
ホームページ >テクノロジー周辺機器 >AI >「ChatGPT検索」4機種を徹底比較!スタンフォード大学の中国人医師による手書きの注釈: New Bing は流暢さが最も低く、文のほぼ半分が引用されていません。
「ChatGPT検索」4機種を徹底比較!スタンフォード大学の中国人医師による手書きの注釈: New Bing は流暢さが最も低く、文のほぼ半分が引用されていません。

- 王林転載
- 2023-05-01 23:28:09994ブラウズ
ChatGPT のリリースから間もなく、Microsoft は「New Bing」の立ち上げに成功し、株価が急騰しただけでなく、Google に取って代わり、検索エンジンの新時代をもたらす恐れすらありました。
しかし、New Bing は本当に大規模な言語モデルを実行する正しい方法なのでしょうか?生成された回答は実際にユーザーにとって有益ですか?文中の引用はどの程度信憑性がありますか?
最近、スタンフォード大学の研究者は、さまざまなソースから大量のユーザー クエリを収集し、4 つの一般的な生成検索エンジン、Bing Chat、NeevaAI を分析しました。人間の評価は perplexity.ai と YouChat によって実行されました。 。

# 論文リンク: https://arxiv.org/pdf/2304.09848.pdf
実験の結果、既存の生成検索エンジンからの応答は流暢で有益ですが、証拠のない記述や不正確な引用が含まれることが多いことがわかりました。
平均すると、生成された文を完全に裏付けることができるのは引用の 51.5% だけであり、関連する文の証拠の裏付けとして使用できるのは引用の 74.5% だけです。
研究者らは、特に一部の文がもっともらしいものであることを考慮すると、この結果は、情報を求めるユーザーの主要なツールとなる可能性のあるシステムにとっては低すぎると考えています。生成検索エンジンにはまださらなる改善が必要です。最適化。

個人ホームページ: https://cs.stanford.edu/~nfliu/ #筆頭著者の Nelson Liu は、スタンフォード大学の自然言語処理グループの博士課程 4 年生です。指導教官は Percy Liang です。彼はワシントン大学を卒業し、学士号を取得しています。彼の主な研究方向は構築です。実用的な NLP システム、特に情報検索のアプリケーション。
生成検索エンジンを信頼しないでください
2023 年 3 月、Microsoft は、「デイリー プレビュー ユーザーの約 3 分の 1 が毎日 [Bing] の「チャット」を使用している」と報告しました。 、Bing Chat は、パブリック プレビューの最初の 1 か月で 4,500 万のチャットを提供しました。言い換えれば、大規模な言語モデルを検索エンジンに統合することは非常に市場性があり、インターネットへの検索の入り口を変える可能性が非常に高いです。
 しかし、大規模言語モデル技術に基づく既存の生成検索エンジンは、依然として精度が低いという問題を抱えているのが現状です。検索エンジンの機能はまだ十分に評価されておらず、新しい検索エンジンの制限もまだ完全には理解されていません。
しかし、大規模言語モデル技術に基づく既存の生成検索エンジンは、依然として精度が低いという問題を抱えているのが現状です。検索エンジンの機能はまだ十分に評価されておらず、新しい検索エンジンの制限もまだ完全には理解されていません。
検証可能性
は、検索エンジンの信頼性を向上させるための鍵であり、生成された回答内の各文の引用への外部リンクを提供します。これにより、ユーザーは回答の正確性を簡単に確認できるようになります。 研究者らは、さまざまな種類やソースから質問を収集することにより、4 つの商用生成検索エンジン (Bing Chat、NeevaAI、perplexity.ai、YouChat) について手動評価を実施しました。
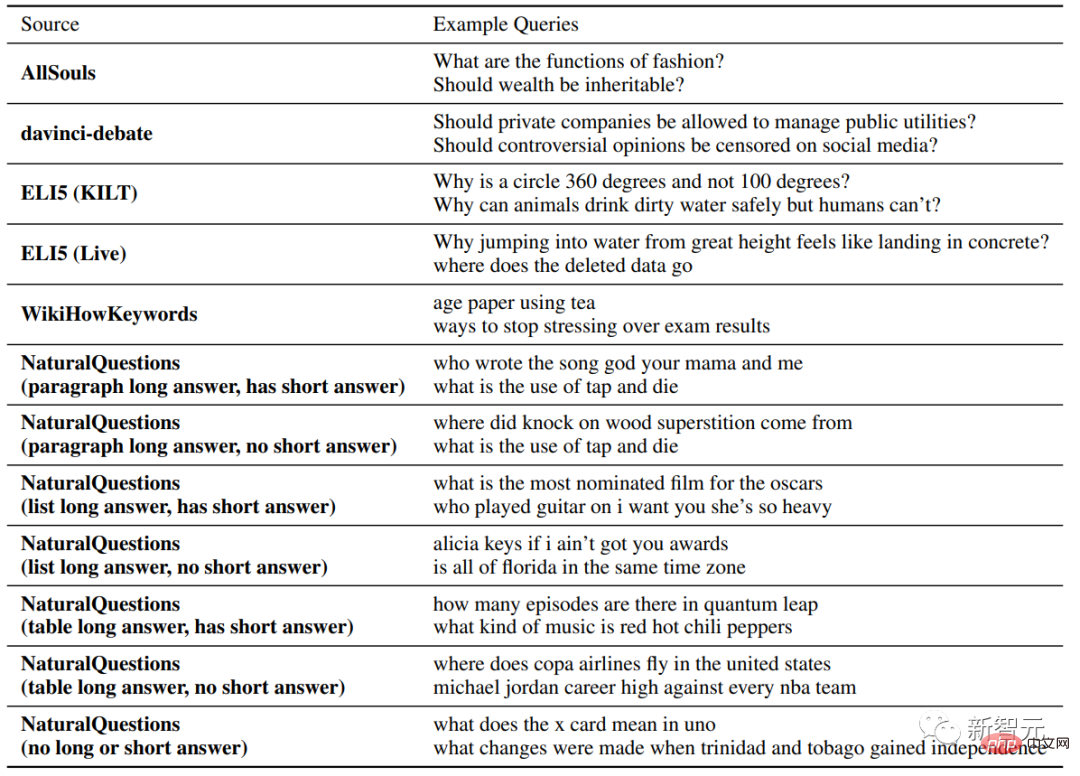
##評価指標
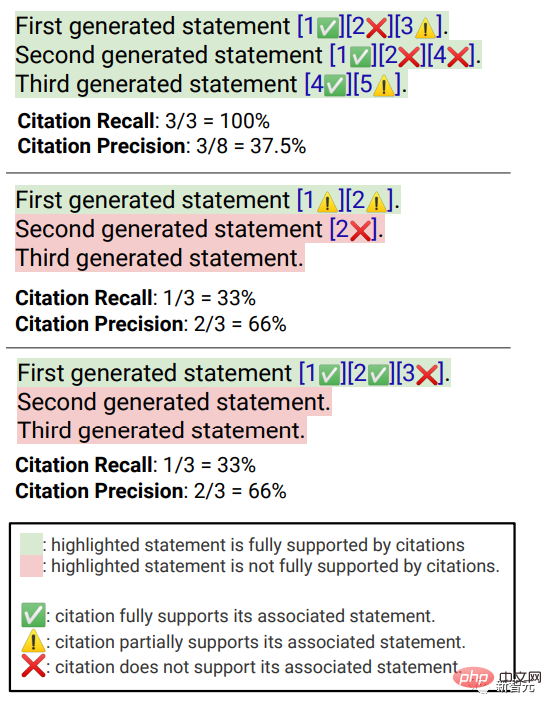
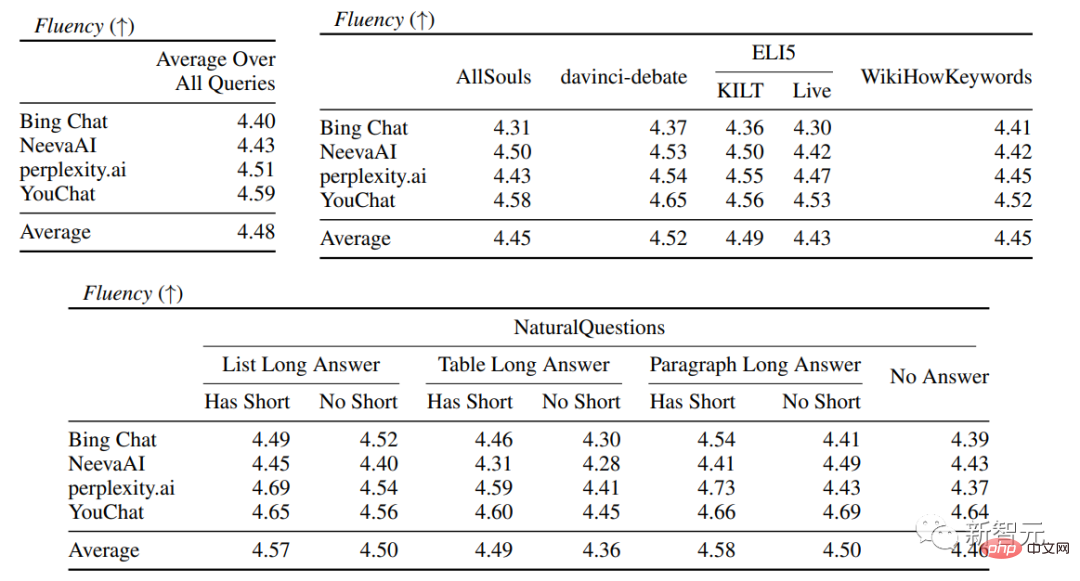
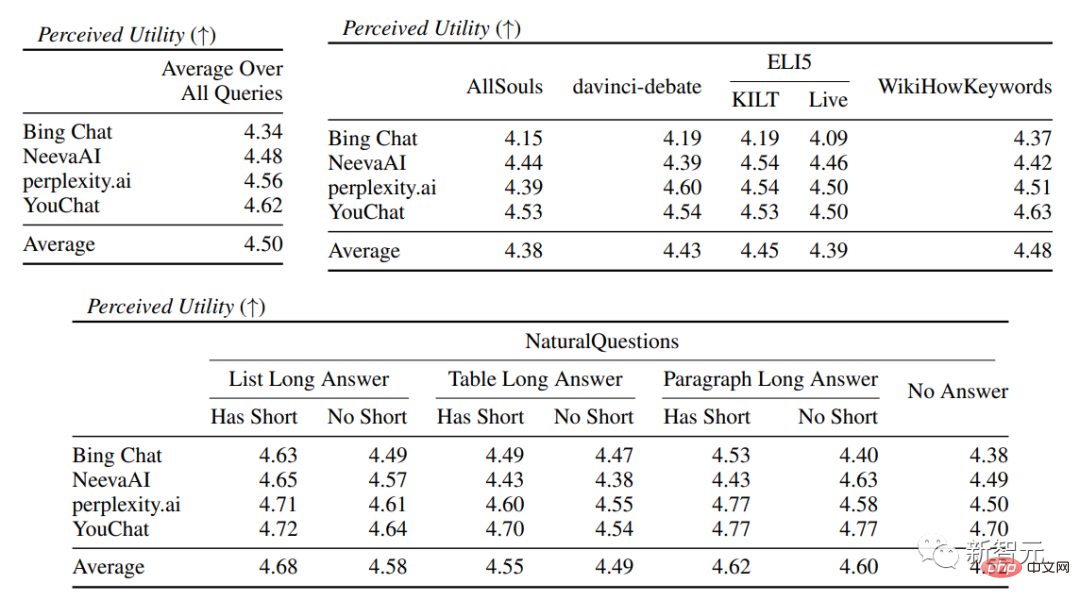
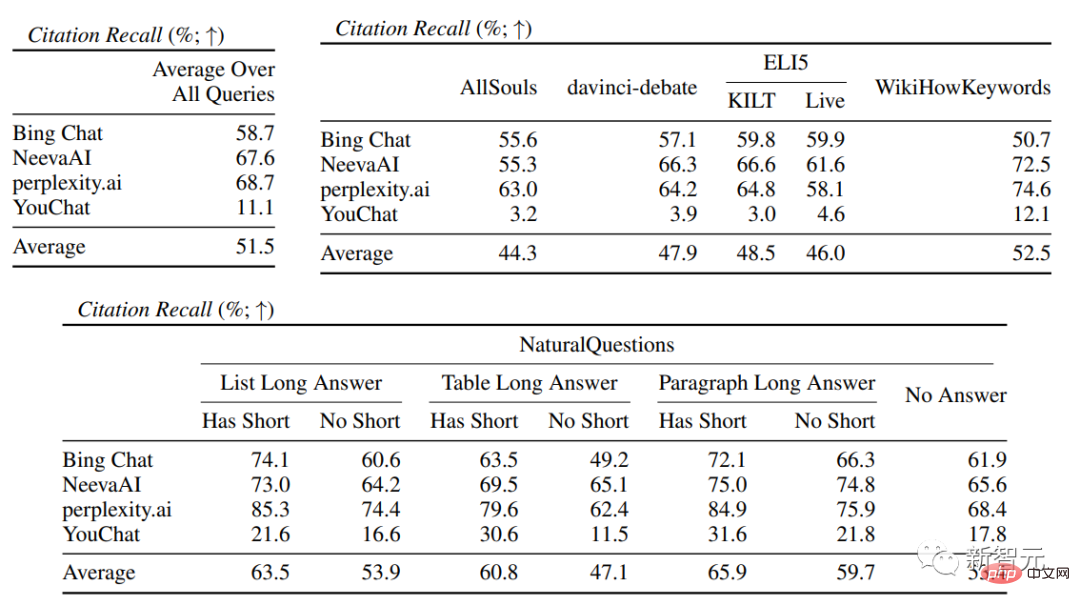
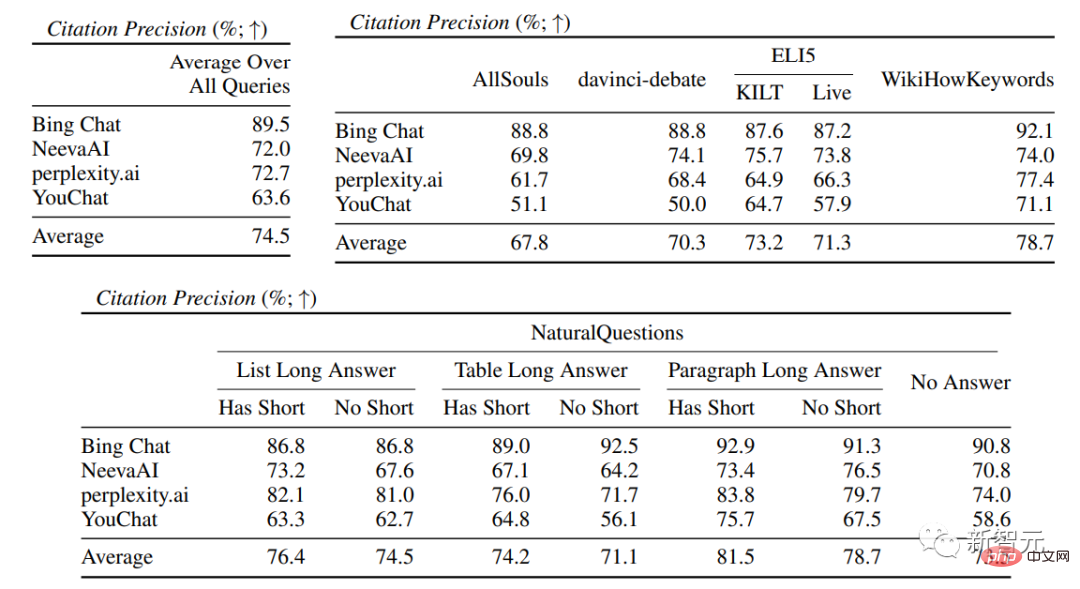
流暢さが含まれます。生成されたテキストは一貫性がある; 有用性、つまり、検索エンジンの応答がユーザーにとって役立つかどうか、および応答の情報が問題を解決できるかどうか; 引用想起、それは、引用サポートを含む外部 Web サイトについて生成された文の割合、Citation Precision、つまり、関連文をサポートする生成された引用の割合です。 流暢さ ユーザーのクエリ、生成された応答、および「応答は流暢で意味的に一貫している」というステートメントを同時に表示し、アノテーターが評価しました。 5 点リッカートスケールのデータ。 認知された有用性 流暢さと同様に、アノテーターは評価を求められます。応答が有用であり、ユーザーのクエリに対して有益であるという声明に同意すること。 引用想起 (引用想起) 引用想起とは、文献によって完全に裏付けられた引用の価値を指します。関連引用 検証された文の割合。そのため、この指標の計算には、回答内の検証に値する文を特定し、検証に値する各文が関連する引用によって裏付けられているかどうかを評価する必要があります。 「検証する価値のある文の特定」 プロセスでは、研究者は、外の世界について生成された各文を検討します。一部の読者にとって明白な「常識」のように見えることが実際には正しくない可能性があるため、明白で些細なことであっても検証する必要があります。 検索エンジン システムの目標は、生成された応答の内容を読者が簡単に確認できるように、外の世界について生成されたすべての文の参照ソースを提供することです。簡略化するために行われており、検証可能性を犠牲にしています。 つまり、実際には、アノテーターは、システムが一人称である応答 (「言語モデルとしては、私には能力がありません)」を除いて、生成されたすべての文を検証します。 . 」や、「もっと詳しく知りたいですか?」などのユーザーへの質問です。 評価 「検証に値する記述が関連する引用によって適切に裏付けられているかどうか」 は特定された出典 (AIS、特定された者に帰属) ソース) 評価フレームワークでは、アノテーターはバイナリ アノテーションを実行します。つまり、通常の聞き手が「引用された Web ページに基づいて結論付けることができる...」と同意した場合、引用は応答を完全に裏付けることができます。 引用の正確さ 引用の正確さを測定するには、アノテーターは次のことを行う必要があります。各引用が、それが関連する文に対して完全な裏付け、部分的な裏付け、または無関係な裏付けを提供しているかどうかを判断します。 完全なサポート : 文中のすべての情報は引用によって裏付けられています。 部分的なサポート : 文内の一部の情報は引用によって裏付けられていますが、他の部分は欠落しているか矛盾している可能性があります。 無関係なサポート (サポートなし) : 参照された Web ページがまったく無関係または矛盾している場合。 関連する引用が複数ある文の場合、アノテーターはさらに、AIS 評価フレームワークを使用して、関連するすべての引用 Web ページが全体としてその文を十分にサポートしているかどうかを判断する必要があります (II メタジャッジメント) )。 流暢性と有用性の評価では、各検索エンジンが非常にスムーズで有用な応答を生成できることがわかります。 特定の検索エンジンの評価では、Bing Chat の流暢さ/有用性の評価が最も低いことがわかります (4.40/ 4.34)、次いで NeevaAI (4.43/4.48)、perplexity.ai (4.51/4.56)、YouChat (4.59/4.62) です。 ユーザー クエリのさまざまなカテゴリでは、短い検索質問の方が長い質問よりもスムーズで、通常は事実に関する知識のみに答えることができます。一部の難しい質問には、さまざまな質問の集約が必要になることがよくあります。テーブルや Web ページ、および合成プロセスによって全体のフローが削減されます。 引用評価では、既存の生成検索エンジンは Web ページを完全に、または正確に引用できないことが多く、生成された文のうち完全にサポートされているのは平均して 51.5% だけであることがわかります。引用 (思い出してください) ですが、引用の 74.5% だけが関連する文を完全にサポートしています (精度)。 この値は、すでに何百万ものユーザーがいる検索エンジン システムでは、特に応答を生成する場合には受け入れられません。多くの場合、大量の情報が含まれます。 そして 異なる生成検索エンジン 間では引用再現率と精度に大きな差があり、perplexity.ai が最高の再現率 (68.7) を達成しているのに対し、NeevaAI (67.6) )、Bing Chat (58.7) と YouChat (11.1) は低くなります。 一方、Bing Chat が最も高い精度 (89.5) を達成し、続いて perplexity.ai (72.7)、NeevaAI (72.0)、YouChat ( 63.6) でした。 ) さまざまなユーザー クエリにわたって、長い回答を持つ NaturalQuestions クエリ と非 NaturalQuestions クエリの間の引用再現ギャップは 11% 近くです (それぞれ 58.5 と 47.8); 同様に、短い回答のある NaturalQuestions クエリ と短い回答のない NaturalQuestions クエリの間の引用再現率では、その差はほぼ 10% (47.8 の場合は 63.4) です。短い回答のあるクエリの場合は 53.6、長い回答のみのクエリの場合は 53.6、長い回答も短い回答のないクエリの場合は 53.4)。 Web ページのサポートがない 質問では引用率が低くなります たとえば、AllSouls の論文の自由回答質問を評価する場合、生成的検索エンジンは引用の想起を行います。レートはわずか 44.3
実験結果
以上が「ChatGPT検索」4機種を徹底比較!スタンフォード大学の中国人医師による手書きの注釈: New Bing は流暢さが最も低く、文のほぼ半分が引用されていません。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。