
ホームページ >バックエンド開発 >Python チュートリアル >Python の pandas ライブラリを使用してマルチレベル インデックス (MultiIndex) を作成するにはどうすればよいですか?
Python の pandas ライブラリを使用してマルチレベル インデックス (MultiIndex) を作成するにはどうすればよいですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-07 14:55:082948ブラウズ
はじめに
pd.MultiIndex、複数のレベルを持つインデックス。マルチレベルのインデックスを通じて、インデックス グループ全体のデータを操作できます。この記事では主に、Pandas でマルチレベル インデックスを作成する 6 つの方法を紹介します。
pd.MultiIndex.from_arrays(): 多次元配列はパラメータとして使用され、高次元は高レベルを指定します。インデックス、および低次元は低レベルのインデックスを指定します。
pd.MultiIndex.from_tuples(): 引数としてのタプルのリスト。各タプルは各インデックス (高次元および低次元のインデックス) を指定します。
pd.MultiIndex.from_product(): 複数の反復可能なオブジェクト要素インデックスのデカルト積 (要素のペアの組み合わせ) に基づいて作成される、パラメーターとしての反復可能なオブジェクトのリスト。
pd.MultiIndex.from_frame: 既存のデータ フレームに基づいて直接生成
-
groupby(): データ グループ化統計を通じて取得
pivot_table(): ピボット テーブルを生成して、
pd.MultiIndex.from_arrays()
In [1] :
import pandas as pd import numpy as np
は配列を通じて生成され、通常はリスト内の要素を指定します。
In [2]:
# 列表元素是字符串和数字
array1 = [["xiaoming","guanyu","zhangfei"],
[22,25,27]
]
m1 = pd.MultiIndex.from_arrays(array1)
m1Out[2]:
MultiIndex([('xiaoming', 22), ( 'guanyu', 25), ('zhangfei', 27)],
)[3]:
type(m1) # 查看数据类型
で type 関数を使用してデータ型をチェックし、それが実際であることを確認します。 MultiIndex
Out[3]:
pandas.core.indexes.multi.MultiIndex
が作成されます。同時に、各レベルの名前を指定できます。
In [4]:
# 列表元素全是字符串
array2 = [["xiaoming","guanyu","zhangfei"],
["male","male","female"]
]
m2 = pd.MultiIndex.from_arrays(
array2,
# 指定姓名和性别
names=["name","sex"])
m2Out[4]:
MultiIndex([('xiaoming', 'male'), ( 'guanyu', 'male'), ('zhangfei', 'female')],
names=['name', 'sex'])次の例では、次のインデックスを生成します。 3 つのレベルと名前の指定:
In [5]:
array3 = [["xiaoming","guanyu","zhangfei"],
["male","male","female"],
[22,25,27]
]
m3 = pd.MultiIndex.from_arrays(
array3,
names=["姓名","性别","年龄"])
m3Out[5]:
MultiIndex([('xiaoming', 'male', 22), ( 'guanyu', 'male', 25), ('zhangfei', 'female', 27)],
names=['姓名', '性别', '年龄'])pd.MultiIndex.from_tuples()
Throughタプル マルチレベル インデックスを次の形式で生成するには:
In [6]:
# 元组的形式
array4 = (("xiaoming","guanyu","zhangfei"),
(22,25,27)
)
m4 = pd.MultiIndex.from_arrays(array4)
m4Out[6]:
MultiIndex([('xiaoming', 22), ( 'guanyu', 25), ('zhangfei', 27)],
)In [7]:
# 元组构成的3层索引
array5 = (("xiaoming","guanyu","zhangfei"),
("male","male","female"),
(22,25,27))
m5 = pd.MultiIndex.from_arrays(array5)
m5 Out [7]:
MultiIndex([('xiaoming', 'male', 22), ( 'guanyu', 'male', 25), ('zhangfei', 'female', 27)],
)リストとタプルは混在できます。
最外層はリストです
すべてはタプルです
In [8]:
array6 = [("xiaoming","guanyu","zhangfei"),
("male","male","female"),
(18,35,27)
]
# 指定名字
m6 = pd.MultiIndex.from_arrays(array6,names=["姓名","性别","年龄"])
m6Out[8]:
MultiIndex([('xiaoming', 'male', 18), ( 'guanyu', 'male', 35), ('zhangfei', 'female', 27)],
names=['姓名', '性别', '年龄'] # 指定名字
)pd.MultiIndex.from_product()
反復可能なオブジェクトのリストをパラメーターとして使用して、複数の反復可能なオブジェクト要素 (要素のペアの組み合わせ) のデカルト積に基づいてインデックスを作成します。
Python では、isinstance() 関数を使用して、Python オブジェクトが反復可能かどうかを判断します。
# 导入 collections 模块的 Iterable 对比对象 from collections import Iterable


上記の例を通じて、次のことを要約します。共通の文字列、リスト、セット、タプル、および辞書はすべて反復可能なオブジェクトです。
次の例は、説明のために示しています。 18 ]:
names = ["xiaoming","guanyu","zhangfei"]
numbers = [22,25]
m7 = pd.MultiIndex.from_product(
[names, numbers],
names=["name","number"]) # 指定名字
m7アウト[18]:
MultiIndex([('xiaoming', 22), ('xiaoming', 25), ( 'guanyu', 22), ( 'guanyu', 25), ('zhangfei', 22), ('zhangfei', 25)],
names=['name', 'number'])イン[19]:
# 需要展开成列表形式
strings = list("abc")
lists = [1,2]
m8 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m8アウト[19]:
MultiIndex([('a', 1), ('a', 2), ('b', 1), ('b', 2), ('c', 1), ('c', 2)],
names=['alpha', 'number'])イン[20] :
# 使用元组形式
strings = ("a","b","c")
lists = [1,2]
m9 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m9アウト[20]:
MultiIndex([('a', 1), ('a', 2), ('b', 1), ('b', 2), ('c', 1), ('c', 2)],
names=['alpha', 'number'])イン[21]:
# 使用range函数
strings = ("a","b","c") # 3个元素
lists = range(3) # 0,1,2 3个元素
m10 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m10アウト[21]:
MultiIndex([('a', 0), ('a', 1), ('a', 2), ('b', 0), ('b', 1), ('b', 2), ('c', 0), ('c', 1), ('c', 2)],
names=['alpha', 'number'])イン[22]:
# 使用range函数
strings = ("a","b","c")
list1 = range(3) # 0,1,2
list2 = ["x","y"]
m11 = pd.MultiIndex.from_product(
[strings, list1, list2],
names=["name","l1","l2"]
)
m11 # 总个数 3*3*2=18合計数は「332=18」です:
Out[22]:
MultiIndex([('a', 0, 'x'), ('a', 0, 'y'), ('a', 1, 'x'), ('a', 1, 'y'), ('a', 2, 'x'), ('a', 2, 'y'), ('b', 0, 'x'), ('b', 0, 'y'), ('b', 1, 'x'), ('b', 1, 'y'), ('b', 2, 'x'), ('b', 2, 'y'), ('c', 0, 'x'), ('c', 0, 'y'), ('c', 1, 'x'), ('c', 1, 'y'), ('c', 2, 'x'), ('c', 2, 'y')],
names=['name', 'l1', 'l2'])pd.MultiIndex.from_frame()
By current一部のデータフレームはマルチレベル インデックスを直接生成します:
df = pd.DataFrame({"name":["xiaoming","guanyu","zhaoyun"],
"age":[23,39,34],
"sex":["male","male","female"]})
df
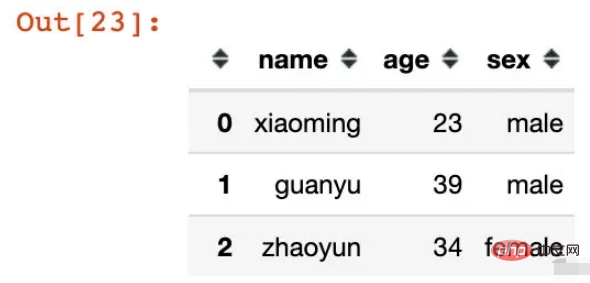 マルチレベル インデックスは直接生成され、名前は既存のデータ フレームの列フィールドです:
マルチレベル インデックスは直接生成され、名前は既存のデータ フレームの列フィールドです:
In [24]:
pd.MultiIndex.from_frame(df)
Out[24]:
MultiIndex([('xiaoming', 23, 'male'), ( 'guanyu', 39, 'male'), ( 'zhaoyun', 34, 'female')],
names=['name', 'age', 'sex'])names パラメータで名前を指定します:
In [25]:
# 可以自定义名字 pd.MultiIndex.from_frame(df,names=["col1","col2","col3"])
Out[ 25]:
MultiIndex([('xiaoming', 23, 'male'), ( 'guanyu', 39, 'male'), ( 'zhaoyun', 34, 'female')],
names=['col1', 'col2', 'col3'])groupby()
は、groupby 関数のグループ化関数によって計算されます:
In [26]:
df1 = pd.DataFrame({"col1":list("ababbc"),
"col2":list("xxyyzz"),
"number1":range(90,96),
"number2":range(100,106)})
df1 Out[26] :
df2 = df1.groupby(["col1","col2"]).agg({"number1":sum,
"number2":np.mean})
df2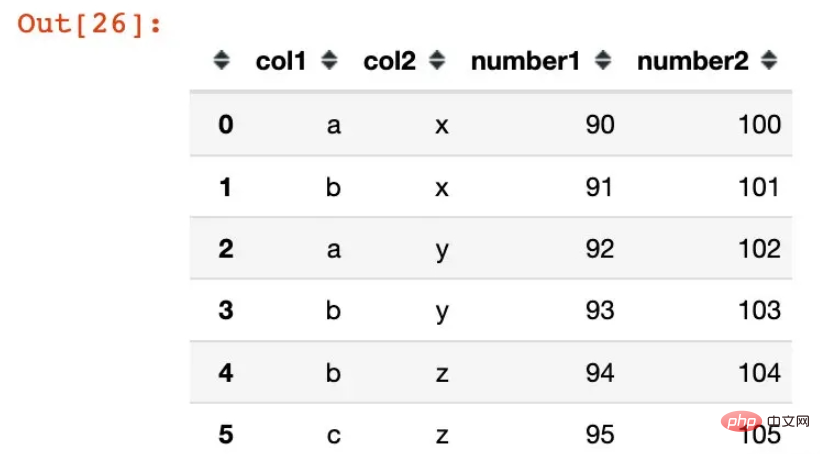
 データのインデックスを表示します:
データのインデックスを表示します:
In [28] :
df2.index
Out [28]:
MultiIndex([('a', 'x'), ('a', 'y'), ('b', 'x'), ('b', 'y'), ('b', 'z'), ('c', 'z')],
names=['col1', 'col2'])pivot_table()
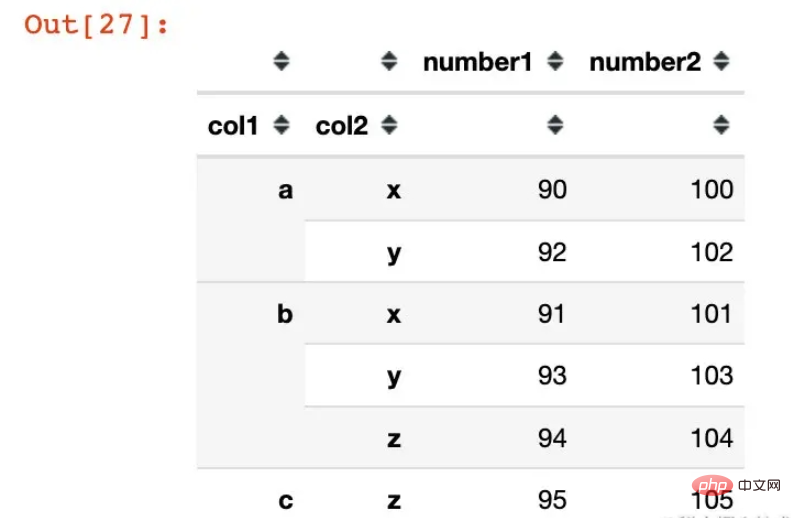
データ ピボット関数によって取得:
In [29]:
df3 = df1.pivot_table(values=["col1","col2"],index=["col1","col2"]) df3
 イン [30]:
イン [30]:
df3.index
アウト[30]:
MultiIndex([('a', 'x'), ('a', 'y'), ('b', 'x'), ('b', 'y'), ('b', 'z'), ('c', 'z')],
names=['col1', 'col2'])以上がPython の pandas ライブラリを使用してマルチレベル インデックス (MultiIndex) を作成するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。