
ホームページ >テクノロジー周辺機器 >AI >PyTorch に負けました! GoogleがTensorFlowを放棄、JAXに賭ける
PyTorch に負けました! GoogleがTensorFlowを放棄、JAXに賭ける

- 王林転載
- 2023-05-04 08:16:061031ブラウズ
一部のネチズンの言葉がとても気に入っています。
「この子は本当に良くないので、別の子を手に入れましょう。」
Google は本当にこれを実行しました。
7 年間の開発を経て、TensorFlow は最終的に Meta の PyTorch にある程度まで敗北しました。
何かが間違っていると判断した Google は、すぐに別のフレームワーク、つまりまったく新しい機械学習フレームワークである「JAX」を求めました。

最近大人気の DALL・E Mini については皆さんご存知のとおり、そのモデルは JAX に基づいてプログラムされており、Google TPU によってもたらされる利点を最大限に活用しています。
TensorFlow の黄昏と PyTorch の台頭
2015 年、Google が開発した機械学習フレームワークである TensorFlow が登場しました。
当時、TensorFlow は Google Brain の小さなプロジェクトにすぎませんでした。
TensorFlow が登場してすぐに大人気になるとは誰も予想していませんでした。
Uber や Airbnb などの大企業だけでなく、NASA などの国家機関もこれを使用しています。そしてそれらはすべて、最も複雑なプロジェクトで使用されています。
2020 年 11 月の時点で、TensorFlow は 1 億 6,000 万回ダウンロードされました。
#しかし、Google は多くのユーザーの感情をあまり気にしていないようです。
奇妙なインターフェイスと頻繁なアップデートにより、TensorFlow はユーザーにとってますます不親切になり、操作がますます困難になります。
Google社内でも、このフレームワークは下り坂になりつつあると感じています。
実のところ、Google がこれほど頻繁に更新するのは本当に無力であり、結局のところ、これが機械学習の分野における急速な反復に追いつく唯一の方法なのです。
その結果、プロジェクトに参加する人が増え、チーム全体が徐々に集中力を失っていきました。
元々 TensorFlow を最適なツールにした輝かしい点は、非常に多くの要素に埋もれており、もはや真剣に受け止められていません。
この現象は、Insider によって「いたちごっこ」と表現されています。会社は猫のようなもので、絶え間ない反復によって新たなニーズが生まれてくるのはネズミのようなものです。猫は常に警戒を怠らず、ネズミに襲いかかる準備ができている必要があります。

#特定の市場に初めて参入する企業にとって、このジレンマは避けられません。
たとえば、検索エンジンに関する限り、Google が最初ではありません。したがって、Google は前任者 (AltaVista、Yahoo など) の失敗から学び、それを自社の開発に適用することができます。
残念ながら、TensorFlow に関して言えば、罠にかかっているのは Google です。
もともと Google で働いていた開発者は、まさに上記の理由により、以前の雇用主に対する信頼を徐々に失いました。
かつてはユビキタスだった TensorFlow は徐々に衰退し、Meta の新星である PyTorch に負けました。

2017 年に、PyTorch のベータ版がオープンソースになりました。
2018 年、Facebook の人工知能研究所は PyTorch の完全版をリリースしました。
PyTorch と TensorFlow は両方とも Python に基づいて開発されているのに対し、Meta はオープンソース コミュニティの維持により注意を払い、多くのリソースを投資していることにも言及する価値があります。
さらに、メタ社は Google の問題に注目しており、同じ過ちを繰り返すわけにはいかないと信じています。彼らは少数の機能に焦点を当て、それらを可能な限り最高のものにします。
Meta は Google の足跡をたどっていません。このフレームワークは Facebook で初めて開発され、徐々に業界のベンチマークになりました。
機械学習の新興企業の研究エンジニアは、「私たちは基本的に PyTorch を使用しています。そのコミュニティとオープンソースが最高です。すべての質問に答えてくれるだけでなく、与えられた例も非常に実用的です」と述べました。 ."

この状況に直面して、Google 開発者、ハードウェア専門家、クラウド プロバイダー、および Google 機械学習に関係する人は皆、インタビューで同じことを言い、TensorFlow は開発者の心を失ったと信じています。
一連の公然かつ秘密の闘争の後、メタはついに優位に立った。
一部の専門家は、Google が将来的に機械学習をリードし続ける機会は徐々に失われつつあると述べています。
PyTorch は、徐々に一般の開発者や研究者にとって最適なツールになってきました。
Stack Overflow によって提供されるインタラクション データから判断すると、開発者フォーラムでは PyTorch に関する質問がますます増えていますが、TensorFlow に関する質問は近年停滞しています。
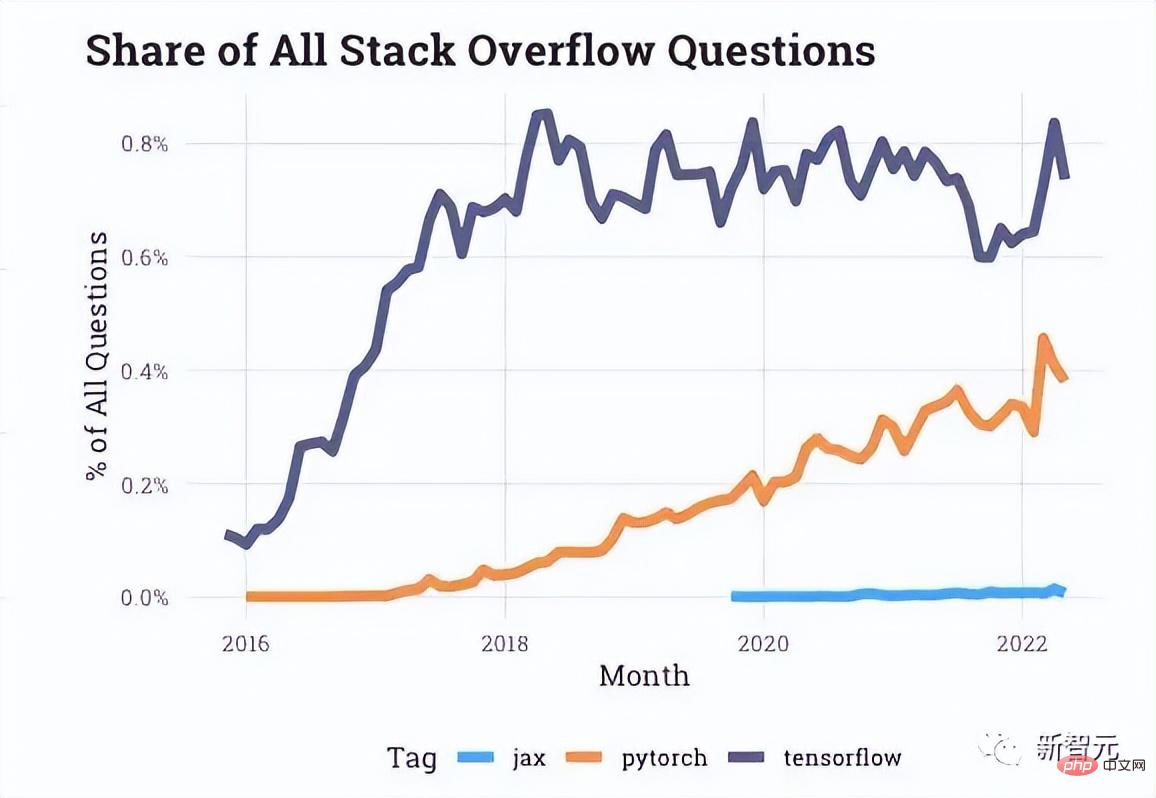
記事の冒頭で述べた Uber などの企業も PyTorch に注目しています。
実際、その後の PyTorch の更新はすべて、TensorFlow に対する平手打ちのように思えます。
Google 機械学習の将来 - JAX
TensorFlow と PyTorch が本格的に戦っていたちょうどそのとき、Google 内の「小規模なダークホース研究チーム」がまったく新しいフレームワークの開発に取り組み始めました。 . TPUをさらに便利にご利用いただけます。

2018 年、「高レベル トレースによる機械学習プログラムのコンパイル」というタイトルの論文により、JAX プロジェクトが表面化しました。著者は Roy Frostig と Matthew James でした。ジョンソンそしてクリス・リアリー。

左から右に、これら 3 人の偉大な神がいます。
そして、PyTorch のオリジナル作成者の 1 人である Adam Paszke も、2008 年に JAX にフルタイムで加わりました。 2020年初頭のチーム。

#JAX は、機械学習における最も複雑な問題の 1 つであるマルチコア プロセッサのスケジューリング問題に対処する、より直接的な方法を提供します。
JAX は、アプリケーションの状況に応じて、1 つを単独で使用するのではなく、複数のチップを自動的に小さなグループに結合します。
これの利点は、できるだけ多くの TPU が瞬時に応答し、それによって私たちの「錬金術の世界」を燃やすことができることです。
結局のところ、肥大化した TensorFlow と比較して、JAX は Google 内の大きな問題、つまり TPU に素早くアクセスする方法を解決しました。
以下は、JAX を構成する Autograd と XLA について簡単に説明します。
Autograd は主に勾配ベースの最適化に使用され、Python と Numpy コードを自動的に区別できます。
ループ、再帰、クロージャなどの Python のサブセットを処理するために使用でき、導関数の導関数も実行できます。
さらに、Autograd は勾配の逆伝播をサポートしています。つまり、配列値パラメーターに対するスカラー値関数の勾配と順モード微分を効果的に取得でき、両方を使用できます。任意の組み合わせ。
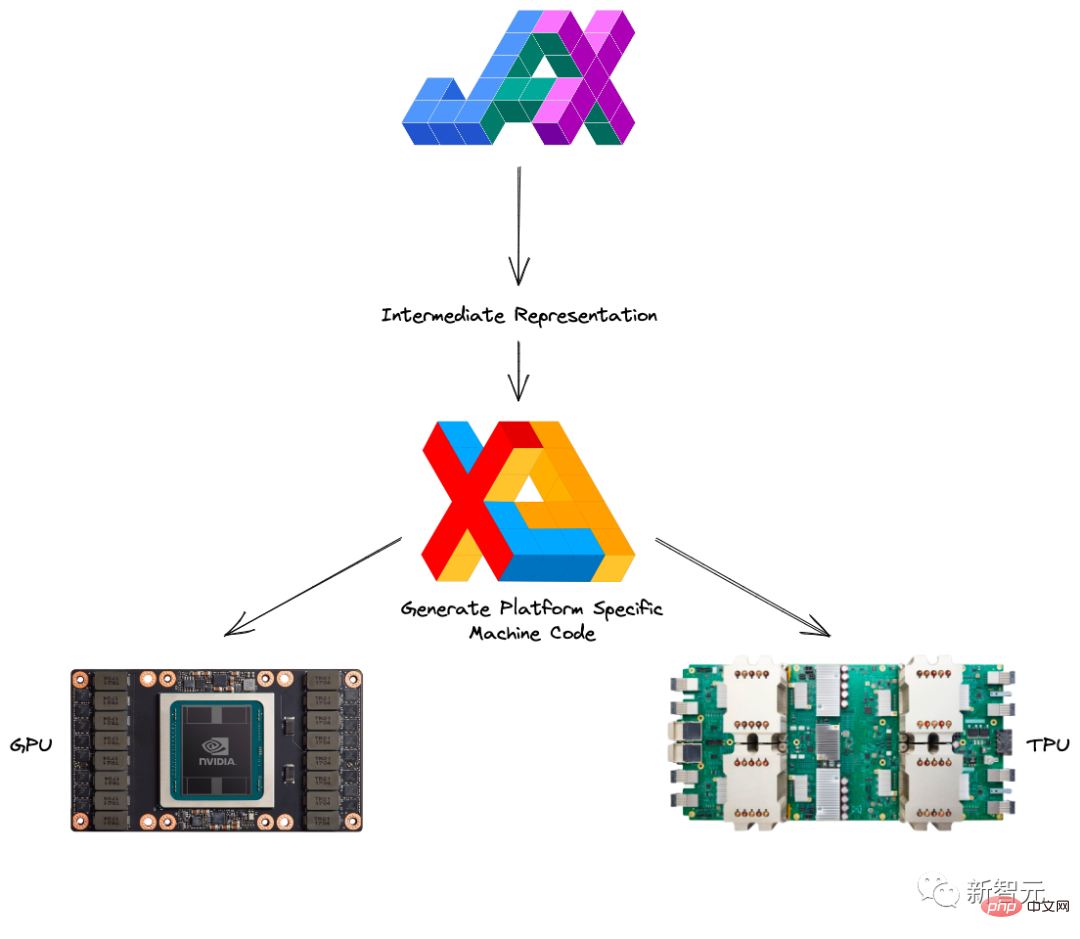
XLA (Accelerated Linear Algebra) は、ソース コードを変更せずに TensorFlow モデルを高速化できます。
プログラムの実行中、すべての操作は実行プログラムによって個別に実行されます。各オペレーションには、エグゼキュータがディスパッチされるプリコンパイルされた GPU カーネル実装があります。
例:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">def</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">model_fn</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">x</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">y</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">z</span>):<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">return</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">tf</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">reduce_sum</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">x</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">+</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">y</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">*</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">z</span>)
XLA なしで実行すると、この部分は 3 つのコア (乗算に 1 つ、加算に 1 つ、減算に 1 つ) を開始します。
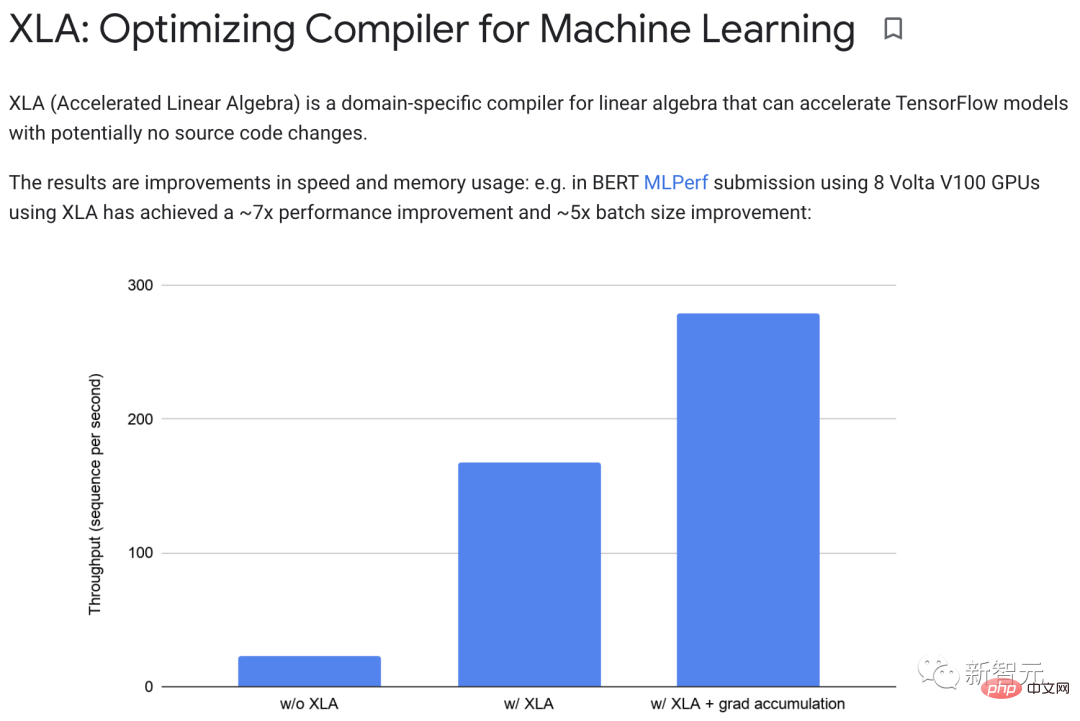
#XLA は、加算、乗算、減算を単一の GPU コアに「マージ」することで最適化を実現できます。 この融合操作は、メモリによって生成された中間値を y*z メモリ x y*z に書き込むのではなく、これらの中間計算の結果をユーザーに直接「ストリーミング」します。 GPUに保存されます。実際には、XLA は約 7 倍のパフォーマンス向上と約 5 倍のバッチ サイズの向上を達成できます。
さらに、XLA と Autograd は任意の方法で組み合わせることができ、pmap メソッドを使用して複数の GPU または TPU コアを同時にプログラミングすることもできます。
JAX と Autograd および Numpy を組み合わせることで、CPU、GPU、TPU 向けのプログラミングが簡単で高性能な機械学習システムを実現できます。
Google が今回教訓を学んだのは明らかで、自社製品を本格的に展開することに加えて、オープンソース エコシステムの構築の促進にも特に積極的です。
2020 年、DeepMind は正式に JAX の傘下に入り、これにより Google 自体の終了も発表され、それ以来、さまざまなオープンソース ライブラリが際限なく登場してきました。


「内紛」全体を見て、Jia Yangqing 氏は、TensorFlow を批判する過程で、AI システムは次のように信じていたと述べました。 Python の科学的研究がすべて必要でした。
しかし、純粋な Python ではソフトウェアとハードウェアの効率的な共同設計を実現できない一方で、上位レベルの分散システムでは依然として効率的な抽象化が必要です。
そして JAX はより良いバランスを模索しています。自らを覆すことをいとわない Google の実用主義は学ぶ価値があります。

原因 R パッケージと関連するベイズ分析教科書の著者は、Google が TF からよりクリーンなソリューションである JAX に移行したことをうれしく思っていると述べました。

Google の課題
Jax は新人として、2 つの古い前任者である PyTorch と TensorFlow の利点から学ぶことができますが、時には後発者になる可能性があります。 . デメリットも伴います。

まず第一に、JAX はまだ「若く」、実験的なフレームワークとして、成熟した Google 製品の基準には程遠いです。
さまざまな隠れたバグに加えて、JAX はいくつかの問題について依然として他のフレームワークに依存しています。
データのロードと前処理では、ほとんどの設定を処理するために TensorFlow または PyTorch を使用する必要があります。
明らかに、これは理想的な「ワンストップ」フレームワークにはまだ程遠いです。

第 2 に、JAX は主に TPU に対して高度に最適化されていますが、GPU と CPU に関してはさらに最適化されていません。
一方で、2018 年から 2021 年にかけての Google の組織的および戦略的混乱により、GPU をサポートするための研究開発資金が不足し、関連問題への対処の優先順位が低くなりました。
同時に、彼らはおそらく、AI 高速化において自社の TPU がより多くの役割を担うことに集中しすぎているのでしょう。当然のことながら、GPU サポートなどの詳細を改善することはおろか、NVIDIA との協力も非常に不足しています。
一方、Google 自身の内部研究は、言うまでもなくすべて TPU に焦点を当てているため、Google は GPU 使用率に関する良好なフィードバック ループを失うことになります。
さらに、デバッグ時間の延長、Windows との互換性のなさ、副作用を追跡できないリスクなど、すべてが Jax の敷居と親しみやすさを高めます。
現在、PyTorch は誕生してからほぼ 6 年になりますが、当時の TensorFlow に見られたような衰退はありません。
ジャックスが後発選手たちに追いつきたいと思うなら、まだまだ道のりは長いようだ。
以上がPyTorch に負けました! GoogleがTensorFlowを放棄、JAXに賭けるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。