



この記事は Lei Feng.com から転載されたものです。転載する必要がある場合は、Lei Feng.com の公式 Web サイトにアクセスして許可を申請してください。
大学を卒業して最初の仕事に就いたとき、私は機械学習についてよく知っていると思っていました。私は Pinterest と Khan Academy で機械学習システムを構築する 2 つのインターンシップに参加しました。バークレーでの最終年には、コンピューター ビジョンのためのディープ ラーニングの研究を行い、最初に人気のあるディープ ラーニング ライブラリの 1 つである Caffe に取り組みました。卒業後、私は自動運転車の製造を専門とする「Cruise」という小さなスタートアップ企業に入社しました。現在、私は Aquarium で、重要な社会問題を解決するために企業がディープラーニング モデルを導入するのを支援しています。
私は何年にもわたって、非常に優れたディープ ラーニングとコンピューター ビジョン スタックを構築してきました。私がバークレーで研究をしていた頃よりも、今では実稼働アプリケーションでディープラーニングを使用している人が増えています。彼らが現在直面している問題の多くは、2016 年に私がクルーズで直面した問題と同じです。本番環境におけるディープラーニングについて学んだ教訓がたくさんありますので、それを皆さんと共有したいと思います。皆さんが難しい方法で学ぶ必要がないことを願っています。

注: 著者のチームは、自動車に導入された最初の機械学習モデルを開発しました。
1 ML のストーリー自動運転車へのモデル展開
まず、クルーズ史上初めて自動車に展開された ML モデルについてお話します。モデルを開発するとき、ワークフローは私が研究時代に慣れていたものとよく似ていました。私たちはオープンソース データに基づいてオープンソース モデルをトレーニングし、それらを会社の製品ソフトウェア スタックに統合して、自動車に展開します。数週間の作業の後、最終的な PR をマージし、モデルを車で実行しました。
「任務は達成された!」私は、次の火を消し続けなければならないと思いました。本当の仕事は始まったばかりだったとは、ほとんど知りませんでした。
モデルが実稼働環境に導入されると、QA チームはモデルのパフォーマンスの問題に気づき始めました。しかし、構築すべき他のモデルや実行すべきタスクがあったため、これらの問題にはすぐには対処できませんでした。 3 か月後に問題を調査したところ、最初のデプロイメント以降にコードベースが変更されたため、トレーニング スクリプトと検証スクリプトがすべて壊れていることがわかりました。
1 週間の修正後、過去数か月の機能停止を確認したところ、モデルの実稼働実行で観察された問題の多くは、モデル コードを変更することで簡単に解決できないことがわかりました。オープンソース データに依存するのではなく、社用車両に関する新しいデータから生じた問題を収集してタグ付けします。これは、プロセスに必要なすべてのツール、運用、インフラストラクチャを含むラベル付けプロセスを確立する必要があることを意味します。
さらに 3 か月後、車からランダムに選択したデータに基づいてトレーニングされた新しいモデルを実行しました。次に、独自のツールを使用してマークアップします。しかし、単純な問題を解決し始めるときは、どのような変更が結果をもたらす可能性があるかをより見極める必要があります。
問題の約 90% は、モデル アーキテクチャの大幅な変更やハイパーパラメーターの調整ではなく、困難またはまれなシナリオの慎重なデータ キュレーションによって解決されます。たとえば、雨の日 (サンフランシスコでは珍しいこと) ではモデルのパフォーマンスが低下することがわかったので、より多くの雨の日のデータにラベルを付け、新しいデータでモデルを再トレーニングしたところ、モデルのパフォーマンスが向上しました。同様に、緑色の錐台 (オレンジ色の錐台に比べて一般的ではない) ではモデルのパフォーマンスが低いことが判明したため、緑色の錐台でデータを収集し、同じプロセスを実行したところ、モデルのパフォーマンスが向上しました。
このような問題を迅速に特定して解決できるプロセスを確立する必要があります。
このモデルの 1.0 バージョンを組み立てるのに数週間かかり、モデルの新しく改良されたバージョンを発売するのにさらに 6 か月かかりました。私たちはいくつかの側面 (ラベル付けインフラストラクチャ、クラウド データ処理、トレーニング インフラストラクチャ、デプロイメントの監視) にますます取り組んでおり、ほぼ毎月から毎週モデルの再トレーニングと再デプロイを行っています。
さらに多くのモデル パイプラインをゼロから構築し、改善に取り組むと、いくつかの共通のテーマが見えてきます。私たちが学んだことを新しいパイプラインに適用すると、より少ない労力でより良いモデルをより速く実行することが容易になりました。
2 反復学習を維持する
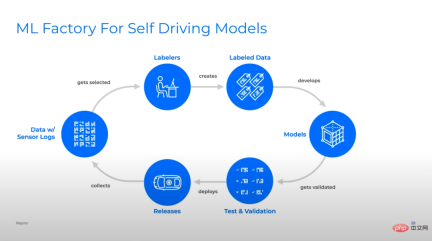
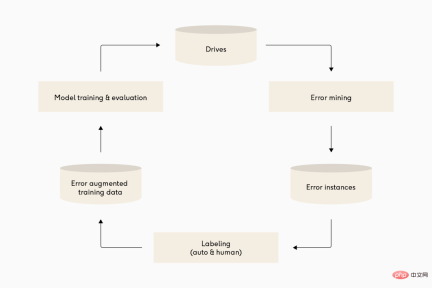
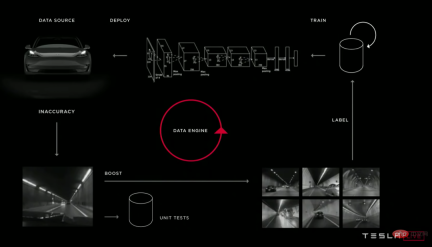
図: 多くの異なる自動運転ディープ ラーニング チームは、モデル パイプラインの反復サイクルが非常に似ています。上から下へ: Waymo、Cruise、Tesla。
私は、機械学習は主にモデルに関するものだと考えていました。実際、工業生産における機械学習はほとんどがパイプラインです。成功を予測する最良の要因の 1 つは、モデル パイプライン上で効率的に反復できるかどうかです。これは単に迅速に反復することを意味するのではなく、スマートに反復することを意味します。2 番目の部分が重要です。そうしないと、パイプラインで悪いモデルがすぐに生成されてしまいます。
従来のソフトウェアのほとんどは、製品の要件が不明であり、適応を通じて発見する必要があるため、迅速な反復と機敏な配信プロセスを重視しています。したがって、初期段階で不安定な前提を置いて詳細な計画を立てるよりも、迅速に配信する方が良いでしょう。 MVP と反復。
従来のソフトウェア要件が複雑であるのと同様に、機械学習システムが処理しなければならないデータ入力の領域は実に広大です。通常のソフトウェア開発とは異なり、機械学習モデルの品質は、コードでの実装と、コードが依存するデータに依存します。このデータへの依存は、機械学習モデルがデータセットの構築/管理を通じて入力ドメインを「探索」できることを意味し、コードを変更することなく、タスクの要件を理解し、時間の経過とともにそれに適応できるようになります。
この機能を活用するには、機械学習にはデータとコードの反復を重視する継続学習の概念が必要です。機械学習チームは次のことを行う必要があります:
- データまたはモデルのパフォーマンスの問題を発見する
- 問題が発生する理由を診断する
- データまたはモデルのコードを変更して問題を解決する
- 再トレーニング後にモデルが改善されることを検証する
- 新しいモデルをデプロイして繰り返す
チームはこのサイクルを少なくとも毎月実行するように努める必要があります。上手なら毎週やってもいいかもしれません。
大企業はモデル展開サイクルを 1 日以内に完了できますが、インフラストラクチャを迅速かつ自動的に構築することは、ほとんどのチームにとって困難です。モデルの更新頻度がこれよりも低い場合、コードの破損 (コード ベースの変更によりモデル パイプラインが中断される) やデータ ドメインのシフト (運用環境のモデルが時間の経過によるデータの変化に一般化できない) が発生する可能性があります。
大企業では、モデルの導入サイクルを 1 日で完了できますが、ほとんどのチームにとって、インフラストラクチャを迅速かつ自動的に構築することは非常に困難です。これより低い頻度でモデルを更新すると、コードの破損 (コード ベースの変更によりモデル パイプラインが破損する) やデータ ドメインのシフト (運用環境のモデルが時間の経過によるデータの変化に一般化できない) が発生する可能性があります。
ただし、正しく行えば、チームは改善されたモデルを運用環境にデプロイする良いリズムに乗ることができます。
3 フィードバック ループの構築
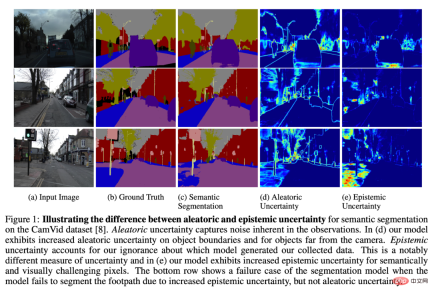
モデルのキャリブレーションにおける不確実性は、モデルが失敗する可能性があると思われる箇所にフラグを立てることができる興味深い研究分野です。
モデルを効果的に反復するための重要な部分は、最も影響力のある問題の解決に集中することです。モデルを改善するには、モデルの何が問題なのかを知り、製品/ビジネスの優先順位に従って問題を分類できる必要があります。フィードバック ループを構築する方法はたくさんありますが、まずエラーを見つけて分類することから始まります。
ドメイン固有のフィードバック ループを活用します。
どちらかといえば、これはモデルに関するフィードバックを得る非常に強力で効果的な方法です。たとえば、予測タスクは、実際に発生した履歴データをトレーニングすることでラベル付きデータを「無料」で取得できるため、大量の新しいデータを継続的に供給して、新しい状況にかなり自動的に適応できます。
人々がモデルの出力を確認し、エラーが発生した場合にフラグを立てることができるワークフローを設定します。
このアプローチは、多くのモデル推論を通じてエラーを簡単に発見できる場合に特に役立ちます。これが最も一般的に起こるのは、顧客がモデル出力のエラーに気づき、機械学習チームに苦情を申し立てた場合です。このチャネルを使用すると、顧客からのフィードバックを開発サイクルに直接組み込むことができるため、これを過小評価してはなりません。チームは、顧客が見逃した可能性のあるモデル出力を人間に再確認させることができます。オペレーターがベルトコンベア上で荷物を仕分けするロボットを観察し、エラーが発生したことに気付いたときにボタンをクリックするところを想像してください。
人々がモデルの出力を確認し、エラーが発生した場合にフラグを立てることができるワークフローを設定します。これは、多数のモデル推論におけるエラーが人間のレビューによって簡単に発見される場合に特に適しています。最も一般的なのは、顧客がモデル出力のエラーに気づき、ML チームに苦情を申し立てる場合です。このチャネルを使用すると、顧客のフィードバックを開発サイクルに直接組み込むことができるため、これを過小評価すべきではありません。チームは、顧客が見逃した可能性のあるモデル出力を人間に精査させることができます。ロボットがベルトコンベアで荷物を仕分けしているのをオペレーターが見ていると考えてください。エラーが発生するたびにボタンをクリックします。
モデルの実行頻度が高すぎて人間がチェックできない場合は、自動レビューの設定を検討してください。
これは、モデル出力に対する「健全性チェック」を簡単に作成できる場合に特に便利です。たとえば、LIDAR オブジェクト検出器と 2D 画像オブジェクト検出器が矛盾する場合、またはフレーム間検出器が時間追跡システムと矛盾するたびにフラグを立てます。機能すると、障害状態がどこで発生しているかを知らせる、多くの有用なフィードバックが提供されます。それが機能しない場合は、チェック システムのバグが明らかになるか、システムに問題が発生するたびに見逃されるだけです。これは非常に低リスクで高利益です。
最も一般的な (しかし困難な) 解決策は、実行されるデータのモデルの不確実性を分析することです。
簡単な例として、実稼働環境でモデルが信頼性の低い出力を生成する例を見てみましょう。これにより、モデルが実際に不確実であるが、100% 正確ではない部分が示されます。場合によっては、モデルが確実に間違っている可能性があります。適切な推論に利用できる情報が不足しているため、モデルが不定になることがあります (たとえば、人間が理解するのが難しいノイズの多い入力データなど)。これらの問題に対処するモデルはありますが、これは活発な研究分野です。
最後に、モデルのフィードバックをトレーニング セットに使用できます。
たとえば、モデルとそのトレーニング/検証データセット (つまり、高損失の例) の間の不一致をチェックすると、信頼性の高い失敗またはラベル付けの誤りが示されます。ニューラル ネットワーク埋め込み分析は、トレーニング/検証データ セットの故障モードのパターンを理解する方法を提供し、トレーニング データ セットと実稼働データ セットの生データ分布の違いを発見できます。

キャプション: ほとんどの人の時間は、典型的な再トレーニング サイクルから簡単に奪われてしまいます。たとえマシン時間の効率が低下するという犠牲を払ってでも、多くの手作業の負担が軽減されます。
反復の高速化の主な内容は、反復サイクルを完了するために必要な作業量を削減することです。ただし、物事を楽にする方法は常にあるため、改善したいものを優先する必要があります。私は、努力を時計の時間と人間の時間の 2 つの方法で考えるのが好きです。
クロック時間とは、データの ETL、モデルのトレーニング、推論の実行、インジケーターの計算など、特定のコンピューティング タスクの実行に必要な時間を指します。人間の時間とは、結果を手動で確認したり、コマンドを実行したり、パイプラインの途中でスクリプトをトリガーしたりするなど、パイプラインを実行するために人間が積極的に介入する必要がある時間を指します。
たとえば、ステップ間でファイルを手動で移動することにより、複数のスクリプトを順番に手動で実行する必要があります。これは非常に一般的ですが、無駄です。ナプキンの裏側の計算: 機械学習エンジニアの時給が 90 ドルで、手動でスクリプトを実行するために週に 2 時間を無駄にしている場合、年間 1 人あたり合計 9,360 ドルになります。
複数のスクリプトと人間による割り込みを 1 つの完全に自動化されたスクリプトに結合すると、モデル パイプライン ループの実行がより速く簡単になり、大量のコストが節約され、機械学習エンジニアの負担が軽減されます。
対照的に、クロック時間は通常「合理的」である必要があります (たとえば、一晩で実行できる)。唯一の例外は、機械学習エンジニアが大規模な実験を行っている場合、または極端なコスト/スケーリング制約がある場合です。これは、クロック時間が一般にデータ サイズとモデルの複雑さに比例するためです。ローカル処理から分散クラウド処理に移行すると、クロック時間が大幅に短縮されます。その後、問題のサイズが大きくなるまでは、クラウドでの水平スケーリングによって、ほとんどのチームの問題が解決される傾向があります。
残念ながら、一部のタスクを完全に自動化することはできません。ほとんどすべての実稼働機械学習アプリケーションは教師あり学習タスクであり、そのほとんどはモデルに何をすべきかを伝えるためにある程度の人間の対話に依存しています。一部の領域では、人間とコンピューターの対話は無料です (例: ソーシャル メディアの推奨ユースケースや、大量の直接ユーザー フィードバックを伴うその他のアプリケーション)。また、訓練を受けた放射線科医がトレーニング データの CT スキャンに「ラベルを付ける」場合など、人間の時間がより制限されたり、費用がかかったりする場合もあります。
いずれの場合も、モデルの改善に必要な労働時間やその他のコストを最小限に抑えることが重要です。初期のチームはデータ セットの管理を機械学習エンジニアに頼ることもありますが、多くの場合、機械学習の知識を持たない運用ユーザーまたはドメインの専門家にデータ管理の重労働を任せたほうが経済的です (放射線科医の場合は必要です)。この時点で、優れたソフトウェア ツールを使用してデータ セットのラベル付け、検査、改善、バージョン管理を行う運用プロセスを確立することが重要になります。
5 ML エンジニアの健康維持を奨励する

凡例: ML エンジニアは負荷を軽減している一方で、モデル学習の負荷も増加しています
新しいドメインや新しいユーザー グループをサポートするのに十分なツールを構築するには、多くの時間と労力がかかりますが、うまく行えば、それだけの価値のある結果が得られます。クルーズ社のエンジニアの 1 人は特に頭がよかったです (怠け者だと言う人もいます)。
このエンジニアは、運用フィードバックとメタデータ クエリを組み合わせて、モデルのパフォーマンスが低いデータを抽出してラベルを付ける反復ループを確立しました。その後、オフショア運用チームがデータにラベルを付け、新しいバージョンのトレーニング データセットに追加します。その後、エンジニアは、コンピュータ上でスクリプトを実行し、新しく追加されたデータに基づいて単純なモデルを自動的に再トレーニングおよび検証するための一連のクラウド タスクを起動できるインフラストラクチャをセットアップします。
毎週、再トレーニング スクリプトが実行されます。次に、モデルがトレーニングして自身を検証している間、彼らはジムに行きました。数時間のフィットネスと夕食の後、彼らは結果を確認するために戻ってきました。偶然にも、新しく改良されたデータはモデルの改良につながり、すべてが意味をなしていることを確認するための簡単な再チェックの後、新しいモデルが生産に出荷され、車の操縦性が向上します。その後、彼らは 1 週間かけてインフラストラクチャを改善し、新しいモデル アーキテクチャを実験し、新しいモデル パイプラインを構築しました。このエンジニアは四半期の終わりに昇進しただけでなく、絶好調でした。
6 結論
要約すると、調査とプロトタイピングの段階では、モデルの構築と公開に重点が置かれます。ただし、システムが実稼働に入ると、中心的なタスクは、最小限の労力で改良されたモデルを定期的にリリースできるシステムを構築することです。上達すればするほど、より多くのモデルを構築できるようになります。
これを行うには、次のことに重点を置く必要があります:
- モデル パイプラインを定期的に実行し、出荷モデルを以前よりも改善することに重点を置きます。新しい改良されたモデルを毎週またはそれ以下で実稼働環境に導入してください。
- モデルの出力から開発プロセスまでの適切なフィードバック ループを確立します。モデルのパフォーマンスが低い例を見つけて、トレーニング データセットにさらに例を追加します。
- パイプライン内の特に負荷の高いタスクを自動化し、チームメンバーが専門分野に集中できるチーム構造を確立します。テスラのアンドレイ・カルパシー氏は、理想的な最終状態を「オペレーション・ホリデー」と呼んでいる。機械学習エンジニアがジムに通い、機械学習パイプラインに重労働を任せるワークフローを設定することをお勧めします。
最後に、私の経験では、モデルのパフォーマンスに関するほとんどの問題はデータで解決できますが、一部の問題はモデル コードを変更することによってのみ解決できることを強調する必要があります。
これらの変更は、多くの場合、当面のモデル アーキテクチャに非常に固有です。たとえば、画像オブジェクト検出器に数年間取り組んだ後、特定の向きの比率に対する以前のボックスの最適な割り当てについて心配することに非常に多くの時間を費やしました。小さなオブジェクトの特徴マップの解像度を向上させます。
しかし、Transformers がさまざまなディープ ラーニング タスクのユニバーサル モデル アーキテクチャ タイプになる可能性を示しているため、これらのテクニックの関連性が薄れ、機械学習開発の焦点がさらに移っていくのではないかと私は考えています。データセット。
以上が自動運転に機械学習を実装する場合、中心となるのはモデルではなくパイプラインですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM
踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM科学者は、彼らの機能を理解するために、人間とより単純なニューラルネットワーク(C. elegansのものと同様)を広く研究してきました。 ただし、重要な疑問が生じます。新しいAIと一緒に効果的に作業するために独自のニューラルネットワークをどのように適応させるのか
 新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AM
新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AMGoogleのGemini Advanced:Horizonの新しいサブスクリプションティア 現在、Gemini Advancedにアクセスするには、1か月あたり19.99ドルのGoogle One AIプレミアムプランが必要です。 ただし、Android Authorityのレポートは、今後の変更を示唆しています。 最新のGoogle p
 データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM
データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM高度なAI機能を取り巻く誇大宣伝にもかかわらず、エンタープライズAIの展開内に大きな課題が潜んでいます:データ処理ボトルネック。 CEOがAIの進歩を祝う間、エンジニアはクエリの遅い時間、過負荷のパイプライン、
 MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AM
MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AMドキュメントの取り扱いは、AIプロジェクトでファイルを開くだけでなく、カオスを明確に変えることです。 PDF、PowerPoint、Wordなどのドキュメントは、あらゆる形状とサイズでワークフローをフラッシュします。構造化された取得
 建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AM
建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AMGoogleのエージェント開発キット(ADK)のパワーを活用して、実際の機能を備えたインテリジェントエージェントを作成します。このチュートリアルは、ADKを使用して会話エージェントを構築し、GeminiやGPTなどのさまざまな言語モデルをサポートすることをガイドします。 w
 効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AM
効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AMまとめ: Small Language Model(SLM)は、効率のために設計されています。それらは、リソース不足、リアルタイム、プライバシーに敏感な環境の大手言語モデル(LLM)よりも優れています。 特にドメインの特異性、制御可能性、解釈可能性が一般的な知識や創造性よりも重要である場合、フォーカスベースのタスクに最適です。 SLMはLLMSの代替品ではありませんが、精度、速度、費用対効果が重要な場合に理想的です。 テクノロジーは、より少ないリソースでより多くを達成するのに役立ちます。それは常にドライバーではなく、プロモーターでした。蒸気エンジンの時代からインターネットバブル時代まで、テクノロジーの力は、問題の解決に役立つ範囲にあります。人工知能(AI)および最近では生成AIも例外ではありません
 コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AM
コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AMコンピュータービジョンのためのGoogleGeminiの力を活用:包括的なガイド 大手AIチャットボットであるGoogle Geminiは、その機能を会話を超えて拡張して、強力なコンピュータービジョン機能を網羅しています。 このガイドの利用方法については、
 Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM2025年のAIランドスケープは、GoogleのGemini 2.0 FlashとOpenaiのO4-Miniの到着とともに感動的です。 数週間離れたこれらの最先端のモデルは、同等の高度な機能と印象的なベンチマークスコアを誇っています。この詳細な比較


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

ドリームウィーバー CS6
ビジュアル Web 開発ツール

WebStorm Mac版
便利なJavaScript開発ツール

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、
ホットトピック
 7760
7760 15164414139952129325123429
15164414139952129325123429