
ホームページ >テクノロジー周辺機器 >AI >HKUST と MSRA の調査: 画像から画像への変換に関しては、微調整だけで十分です
HKUST と MSRA の調査: 画像から画像への変換に関しては、微調整だけで十分です

- 王林転載
- 2023-05-04 23:10:061008ブラウズ

多くのコンテンツ制作プロジェクトでは、単純なスケッチをリアルな画像に変換する必要があります。これには、深層生成モデル学習を使用した画像間の変換が含まれます。入力が与えられた場合の自然画像の条件付き分布です。
画像から画像への変換の基本概念は、事前にトレーニングされたニューラル ネットワークを利用して自然な画像多様体をキャプチャすることです。画像変換は、多様体を走査して実行可能な入力意味点を見つけることに似ています。このシステムは、潜在空間のあらゆるサンプリングから信頼性の高い出力を提供するために、多くの画像を使用して合成ネットワークを事前トレーニングします。事前トレーニングされた合成ネットワークを通じて、下流トレーニングはユーザー入力をモデルの潜在表現に適応させます。
長年にわたり、多くのタスク固有の手法が SOTA レベルに達しているのを見てきましたが、現在のソリューションでは、現実世界で使用するための高忠実度の画像を作成するのに依然として苦労しています。

最近の論文では、香港科技大学とマイクロソフト リサーチ アジアの研究者は、画像から画像への変換には事前トレーニングだけで十分であると考えています。 。従来の方法では、特殊なアーキテクチャ設計と単一の変換モデルのトレーニングを一から行う必要があり、特にペアのトレーニング データが不十分な場合、高品質の複雑なシーンを生成することが困難でした。
したがって、研究者らは、画像から画像への各変換問題を下流タスクとして扱い、さまざまな画像から画像への変換に適応するために事前トレーニングされた拡散モデルを採用する単純な一般的なフレームワークを導入しました。彼らは、提案された事前トレーニングされた画像から画像への変換モデルを PITI (事前トレーニングベースの画像から画像への変換) と呼びました。さらに、研究者らは、敵対的トレーニングを使用して拡散モデルのトレーニングにおけるテクスチャ合成を強化し、それを正規化されたガイド付きサンプリングと組み合わせて生成品質を向上させることも提案しました。
最後に、研究者らは、ADE20K、COCO-Stuff、DIODE などの挑戦的なベンチマークでさまざまなタスクについて広範な実証的比較を実施し、PITI 合成画像が前例のないリアリズムと忠実度を示すことを実証しました。

- 論文リンク: https://arxiv.org/pdf/2205.12952.pdf
- プロジェクトのホームページ: https://tengfei-wang .github.io/PITI/index.html
GAN は死んだ、拡散モデルは生き続ける
著者は特定の分野で最高のパフォーマンスを発揮した GAN を使用しませんでしたが、拡散モデルを使用し、多種多様な画像を合成します。次に、2 種類の潜在コードから画像を生成する必要があります。1 つは視覚的なセマンティクスを記述するもの、もう 1 つは画像の変動を調整するものです。セマンティックな低次元の潜在性は、下流のタスクにとって重要です。そうしないと、モーダル入力を複雑な潜在空間に変換することが不可能になります。これを考慮して、彼らは、事前学習済みの事前生成として、さまざまな画像を生成できるデータ駆動型モデルである GLIDE を使用しました。 GLIDE は潜在テキストを使用するため、意味論的な潜在スペースが可能になります。
拡散およびスコアベースの手法は、ベンチマーク全体での生成品質を実証します。クラス条件付き ImageNet では、これらのモデルは、視覚的な品質とサンプリングの多様性の点で GAN ベースの手法と競合します。最近、大規模なテキストと画像のペアでトレーニングされた拡散モデルが驚くべき機能を示しました。よく訓練された拡散モデルは、合成のための一般的な事前生成を提供できます。
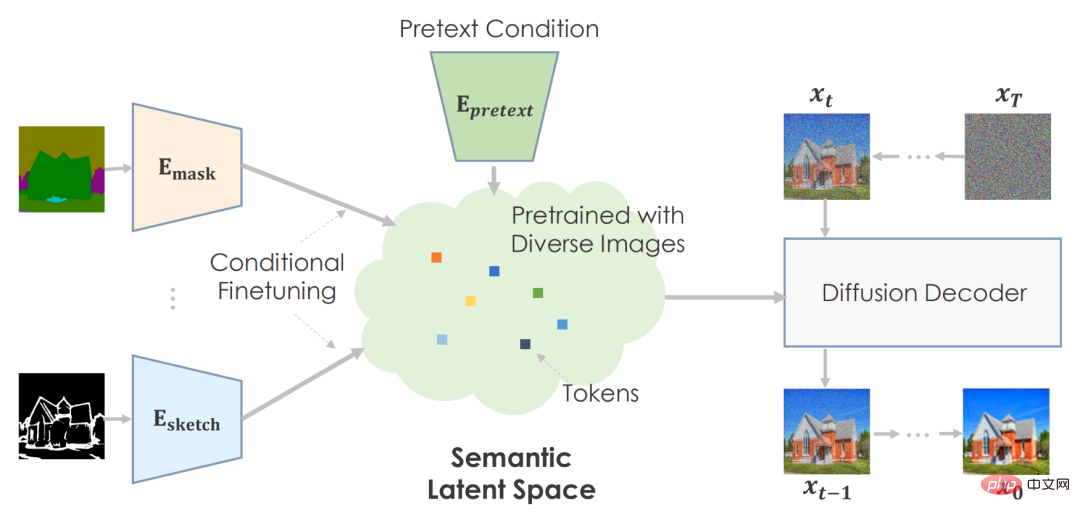
フレームワーク
作成者は、プレテキスト タスクを使用して、大量のデータで事前トレーニングし、画像統計を予測するための非常に意味のある潜在空間を開発できます。
下流タスクの場合、意味空間を条件付きで微調整してタスク固有の環境をマップします。このマシンは、事前にトレーニングされた情報に基づいて、信頼できるビジュアルを作成します。
著者は、セマンティック入力を使用して拡散モデルを事前トレーニングすることを推奨しています。テキスト条件付き、画像トレーニング済みの GLIDE モデルを使用します。 Transformer ネットワークはテキスト入力をエンコードし、拡散モデルのトークンを出力します。計画通り、スペースにテキストを埋め込むのは理にかなっています。

上の写真は作者の作品です。事前トレーニングされたモデルは、ゼロからの手法と比較して画質と多様性を向上させます。 COCO データセットには多数のカテゴリと組み合わせがあるため、基本的なアプローチでは魅力的なアーキテクチャを備えた美しい結果を提供できません。彼らの方法では、難しいシーンでも正確なセマンティクスを備えた豊かな詳細を作成できます。写真は彼らのアプローチの多用途性を示しています。
実験と影響
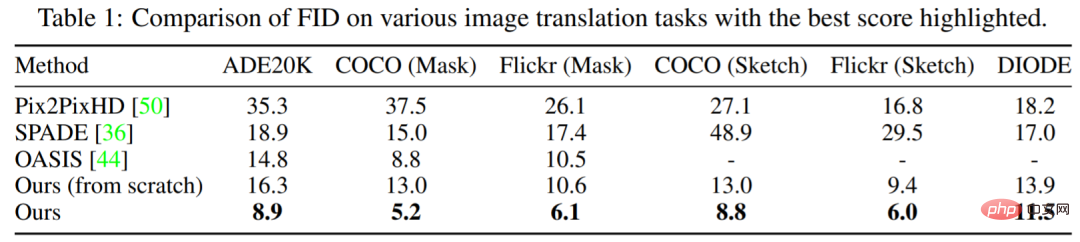
表 1 は、この研究で提案された方法のパフォーマンスが他のモデルよりも常に優れていることを示しています。主要な OASIS と比較して、PITI はマスクからイメージへの合成における FID において大幅な改善を達成しています。さらに、この方法は、スケッチからイメージへの合成タスクおよびジオメトリからイメージへの合成タスクでも優れたパフォーマンスを示します。
# 図 3 は、さまざまなタスクに関するこの研究の視覚化結果を示しています。実験によると、最初からトレーニングする方法と比較して、事前トレーニングされたモデルは、生成される画像の品質と多様性が大幅に向上します。この研究で使用された方法は、困難な生成タスクであっても、鮮明な詳細と正しいセマンティクスを生成できます。

この調査では、Amazon Mechanical Turk の COCO-Stuff でのマスクから画像への合成に関するユーザー調査も実施され、20 人の参加者チケットから 3000 件の結果が得られました。参加者には一度に2枚の画像が与えられ、どちらがより現実的か投票するよう求められた。表 2 に示すように、提案された方法は、ゼロからのモデルや他のベースラインよりも大幅に優れています。

条件付き画像合成では、特定の条件を満たす高画質な画像を作成します。コンピューター ビジョンとグラフィックスの分野では、情報の作成と操作にそれが使用されます。大規模な事前トレーニングにより、画像分類、オブジェクト認識、セマンティック セグメンテーションが向上します。不明なことは、大規模な事前トレーニングが一般的な生成タスクに有益であるかどうかです。
エネルギー使用量と炭素排出量は、画像の事前トレーニングにおける重要な問題です。事前トレーニングはエネルギーを大量に消費しますが、必要なのは 1 回だけです。条件付き微調整により、下流タスクで同じ事前トレーニング済みモデルを使用できるようになります。事前トレーニングにより、少ないトレーニング データで生成モデルをトレーニングできるため、プライバシーの問題や高価なアノテーション コストによりデータが制限されている場合の画像合成が向上します。
以上がHKUST と MSRA の調査: 画像から画像への変換に関しては、微調整だけで十分ですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。