します。 
#表 1 は、再訪問時間と二次リテンション指標の点で、RLUR が CEM や TD3 よりも大幅に優れていることを示しています。この研究では、アブレーション実験を実施して、RLUR を保持学習部分のみ (RLUR (naive)) と比較します。これは、保持の課題を解決するためのこの研究のアプローチの有効性を示すことができます。そして、
と
を比較すると、複数のセッションの再訪問時間を最小化するアルゴリズムの方が、セッションの再訪問時間を最小化するよりも優れていることが示されています。シングルセッション。 
オンライン実験
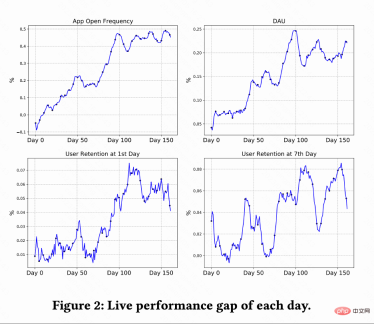
 この作業では、Kuaishou ショートビデオ レコメンデーション システムで A/B テストを実施し、RLUR を比較します。および CEM メソッド。図 2 は、RLUR と CEM とそれぞれ比較した、アプリの起動頻度、DAU、初回保持率、および 7 回目の保持率の改善率を示しています。アプリを開く頻度は徐々に増加し、0 日から 100 日にかけて収束することもあります。また、2 番目の保持率、7 番目の保持率、および DAU 指標の改善も促進します (0.1% の DAU と 2 番目の保持率の 0.01% の改善は、統計的に有意であると考えられます)。
この作業では、Kuaishou ショートビデオ レコメンデーション システムで A/B テストを実施し、RLUR を比較します。および CEM メソッド。図 2 は、RLUR と CEM とそれぞれ比較した、アプリの起動頻度、DAU、初回保持率、および 7 回目の保持率の改善率を示しています。アプリを開く頻度は徐々に増加し、0 日から 100 日にかけて収束することもあります。また、2 番目の保持率、7 番目の保持率、および DAU 指標の改善も促進します (0.1% の DAU と 2 番目の保持率の 0.01% の改善は、統計的に有意であると考えられます)。
以上がKuaishou ユーザー維持率を向上させるために強化学習を使用する方法は?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM
AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM「AI-Ready労働力」という用語は頻繁に使用されますが、サプライチェーン業界ではどういう意味ですか? サプライチェーン管理協会(ASCM)のCEOであるAbe Eshkenaziによると、批評家ができる専門家を意味します
 1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM
1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM分散型AI革命は静かに勢いを増しています。 今週の金曜日、テキサス州オースティンでは、ビテンサーのエンドゲームサミットは極めて重要な瞬間を示し、理論から実用的な応用に分散したAI(DEAI)を移行します。 派手なコマーシャルとは異なり
 Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AM
Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AMエンタープライズAIはデータ統合の課題に直面しています エンタープライズAIの適用は、ビジネスデータを継続的に学習することで正確性と実用性を維持できるシステムを構築する大きな課題に直面しています。 NEMOマイクロサービスは、NVIDIAが「データフライホイール」と呼んでいるものを作成することにより、この問題を解決し、AIシステムがエンタープライズ情報とユーザーインタラクションへの継続的な露出を通じて関連性を維持できるようにします。 この新しく発売されたツールキットには、5つの重要なマイクロサービスが含まれています。 NEMOカスタマイザーは、より高いトレーニングスループットを備えた大規模な言語モデルの微調整を処理します。 NEMO評価者は、カスタムベンチマークのAIモデルの簡素化された評価を提供します。 Nemo Guardrailsは、コンプライアンスと適切性を維持するためにセキュリティ管理を実装しています
 aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AM
aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AMAI:芸術とデザインの未来 人工知能(AI)は、前例のない方法で芸術とデザインの分野を変えており、その影響はもはやアマチュアに限定されませんが、より深く影響を与えています。 AIによって生成されたアートワークとデザインスキームは、広告、ソーシャルメディアの画像生成、Webデザインなど、多くのトランザクションデザインアクティビティで従来の素材画像とデザイナーに迅速に置き換えられています。 ただし、プロのアーティストやデザイナーもAIの実用的な価値を見つけています。 AIを補助ツールとして使用して、新しい美的可能性を探求し、さまざまなスタイルをブレンドし、新しい視覚効果を作成します。 AIは、アーティストやデザイナーが繰り返しタスクを自動化し、さまざまなデザイン要素を提案し、創造的な入力を提供するのを支援します。 AIはスタイル転送をサポートします。これは、画像のスタイルを適用することです
 エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM
エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM最初はビデオ会議プラットフォームで知られていたZoomは、エージェントAIの革新的な使用で職場革命をリードしています。 ZoomのCTOであるXD Huangとの最近の会話は、同社の野心的なビジョンを明らかにしました。 エージェントAIの定義 huang d
 大学に対する実存的な脅威Apr 26, 2025 am 11:08 AM
大学に対する実存的な脅威Apr 26, 2025 am 11:08 AMAIは教育に革命をもたらしますか? この質問は、教育者と利害関係者の間で深刻な反省を促しています。 AIの教育への統合は、機会と課題の両方をもたらします。 Tech Edvocate NotesのMatthew Lynch、Universitとして
 プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM
プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM米国における科学的研究と技術の開発は、おそらく予算削減のために課題に直面する可能性があります。 Natureによると、海外の雇用を申請するアメリカの科学者の数は、2024年の同じ期間と比較して、2025年1月から3月まで32%増加しました。以前の世論調査では、調査した研究者の75%がヨーロッパとカナダでの仕事の検索を検討していることが示されました。 NIHとNSFの助成金は過去数か月で終了し、NIHの新しい助成金は今年約23億ドル減少し、3分の1近く減少しました。リークされた予算の提案は、トランプ政権が科学機関の予算を急激に削減していることを検討しており、最大50%の削減の可能性があることを示しています。 基礎研究の分野での混乱は、米国の主要な利点の1つである海外の才能を引き付けることにも影響を与えています。 35
 オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AM
オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AMOpenaiは、強力なGPT-4.1シリーズを発表しました。実際のアプリケーション向けに設計された3つの高度な言語モデルのファミリー。 この大幅な飛躍は、より速い応答時間、理解の強化、およびTと比較した大幅に削減されたコストを提供します


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

SublimeText3 中国語版
中国語版、とても使いやすい
ホットトピック
 7739
7739 15164314139752129025123329
15164314139752129025123329