
ホームページ >テクノロジー周辺機器 >AI >脳の階層的予測により、大規模なモデルがより効率的になります。
脳の階層的予測により、大規模なモデルがより効率的になります。

- 王林転載
- 2023-05-03 14:37:061737ブラウズ
1,000 億個のニューロンがあり、各ニューロンには約 8,000 のシナプスがあり、脳の複雑な構造は人工知能の研究にインスピレーションを与えています。
#現在、ほとんどの深層学習モデルのアーキテクチャは、生物学的な脳のニューロンにヒントを得た人工ニューラル ネットワークです。
Generative AI が爆発的に爆発し、深層学習アルゴリズムが 、能力を生成しているのがわかりますテキストを要約、翻訳、分類する機能はますます強力になっています。
#しかし、これらの言語モデルは依然として人間の言語能力に匹敵するものではありません。
# 予測コーディング理論では、この違いについて暫定的な説明を提供します。
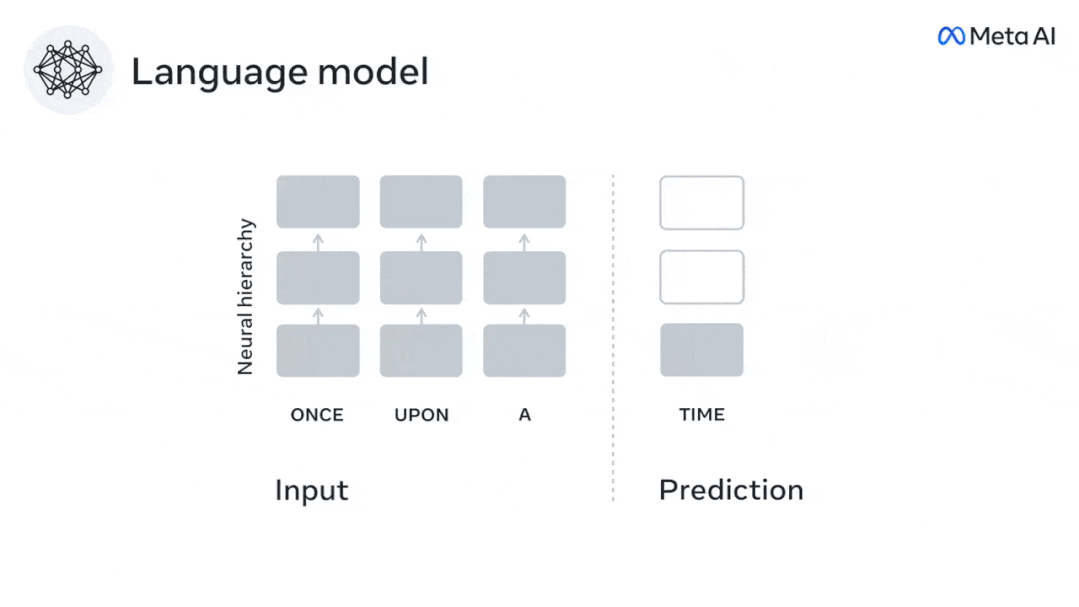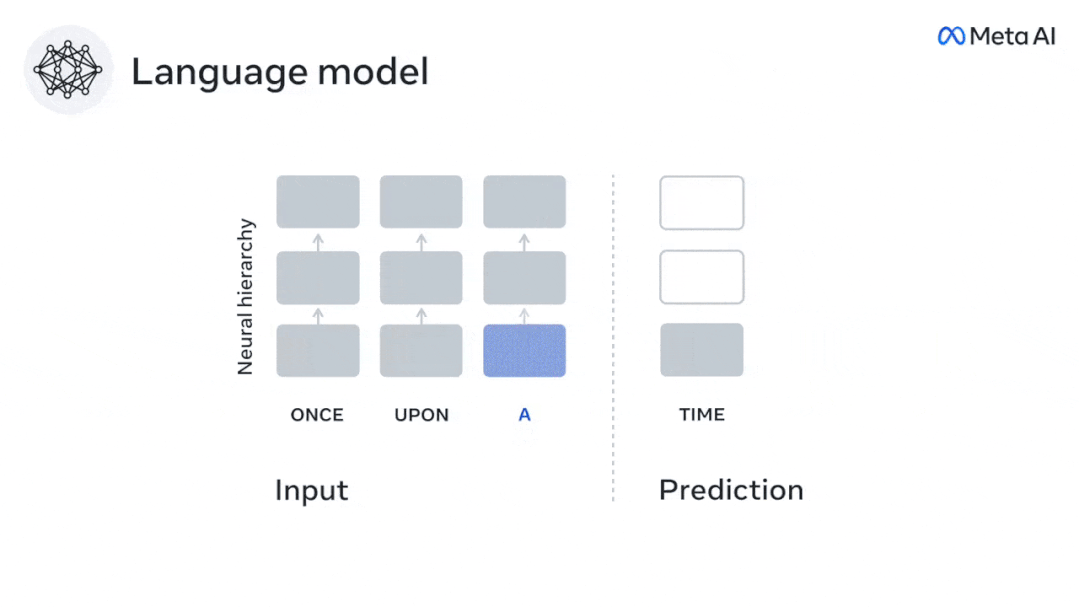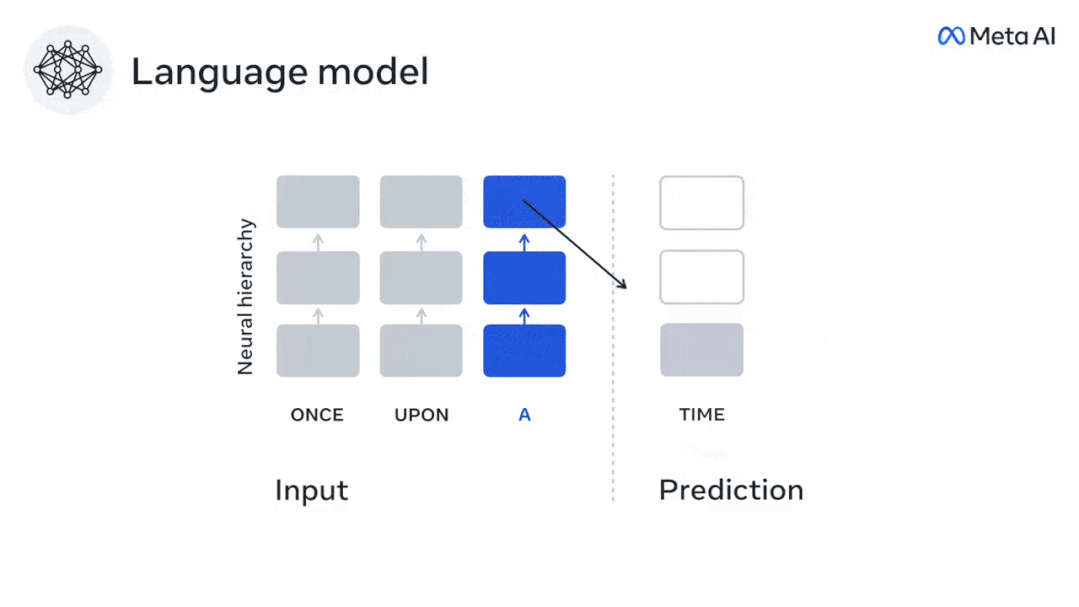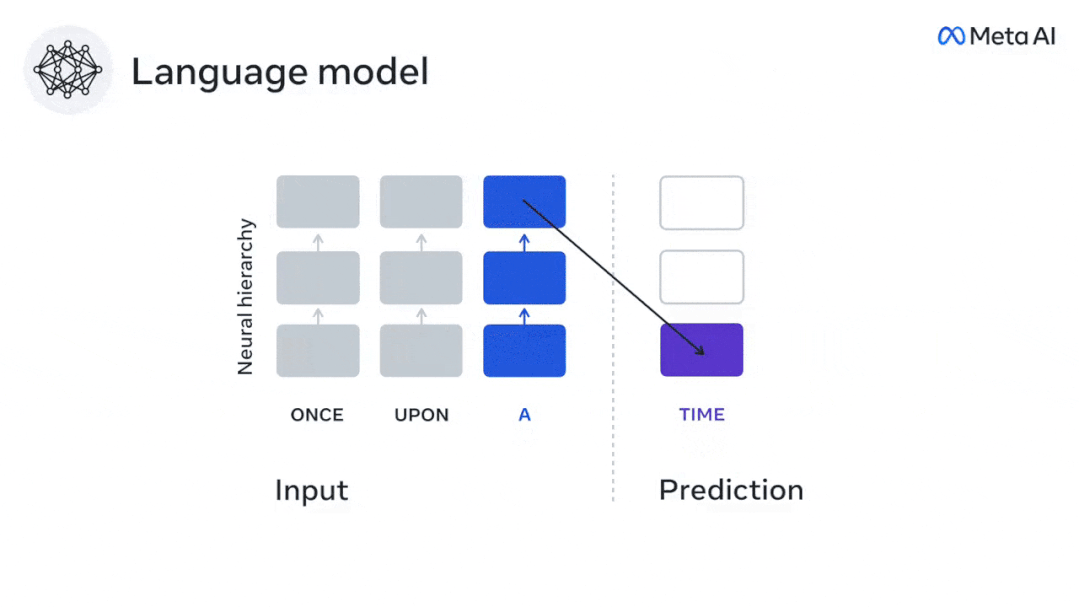
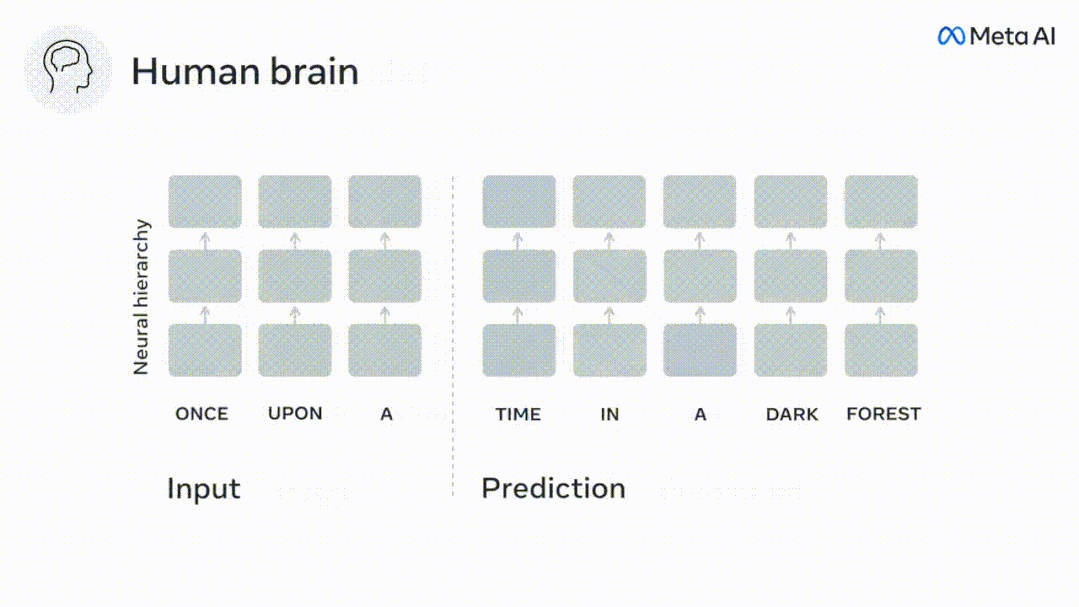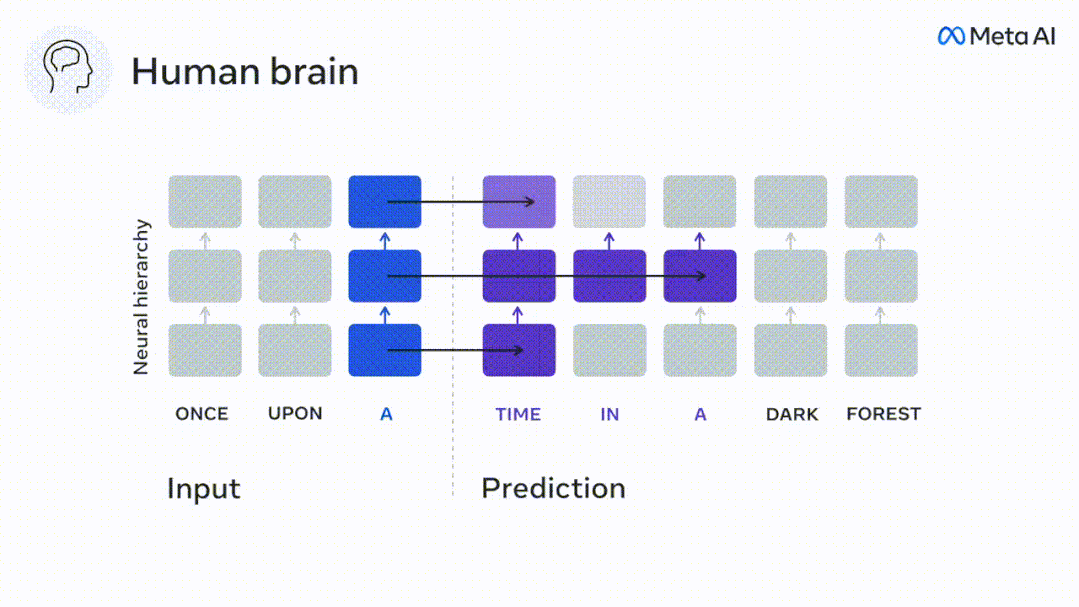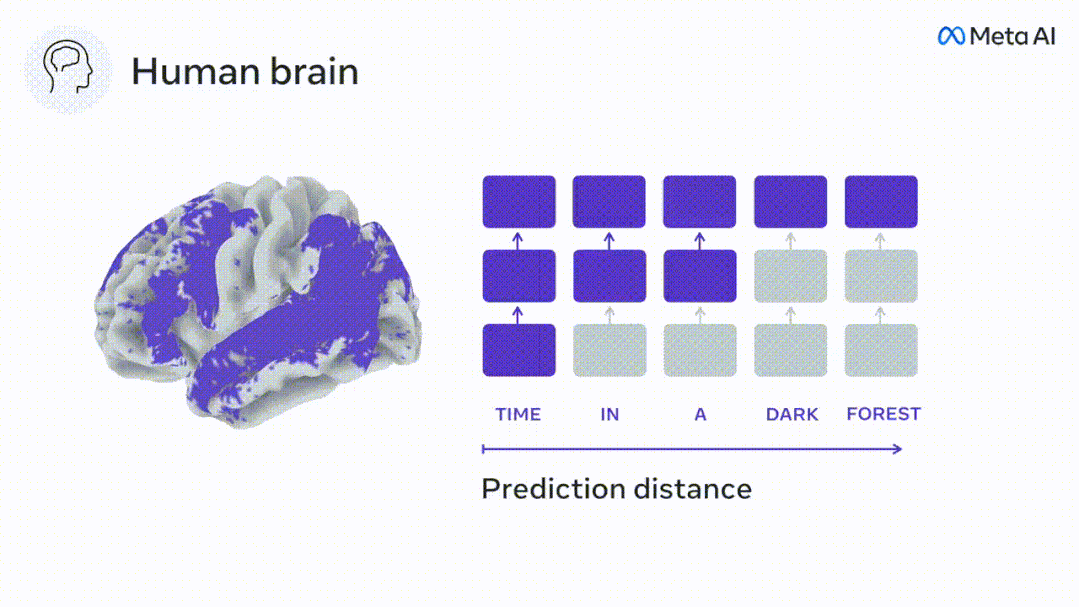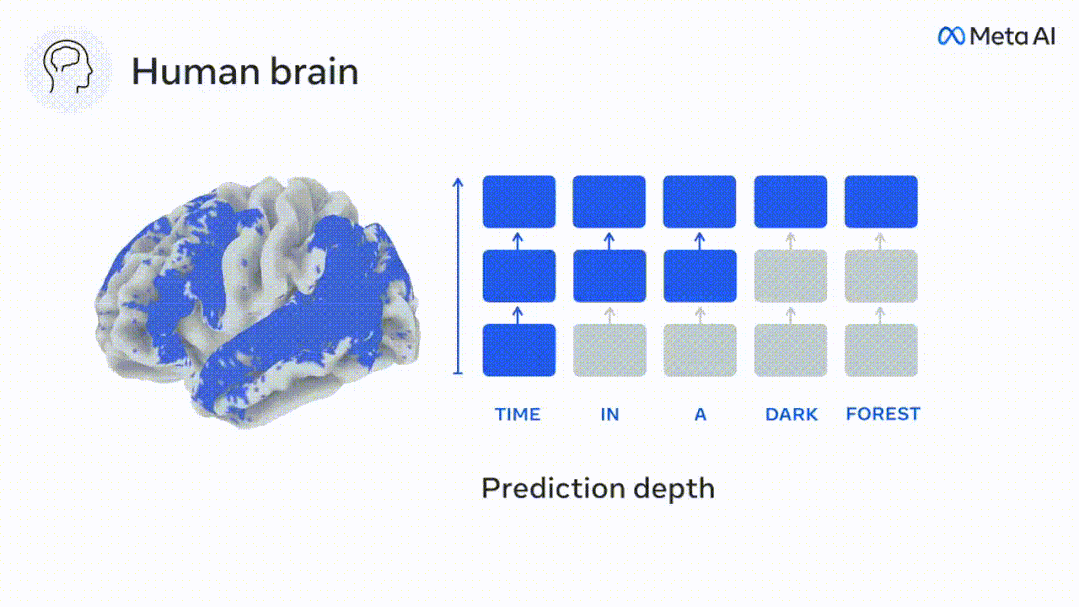
言語モデルは近くの単語を予測できますが、人間の脳は常に複数の時間スケールにわたる表現の層を予測します。
この仮説を検証するために、Meta AI の科学者たちは、短編小説を聞いた 304 人の脳の fMRI 信号を分析しました。
#階層型予測コーディングは言語処理において重要な役割を果たしていると結論付けられています。
#一方、神経科学と人工知能の相乗効果によって、人間の認知の計算基盤がどのように解明されるのかが研究によって明らかにされています。
#最新の研究は、Nature サブジャーナル Nature Human Behavior に掲載されました。

#実験中に GPT-2 が使用されたことは言及する価値があります。おそらくこの研究は、将来 OpenAI の未開封モデルにインスピレーションを与える可能性があります。
その頃には ChatGPT はさらに強力になっているのではないでしょうか?
脳の予測コーディング階層
ディープ ラーニングは、3 年足らずでテキストの生成と翻訳において大きな進歩を遂げました。 - 訓練されたアルゴリズム: 近くのコンテキストに基づいて単語を予測します。
#注目すべきことに、これらのモデルによる活性化は、音声とテキストに対する脳の反応に線形にマッピングされることが示されています。
さらに、このマッピングは主に将来の単語を予測するアルゴリズムの能力に依存しているため、この目標は脳のような計算に収束するには十分であることを示唆しています。
#しかし、これらのアルゴリズムと脳の間には依然としてギャップが存在します。大量のトレーニング データにもかかわらず、現在の言語モデルは、要約するような長い物語を生成することができません。一貫した会話と情報検索に挑戦します。
#アルゴリズムは一部の構文構造と意味論的特性を捕捉できず、言語の理解も非常に表面的なものであるためです。
#たとえば、アルゴリズムは、ネストされたフレーズ内の主語に動詞を誤って割り当てる傾向があります。
「男が持っている鍵はここにあります」
同様に、次の単語のみに最適化された予測を生成する場合、深層言語モデルは当たり障りのない一貫性のないシーケンスを生成したり、無限に繰り返されるループに陥ったりする可能性があります。
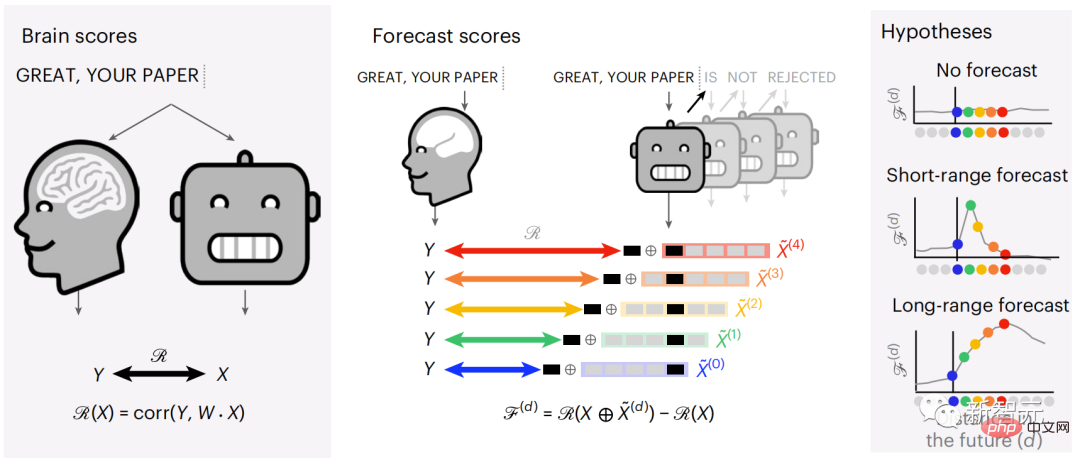
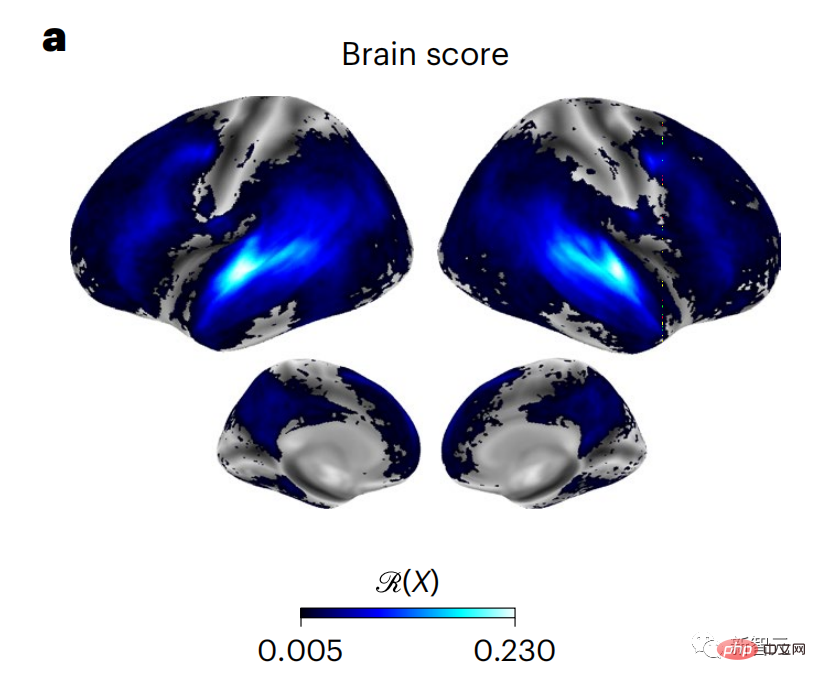
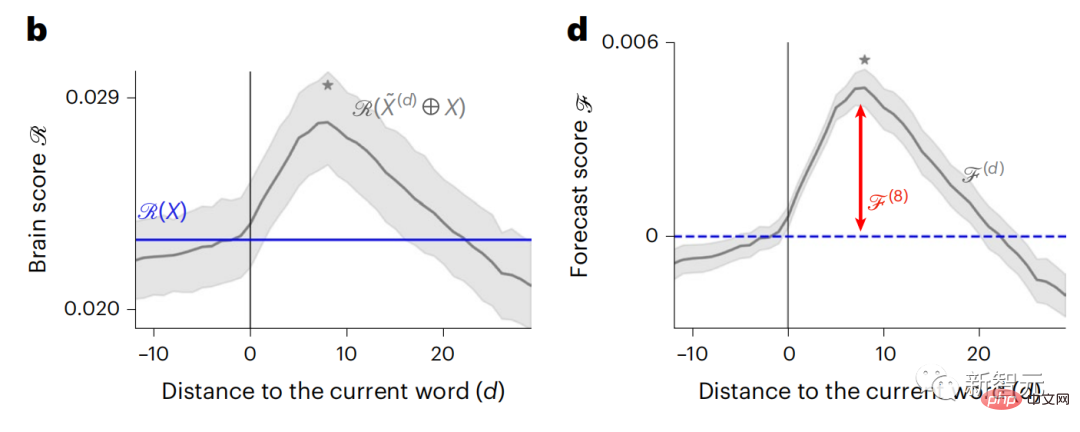
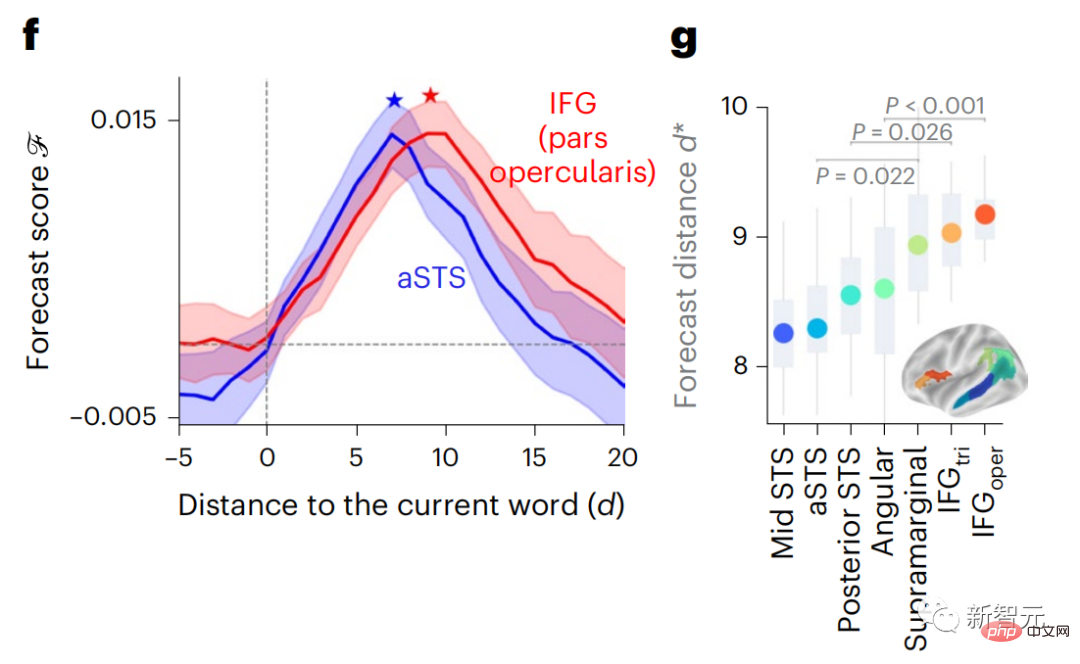
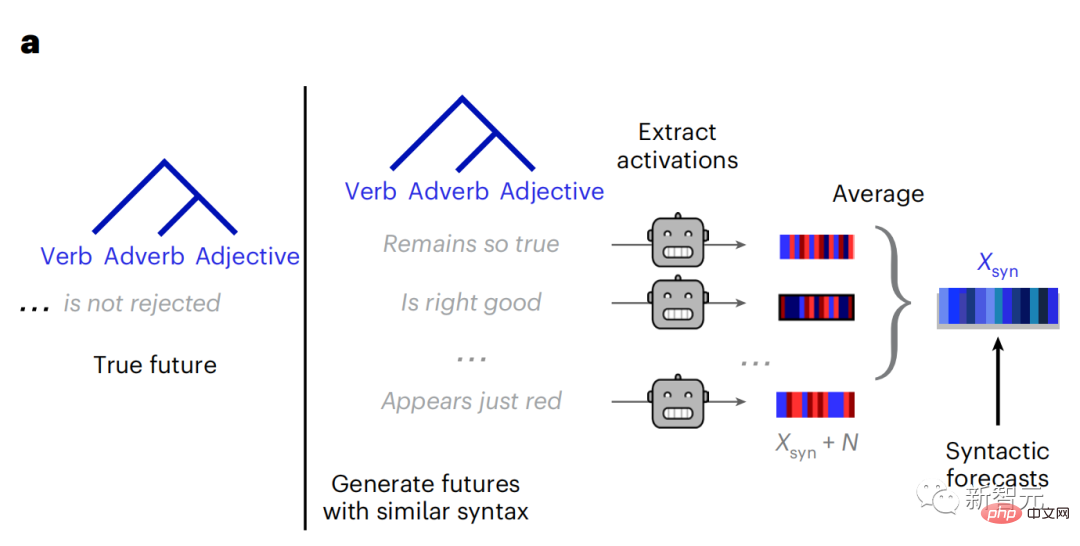
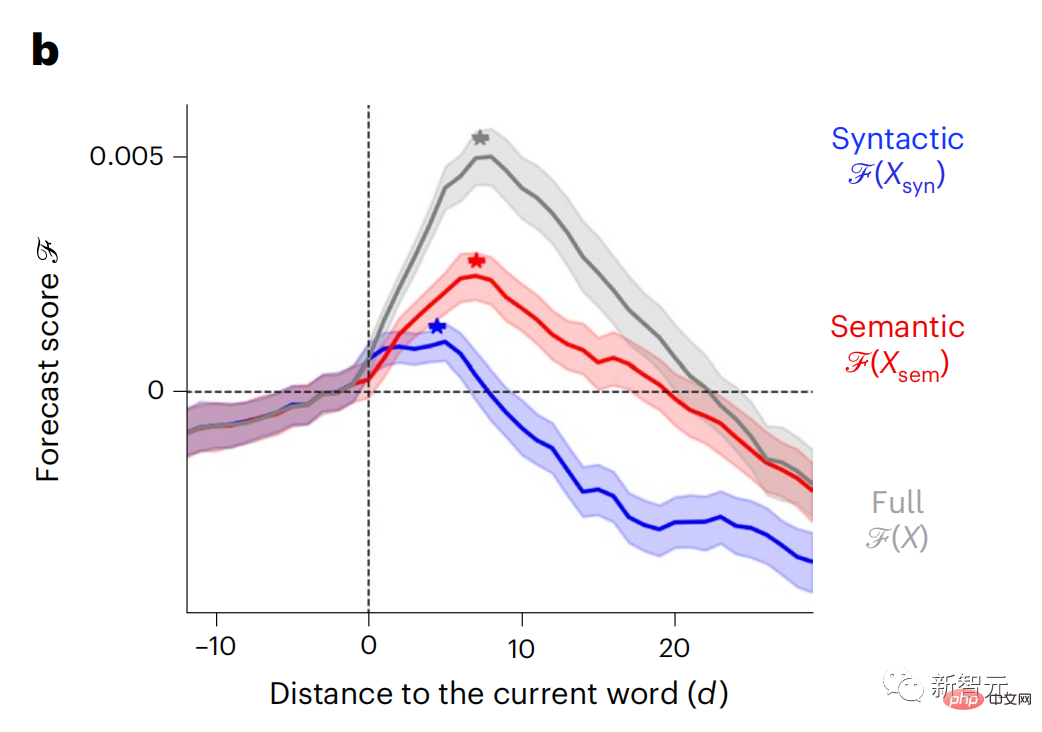
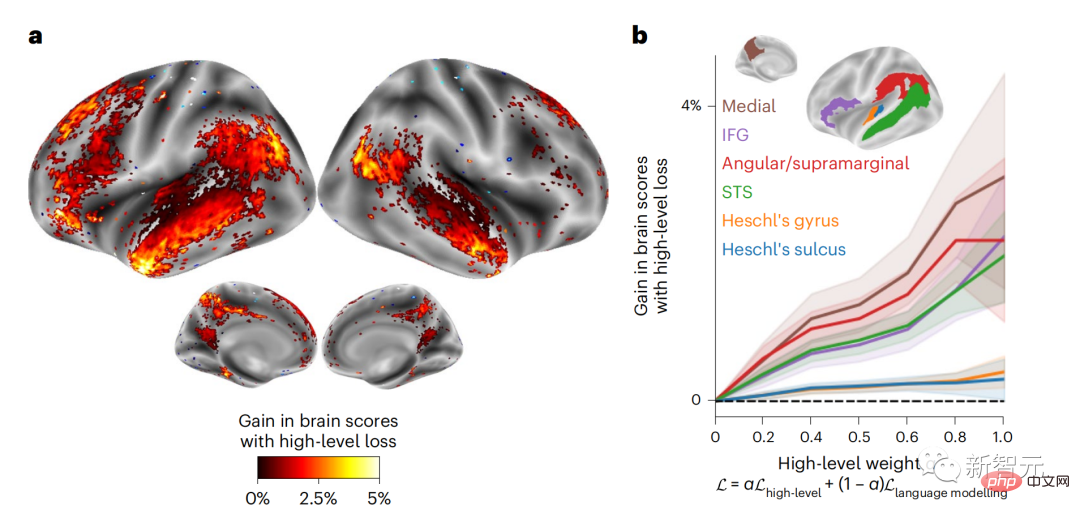
現時点では、予測コーディング理論がこの欠陥の潜在的な説明を提供しています: 深層言語モデルは主に、コードの予測に使用されます。次の言葉ですが、このフレームワークは、人間の脳が複数の時間スケールと皮質レベルの表現で予測できることを示しています。 これまでの研究では、脳内の音声予測、つまり単語や音素が機能的予測とよく相関していることが実証されています。磁気共鳴画像法 (fMRI)、脳波検査、脳磁図および皮質電図検査は相関していました。 #次の単語または音素を予測するようにトレーニングされたモデルは、その出力を単一の数値 (次の記号の確率) に減らすことができます。 # ただし、予測表現の性質と時間スケールはほとんどわかっていません。 #この研究では、研究者らは 304 人から fMRI 信号を抽出し、各人に約 26 分間聞いてもらいました。数分の短編小説 (Y) を入力し、同じ内容を入力して言語アルゴリズムをアクティブにします (X)。 X と Y の類似性は、「脳スコア」、つまり最良の線形マッピング後のピアソン相関係数 (R) によって定量化されます。 W 。 #予測された単語の表現を追加することでこの相関関係が改善されるかどうかをテストするには、ネットワークのアクティブ化 (黒い四角形 X) を変更します。 ) は予測ウィンドウ (色付きの四角形 ~X) に接続され、PCA を使用して予測ウィンドウの次元を X の次元に削減します。 最後に、F は、言語アルゴリズムによるこの予測ウィンドウの活性化を強化することによって得られる脳スコアのゲインを定量化します。異なる距離ウィンドウを使用してこの分析 (d) を繰り返します。 #これらのアルゴリズムを複数の時間スケールにわたる予測、つまり長距離予測と階層予測で強化することで、この脳のマッピングを改善できることがわかりました。 #最終的に、実験結果により、これらの予測は階層的に組織化されていることがわかりました。前頭葉皮質は、側頭葉皮質よりも高いレベル、より広い範囲、より多くの予測を予測します。コンテキスト表現。 深層言語モデルは脳活動にマッピング # 研究者らは、入力内容が同じ場合の深層言語モデルと脳との類似性を定量的に研究しました。 Narratives データセットを使用して、短編小説を聞いた 304 人の fMRI (機能的磁気共鳴画像法) が分析されました。 各ボクセルと各実験個体の結果に対して独立した線形リッジ回帰を実行し、いくつかの深層言語モデルの活性化から生じる fMRI 信号を予測します。 保持されたデータを使用して、対応する「脳スコア」、つまり fMRI 信号と得られたリッジ回帰予測結果の間の相関が計算されました。指定された言語モデル刺激セックスを入力することによって。 わかりやすくするために、まず GPT-2 の第 8 層の活性化に焦点を当てます。GPT-2 は、HuggingFace2 を利用した 12 層の因果的ディープ ニューラル ネットワークです。予測的な脳活動。 以前の研究と一致して、GPT-2 活性化は両側の脳領域の分散セットに正確にマッピングされ、脳スコアは聴覚皮質と前側頭領域および上側頭領域でピークに達しました。 メタチームはその後長距離予測機能を備えた言語モデルの刺激を増やすと、脳スコアが向上するかどうかをテストしました。 #研究者らは、単語ごとに、現在の単語のモデルのアクティブ化を、将来の単語で構成される「予測ウィンドウ」に関連付けました。予測ウィンドウの表現パラメーターには、ウィンドウ内の現在の単語と将来の最後の単語の間の距離を表す d と、連結された単語の数を表す w が含まれます。各 d について、予測表現ありとなしの脳スコアを比較し、「予測スコア」を計算します。 #その結果、d=8 のときに予測スコアが最も高く、言語処理に関係する脳領域にピーク値が現れることがわかりました。 d=8 は 3.15 秒の音声に相当し、これは 2 回の連続する fMRI スキャンの時間です。予測スコアは、下前頭回および縁上回を除き、脳の両側に分布しました。 補足分析を通じて、チームは次の結果も得ました: (1) 現在の単語から 0 ~ 10 の距離にある未来の各単語には、有意な意味があります。 ; (2) 予測表現は約 8 単語のウィンドウ サイズで最もよくキャプチャされます; (3) ランダムな予測表現は脳スコアを改善できません; (4) 実際の未来の単語と比較して、GPT-2 で生成された単語は、同様の結果が得られますが、スコアは低くなります。 解剖学と脳の層に沿って変化します。機能研究により、大脳皮質は階層的であることが示されています。予測時間枠は皮質の異なるレベルで同じですか? #研究者らは、各ボクセルのピーク予測スコアを推定し、その対応する距離を d として表しました。 結果は、前頭前野領域の予測ピークに対応する d が、平均して側頭葉領域のものよりも大きいことを示しました (図 2e)。下側頭回のd 上側頭溝よりも大きい。
構文と意味予測の時間範囲は異なります
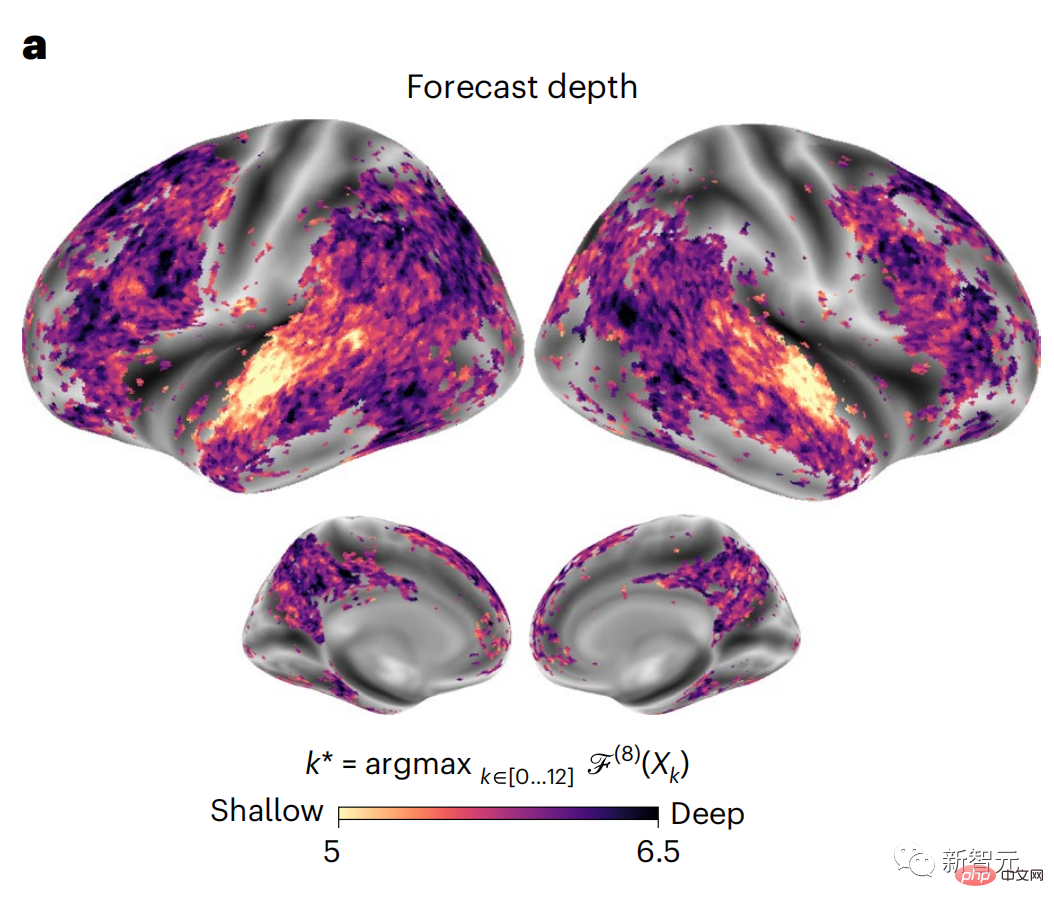
これらの結果は、脳における複数のレベルの予測を明らかにしています。上位側頭葉皮質は主に短期的で浅い構文表現を予測し、下前頭葉と頭頂葉領域は主に長期的な表現を予測します。文脈的、高レベルの構文表現、意味表現。 予測される背景は脳階層に沿ってより複雑になります 以前と同様このメソッドは予測スコアを計算しますが、各ボクセルの k (予測スコアが最大化される深さ) を決定するための GPT-2 レイヤーの使用を変更します。 私たちの結果は、最適な予測深度は予想される皮質階層に沿って変化し、最良のモデルは下位レベルの言語野よりも連合皮質の深部を予測することを示しています。領域間の違いは、平均すると小さいですが、個人によっては非常に顕著です。 一般に、前頭皮質における長期予測は、下位皮質における短期予測よりも複雑な背景を持っています。 -レベルの脳領域 レベルが高くなります。 GPT-2 を予測符号化構造に調整する GPT-2 の現在の単語と将来の単語を調整するこれらの表現を連結して、特に前頭部の脳活動のより適切なモデルを取得できます。 GPT-2 を微調整して、より遠い距離、より豊富な背景、より高い階層レベルでの表現を予測することで、これらの領域の脳マッピングを改善できるでしょうか? 調整では、言語モデリングだけでなく、高レベルのターゲットや長距離のターゲットも使用されます。 -トレーニング済み GPT -2 モデルのレイヤー 8。 その結果、GPT-2 を高レベルおよび長距離モデリングのペアで微調整すると、前頭葉の反応が最もよく改善される一方で、聴覚野と下位領域の反応が最も改善されることがわかりました。脳領域のレベルは、そのような高レベルのターゲティングから大きな恩恵を受けず、言語の長距離、文脈、および高レベルの表現を予測する際の前頭領域の役割をさらに反映しています。 参考: https:/ / www.php.cn/link/7eab47bf3a57db8e440e5a788467c37f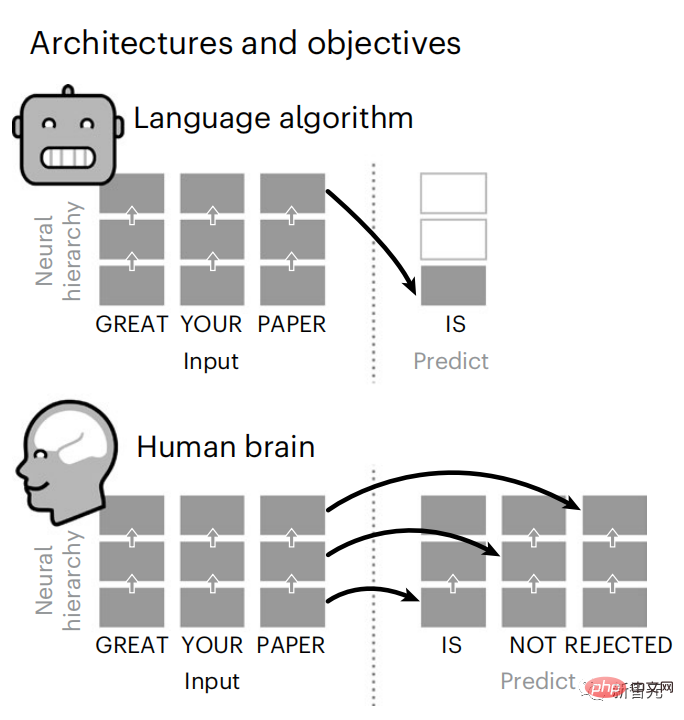
 #
#
以上が脳の階層的予測により、大規模なモデルがより効率的になります。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。