
ホームページ >テクノロジー周辺機器 >AI >「ChatGPT Nemesis」アップグレード: 教師はクラス全体の宿題をテストに投入できます。中国人作家:無料で使用可能
「ChatGPT Nemesis」アップグレード: 教師はクラス全体の宿題をテストに投入できます。中国人作家:無料で使用可能

- 王林転載
- 2023-05-04 19:25:041113ブラウズ
「ChatGPT Nemesis」がバージョンアップしました!
はい、これは中国人のエドワード・ティアン兄弟が構築した GPTZero です。テキストが人間によって書かれたのか AI によって書かれたのかを数秒で知ることができます。

ほぼ 1 か月後、この男が立ち上げたバージョンは GPTZeroX と呼ばれ、次のようにも言いました。
これは特に教育者向けに作成された AI モデルです。
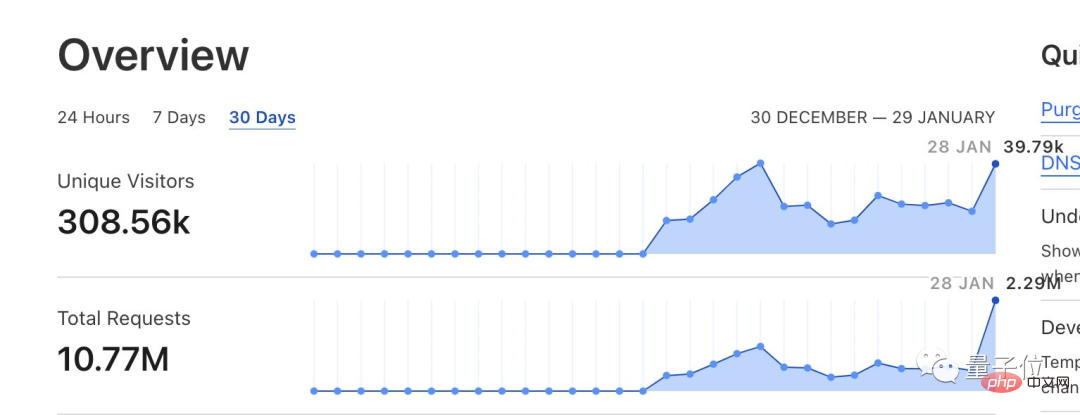
このニュースが発表されるとすぐに、大量のネチズンが殺到し、1 日で 40 万件の訪問と 220 万件のサービス リクエストが寄せられました。
そこで今回は、この「ChatGPT Nemesis」がもたらす新たな能力とは?
混合書き込みのテストも可能で、Word などの形式にも対応
アップグレードの大きな特徴は、GPTZeroX が「人間 AI」によって混合されたテキスト コンテンツを検出できることです。
たとえば、最初に人間が書いたニュースをテストに投入します。

GPTZeroX はわずか数秒で非常に迅速に結果を返します。 答え:
あなたのテキストはすべて人間によって書かれている可能性があります。
あなたのテキストはすべて人間によって書かれている可能性があります。
次に、先ほどニュースの後ろに ChatGPT で書かれたテキストを放り込んで混合検出を行ってみましょう:
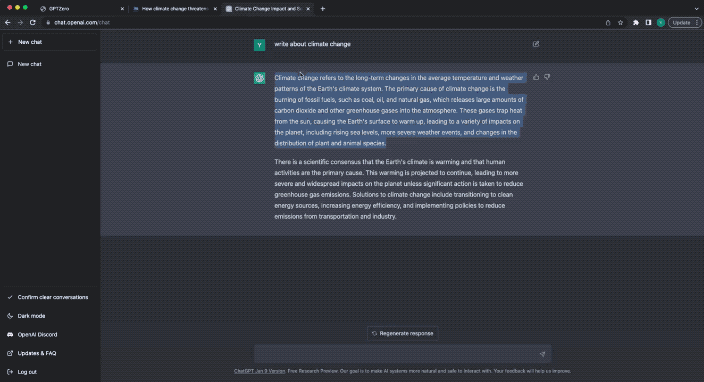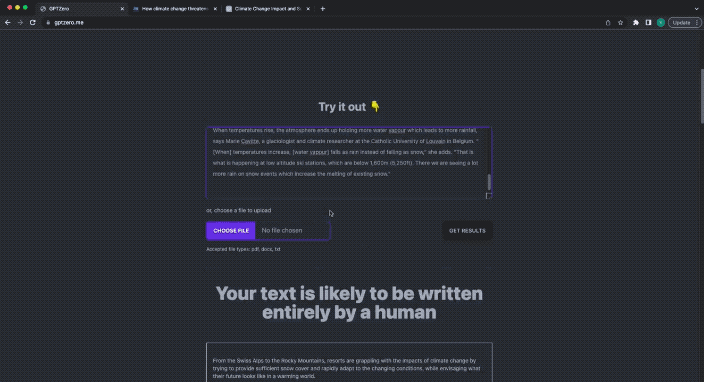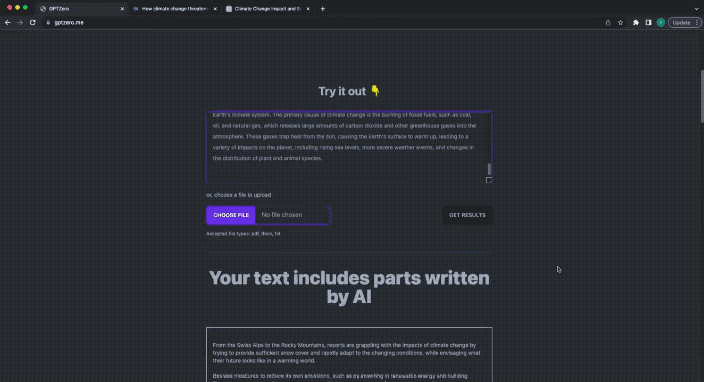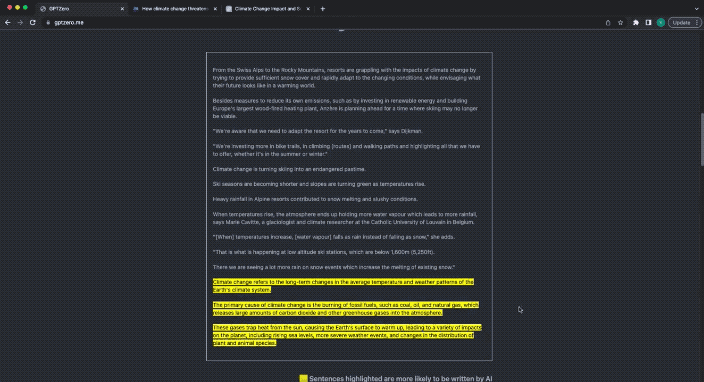
今回は、 GPTZero の答えは次のとおりです。
あなたのテキストには AI によって書かれた部分が含まれています。
あなたのテキストの一部は AI によって書かれています。
ChatGPT によって生成されたコンテンツも黄色で強調表示されます。

弟はこう言いました:
これは教育者が常に望んでいた重要な機能です。
しかし、教師が生徒の宿題をチェックするときに、テキストを段落ごとにコピーして貼り付けるのは非常に面倒な作業です。
それ以来、この男は、Word、PDF、TXT、その他の形式をサポートする、ファイルをバッチでインポートする機能という別の新機能も思慮深く立ち上げました。
そして、Web サイトでこの機能が紹介されると、次のように説明されます。

:

さらに、サービスのクラッシュを防ぐために、ストレス テスト済みの Python API も作成しました。

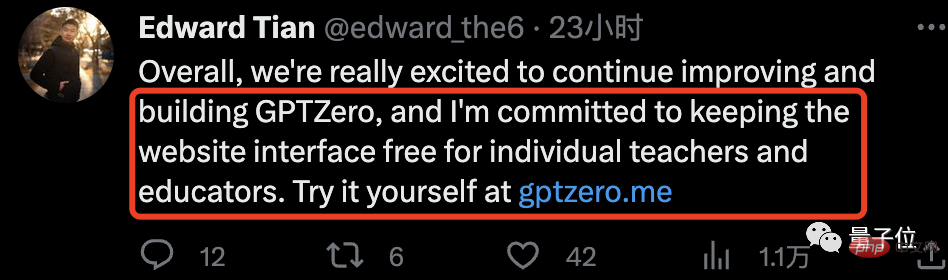
最後に、弟は思慮深いことも言いました:
このウェブサイトは個人の教師や教育者にとって今後も無料であることを約束します。
どうやってやったのですか?
与えられたコンテンツを誰が書いたかを判断する指標として、主に「perplexity」、つまりテキストの「わかりにくさ」に依存します。
NLP 分野の友人は、この指標が言語モデルの品質を評価するために使用されていることを知っています。
ここで、GPTZero にテスト コンテンツをフィードすると、それぞれ次の計算が行われます:
1. テキスト全体の混乱
この値が大きいほど、その可能性が高くなります。人間の手によって作られました。

#2. すべての文の平均混乱度
文が長くなるほど、通常、この値は低くなります。

3. 各文の混乱度
# は棒グラフの形式で表示されます。各四角形の上にマウスを置くと、対応する文がどのようなものかを確認できます。です (今回入力したテスト内容は 2 つの文だけなので、ここでは Two Pieces となります)。
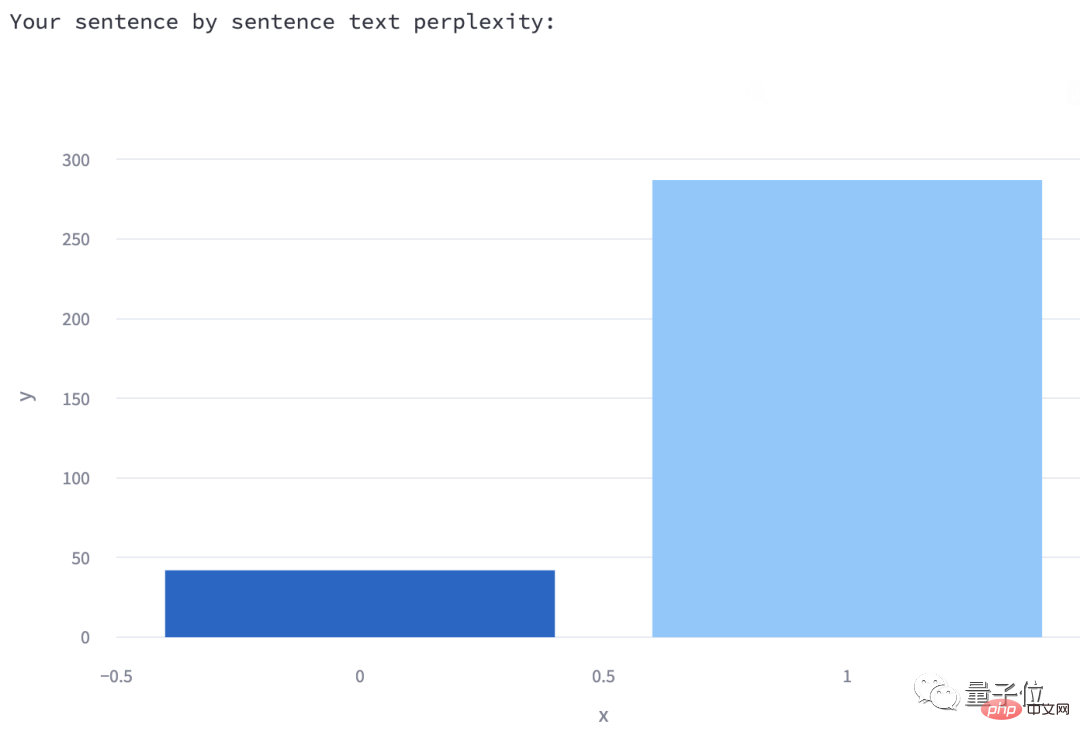
著者は、このような棒グラフが描かれる理由についても説明しています:
最新の研究によると、人間が書いた文章の中には、次のようなものがある可能性があります。混乱度は低いですが (前述したように、人間の混乱度は比較的高いです)、書き続けると混乱度は必ずピークに達します。
対照的に、機械生成されたテキストでは、困惑度は均等に分散され、常に低くなります。
さらに、GPTZero は、混乱の程度が最も高い文 (つまり、最も人間らしい文) も選択します。

Anti-ChatGPT Feng Zhengsheng
ことわざにあるように、魔法は道と同じくらい高いです。ChatGPT がさまざまな武道のスキルを披露する一方で、GPTZero のような「魔法で魔法を倒す」ためのツールや研究も行われています。次々と登場。
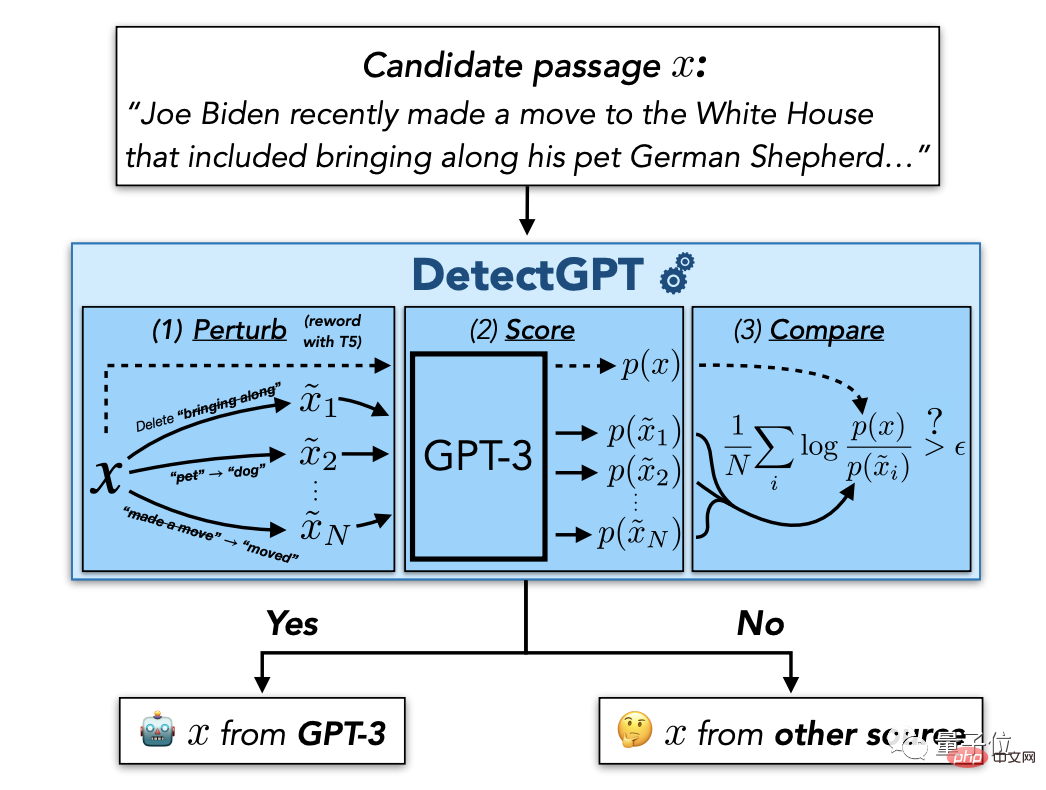
たとえば、スタンフォード大学は最近、学生が ChatGPT を使用して論文を書いたりカンニングしたりするのを防ぐために、「反偵察」アーティファクト DetectGPT を立ち上げました。

このメソッドは、別個の分類器をトレーニングする必要も、実際のパッセージまたは生成されたパッセージのデータ セットを収集する必要もありません。確率的曲率に基づくゼロショット メソッドです。
さらに、OpenAI 自体も、ハーバード大学や他の大学と協力して、GPT-2 Output Detector という検出器を作成しました。

著者らは、AI が「AI 言語」を理解できるようにするために、「GPT-2 で生成されたコンテンツ」と WebText (特に外国の投稿バーである Reddit から取得した) データ セットを最初にリリースしました。 「 」と「人間の音声」の違い。
その後、このデータセットを使用して RoBERTa モデルを微調整し、AI 検出器を取得しました。人間の音声は常に True として認識され、AI が生成したコンテンツは常に Fake として認識されます。
(RoBERTa は BERT の改良版です。元の BERT は 13 GB のデータ セットを使用しましたが、RoBERTa は 6,300 万の英語ニュース項目を含む 160 GB のデータ セットを使用しました。)
……
そうですね、ChatGPT は大きな進歩を遂げている一方で、「反 ChatGPT」研究の発展も促進しているようです。
参考リンク: [1] https://twitter.com/edward_the6/status/1619874139954905090[2] https://arxiv.org/abs/2301.11305
以上が「ChatGPT Nemesis」アップグレード: 教師はクラス全体の宿題をテストに投入できます。中国人作家:無料で使用可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。