



ファイルの読み取り
私が初めて Java の IO ストリーム部分を学んだとき、本には、画像やビデオなどの非テキスト バイナリ ファイルの読み取りに使用できるのはバイト ストリームのみであり、文字ストリームは使用できないと書かれていました。使用しない場合、ファイルが破損します。それで、これはずっと覚えているのですが、なぜこれが使えないのかということがずっと疑問でした。今日、この問題をもう一度考えたので、一気に解決してみようかなと思いました。
まず、画像のコピーに関するコード例を見てみましょう: 注: 私のコンピューターにはパス D:/DB があります。パスがない場合は、DB フォルダー用にパスを作成する必要があります。
package dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ReadImage {
public static void main(String[] args) throws IOException {
String imgPath = "D:/DB/husky/kkk.jpeg";
String byteImgCopyPath = "D:/DB/husky/byteCopykkk.jpeg";
String charImgCopyPath = "D:/DB/husky/charCopykkk.jpeg";
Path srcPath = Paths.get(imgPath);
Path desPath2 = Paths.get(byteImgCopyPath);
Path desPath3 = Paths.get(charImgCopyPath);
byteRead(srcPath.toFile(), desPath2.toFile());
System.out.println("字节复制执行成功!");
characterRead(srcPath.toFile(), desPath3.toFile());
System.out.println("字符复制执行成功!");
}
static void byteRead(File src, File des) throws IOException {
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream(src));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(des))) {
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
bos.write(b, 0, hasRead);
}
}
}
static void characterRead(File src, File des) throws IOException {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(src), "UTF-8"));
BufferedWriter writer = new BufferedWriter(new FileWriter(des))) {
int hasRead = 0;
char[] c = new char[1024];
while ((hasRead = reader.read(c)) != -1) {
writer.write(c, 0, hasRead);
}
}
}
}実行結果: 画像などのバイナリ ファイルは文字ストリームを使用して読み取ることができず、バイト ストリームを使用する必要があることがわかります。

画像サイズの変更: 文字ストリームを使用すると画像サイズが変化しますが、文字ストリームを使用すると変化しないことがわかります。バイトストリーム。

なぜそうなるのでしょうか?
上記の例から、文字ストリームを使用してファイルをコピーすることは実際には不可能であることがわかります。文字ストリームを使用してファイルをコピーすると、ファイルのサイズも変化し、これがタイトルにつながります。今日は議論する予定です。
まず、テキスト ファイルを開いたときにテキストが表示される理由を考えてみましょう。 コンピュータによって処理されるファイルは、テキスト ファイルであろうと非テキスト ファイルであろうと、最終的にはバイナリ形式でコンピュータ内に保存されることは誰もが知っています。
テキスト エディターの 16 進モードを使用して、テキスト ファイルを開きます。

テキスト エディターの 16 進モードを使用します。エディタ 上記のプログラムで使用されている画像ファイルをカスタム モードで開きます。
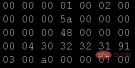
2 つの画像のデータを比較すると、違いは見つからないはずですが、なぜ違いが見つかるのでしょうか。テキストデータは表示されますか?書き込みはどうですか?これは非常に基本的な質問ですが、この点については大学の基礎コース -文字エンコード表で取り上げられています。私が初めてC言語を学び、一番最初に触れたコーディングテーブルはASCII(American Standard Code for Information Interchange)で、その後Javaを学んでUnicode(Universal Code)に出会いました。現在最も一般的に使用されているのは、Unicode の可変長文字エンコーディングである UTF-8 です。)
注: UTF-8 を使用することもできます。 BOM(バイトオーダーマーク、文字セクションオーダーマーク)とそうでないものに分かれており、混在するとエラーが発生しますので、興味のある方は勉強してみてください。

文字エンコーディング テーブルの役割は、エンコーディングに反映されます。百科事典からの一節を引用します:
表示されるテキストパソコン内の写真やその他の情報は、モニター上で実際に目に見えるものではなく、すべての情報がハードディスクに保存されているとわかっていても、分解してみると中身は何も見えず、一部のディスクだけが見えます。顕微鏡で円盤を拡大してみると、円盤の表面には凹凸があり、凸部は磁化されており、凹部は磁化されていません。凸部は数字の1を表し、凹部は数字を表しています。数字の0。ハードディスクでは、すべてのテキスト、画像、その他の情報を表すために 0 と 1 のみを使用できます。では、文字「A」はハードドライブにどのように保存されるのでしょうか?おそらく、Xiao Zhang のコンピュータでは文字「A」が 1100001 として保存され、Xiao Wang のコンピュータでは文字「A」が 11000010 として保存されます。このようにして、双方が情報を交換するときに誤解が生じます。たとえば、Xiao Zhang は Xiao Wang に 1100001 を送信しました。Xiao Wang は 1100001 が文字「A」であるとは考えず、おそらく文字「X」であると考えました。したがって、Xiao Wang がメモ帳を使用してハードディスクに保存されている 1100001 にアクセスすると、 , 画面にエラーメッセージが表示されましたが、表示されているのは「X」の文字です。つまり、Xiao Zhang と Xiao Wang は異なるコーディング テーブルを使用しました。
したがって、 文字エンコーディング テーブルは、2 進数と文字 の間の 1 対 1 のマッピングです。たとえば、65 (数値) は A を表すため、次のコードは次のようになります。画面Aに出力します。
char c = 65; System.out.println(c);
ループを使用してテストしてみましょう:
char c = 0;
for (int i = 9999; i < 10009; i++) {
c = (char) i;
System.out.print(c+" ");
}テスト結果: (もちろん、これは現在の文字エンコード テーブルによって異なります。ASCII を使用している場合は、興味深いかもしれません。) # ##################################
这样就解释了前面那个问题(为什么文本文件打开可以显示文字?),我们之所以可以看见文本文件的字符是因为计算机按照我们文件的编码(ASCII、UTF-8或者GBK等),从字符编码表中找出来对应的字符。 所以,当我们使用记事本打开二进制文件会看到乱码,这就是原因。文件的复制过程也是复制的二进制数据,而不是真实的文字。
因此可以这样理解文件复制的过程:
字符流:二进制数据 --编码-> 字符编码表 --解码-> 二进制数据
字节流:二进制数据 —> 二进制数据
所以问题就是出现在编码和解码的过程中,既然是字符的编码表,那它就是包含所有的字符,但是字符的数量是有限的,这就意味着它不能表示一些超过编码表的字符,因为根本不存在表中。所以,JVM 会使用一些字符进行替换,基本上都是乱码(所以大小会发生变化),而且如果有一个数据恰好是-1,那么读取就会中断,引起数据丢失。
例如如下代码使用字符流读取就会错误:
String filename = "D:/DB/fos.txt"; //文件名
byte[] b = new byte[] {-1, -1}; //两个字节,127的二进制就是 1111 1111
//数据写入文件
try (FileOutputStream fos = new FileOutputStream(filename)) {
fos.write(b, 0, b.length); //将两个127连续写入,就是 1111 1111 1111 1111
}
File file = new File(filename);
//输出文件的大小
System.out.println("file length: " + file.length());
char[] c = new char[2];
//使用字符流读取文件
try (FileReader reader = new FileReader(filename)) {
int count = reader.read(c); //Java使用Unicode编码,读取的是从 0-65535 之间的数字。
System.out.println("以文本形式输出:" + new String(c, 0, count)+" "+count);
for (char d : c) {
System.out.println("字符为:" + d);
}
}
System.out.println("表示字符:" + c[0]);
//再写入文件
try (FileWriter writer = new FileWriter(filename)) {
writer.write(c, 0, 2);
}
File f = new File(filename);
System.out.println("file length: " + f.length());结果:

说明: 我将两个1字节的-1写入(字节流)了文本文件(注意是字节:-1,不是字符:-1),然后再读取(字符流),再写入(字符流)就已经出现了问题。读取出的字符显示了一个奇怪的符号,而且它的值为:65533,这个值如果用字节表示的话,一个字节是不够的,所以文件的大小就会变化。在非文本的二进制数据中,出现这种情况都是正常的,因为本来就不是按照字符编码的。
因为字符都是正数,而非字符编码的话,字节数可能是负数(很可能),但是负数在字符看来就是正数,这也是为什么-1,被读成 65533的原因。可以看出来,读取就已经错误了。
注意: 这里的重点是对于使用字符流读取非文本文件,在读取-写入的过程中的问题。
以上がJava が文字ストリームを使用して非テキスト バイナリ ファイルを読み取れない理由は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 高度なJavaプロジェクト管理、自動化の構築、依存関係の解像度にMavenまたはGradleを使用するにはどうすればよいですか?Mar 17, 2025 pm 05:46 PM
高度なJavaプロジェクト管理、自動化の構築、依存関係の解像度にMavenまたはGradleを使用するにはどうすればよいですか?Mar 17, 2025 pm 05:46 PMこの記事では、Javaプロジェクト管理、自動化の構築、依存関係の解像度にMavenとGradleを使用して、アプローチと最適化戦略を比較して説明します。
 適切なバージョン化と依存関係管理を備えたカスタムJavaライブラリ(JARファイル)を作成および使用するにはどうすればよいですか?Mar 17, 2025 pm 05:45 PM
適切なバージョン化と依存関係管理を備えたカスタムJavaライブラリ(JARファイル)を作成および使用するにはどうすればよいですか?Mar 17, 2025 pm 05:45 PMこの記事では、MavenやGradleなどのツールを使用して、適切なバージョン化と依存関係管理を使用して、カスタムJavaライブラリ(JARファイル)の作成と使用について説明します。
 カフェインやグアバキャッシュなどのライブラリを使用して、Javaアプリケーションにマルチレベルキャッシュを実装するにはどうすればよいですか?Mar 17, 2025 pm 05:44 PM
カフェインやグアバキャッシュなどのライブラリを使用して、Javaアプリケーションにマルチレベルキャッシュを実装するにはどうすればよいですか?Mar 17, 2025 pm 05:44 PMこの記事では、カフェインとグアバキャッシュを使用してJavaでマルチレベルキャッシュを実装してアプリケーションのパフォーマンスを向上させています。セットアップ、統合、パフォーマンスの利点をカバーし、構成と立ち退きポリシー管理Best Pra
 キャッシュや怠zyなロードなどの高度な機能を備えたオブジェクトリレーショナルマッピングにJPA(Java Persistence API)を使用するにはどうすればよいですか?Mar 17, 2025 pm 05:43 PM
キャッシュや怠zyなロードなどの高度な機能を備えたオブジェクトリレーショナルマッピングにJPA(Java Persistence API)を使用するにはどうすればよいですか?Mar 17, 2025 pm 05:43 PMこの記事では、キャッシュや怠zyなロードなどの高度な機能を備えたオブジェクトリレーショナルマッピングにJPAを使用することについて説明します。潜在的な落とし穴を強調しながら、パフォーマンスを最適化するためのセットアップ、エンティティマッピング、およびベストプラクティスをカバーしています。[159文字]
 Javaのクラスロードメカニズムは、さまざまなクラスローダーやその委任モデルを含むどのように機能しますか?Mar 17, 2025 pm 05:35 PM
Javaのクラスロードメカニズムは、さまざまなクラスローダーやその委任モデルを含むどのように機能しますか?Mar 17, 2025 pm 05:35 PMJavaのクラスロードには、ブートストラップ、拡張機能、およびアプリケーションクラスローダーを備えた階層システムを使用して、クラスの読み込み、リンク、および初期化が含まれます。親の委任モデルは、コアクラスが最初にロードされ、カスタムクラスのLOAに影響を与えることを保証します


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

ドリームウィーバー CS6
ビジュアル Web 開発ツール

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

