
ホームページ >テクノロジー周辺機器 >AI >「紅楼夢」の半分を ChatGPT 入力ボックスに移動したいですか?まずはこの問題を解決しましょう
「紅楼夢」の半分を ChatGPT 入力ボックスに移動したいですか?まずはこの問題を解決しましょう

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-01 21:01:05954ブラウズ

過去 2 年間、スタンフォード大学のヘイジー研究所は、配列の長さを増やすという重要な課題に取り組んできました。
彼らは次のような見解を持っています: より長いシーケンスは、基本的な機械学習モデルの新時代の到来をもたらすでしょう - より長いコンテキストと複数のメディア ソースから学習できるモデル、複雑なデモンストレーションなどを学びます。現在、この研究は新たな進歩を遂げています。 Hazy Research 研究所の Tri Dao 氏と Dan Fu 氏は、FlashAttention アルゴリズムの研究と普及を主導し、32k のシーケンス長が可能であることを証明し、現在の基本モデル時代 (OpenAI、Microsoft、NVIDIA などの企業) で広く使用されることになるでしょう。モデルは FlashAttention アルゴリズムを使用しています)。
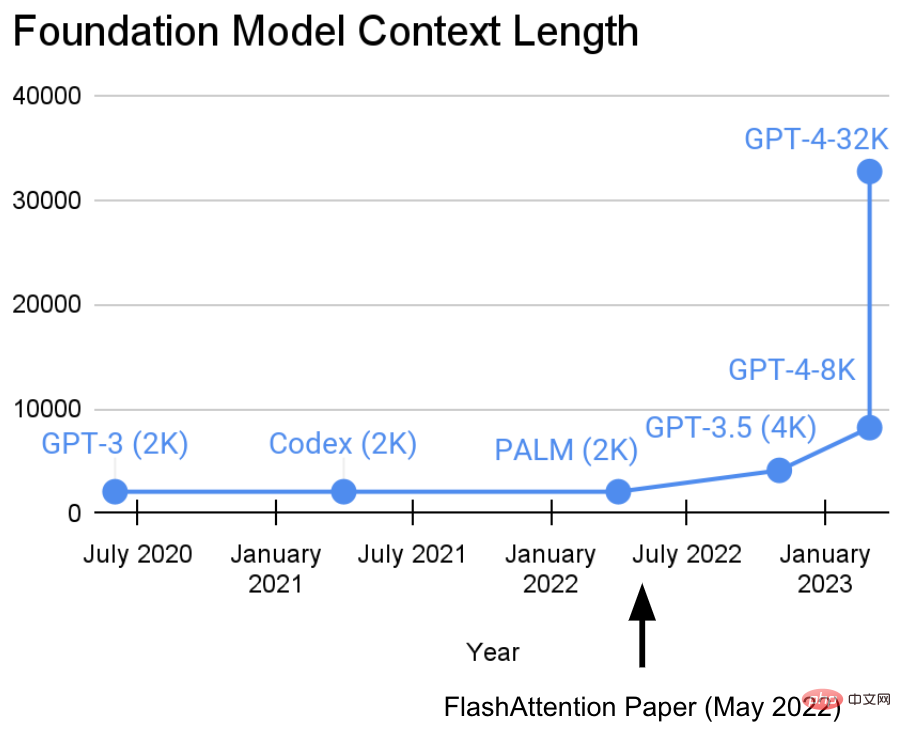
- 文書アドレス: https://arxiv.org/abs/2205.14135
- コードアドレス: https://github.com/HazyResearch/flash-attention
- GPT4 の関連情報が指摘しているように、これにより、約 50 ページのテキストをコンテキストとして使用し、Deepmind Gato と同様にトークン化/パッチ適用を実装し、画像をコンテキストとして使用します。
この記事では、著者はシーケンスの長さを高レベルで増やすための新しい方法を紹介し、新しいプリミティブのセットへの「ブリッジ」を提供します。
#トランスフォーマーはより深く、より幅広くなってきていますが、長いシーケンスでトランスフォーマーをトレーニングすることは依然として困難です。研究者が直面する基本的な問題は、Transformer のアテンション層のシーケンス長が二次関数的に増加することです。つまり、長さが 32k から 64k に増加すると、コストが 2 倍だけでなく 4 倍も増加します。したがって、これは研究者が線形時間計算量を備えたシーケンス長モデルを探索する動機になります。 
FlashAttendant は、近似せずに、注意を高速化し、メモリ使用量を削減します。 「6 か月前に FlashAttend をリリースして以来、多くの組織や研究機関がトレーニングと推論を加速するために FlashAttend を採用していることを嬉しく思います」とブログ投稿には書かれています。
FlashAttendant は、アテンションの計算を並べ替え、古典的な手法 (タイリング、再計算) を利用して、シーケンス長アルゴリズムでのメモリ使用量を 2 次から線形に高速化し、削減するメソッドです。各アテンション ヘッドについて、メモリの読み取り/書き込みを削減するために、FlashAttendant は古典的なタイリング手法を使用してクエリ、キー、および値のブロックを GPU HBM (メイン メモリ) から SRAM (高速キャッシュ) にロードし、アテンションを計算して出力を書き戻します。 HBM。このメモリの読み取り/書き込みの削減により、ほとんどの場合、速度が大幅に向上します (2 ~ 4 倍)。
#FlashAttendant は、GPU メモリの読み取りと書き込みを削減することで注意を高速化します。 Google の研究者は、さまざまなモデルが長距離の依存関係をどの程度うまく処理できるかを評価するために、2020 年に Long Range Arena (LRA) ベンチマークを開始しました。 LRA は、テキスト、画像、数式などのさまざまなデータ型とモダリティをカバーする一連のタスクを、最大 16K のシーケンス長でテストできます (Path-X: 空間一般化バイアスなしでピクセルに展開された画像の分類)。トランスフォーマーをより長いシーケンスにスケーリングするために多くの素晴らしい作業が行われてきましたが、その多くは精度を犠牲にしているようです (下の画像に示すように)。 Path-X 列に注目してください。すべての Transformer メソッドとそのバリアントのパフォーマンスは、ランダムな推測よりもさらに悪くなります。 #次に、Albert Gu によって開発された S4 について説明しましょう。 LRA ベンチマーク結果に触発された Albert Gu 氏は、長距離依存関係をより適切にモデル化する方法を見つけたいと考え、直交多項式と再帰モデルおよび畳み込みモデルの関係に関する長期研究に基づいて、S4 を立ち上げました。構造化状態空間モデル (SSM) に基づいています。 重要な点は、長さ N のシーケンスを 2N に拡張するときの SSM の時間計算量は さらに、Hazy Research が FlashAttendant をリリースしたとき、すでに Transformer のシーケンス長を増やすことが可能でした。また、シーケンス長を 16K に増やすだけで、Transformer が Path-X 上でも優れたパフォーマンス (63%) を達成できることもわかりました。 しかし、言語モデリングにおける S4 の品質には、最大 5% の複雑さのギャップがあります (文脈上、これは 1 億 2,500 万のモデルと 6.7 B モデル間のギャップ)。このギャップを埋めるために、研究者たちは連想想起などの合成言語を研究し、言語が持つべき特性を決定してきました。最終的な設計は H3 (Hungry Hungry Hippo) で、これは 2 つの SSM をスタックし、その出力を乗算ゲートで乗算する新しい層です。 Hazy Research の研究者は、H3 を使用して、GPT スタイルの Transformer のほぼすべてのアテンション レイヤーを置き換え、複雑さにおいて高いパフォーマンスを達成し、下流の評価に関しては Transformer に匹敵することができました。 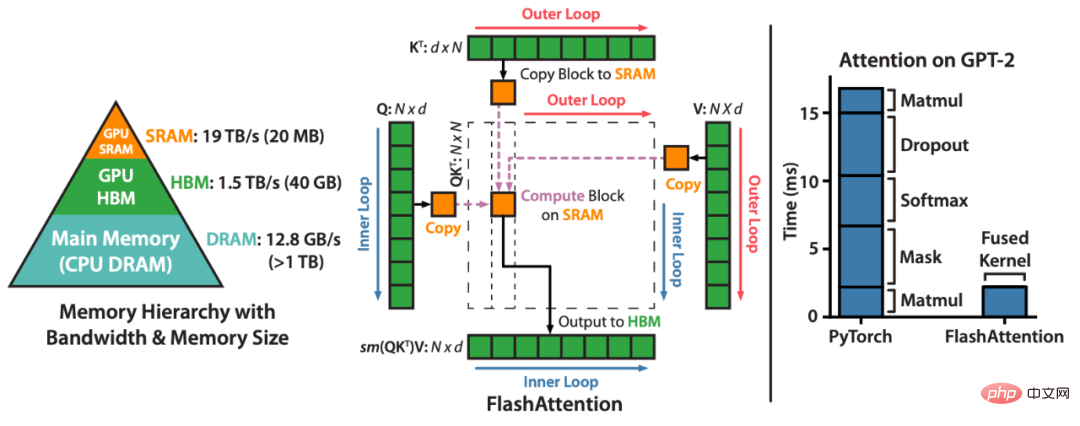
Long Range Arena ベンチマークと S4
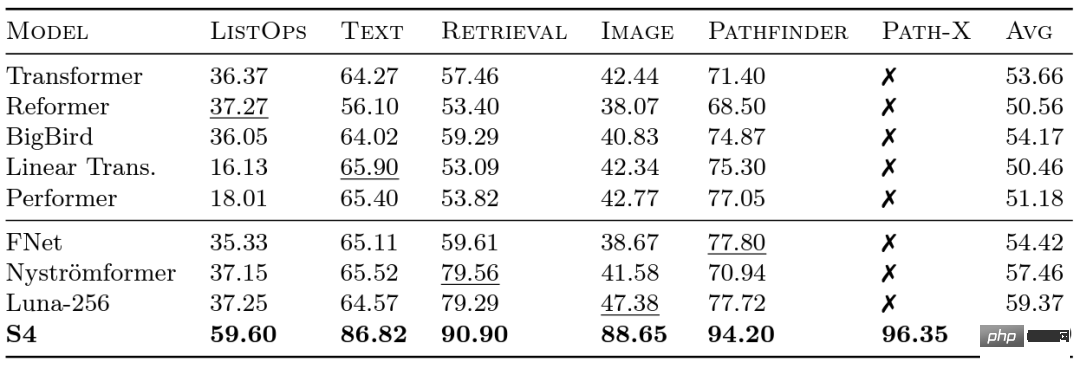
 であるということです。注意とは異なります。メカニズムもまた、急速に成長します。スクエアレベル! S4 は、LRA の長距離依存関係のモデル化に成功し、Path-X で平均を上回るパフォーマンスを達成した最初のモデルになりました (現在、96.4% の精度を達成しています!)。 S4 のリリース以来、多くの研究者がこれに基づいて開発および革新を行ってきました。スコット リンダーマンのチームの S5 モデル、アンキット グプタの DSS (およびその後のヘイジー研究所の S4D)、ハサニとレヒナーの Liquid-S4、などのモデル。
であるということです。注意とは異なります。メカニズムもまた、急速に成長します。スクエアレベル! S4 は、LRA の長距離依存関係のモデル化に成功し、Path-X で平均を上回るパフォーマンスを達成した最初のモデルになりました (現在、96.4% の精度を達成しています!)。 S4 のリリース以来、多くの研究者がこれに基づいて開発および革新を行ってきました。スコット リンダーマンのチームの S5 モデル、アンキット グプタの DSS (およびその後のヘイジー研究所の S4D)、ハサニとレヒナーの Liquid-S4、などのモデル。 モデリングの欠点
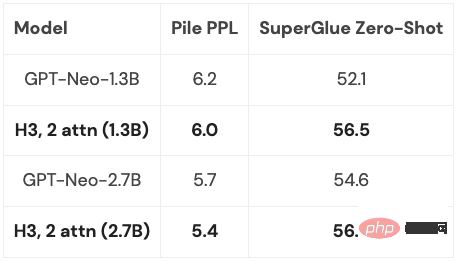
H3 レイヤーは SSM 上に構築されているため、シーケンスの長さの観点から計算の複雑さも高くなります。  の速度で成長しています。 2 つのアテンション レイヤーにより、モデル全体が依然として
の速度で成長しています。 2 つのアテンション レイヤーにより、モデル全体が依然として
## 複雑になります。この問題については、後で詳しく説明します。 
もちろん、この方向性を検討しているのは Hazy Research だけではありません。GSS も、ゲーティングを備えた SSM が言語モデリングで注意を払うことでうまく機能することを発見しました (これが H3 に影響を与えました)。Meta は、これも組み合わせた Mega モデルをリリースしました。 SSM とアテンション、BiGS モデルは BERT スタイル モデルのアテンションを置き換え、RWKV は完全なループ アプローチに取り組んできました。
新しい進歩: ハイエナ
これまでの一連の研究に基づいて、Hazy Research の研究者は新しいアーキテクチャであるハイエナを開発するようインスピレーションを受けました。彼らは、H3 の最後の 2 つのアテンション層を取り除き、より長いシーケンス長に対してほぼ直線的に成長するモデルを取得しようとしました。答えを見つけるには、2 つの単純なアイデアが鍵であることがわかります。
- #各 SSM は、入力シーケンスと同じ長さの畳み込みフィルターとして見ることができます。したがって、SSM を入力シーケンスと同じサイズの畳み込みに置き換えて、同じ計算量でより強力なモデルを取得できます。具体的には、畳み込みフィルターは、ニューラル分野の文献や CKConv/FlexConv に関する強力な手法を利用して、別の小さなニューラル ネットワークを介して暗黙的にパラメーター化されます。さらに、畳み込みは O (NlogN) 時間で計算できます (N はシーケンスの長さ)。ほぼ線形のスケーリングが実現します。
- #H3 のゲート動作は次のように要約できます。 H3 は入力の 3 つの投影を取得し、繰り返し畳み込み、ゲートを適用します。ハイエナでは、より多くのプロジェクションとより多くのゲートを追加するだけで、より表現力豊かなアーキテクチャに一般化し、注目を集めてギャップを埋めることができます。
Hyena は、複雑さと下流のタスクにおいて Transformer に匹敵する、完全に線形に近い時間畳み込みモデルを初めて提案し、実験で良好な結果を達成しました。また、小規模および中規模のモデルは PILE のサブセットでトレーニングされ、そのパフォーマンスは Transformer に匹敵しました:
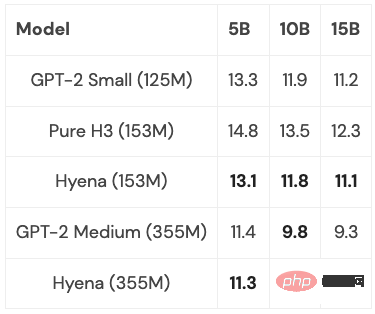
いくつかの最適化 (詳細は後述) を行うと、Hyena モデルは、2K のシーケンス長では同じサイズの Transformer よりわずかに遅くなりますが、シーケンス長が長くなると高速になります。
次に考慮する必要があるのは、これらのモデルをどの程度まで一般化できるかということです。それらを PILE のフルサイズ (400B トークン) まで拡張することは可能ですか? H3 とハイエナのアイデアの最良の部分を組み合わせると何が起こるでしょうか?また、それはどこまで実現できるでしょうか?
FFT それとももっと基本的なアプローチでしょうか?
これらすべてのモデルで共通の基本演算は FFT です。これは畳み込みを計算する効率的な方法であり、必要な時間は O (NlogN) のみです。ただし、FFT は、特殊な行列乗算ユニットと GEMM (NVIDIA GPU のテンソル コアなど) が主流のアーキテクチャである最新のハードウェアではあまりサポートされていません。
FFT を一連の行列乗算演算として書き直すことで、効率のギャップを埋めることができます。研究チームのメンバーは、バタフライ行列を使用してスパース トレーニングを調査することで、この目標を達成しました。最近、Hazy Research の研究者は、この接続を利用して、バタフライ分解を使用して FFT 計算を一連の行列乗算演算に変換することにより、FlashConv や FlashButterfly などの高速畳み込みアルゴリズムを構築しました。
さらに、以前の作業を利用することで、より深いつながりを作ることができます。これには、これらの行列を学習できるようにすることも含まれます。これにも同じ時間がかかりますが、パラメータが追加されます。研究者たちは、いくつかの小規模なデータセットでこの関連性を調査し始め、初期の結果を達成しました。この関係が何をもたらす可能性があるのか (言語モデルに適したものにする方法など) が明確にわかります。

この拡張機能はさらに深く調査する価値があります。この拡張機能はどのような種類の変換を学習し、何ができるようになるのでしょうか?それを言語モデリングに適用するとどうなるでしょうか?
これらはエキサイティングな方向性であり、その後に続くものは、この新しい領域をさらに探索できるようにする、ますます長いシーケンスと新しいアーキテクチャになるでしょう。高解像度イメージング、新しいデータ形式、本全体を読み取ることができる言語モデルなど、長いシーケンス モデルから恩恵を受けるアプリケーションには特に注意を払う必要があります。本全体を言語モデルに読ませてストーリーラインを要約させたり、コード生成モデルに自分が書いたコードに基づいて新しいコードを生成させたりすることを想像してください。考えられるシナリオはたくさんあり、どれもとてもエキサイティングです。
以上が「紅楼夢」の半分を ChatGPT 入力ボックスに移動したいですか?まずはこの問題を解決しましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。