
ホームページ >テクノロジー周辺機器 >AI >ユーザー数が 5 日間で 100 万人を突破、ChatGPT の背後にある謎とは何ですか?
ユーザー数が 5 日間で 100 万人を突破、ChatGPT の背後にある謎とは何ですか?

- PHPz転載
- 2023-05-04 10:19:061225ブラウズ
翻訳者 | Li Rui
レビュアー | Sun Shujuan
OpenAI が再び人気です。最近、多くの人が友人の中に、愛されていると同時に恐れられている冷酷なキャラクターを見つけたため、StackOverflow は急いでそのキャラクターを棚から削除しなければなりませんでした。
最近、OpenAI がチャット AI ChatGPT をリリースしましたが、わずか数日でユーザー数が 100 万人に達し、サーバーは登録ユーザーで超過密になりました。
ネチズンが「Google 検索を超える」と驚嘆するこの種の成果物は、どのようにして実現するのでしょうか?信頼できるものですか?
1. イベント レビュー
OpenAI 社は最近 ChatGPT をリリースしました。これは主力 GPT シリーズに基づくもう 1 つの大規模言語モデル (LLM) であり、特に会話型の対話に使用されるモデルです。ユーザーは同社の無料デモ版をダウンロードできる。
リリースされたほとんどの大規模言語モデル (LLM) と同様に、ChatGPT のリリースもいくつかの論争を引き起こしました。リリースからわずか数時間以内に、新しい言語モデルは Twitter 上で騒動を引き起こし、ユーザーは ChatGPT の素晴らしい成果や壊滅的な失敗のスクリーンショットをアップロードしました。
ただし、大規模な言語モデルという幅広い観点から見ると、ChatGPT はこの分野の短くても豊かな歴史を反映しており、わずか数年でどれだけの進歩があったのか、そしてどのような根本的な問題がまだ解決されていないのかを表しています。 。
2.教師なし学習の夢
教師なし学習は依然として人工知能コミュニティが追求する目標の 1 つであり、インターネット上には貴重な知識や情報がたくさんあります。しかし、最近まで、この情報の多くは機械学習システムで利用できませんでした。ほとんどの機械学習および深層学習アプリケーションは監視されています。つまり、機械学習システムをトレーニングするには、人間が大量のデータ サンプルを取得し、各サンプルに注釈を付ける必要があります。
大規模な言語モデルの重要なコンポーネントである Transformer アーキテクチャの出現により、この状況は変わりました。 Transformer モデルは、ラベルのないテキストの大規模なコーパスを使用してトレーニングできます。彼らはテキストの一部をランダムにマスクし、欠落している部分を予測しようとします。この操作を繰り返し実行することで、Transformer はパラメータを調整して、大きなシーケンス内の異なる単語間の関係を表現します。
これは非常に効果的で拡張性のある戦略であることが証明されています。人間によるラベル付けを必要とせずに非常に大規模なトレーニング コーパスを収集できるため、ますます大規模な Transformer モデルの作成とトレーニングが可能になります。研究と実験により、Transformer モデルとラージ言語モデル (LLM) のサイズが大きくなるにつれて、より長い一貫性のあるテキスト シーケンスが生成されることが示されています。大規模言語モデル (LLM) も、大規模な緊急事態対応機能を実証します。
3. 回帰教師あり学習?
大規模言語モデル (LLM) は通常、テキストのみであり、模倣しようとしている人間の豊かな多感覚体験が欠けていることを意味します。 GPT-3 などの大規模言語モデル (LLM) は目覚ましい結果を達成しますが、いくつかの根本的な欠陥があり、常識、論理、計画、推論、および通常本文から省略されるその他の知識を必要とするタスクでは予測不能になります。大規模言語モデル (LLM) は、錯覚的な応答を生成したり、一貫性はあるが事実に反するテキストを生成したり、ユーザー プロンプトの明らかな意図を誤解したりすることがよくあることで知られています。
モデルとそのトレーニング コーパスのサイズを増やすことで、科学者は大規模な言語モデルにおける明らかなエラーの頻度を減らすことができました。しかし、根本的な問題が解決したわけではなく、最大規模の大規模言語モデル (LLM) であっても、ほんの少しの努力で愚かな間違いを犯す可能性があります。
大規模言語モデル (LLM) が科学研究室でベンチマークのパフォーマンスを追跡するためにのみ使用されている場合、これは大きな問題ではないかもしれません。しかし、現実世界のアプリケーションで大規模言語モデル (LLM) を使用することへの関心が高まるにつれて、これらの問題やその他の問題に対処することがより重要になってきます。エンジニアは、機械学習モデルがさまざまな条件下でも堅牢性を維持し、ユーザーのニーズと要件を満たしていることを確認する必要があります。
この問題を解決するために、OpenAI は強化学習モデルを最適化するために以前に開発されたヒューマン フィードバックによる強化学習 (RLHF) テクノロジーを使用します。人間によるフィードバックを伴う強化学習 (RLHF) は、強化学習モデルにその環境と動作をランダムに探索させるのではなく、人間のスーパーバイザーからの不定期なフィードバックを使用して、エージェントを正しい方向に導きます。人間によるフィードバックによる強化学習 (RLHF) の利点は、人間によるフィードバックを最小限に抑えながら強化学習エージェントのトレーニングを改善できることです。
OpenAI はその後、ユーザー プロンプトの指示をよりよく理解し、応答するように設計された大規模言語モデル (LLM) のファミリーである InstructGPT にヒューマン フィードバックによる強化学習 (RLHF) を適用しました。 InstructGPT は、人間のフィードバックに基づいて微調整された GPT-3 モデルです。
これは明らかにトレードオフです。人間による注釈は、スケーラブルなトレーニング プロセスのボトルネックになる可能性があります。しかし、教師なし学習と教師あり学習の適切なバランスを見つけることで、OpenAI は、指示に対する応答の向上、有害な出力の削減、リソースの最適化などの重要な利点を実現できます。 OpenAI の研究結果によると、13 億パラメータの struct GPT は、命令フォローにおいて 1,750 億パラメータの GPT-3 モデルよりも一般的に優れています。
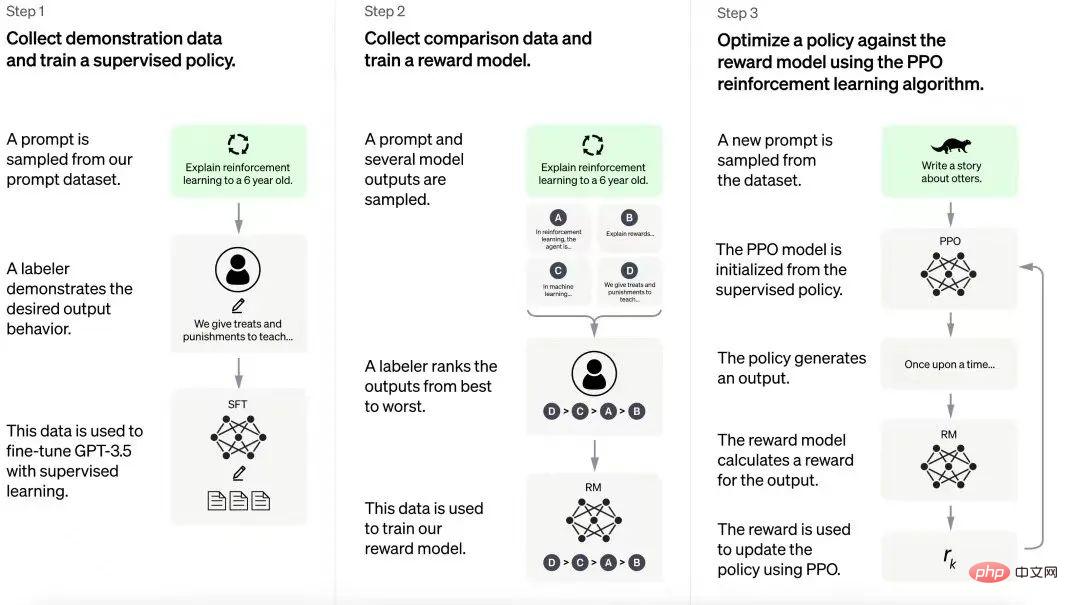
ChatGPT のトレーニング プロセス
ChatGPT は、InstructGPT モデルから得られた経験に基づいて構築されています。ヒューマン・アノテーターは、ユーザーのプロンプトと模範的な応答を含む一連の会話例を作成します。このデータは、ChatGPT が構築されている GPT-3.5 モデルを微調整するために使用されます。次のステップでは、微調整されたモデルに新しいプロンプトが与えられ、いくつかの応答が与えられます。アノテーターはこれらの回答をランク付けします。これらのインタラクションから生成されたデータは、報酬モデルのトレーニングに使用されます。これは、強化学習パイプラインの大規模言語モデル (LLM) をさらに微調整するのに役立ちます。
OpenAI は強化学習プロセスの完全な詳細を明らかにしていませんが、人々はこのプロセスの「拡張不可能なコスト」、つまりどれくらいの人的資源が必要かについて知りたがっています。
4. ChatGPT はどの程度信頼できますか?
ChatGPT の結果は印象的です。このモデルは、コードに関するフィードバックの提供、詩の執筆、さまざまな口調での技術概念の説明、生成人工知能モデルのプロンプトの生成など、さまざまなタスクを完了しました。
ただし、このモデルは、存在しない論文や書籍の引用、直観的な物理学の誤解、構成性の失敗など、大規模言語モデル (LLM) による間違いと同様の間違いを犯しやすいです。
人々はこうした失敗に驚きません。 ChatGPT は魔法のような機能はなく、以前のバージョンと同じ問題に悩まされるはずです。しかし、実際のアプリケーションのどこで、どの程度信頼できるのでしょうか? Codex と GitHubCopilot でラージ言語モデル (LLM) が非常に効果的に使用できることがわかるように、ここには明らかに何らかの価値があります。
ここで、ChatGPT が役立つかどうかを決定するのは、ChatGPT に実装されているツールと保護の種類です。たとえば、ChatGPT は、コーディングやグラフィック デザイン用のデジタル コンパニオンなど、企業向けのチャットボットを作成するための非常に優れたプラットフォームになる可能性があります。まず、InstructGPT の例に従えば、より少ないパラメータで複雑なモデルのパフォーマンスを得ることができ、コスト効率が高くなります。さらに、OpenAI が、企業がヒューマン フィードバックを使用した強化学習 (RLHF) の独自の微調整を実装できるツールを提供すれば、特定のアプリケーション向けにさらに最適化することができ、ほとんどの場合、チャットボットよりも便利になります。何でもについて。最後に、アプリケーション開発者に、ChatGPT をアプリケーション シナリオと統合し、その入力と出力を特定のアプリケーション イベントとアクションにマッピングするためのツールが提供されれば、モデルが不安定な動作をするのを防ぐための適切なガードレールを設定できるようになります。
基本的に、OpenAI は強力な人工知能ツールを作成しましたが、明らかな欠陥がありました。製品チームが ChatGPT の力を活用できるようにするには、開発ツールの適切なエコシステムを作成する必要があります。 GPT-3 は多くの予測不可能なアプリケーションへの道を開くので、ChatGPT が何を用意しているのかを知るのは興味深いでしょう。
元のリンク: https://bdtechtalks.com/2022/12/05/openai-chatgpt/
以上がユーザー数が 5 日間で 100 万人を突破、ChatGPT の背後にある謎とは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。