
ホームページ >バックエンド開発 >Python チュートリアル >Python での単語頻度統計とキーワード抽出に Jieba を使用する方法
Python での単語頻度統計とキーワード抽出に Jieba を使用する方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-02 19:46:054515ブラウズ
1 単語頻度統計
1.1 単純な単語頻度統計
1. jieba ライブラリをインポートし、テキスト
import jieba text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"
2. セグメントを定義します。テキスト
words = jieba.cut(text)
このステップでは、テキストをいくつかの単語に分割し、ジェネレーター オブジェクト words を返します。for を使用すると、すべての単語をループできます。
3. 単語の頻度をカウントする
word_count = {}
for word in words:
if len(word) > 1:
word_count[word] = word_count.get(word, 0) + 1このステップでは、すべての単語を対象に、各単語の出現回数をカウントし、辞書に保存しますword_count。単語の頻度をカウントする場合、ストップ ワードを削除することで最適化を実行できますが、ここでは長さが 2 未満の単語を単純にフィルター処理します。
4. 結果の出力
for word, count in word_count.items():
print(word, count)
1.2 ストップワードの追加
単語の出現頻度をより正確にカウントするために、単語頻度統計における単語頻度 ストップワードを追加して、一般的だが意味のない単語を削除します。具体的な手順は次のとおりです。
ストップワード リストを定義する
import jieba # 停用词列表 stopwords = ['是', '一种', '等']
テキストを分割し、ストップワードをフィルタリングする
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。" words = jieba.cut(text) words_filtered = [word for word in words if word not in stopwords and len(word) > 1]
ワードの頻度をカウントし、結果を出力する
word_count = {}
for word in words_filtered:
word_count[word] = word_count.get(word, 0) + 1
for word, count in word_count.items():
print(word, count)ストップ ワードを追加した後の出力結果は次のとおりです。

無効な単語 kind of が表示されていないことがわかります。
2 キーワード抽出
2.1 キーワード抽出原理
単純に単語をカウントする単語頻度統計とは異なり、jieba のキーワード抽出原理は TF-IDF (用語頻度-逆ドキュメント頻度) アルゴリズム。 TF-IDF アルゴリズムは、テキスト内の単語の重要性を測定できる、一般的に使用されるテキスト特徴抽出方法です。
具体的には、TF-IDF アルゴリズムには 2 つの部分が含まれています:
用語頻度: 単語がテキスト内に出現する回数を指し、通常は単純な統計を使用します。単語頻度、バイグラム単語頻度などの値表現。単語の頻度はテキスト内の単語の重要性を反映しますが、コーパス全体における単語の普及率は無視されます。
逆ドキュメント頻度: すべてのドキュメントに出現する単語の頻度の逆数を指し、単語の普及率を測定するために使用されます。逆文書頻度が大きいほど、単語はより一般的であり、重要度は低くなります。逆文書頻度が小さいほど、単語はよりユニークで重要度が高くなります。
TF-IDF アルゴリズムは、単語頻度と逆文書頻度を総合的に考慮してテキスト内の各単語の重要度を計算し、キーワードを抽出します。 jieba では、キーワード抽出の具体的な実装には次の手順が含まれます。
テキストに対して単語分割を実行し、単語分割結果を取得します。
テキスト内に各単語が出現する回数を数え、単語の頻度を計算します。
すべての文書内で各単語が出現する回数を数え、文書頻度の逆数を計算します。
単語頻度と逆文書頻度を総合的に考慮して、テキスト内の各単語の TF-IDF 値を計算します。
TF-IDF 値を並べ替え、最もスコアの高い単語をキーワードとして選択します。
例 :
F (用語頻度) は、文書内に出現する特定の単語の頻度を指します。計算式は次のとおりです。
T F = (文書内での単語の出現回数) / (文書内の総単語数)
たとえば、100 個の単語が含まれる文書内で、ある単語が出現するとします。 10 倍すると、単語の TF は
10 / 100 = 0.1 になります。
IDF (逆文書頻度) は、文書コレクション内で特定の単語が出現する文書の数の逆数を指します。計算式は次のとおりです。
I D F = log (文書コレクション内の文書の総数/その単語が含まれる文書の数)
たとえば、1,000 個の文書が含まれる文書コレクションでは、ある単語が 100 個の文書に出現します。そうであれば、単語の IDF は log (1000 / 100) = 1.0
TFIDF は TF と IDF を掛け合わせた結果であり、計算式は次のとおりです:
T F I D F = T F ∗ I D F
TF-IDF アルゴリズムでは、テキスト内の単語の出現のみが考慮され、単語間の相関関係は無視されることに注意してください。したがって、一部の特定のアプリケーション シナリオでは、単語ベクトル、トピック モデルなど、他のテキスト特徴抽出方法を使用する必要があります。
2.2 キーワード抽出コード
import jieba.analyse
# 待提取关键字的文本
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"
# 使用jieba提取关键字
keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=True)
# 输出关键字和对应的权重
for keyword, weight in keywords:
print(keyword, weight)この例では、まず jieba.analyse モジュールをインポートし、キーワードとして抽出するテキストを定義しましたtext 。次に、jieba.analyse.extract_tags() 関数を使用してキーワードを抽出します。topK パラメータは抽出するキーワードの数を示し、withWeight パラメータは、キーワードの重み値を返すかどうかを示します。最後に、キーワード リストを反復処理して、各キーワードとそれに対応する重み値を出力します。
この関数の出力結果は次のとおりです:
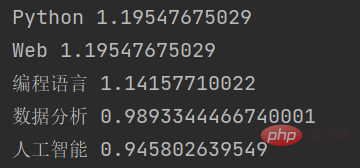
ご覧のとおり、jieba は TF-IDF アルゴリズムに基づいて入力テキスト内の複数のキーワードを抽出し、各キーワードの重み値を返します。
以上がPython での単語頻度統計とキーワード抽出に Jieba を使用する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。