
ホームページ >テクノロジー周辺機器 >AI >量子コンピューティングと人工知能の関係は何ですか?
量子コンピューティングと人工知能の関係は何ですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-05 08:37:061357ブラウズ

数十年にわたる研究を経て、人工知能 (AI) は主要な業界トレンドの 1 つになりつつあります。 Alexa や Siri との会話から、Waymo や Tesla の自動運転車、人間のように散文を書く OpenAI の GPT-3、人間の囲碁グランドマスターを破る DeepMind の AlphaZero まで、人工知能は今や十分に成熟しています。多くの場合、人間よりも速く、より上手に、現実の問題を解決します。
テクノロジー業界の他の場所では、先見の明のある人たちが量子コンピューターの開発に取り組んでおり、量子物理学の特性を利用して今日のコンピューターよりも高速に計算を実行しようとしています。
この時点で、多くの人が疑問に思うかもしれません: 量子コンピューティングと人工知能の関係とは一体何ですか?
アルゴリズムの複雑さは隠れた敵です
アルゴリズムの複雑さは A AI 研究者と量子コンピューティングの先駆者によって行われた研究を結び付ける、ややあいまいな数学的概念。
計算複雑性理論は、空間 (メモリ) や時間などのリソース使用量に基づいて計算問題を分類することに焦点を当てた、数学とコンピューター サイエンスにまたがる分野です。基本的に、計算問題は、アルゴリズムで定義された数学的ステップに従って、コンピューターによって機械的に解決できるタスクです。
たとえば、リスト内の数値を並べ替える問題を考えてみましょう。 「選択ソート」と呼ばれる可能なアルゴリズムの 1 つは、リストの未ソート部分 (最初はすべて) から最小の要素を (昇順で) 繰り返し見つけて先頭に配置することで構成されます。このアルゴリズムは、実行中に元のリストの 2 つのサブリスト、つまり既にソートされた部分とソートされていない残りの部分を効果的に維持します。このプロセスが数回実行されると、結果は最小から最大の順に並べ替えられたリストになります。時間計算量の観点から、これは N 2 の計算量で表されます。ここで、N はリスト内の要素のサイズまたは数を表します。数学者は、「キューブ ソート」や「ティム ソート」など、より効率的だがより複雑なソート アルゴリズムを提案しています。どちらも N x log(N) の複雑さがあります。 100 個の要素のリストを並べ替えるのは今日のコンピューターでは簡単な作業ですが、10 億のレコードのリストを並べ替えるのはそれほど簡単ではない可能性があります。したがって、時間計算量 (または入力問題のサイズに対するアルゴリズムのステップ数) が非常に重要です。
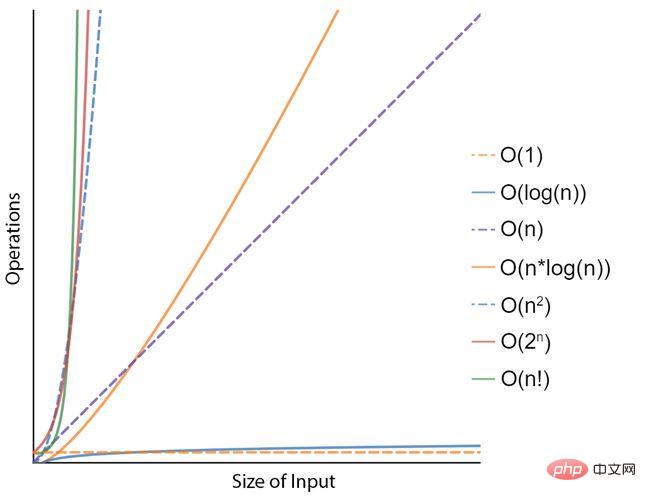
#問題をより速く解決するには、より高速なコンピューターを使用するか、より少ない操作で済むより効率的なアルゴリズムを見つけることができます。これは、時間の複雑さが軽減されることを意味します。ただし、指数関数的な複雑さの問題 (N 2 や 2 N など) では数学が不利になることは明らかであり、より大きな問題サイズでは、より高速なコンピューターを使用するだけでは現実的ではありません。そして、これはまさに人工知能の分野に当てはまります。
人工知能は解決すべき非常に複雑な問題です
まず、今日の人工知能 (AI) システムで使用されている人工ニューラル ネットワークの計算の複雑さを見ていきます。これらの数学的モデルは、動物の脳を構成する生物学的神経ネットワークからインスピレーションを得ています。彼らは、多くの例を見ることで入力データを認識または分類することを「学習」します。これらは、相互接続されたノードまたはニューロンの集合であり、「入力層」に提示されたデータと相互接続の重みに基づいて出力を決定する活性化関数と組み合わされています。
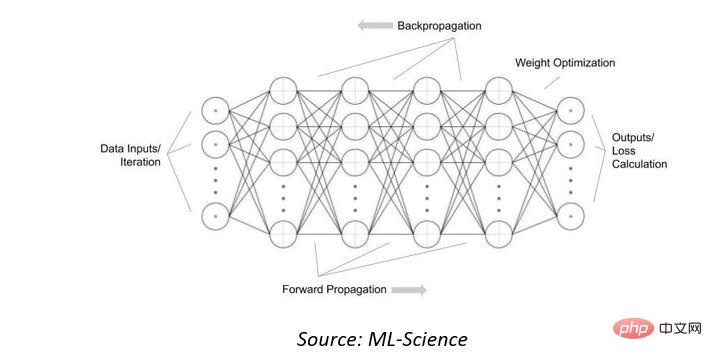
「出力」が有用または正確になるように相互接続の重みを調整するには、出力を多くのデータ例にさらして「トレーニング」することができます。逆伝播」出力損失ネットワーク。
N 個の入力と M 個の隠れ層を備え、i 番目の隠れ層に m i 個の隠れニューロンと k 個の出力ニューロンが含まれるニューラル ネットワークの場合、すべてのニューロンの重みを調整するアルゴリズム (逆伝播アルゴリズムと呼ばれます)時間計算量は次のようになります: 散文、1,750 億のパラメータ (またはニューロン)。数十億メガのこの AI モデルは、現在、大規模なクラウド データ センターの強力なサーバー コンピューターを使用した場合でも、トレーニングに数か月かかります。さらに、AI モデルのサイズは増大し続けるため、時間の経過とともに状況は悪化するでしょう。
量子コンピューティングが助けになります?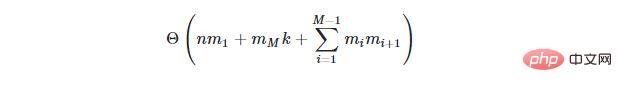
古典コンピュータは情報をビット (「バイナリ ディジット」の略) で送信しますが、量子コンピュータは量子ビット (「量子ビット」の略) を使用します。古典的なビットと同様に、量子ビットは最終的に 1 または 0 のいずれかの形式で情報を送信する必要がありますが、特別なのは、1 と 0 の両方を同時に表現できることです。量子ビットは、70% の確率で 1、30% の確率で 0 になる確率分布を持つと言われています。これが量子コンピューターを特別なものにしている理由です。
量子コンピューターは、量子力学の 2 つの基本特性、重ね合わせともつれを利用します。
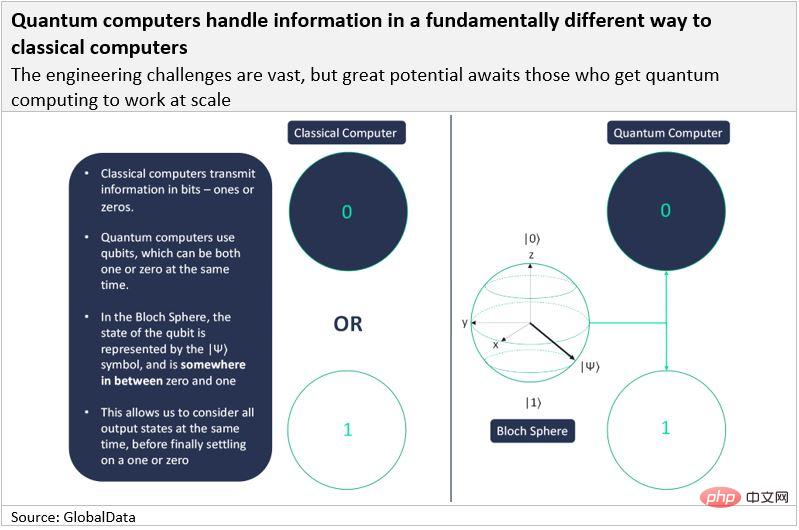
量子ビットが同時に 1 と 0 であるとき、それは重ね合わせ状態にあると言われます。重ね合わせとは、系が同時に複数の状態にあり、測定時に単一の状態のみが想定される状態の総称です。コインが量子オブジェクトであると仮定すると、コインを投げると重ね合わせが生じます。つまり、コインには表か裏の確率しかありません。コインが地面に落ちて測定すると、コインが表か裏かがわかります。同様に、(地面に落ちたコインと同様に)電子のスピンを測定する場合にのみ、電子がどのような状態にあるのか、そしてそれが 1 か 0 であるかを知ることができます。
量子粒子の重ね合わせは、複数の粒子がある場合にのみ役立ちます。これは、量子力学の 2 番目の基本原理であるもつれにつながります。 2 つ (またはそれ以上) の絡み合った粒子を個別に記述することはできず、それらの特性は完全に相互に依存します。したがって、もつれた量子ビットは互いに影響を与える可能性があります。 1 つの量子ビット (1 または 0) の確率分布は、システム内の他のすべての量子ビットの確率分布に依存します。
このため、システムに新しい量子ビットが追加されるたびに、コンピューターが分析できる状態の数が 2 倍になります。このコンピューター能力の指数関数的な増加は、新しいビットごとに線形にしか拡大しない古典的なコンピューティングとは対照的です。
理論的には、もつれた量子ビットは数十億の演算を同時に実行できます。この機能により、N2、2N、または N の範囲の複雑さを持つアルゴリズムが大幅に高速化されることは明らかです。
量子力人工知能への準備を整える
量子コンピューティングには膨大な可能性があるため、ハードウェア チームは引き続きこれらのシステムの実現に取り組んでいます (これまでで最大のものは IBM の 127- Qubit Eagle システム) ですが、ソフトウェア研究者はすでに、暗号、化学、材料科学、システム最適化、機械学習/人工知能などの分野で、この「同時コンピューティング」機能を活用できる新しいアルゴリズムの開発に取り組んでいます。ショールの因数分解量子アルゴリズムは、古典的なコンピューターよりも指数関数的に高速化すると考えられていますが、これは現在の暗号アルゴリズムにリスクをもたらします。
最も興味深いことに、量子線形代数は多項式加速を提供すると考えられており、これにより人工ニューラル ネットワークのパフォーマンスが大幅に向上します。 Google は、ハイブリッド量子古典機械学習モデルの迅速なプロトタイピングを可能にする量子機械学習用のソフトウェア フレームワークである TensorFlow Quantum を開始しました。量子コンピューティングのリーダーでもあるIBMは、最近、量子機械学習における量子の優位性の「数学的証明」を発見したと発表しました。ただし、IBMやGoogleのような企業は垂直統合されている(したがって、ハードウェアシステムとソフトウェアアルゴリズムを同時に開発している)のですが、また、Zapata、Riverlane、1Qbit、さらには Quantinuum (Cambridge Quantum Computing が Honeywell と合併して社名を変更したため、もはや純粋なソフトウェア会社ではありません) など、非常に興味深い量子ソフトウェアのスタートアップ企業も多数あります。いくつかの例。
量子ハードウェアがより強力になり、量子機械学習アルゴリズムが洗練されるにつれて、量子コンピューティングは人工知能チップ市場で大きなシェアを獲得する可能性があります。
以上が量子コンピューティングと人工知能の関係は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。