
ホームページ >テクノロジー周辺機器 >AI >テキスト行が 3D ダイナミック シーンを生成します: Meta の「ワン ステップ」モデルは非常に強力です
テキスト行が 3D ダイナミック シーンを生成します: Meta の「ワン ステップ」モデルは非常に強力です

- 王林転載
- 2023-05-05 14:55:061014ブラウズ
テキスト行を入力するだけで 3D ダイナミック シーンを生成しますか?
はい、一部の研究者はすでにそれを行っています。現在の世代効果はまだ初期段階にあり、いくつかの単純なオブジェクトしか生成できないことがわかります。しかし、この「ワンステップ」法は依然として多くの研究者の注目を集めています。論文の中で、Meta の研究者は、テキストの説明から 3 次元の動的なシーンを生成できる方法である MAV3D (Make-A-Video3D) を初めて提案しました。

論文リンク: https://arxiv.org/abs/2301.11280

- 具体的にはこの方法では、4D 動的神経放射場 (NeRF) を使用して、テキストからビデオ (T2V) 拡散ベースのモデルをクエリすることで、シーンの外観、密度、動きの一貫性を最適化します。提供されたテキストによって生成されたダイナミック ビデオ出力は、任意のカメラ角度または角度から表示でき、任意の 3D 環境に合成できます。
- MAV3D は 3D または 4D データを必要としません。T2V モデルはテキストと画像のペアおよびラベルのないビデオでのみトレーニングされます。
テキストから 4D ダイナミック シーンを生成する MAV3D の効果を見てみましょう:

#さらに、画像から 4D、エフェクトに直接移動することもできます。

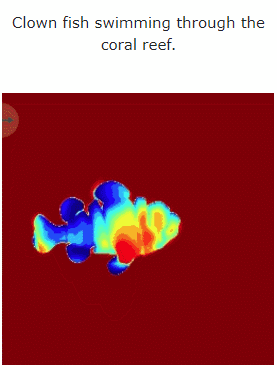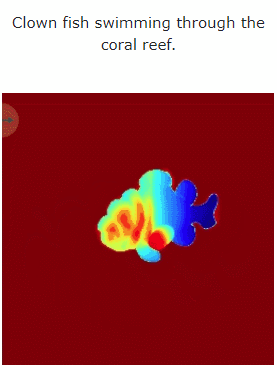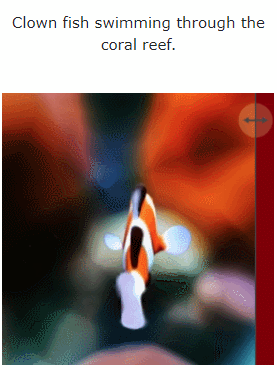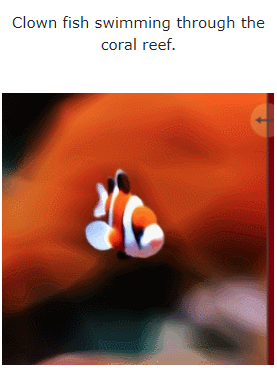
##研究者らは、包括的な調査を通じて証明しました。定量的および定性的実験 以前に確立された内部ベースラインに基づくこの方法の有効性も向上しました。これは、テキストの説明に基づいて 3D ダイナミック シーンを生成する最初の方法であると報告されています。
方法
より高いレベルから、テキスト プロンプト p が与えられると、空間および時間の任意の点でプロンプトに一致するシーンの外観をシミュレートする 4D 表現を研究で適合させることができます。ペアのトレーニング データがなければ、研究では 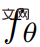 の出力を直接監視できませんが、一連のカメラ ポーズ が与えられると、
の出力を直接監視できませんが、一連のカメラ ポーズ が与えられると、 
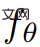 から画像シーケンスをレンダリングできます。
から画像シーケンスをレンダリングできます。 
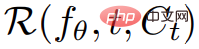 そしてそれらをビデオ V にスタックします。次に、テキスト プロンプト p とビデオ V が、フリーズされ事前トレーニングされた T2V 拡散モデルに渡され、ビデオの信頼性とプロンプトの配置がスコア付けされ、SDS (スコア蒸留サンプリング) を使用してシーン パラメーター θ の更新方向が計算されます。
そしてそれらをビデオ V にスタックします。次に、テキスト プロンプト p とビデオ V が、フリーズされ事前トレーニングされた T2V 拡散モデルに渡され、ビデオの信頼性とプロンプトの配置がスコア付けされ、SDS (スコア蒸留サンプリング) を使用してシーン パラメーター θ の更新方向が計算されます。
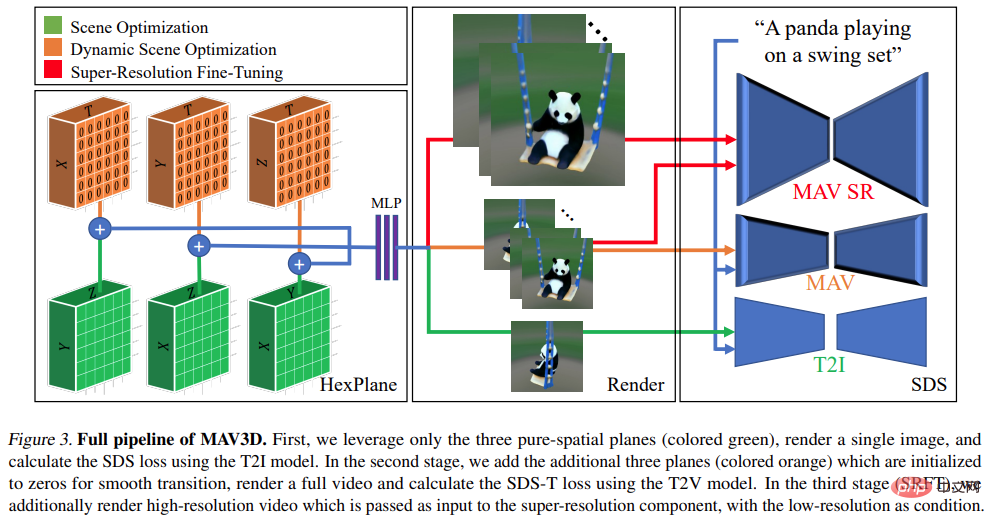
上記のパイプラインは、DreamFusion の拡張機能とみなすことができ、シーン モデルに時間次元を追加し、テキストからイメージへの変換 (T2I) の代わりに T2V モデルを使用します。 )監修用モデル。ただし、高品質の Text-to-4D 生成を実現するには、さらなる革新が必要です:
- まず、柔軟なシーン モーション モデリングを可能にする新しい方法が必要です。4D 表現;
- # 第 2 に、ビデオ品質を向上させ、モデルの収束を改善するには、マルチレベルの静的から動的への最適化スキームが必要です。このスキームでは、いくつかのモーション レギュラライザーを使用して実際のモーションを生成します。
- 3 番目に、超解像度微調整 (SRFT) を使用してモデルの解像度を向上させる必要があります。
具体的な手順については、以下の図を参照してください:
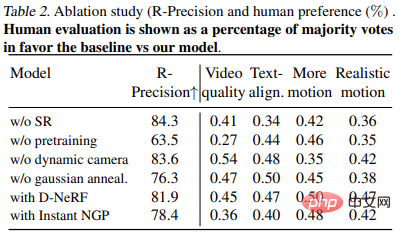
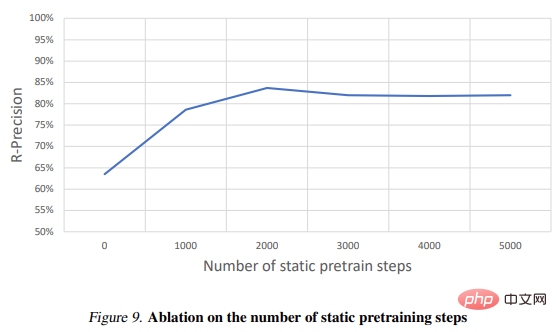
実験では、研究者らはテキストの説明から動的なシーンを生成する MAV3D の機能を評価しました。まず、研究者らは Text-To-4D タスクにおけるこの方法の有効性を評価しました。 MAV3D がこの課題に対する最初のソリューションであると報告されているため、研究ではベースラインとして 3 つの代替方法を開発しました。次に、T2V および Text-To-3D サブタスク モデルの簡易バージョンを評価し、文献内の既存のベースラインと比較します。第三に、包括的なアブレーション研究により、方法設計が正当化されます。 4 番目に、実験では動的 NeRF を動的メッシュに変換し、最終的にモデルを Image-to-4D タスクに拡張するプロセスを説明します。
メトリクス
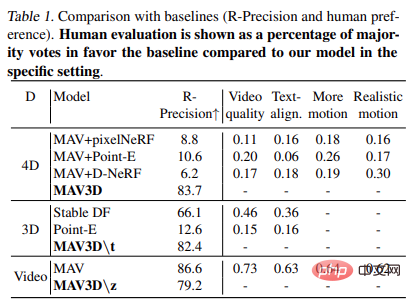
CLIP R-Precision を使用して生成されたビデオを評価する研究。テキストと生成されたシーン間の一貫性を測定します。 。報告されるメトリックは、レンダリングされたフレームから入力プロンプトを取得する精度です。私たちは、CLIP の ViT-B/32 バリアントを使用して、さまざまなビューとタイム ステップでフレームを抽出し、生成された 2 つのビデオのそれぞれについて人間の評価者に好みを尋ねることによって 4 つの定性的メトリクスも使用しました。 (i) ビデオ品質; ( ii) テキストプロンプトへの忠実度、(iii) アクティビティの量、(iv) 動きのリアリズム。テキスト プロンプトのセグメンテーションで使用されるすべてのベースラインとアブレーションを評価しました。
図 1 と図 2 は例です。さらに詳しい視覚化については、make-a-video3d.github.io を参照してください。

# 結果
表 1 に比較を示します。ベースラインまで (R - 精度と人間の好み)。人間によるレビューは、特定の環境におけるモデルと比較したベースライン多数派を支持する投票の割合として表示されます。
リアルタイム レンダリング
従来のグラフィック エンジンを使用する仮想現実やゲームなどのアプリケーションには、テクスチャメッシュなどの標準形式。 HexPlane モデルは、以下に示すようにアニメーション メッシュに簡単に変換できます。まず、マーチング キューブ アルゴリズムを使用して、各時間 t で生成された不透明フィールドから単純なメッシュが抽出され、その後 (効率化のため) メッシュが抽出され、ノイズの多い小さな連結成分が除去されます。 XATLAS アルゴリズムは、メッシュ頂点をテクスチャ アトラスにマッピングするために使用されます。テクスチャは、各頂点を中心とする小さな球内で平均化された HexPlane カラーを使用して初期化されます。最後に、微分可能メッシュを使用して HexPlane によってレンダリングされたいくつかのサンプル フレームとよりよく一致するようにテクスチャがさらに最適化されます。これにより、市販の 3D エンジンで再生できるテクスチャ メッシュのコレクションが生成されます。#Image to 4D
図 6 と図 10 は、指定された入力画像から生成できるメソッドを示しています。奥行きと動き、結果として 4D アセットが得られます。
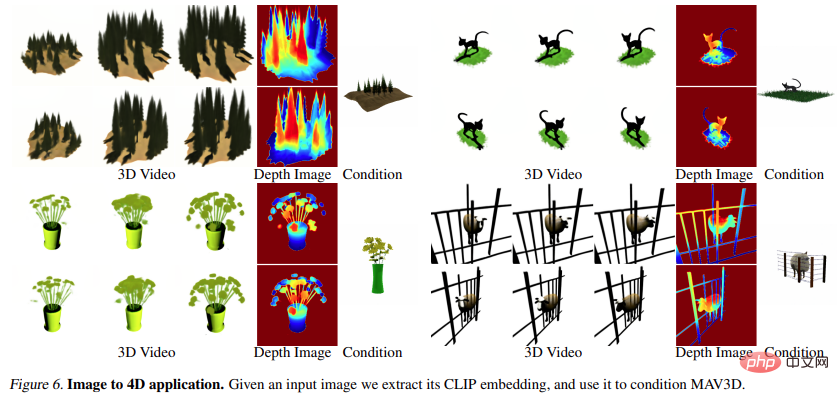


## ※研究の詳細については原論文を参照してください。

以上がテキスト行が 3D ダイナミック シーンを生成します: Meta の「ワン ステップ」モデルは非常に強力ですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。