
ホームページ >Java >&#&チュートリアル >Javaでのハッシュテーブルの解析例
Javaでのハッシュテーブルの解析例

- 王林転載
- 2023-05-06 09:10:07740ブラウズ
1、概念
シーケンシャル構造やバランスツリーでは、要素キーコードとその格納場所に対応関係がないため、検索時に要素については、キー コードの複数の比較を行う必要があります。逐次検索の時間計算量は O(N) です。バランスのとれたツリーでは、それは木の高さ、つまり O( ) です。検索の効率は、検索プロセス中の要素の比較の数に依存します。
理想的な検索方法: 比較することなく、検索対象の要素をテーブルから一度に直接取得できます。格納構造を構築し、特定の関数 (hashFunc) を使用して要素の格納場所とそのキー コードの間に 1 対 1 のマッピング関係を確立すると、検索時にこの関数を通じて要素を迅速に見つけることができます。
この構造体に要素を挿入する場合:
この関数は、挿入する要素のキーコードに基づいて、要素の格納場所を計算し、その場所に従って格納します。
##要素の検索要素のキーコードに対して同じ計算を実行し、得られた関数値を要素の格納場所として扱い、構造内のこの位置に従って要素を比較します。キー コードが等しい場合、検索は成功します。例: データ セット {1, 7, 6, 4, 5, 9};ハッシュ関数は次のように設定されます。 hash(key) = key % 容量; 容量 要素を格納するための基礎となる領域の合計サイズです。2、競合の回避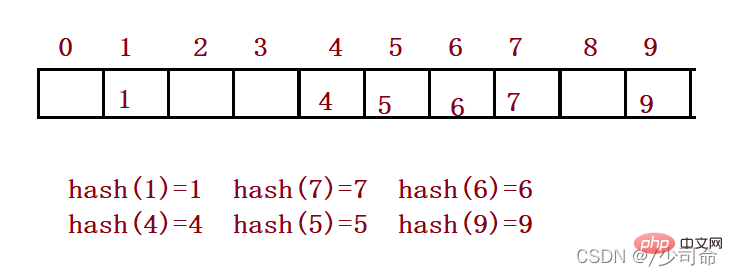 ###まず、ハッシュ テーブルの基になる配列の容量は多くの場合、実際に格納するキーよりも小さい 単語数が問題となる 競合の発生は避けられませんが、できる限り競合率を下げることが考えられます。
###まず、ハッシュ テーブルの基になる配列の容量は多くの場合、実際に格納するキーよりも小さい 単語数が問題となる 競合の発生は避けられませんが、できる限り競合率を下げることが考えられます。
3、競合回避ハッシュ関数の設計
一般的なハッシュ関数
直接カスタマイズ方法 -- (一般的に使用される)
キーワードを取るある線形関数はハッシュアドレスです: Hash (Key) = A*Key B 長所: シンプルで均一 短所: キーワードの分布を事前に知る必要がある 使用シナリオ: 比較的小規模で連続的な状況を見つけるのに適しています
で除算剰余法 -- (一般的に使用される)
ハッシュ テーブルで許可されるアドレスの数が m であると仮定し、m より大きくなく、m に最も近い素数 p を約数として取ります。 、ハッシュ関数に従って: Hash (key) = key% p(p#真ん中の方法を 2 乗する --(理解)
キーが 1234 で、その 2 乗が 1522756 で、中央の 3 桁の 227 がハッシュ アドレスとして抽出されるとします。別の例は、キーワード 4321 で、その 2 乗が 18671041 で、中央の 3 桁の 671 (または 710) は次のようになります。二乗法が適している:キーワードの分布が不明、ビット数もそれほど多くない#4、競合回避負荷率調整
負荷率と競合率間の関係の大まかなデモンストレーション
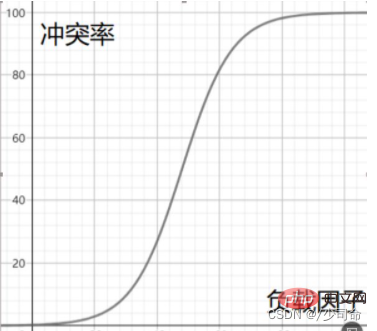 クローズド ハッシュ: オープン アドレッシング方式とも呼ばれます。ハッシュの競合が発生したときに、ハッシュ テーブルがいっぱいでない場合、ハッシュ テーブルがいっぱいになっていることを意味します。ギリシャ語テーブルには空の位置が存在する必要があるため、競合する位置の「次の」空の位置にキーを格納できます。
クローズド ハッシュ: オープン アドレッシング方式とも呼ばれます。ハッシュの競合が発生したときに、ハッシュ テーブルがいっぱいでない場合、ハッシュ テーブルがいっぱいになっていることを意味します。ギリシャ語テーブルには空の位置が存在する必要があるため、競合する位置の「次の」空の位置にキーを格納できます。
①線形検出
たとえば、上記のシナリオでは、要素 44 を挿入する必要があります。まず、ハッシュ関数を通じてハッシュ アドレスを計算します。添字は 4 なので、理論的には 44 になるはずですがこの位置に挿入されるはずですが、値 4 の要素がすでにこの位置に配置されているため、ハッシュの競合が発生します。線形検出: 競合が発生した位置から開始して、次の空き位置が見つかるまで逆方向に検出します。
Insert
ハッシュ関数を使用して、ハッシュテーブルに挿入する要素の位置を取得します。その位置に要素がない場合は、新しい要素を直接挿入します。その位置に要素があると、ハッシュの競合が発生します。線形検出を使用して次の空の位置を見つけ、新しい要素を挿入します。
クローズド ハッシュを使用してハッシュの競合を処理する場合、ハッシュ テーブル内の既存の要素を物理的に削除することはできません。要素を直接削除すると、他の要素の検索に影響します。たとえば、要素 4 を直接削除すると、44 の検索が影響を受ける可能性があります。したがって、線形プローブでは、マークされた擬似削除を使用して要素を削除します。②2 番目の検出
線形検出の欠点は、空の位置を 1 つずつ見つける方法であるため、次の空の位置を見つけることに関係する、矛盾するデータが一緒に蓄積することです。二次検出でこの問題を回避するために、次の空き位置を見つける方法は次のとおりです: = ( )% m または: = ( - )% m。このうち、i = 1,2,3... は要素のキー コード上でハッシュ関数 Hash(x) によって計算される位置、m はテーブルのサイズです。 2.1 の場合、44 を挿入したい場合、競合が発生します。解決策を使用した後の状況は次のとおりです。
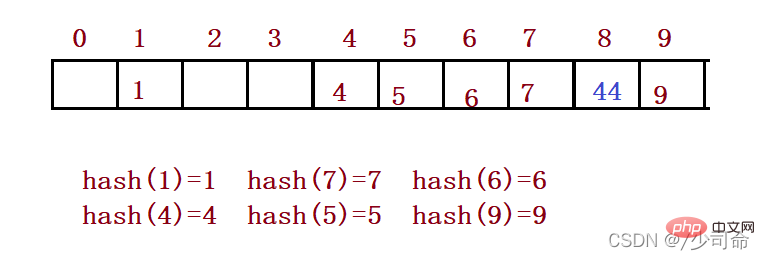
研究によると、テーブルの長さが素数の場合、テーブルの読み込み係数 a が 0.5 を超えない場合、新しいエントリは確実に挿入され、位置が 2 回プローブされることはありません。したがって、テーブルに半分の空きポジションがある限り、テーブルがいっぱいになる問題は発生しません。検索時は表が満杯であることを考慮する必要はありませんが、挿入時は表の負荷率aが0.5を超えないようにする必要があり、超えた場合は容量の増加を検討する必要があります。
6、競合解決-オープンハッシュ/ハッシュバケット
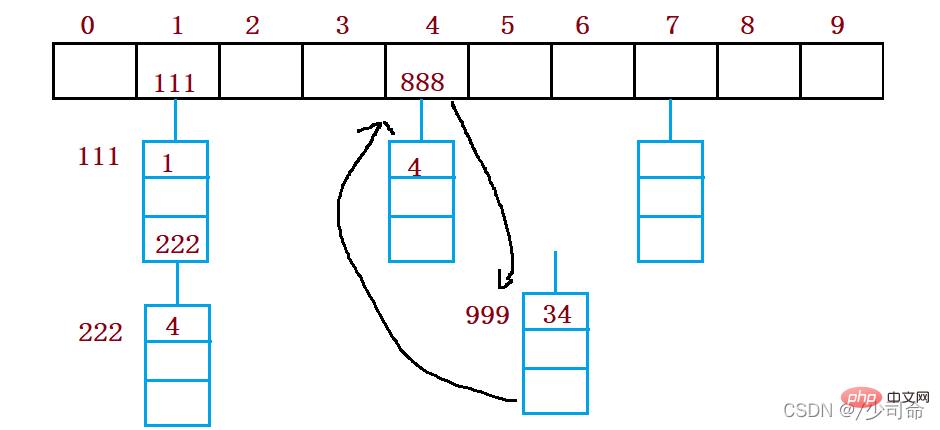
オープンハッシュ法はチェーンアドレス法(オープンチェーン法)とも呼ばれ、まずハッシュ関数を使って、キー コード セット ハッシュ アドレス 同じアドレスを持つキー コードは同じサブセットに属します 各サブセットはバケットと呼ばれます 各バケット内の要素は単一リンク リストを通じてリンクされます 各リンク リストのヘッド ノードハッシュテーブルに保存されます。

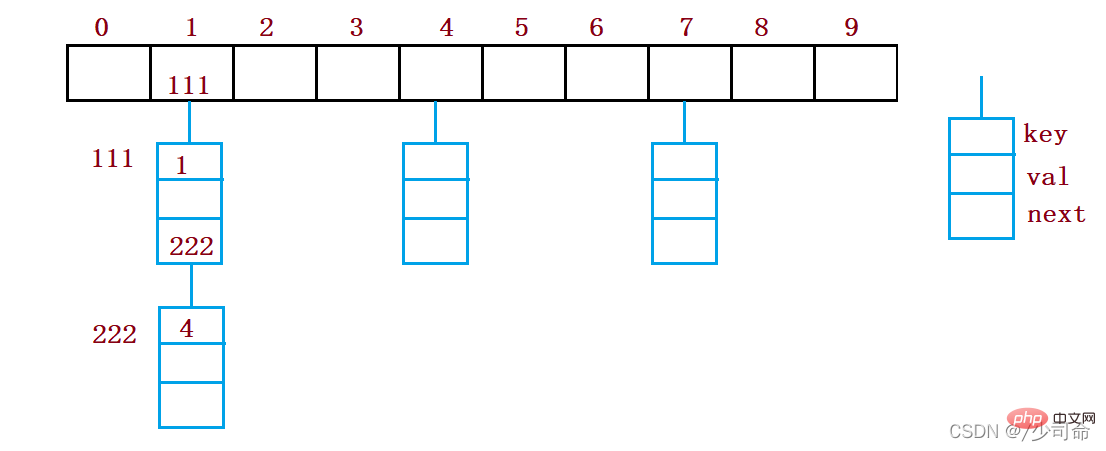
static class Node {
public int key;
public int val;
public Node next;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
}
private Node[] array;
public int usedSize;
public HashBucket() {
this.array = new Node[10];
this.usedSize = 0;
}
 ##rrreerrree
##rrreerrree
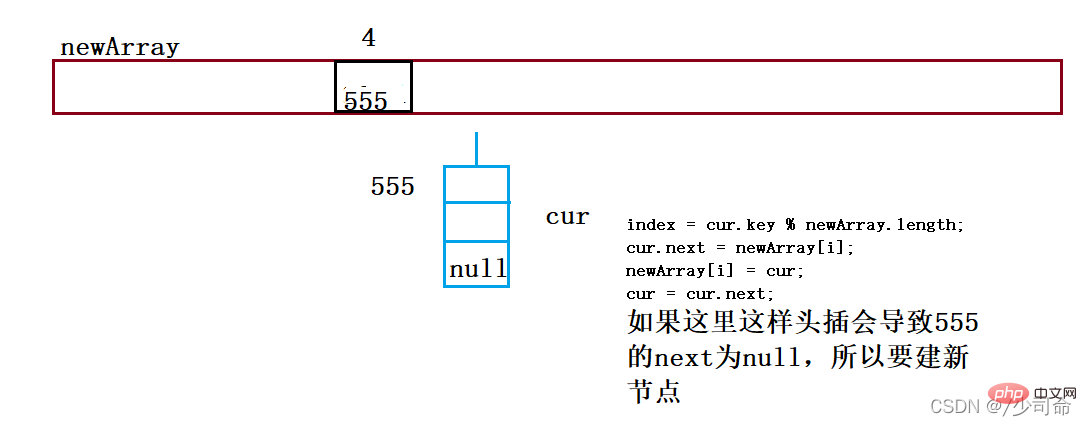
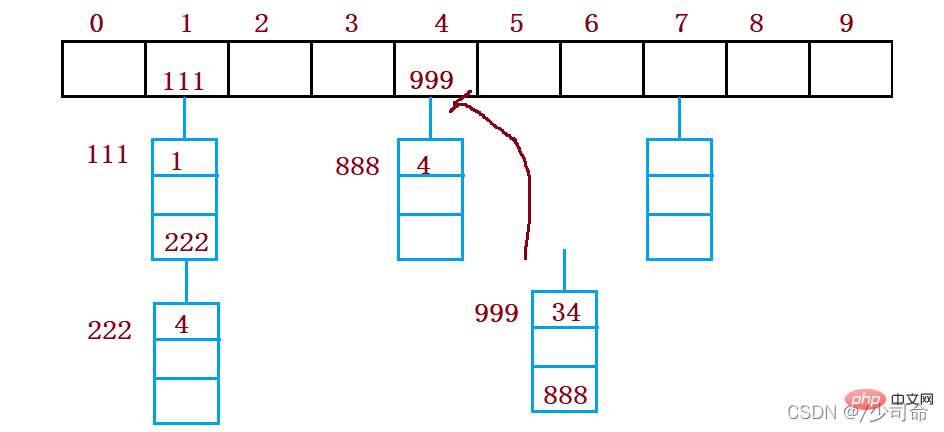
public void put(int key,int val){
int index = key % this.array.length;
Node cur = array[index];
while (cur != null){
if(cur.val == key){
cur.val = val;
return;
}
cur = cur.next;
}
//头插法
Node node = new Node(key,val);
node.next = array[index];
array[index] = node;
this.usedSize++;
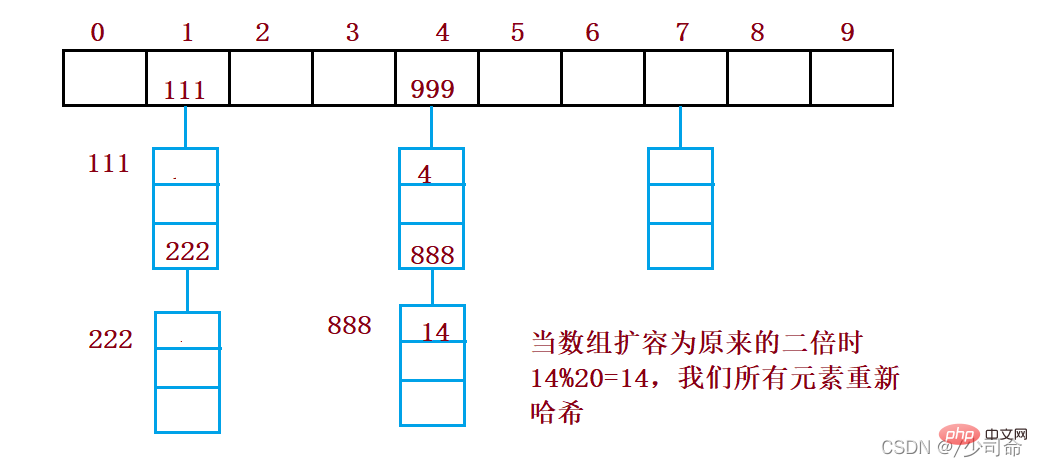
if(loadFactor() >= 0.75){
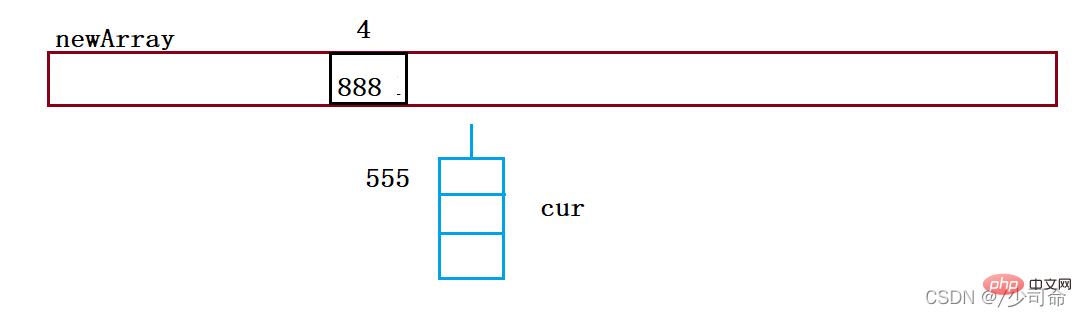
resize();
}
}7、完全なコードpublic int get(int key) {
//以什么方式存储的 那就以什么方式取
int index = key % this.array.length;
Node cur = array[index];
while (cur != null) {
if(cur.key == key) {
return cur.val;
}
cur = cur.next;
}
return -1;//
}
以上がJavaでのハッシュテーブルの解析例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。