



多くの学者の見解では、身体化された知能は AGI に向けた非常に有望な方向性であり、ChatGPT の成功は強化学習に基づく RLHF テクノロジーと切り離すことができません。 DeepMind と OpenAI、どちらが先に AGI を達成できるでしょうか? 答えはまだ明らかにされていないようです。
私たちは、一般的な身体化知能 (つまり、敏捷性と器用さで物理世界で行動し、動物や人間のように理解するエージェント) を作成することが AI 研究者にとって重要なステップであることを理解しています。ロボット工学者の長期的な目標。時間的には、複雑な移動機能を備えたインテリジェントな実体エージェントの作成は、シミュレーションと現実世界の両方で何年も前に遡ります。
近年、進歩のペースは大幅に加速しており、学習ベースの手法が大きな役割を果たしています。 たとえば、深層強化学習は、複雑な知覚主導の全身制御やマルチエージェントの動作など、シミュレートされたキャラクターの複雑なモーション制御の問題を解決できることが示されています。 同時に、深層強化学習は物理ロボットでの使用が増えています。特に、広く使用されている高品質の四足歩行ロボットは、さまざまな堅牢な運動行動を生成する学習のデモンストレーションのターゲットとなっています。
ただし、静的環境での移動は、動物や人間が世界と対話するために体を展開するさまざまな方法の一部にすぎず、この移動様式は多くの研究で使用されています。特に四足ロボットにおいては、全身制御と動作操作が検証されています。関連する動作の例には、木登り、ドリブルやボールキャッチなどのサッカーのスキル、脚を使う簡単な操作などがあります。
その中でも、サッカーに関しては、人間の感覚運動知性の多くの特徴が示されています。サッカーの複雑さには、走る、曲がる、避ける、蹴る、パスする、倒れる、起き上がるなど、機敏でダイナミックなさまざまな動きが必要です。これらのアクションはさまざまな方法で組み合わせる必要があります。プレーヤーはボール、チームメイト、相手プレーヤーを予測し、ゲーム環境に応じて行動を調整する必要があります。この課題の多様性がロボット工学と AI コミュニティで認識され、ロボカップが誕生しました。
ただし、サッカーを上手にプレーするために必要な機敏性、柔軟性、素早い反応、そしてこれらの要素の間のスムーズな移行は、非常に困難で時間がかかることに注意する必要があります。ロボットの手動設計。 最近、DeepMind (現在は Google Brain チームと合併して Google DeepMind を設立) の新しい論文では、二足歩行ロボットの機敏なサッカー スキルを学習するための深層強化学習の使用について検討しています。

#論文アドレス: https://arxiv.org/pdf/2304.13653 .pdf
プロジェクトのホームページ: https://sites.google.com/view/op3-soccer
この論文では、研究者らは動的なマルチエージェント環境における小型ヒューマノイドロボットの全身制御とオブジェクトの相互作用を研究しています。 彼らは、フットボール全体の問題のサブセットを検討し、20 個の制御可能な関節を備えた低コストの小型ヒューマノイド ロボットをトレーニングして 1 対 1 のフットボール ゲームをプレイし、固有受容とゲーム状態の特性を観察しました。 コントローラーを内蔵しているため、ロボットはゆっくりとぎこちなく動きます。しかし、研究者らは、深層強化学習を使用して、動的で機敏な状況適応型運動スキル (歩く、走る、方向転換する、ボールを蹴る、転んでから立ち上がるなど) を統合し、エージェントが自然かつスムーズな方法で複雑な運動スキルを統合しました。 -期の行動。
実験では、エージェントはボールの動きを予測し、ボールを配置し、攻撃をブロックし、バウンドしたボールを使用することを学習しました。エージェントは、スキルの再利用、エンドツーエンドのトレーニング、シンプルな報酬の組み合わせにより、マルチエージェント環境でこれらの行動を実現します。研究者らは、シミュレーションでエージェントをトレーニングし、それらを物理的なロボットに転送し、低コストのロボットでもシミュレーションから現実への転送が可能であることを実証しました。
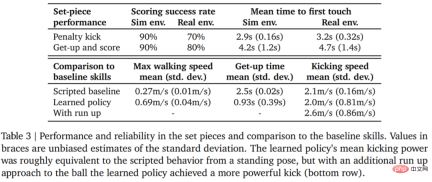
データがそれ自体を物語ります。ロボットの歩行速度は 156% 増加し、立ち上がるまでの時間は 63% 短縮され、キック速度も 24% 増加しました。ベースラインまで。
技術的な解釈に入る前に、1 対 1 のサッカーの試合におけるロボットのハイライトのいくつかを見てみましょう。たとえば、撮影:
 ######################## ペナルティーキック: ###################### ##
######################## ペナルティーキック: ###################### ##
ターン、ドリブル、キックをすべて一度に
##ブロック:
 実験設定
実験設定
ロボットにサッカーを学習させたい場合は、まず基本的な設定が必要です。
環境に関しては、図 1 に示すように、DeepMind はまずカスタマイズされたサッカー環境でエージェントをシミュレートしてトレーニングし、次に戦略を対応する実際の環境に移行します。環境は、長さ 5 メートル、幅 4 メートルのサッカー場と、開口幅 0.8 メートルの 2 つのゴールから構成されていました。シミュレーション環境と実際の環境の両方で、コートはボールを範囲内に保つために傾斜路で囲まれています。実際のコートは、転倒によるロボットの損傷のリスクを軽減し、地面との摩擦を増やすためにゴム製のタイルで覆われています。 
 #環境をセットアップしたら、次のステップはハードウェアとモーション キャプチャをセットアップすることです。 DeepMind は、高さ 51 cm、重さ 3.5 kg の Robotis OP3 ロボットを使用しており、20 個のサーボ モーターで駆動されます。ロボットには GPU やその他の専用アクセラレータがないため、すべてのニューラル ネットワークの計算は CPU 上で実行されます。ロボットの先頭には Logitech C920 ウェブカメラがあり、オプションで 30 フレーム/秒の RGB ビデオ ストリームを提供できます。
#環境をセットアップしたら、次のステップはハードウェアとモーション キャプチャをセットアップすることです。 DeepMind は、高さ 51 cm、重さ 3.5 kg の Robotis OP3 ロボットを使用しており、20 個のサーボ モーターで駆動されます。ロボットには GPU やその他の専用アクセラレータがないため、すべてのニューラル ネットワークの計算は CPU 上で実行されます。ロボットの先頭には Logitech C920 ウェブカメラがあり、オプションで 30 フレーム/秒の RGB ビデオ ストリームを提供できます。
方法
DeepMind の目標は、人々が歩いたり、蹴ったりできるように訓練することです。ボールを投げ、立ち上がって、防御し、エージェントに得点を与える方法を理解し、これらの機能を実際のロボットに移管します。図 3 に示すように、DeepMind はトレーニングを 2 つの段階に分割します。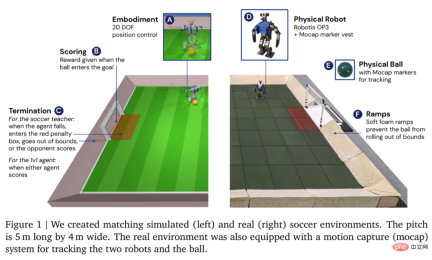
第 2 段階では、第 1 段階の教師戦略を使用してエージェントを制御し、エージェントはますます強力になる敵と効果的に戦う方法を学習します。

#トレーニング
最初は教師のトレーニングです。教師は、目標を達成するためのトレーニングをできるだけ多く受ける必要があります。このラウンド (エピソード) は、エージェントが転倒するか、範囲外に出るか、制限エリア (図 1 の赤でマーク) に進入するか、対戦相手が得点すると終了します。各ラウンドの開始時に、エージェント、相手側、ボールはコート上のランダムな位置と方向に初期化されます。両側がデフォルトのスタンスに初期化されます。敵対者はトレーニングされていないポリシーで初期化されるため、エージェントはこの段階で敵対者を回避する方法を学習しますが、それ以上の複雑な相互作用は発生しません。さらに、各トレーニング段階の報酬とその重みを表 2 に示します。- エージェントは、教師のポリシーに従ってその動作を制御しながら、ますます強力な敵と競争します。このようにして、エージェントは、歩く、蹴る、立ち上がる、得点する、守るといった一連のサッカースキルを習得することができます。エージェントが範囲外に出るか、ゴール ボックス内にいる場合、各タイム ステップで固定ペナルティを受けます。
エージェントがトレーニングされた後の次のステップは、トレーニングされたキック戦略をサンプルなしで実際のロボットに転送することです。ゼロショット転送の成功率を向上させるために、DeepMind はシンプルなシステム識別を通じてシミュレートされたエージェントと実際のロボットの間のギャップを減らし、トレーニング中のドメインのランダム化と摂動を通じて戦略の堅牢性を向上させ、獲得するための報酬戦略の形成を含みます。ロボットに害を及ぼす可能性が高すぎる動作。
実験
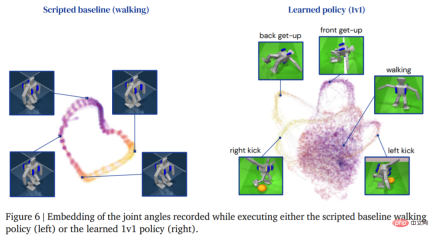
1v1 競技: サッカー エージェントは、地面からの立ち上がり、転倒からの迅速な回復、そして走って振り返る。ゲーム中、エージェントはこれらすべてのスキルの間を流動的に移行します。

#以下の表 3 は、定量分析の結果を示しています。この結果から、強化学習戦略は人工的に設計された特殊なスキルよりも優れたパフォーマンスを発揮し、エージェントの歩行速度が 156% 速くなり、立ち上がるまでの時間が 63% 短縮されたことがわかります。


以上がDeepMind が GPT の祝宴に参加しないのはなぜですか?私は小さなロボットにサッカーを教えていたことが判明しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM
踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM科学者は、彼らの機能を理解するために、人間とより単純なニューラルネットワーク(C. elegansのものと同様)を広く研究してきました。 ただし、重要な疑問が生じます。新しいAIと一緒に効果的に作業するために独自のニューラルネットワークをどのように適応させるのか
 新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AM
新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AMGoogleのGemini Advanced:Horizonの新しいサブスクリプションティア 現在、Gemini Advancedにアクセスするには、1か月あたり19.99ドルのGoogle One AIプレミアムプランが必要です。 ただし、Android Authorityのレポートは、今後の変更を示唆しています。 最新のGoogle p
 データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM
データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM高度なAI機能を取り巻く誇大宣伝にもかかわらず、エンタープライズAIの展開内に大きな課題が潜んでいます:データ処理ボトルネック。 CEOがAIの進歩を祝う間、エンジニアはクエリの遅い時間、過負荷のパイプライン、
 MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AM
MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AMドキュメントの取り扱いは、AIプロジェクトでファイルを開くだけでなく、カオスを明確に変えることです。 PDF、PowerPoint、Wordなどのドキュメントは、あらゆる形状とサイズでワークフローをフラッシュします。構造化された取得
 建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AM
建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AMGoogleのエージェント開発キット(ADK)のパワーを活用して、実際の機能を備えたインテリジェントエージェントを作成します。このチュートリアルは、ADKを使用して会話エージェントを構築し、GeminiやGPTなどのさまざまな言語モデルをサポートすることをガイドします。 w
 効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AM
効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AMまとめ: Small Language Model(SLM)は、効率のために設計されています。それらは、リソース不足、リアルタイム、プライバシーに敏感な環境の大手言語モデル(LLM)よりも優れています。 特にドメインの特異性、制御可能性、解釈可能性が一般的な知識や創造性よりも重要である場合、フォーカスベースのタスクに最適です。 SLMはLLMSの代替品ではありませんが、精度、速度、費用対効果が重要な場合に理想的です。 テクノロジーは、より少ないリソースでより多くを達成するのに役立ちます。それは常にドライバーではなく、プロモーターでした。蒸気エンジンの時代からインターネットバブル時代まで、テクノロジーの力は、問題の解決に役立つ範囲にあります。人工知能(AI)および最近では生成AIも例外ではありません
 コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AM
コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AMコンピュータービジョンのためのGoogleGeminiの力を活用:包括的なガイド 大手AIチャットボットであるGoogle Geminiは、その機能を会話を超えて拡張して、強力なコンピュータービジョン機能を網羅しています。 このガイドの利用方法については、
 Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM2025年のAIランドスケープは、GoogleのGemini 2.0 FlashとOpenaiのO4-Miniの到着とともに感動的です。 数週間離れたこれらの最先端のモデルは、同等の高度な機能と印象的なベンチマークスコアを誇っています。この詳細な比較


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

ドリームウィーバー CS6
ビジュアル Web 開発ツール
ホットトピック
 7767
7767 15164414139952129325123429
15164414139952129325123429