
ホームページ >テクノロジー周辺機器 >AI >超プログラムされたAIがサイエンス誌の表紙に登場! AlphaCode プログラミング コンテスト: プログラマーの半数が出場
超プログラムされたAIがサイエンス誌の表紙に登場! AlphaCode プログラミング コンテスト: プログラマーの半数が出場

- 王林転載
- 2023-04-30 13:19:061281ブラウズ
OpenAI の ChatGPT が勢いを増しているこの 12 月、かつてプログラマーの半数を圧倒した AlphaCode が Science の表紙を飾りました。

論文リンク: https://www.science.org/doi/10.1126/science.abq1158
AlphaCode といえば、誰もがよく知っているはずです。
今年の 2 月には、有名な Codeforces で 10 件のプログラミング コンテストに静かに参加し、人間のプログラマーの半数を一気に破りました。
プログラマーの半数が敗北するでしょう
#この種のテストがプログラマーとプログラミングのコンテストで非常に人気があることは誰もが知っています。
コンテストでは、主にプログラマが経験を通じて批判的に思考し、予期せぬ問題に対する解決策を生み出す能力がテストされます。
これは人間の知性の鍵を具体化したものであり、機械学習モデルがこの種の人間の知性を模倣することは多くの場合困難です。
しかし、ディープマインドの科学者たちはこのルールを破りました。
YujiA Li らは、自己教師あり学習とエンコーダ/デコーダ コンバータ アーキテクチャを使用して AlphaCode を開発しました。

AlphaCode の開発作業が在宅中に完了しました
##AlphaCode も標準の Transformer コーデック アーキテクチャに基づいていますが、DeepMind はそれを「壮大なレベル」で強化しました -Transformer ベースの言語モデルを使用し、コードを生成します前例のない規模で、利用可能なプログラムの小さなサブセットを巧みにフィルタリングして除外します。
具体的な手順は次のとおりです:
1) マルチアスク アテンション: 各アテンション ブロックでキーと値のヘッダーを共有し、同時に、エンコーダー/デコーダー モデルと組み合わせると、AlphaCode のサンプリング速度は 10 倍以上増加します。
2) マスクされた言語モデリング (MLM): MLM 損失をエンコーダーに追加することにより、モデルの解決率が向上します。
3) テンパリング: トレーニング分布をよりシャープにし、それによって過学習による正則化効果を防ぎます。
4) 値の調整と予測: CodeContests データセット内の正しい質問と誤った質問の提出を区別することで、追加のトレーニング シグナルを提供します。
5) 例示的な戦略外学習生成 (GOLD): 各問題に対する最も可能性の高い解決策に焦点を当ててトレーニングすることにより、モデルに各問題に対する正しい解決策を生成させます。
# さて、結果は誰もが知っています。
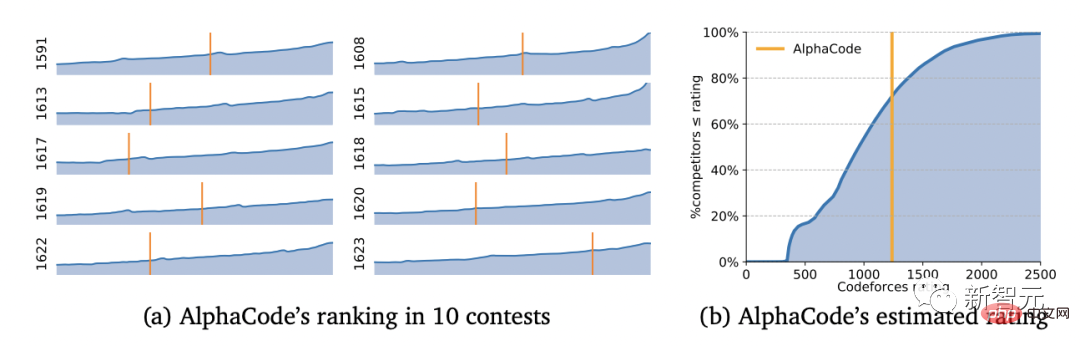
Elo スコア 1238 により、AlphaCode はこれら 10 ゲームで上位 54.3% にランクされました。過去6か月を見ると、この結果は上位28%に達しました。
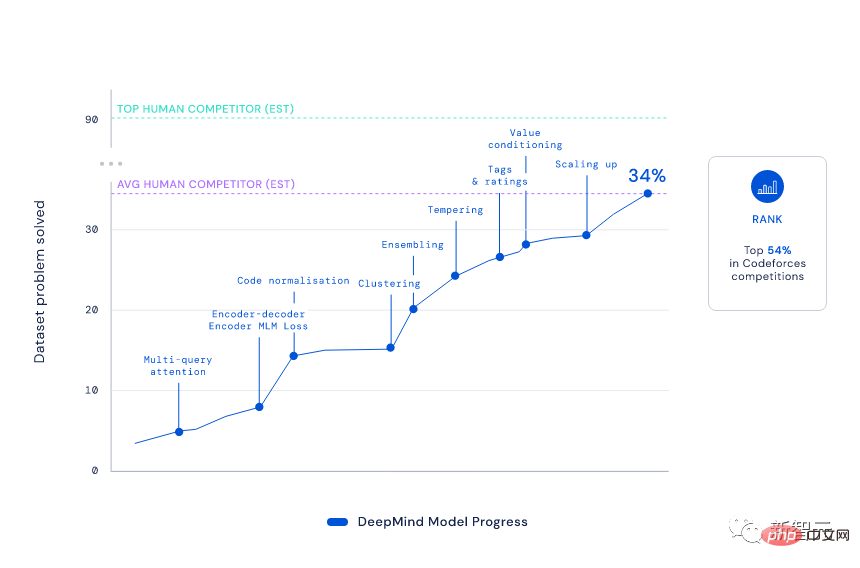 このランキングを達成するには、AlphaCode が「5 つのレベルを通過し、6 人の将軍を倒す」必要があり、批判的思考を組み込んだ問題を解決する必要があることを知っておく必要があります。 、ロジック、アルゴリズム、コーディングと自然言語理解を組み合わせたさまざまな新しい問題。
このランキングを達成するには、AlphaCode が「5 つのレベルを通過し、6 人の将軍を倒す」必要があり、批判的思考を組み込んだ問題を解決する必要があることを知っておく必要があります。 、ロジック、アルゴリズム、コーディングと自然言語理解を組み合わせたさまざまな新しい問題。
結果から判断すると、AlphaCode は CodeContests データセット内のプログラミング問題の 29.6% を解決しただけでなく、そのうちの 66% が最初の提出で解決されました。 (提出回数は合計 10 回までに制限されています)
それに比べて、従来の Transformer モデルの解決率は比較的低く、わずか 1 桁です。
Codeforces の創設者である Mirzayanov でさえ、この結果には非常に驚きました。
結局のところ、プログラミング コンテストではアルゴリズムを発明する能力が試されますが、これは常に AI の弱点であり人間の強みでした。
AlphaCode の結果は私の期待を上回っていたと断言できます。単純な競争問題であっても、アルゴリズムを実装するだけでなく、アルゴリズムを発明する必要があるため、私は最初は懐疑的でした (これが最も難しい部分です)。 AlphaCode は、多くの人間にとって手強い敵となっています。今後どうなるか楽しみです!
——Codeforces 創設者 Mike Mirzayanov
では、AlphaCode はプログラマーの仕事を盗むことができるのでしょうか? ############もちろん違います。
AlphaCode は単純なプログラミング タスクしか実行できません。タスクがより複雑になり、問題がより「予測不能」になった場合、命令をコードに変換するだけの AlphaCode では無力になります。
結局のところ、ある観点から見ると、1238 というスコアは、プログラミングを学習したばかりの中学生のレベルに相当します。このレベルでは、実際のプログラミングの専門家にとっては脅威ではありません。
しかし、このタイプのコーディング プラットフォームの開発がプログラマーの生産性に大きな影響を与えることは間違いありません。
プログラミング文化全体さえも変わるかもしれません。おそらく将来、人間は問題を定式化することのみを担当し、コードの生成と実行のタスクは機械に引き継がれるようになるでしょう。学ぶ。
プログラミングコンテストの何がそんなに難しいのでしょうか?
機械学習はテキストの生成と理解において大きな進歩を遂げましたが、ほとんどの AI は依然として単純な数学とプログラミングの問題に限定されていることがわかっています。彼らが行うことは、既存のソリューションを取得してコピーすることです (最近 ChatGPT をプレイしたことのある人なら誰でもこれを理解できると思います)。
では、AI が正しいプログラムの生成を学習するのはなぜそれほど難しいのでしょうか?
1. 指定されたタスクを解決するコードを生成するには、すべての可能な文字シーケンスを検索する必要があります。これは膨大なスペースであり、有効な文字列に対応するのはそのほんの一部だけです。正しいプログラム。
2. 単一の文字を編集するだけでプログラムの動作が完全に変わったり、クラッシュを引き起こしたりする可能性があり、各タスクには個別の有効な解決策が多数あります。
非常に難しいプログラミング コンテストの場合、AI は複雑な自然言語の記述を理解する必要があります。コード スニペットを単に暗記するのではなく、これまでに見たことのない問題について推論する必要があります。さまざまな知識が必要です。アルゴリズムとデータ構造、そして数百行にも及ぶコードの正確な完成。
さらに、生成されたコードを評価するために、AI は隠されたテストの徹底的なセットでタスクを実行し、実行速度とエッジケースの正確性をチェックする必要もあります。
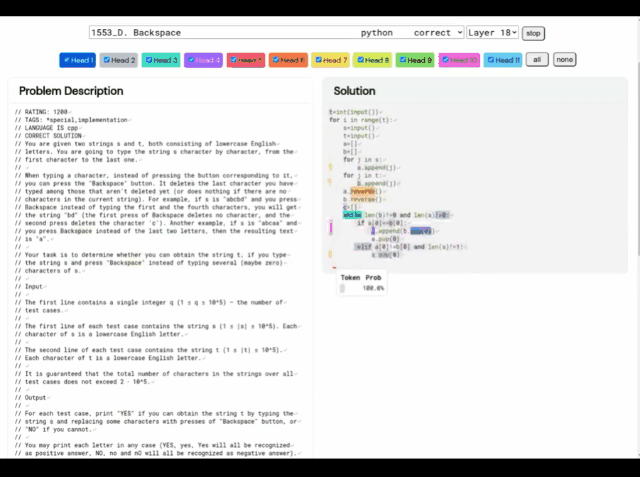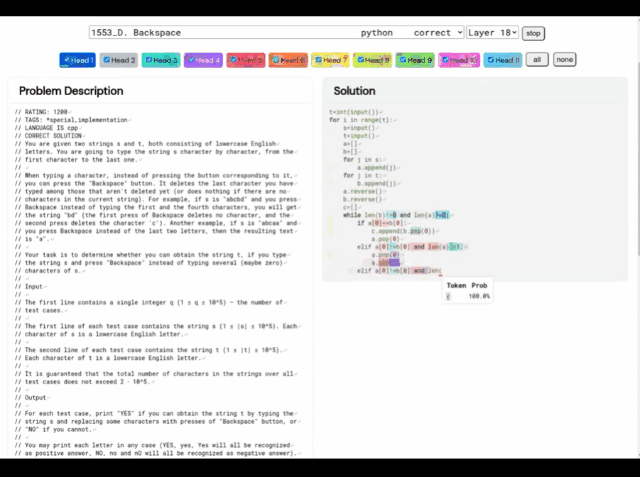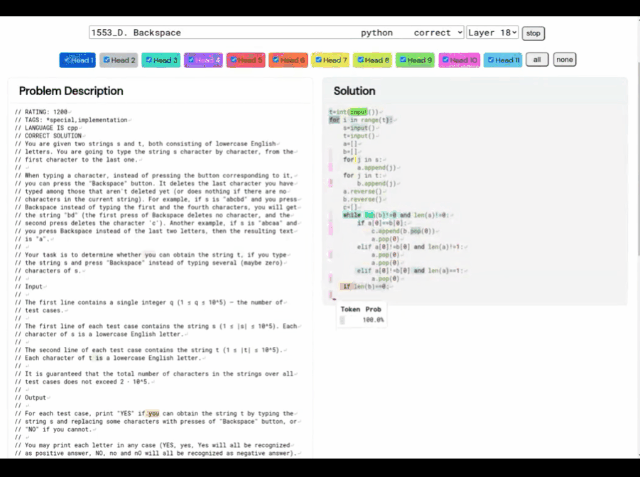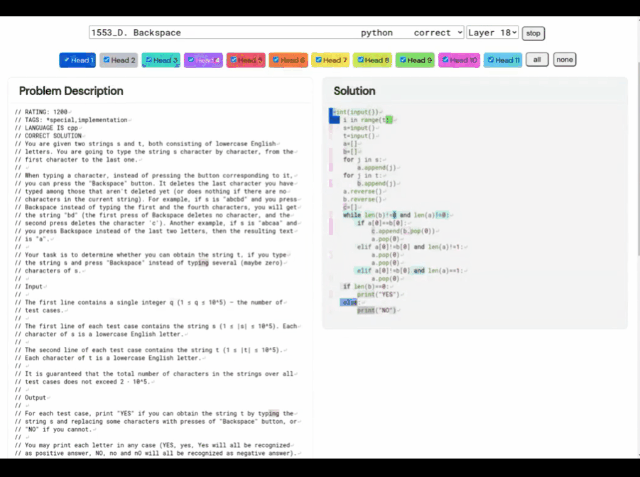
# (A) 問題 1553D、中難易度スコア 1500; (B) AlphaCode によって生成された問題解決法 
この 1553D 問題を例に挙げると、参加者は、限られた入力セットを使用して、ランダムに繰り返される s と t の文字列を同じ文字の別の文字列に変換する方法を見つける必要があります。 。
出場者は新しい文字を入力するだけではなく、「バックスペース」コマンドを使用して元の文字列からいくつかの文字を削除する必要があります。具体的な質問は次のとおりです:
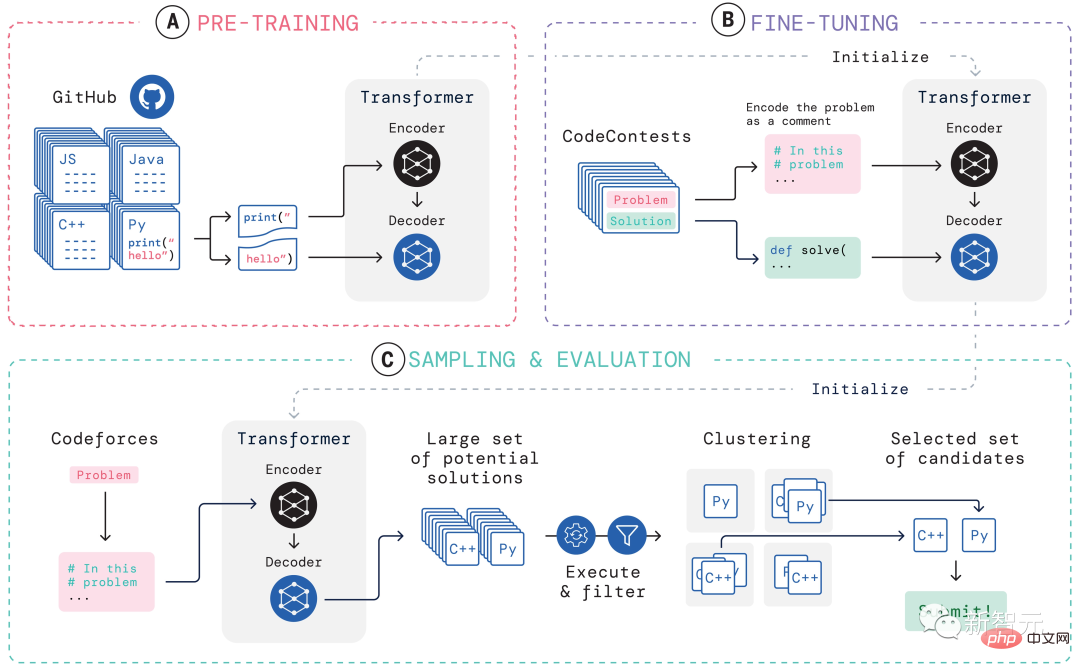
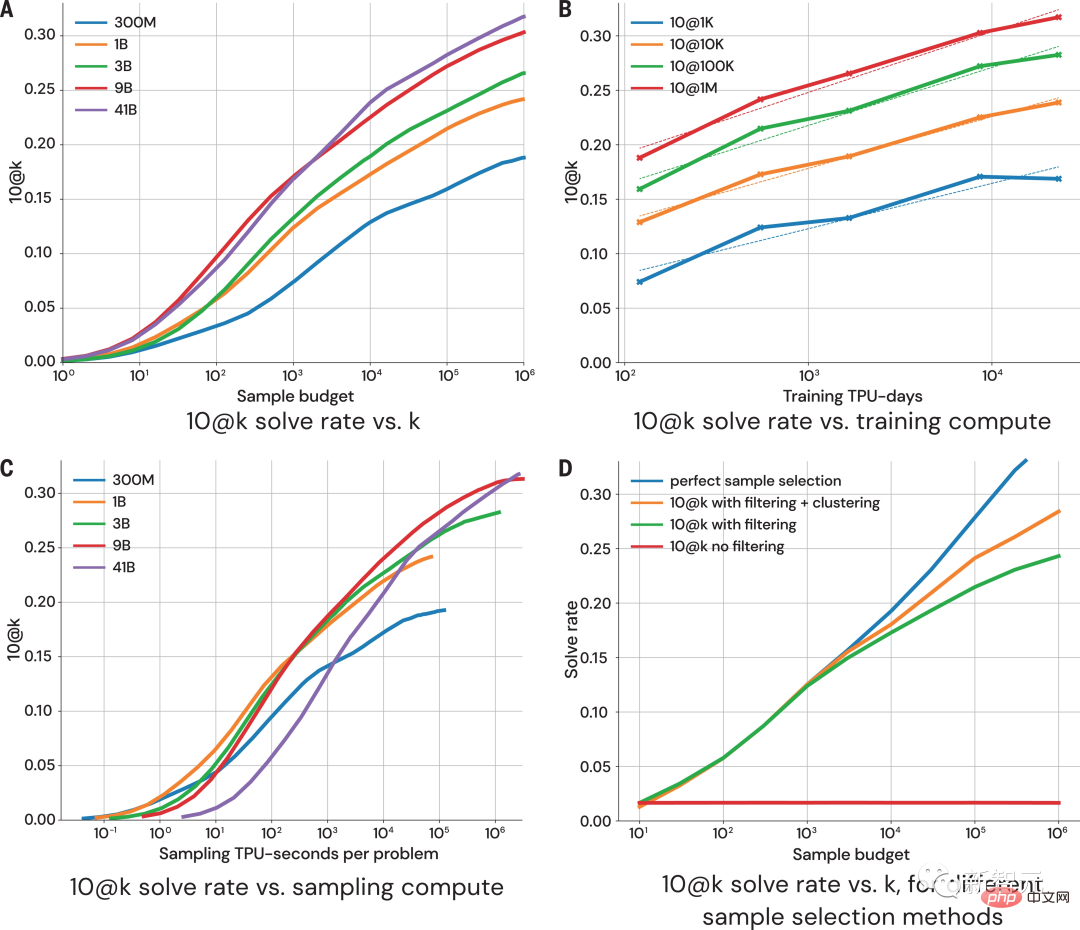
これに関して、AlphaCode が与える解決策は次のとおりです。 さらに、AlphaCode の「問題解決のアイデア」は、これは、コードの場所と注意事項のハイライトも示すブラック ボックスです。 プログラミング コンテストに参加する際、AlphaCode が直面する主な課題は次のとおりです。 (i) 巨大なプログラム空間での検索が必要、(ii) トレーニングに利用できるサンプル タスクは約 13,000 のみ、(iii) 問題ごとの提出数は限られています。 これらの問題に対処するために、AlphaCode の学習システム全体の構築は、事前トレーニング、微調整、上の図に示すように、サンプリングと評価を示します。 プレトレーニング プレトレーニング段階では、人間のコーダーから収集された 715 GB のコード スナップショットを使用します。 GitHub、モデルを事前トレーニングし、クロスエントロピーのネクストトークン予測損失を使用します。事前トレーニング プロセス中に、コード ファイルはランダムに 2 つの部分に分割され、最初の部分はエンコーダーの入力として使用され、モデルはエンコーダーなしで 2 番目の部分を生成するようにトレーニングされます。 この事前トレーニングでは、エンコードの強力な事前学習を学習し、その後のタスク固有の微調整をより小さなデータセットで実行できるようにします。 微調整 微調整フェーズでは、モデルは 2.6 GB の競技プログラミングで実行されます。問題データセット 微調整と評価のために、データセットは DeepMind によって作成され、CodeContests という名前で公開されました。 CodeContests データ セットには、質問とテスト ケースが含まれています。トレーニング セットには 13,328 の質問が含まれており、質問ごとに平均 922.4 の回答が提出されています。検証セットとテスト セットには、それぞれ 117 問と 165 問が含まれています。 微調整中に、自然言語の問題ステートメントはプログラムの注釈としてエンコードされるため、事前トレーニング中に表示されたファイルにより似たものになります (拡張自然言語注釈を含めることができます)。 ) と同じ次のトークンの予測損失を使用します。 サンプリング 送信に最適な 10 個のサンプルを選択するには、フィルタリングおよびクラスタリング手法が使用され、次のコマンドを実行します。問題ステートメントに含まれるサンプル テストを使用してサンプルを作成し、これらのテストに失敗したサンプルを削除します。 モデル サンプルのほぼ 99% をフィルターで除外し、残りの候補サンプルをクラスタリングし、別のトランスフォーマー モデルによって生成された入力に対してこれらのサンプルを実行し、生成されたものに対して同じ出力を生成するプログラムを実行します。入力はグループ化されます。 次に、最大 10 個のクラスターのそれぞれからサンプルを 1 つ選択して送信します。直感的には、正しいプログラムは同じように動作し、大きなクラスターを形成しますが、正しくないプログラムはさまざまな方法で失敗します。 #評価 #1. サンプル サイズが大きくなると、解決率は対数直線的に拡大します。 2. より優れたモデルは、スケーリング曲線の傾きが高くなります; 3. 解速度は、より多くの計算に対数的に線形に比例します; 4. サンプルの選択は、解速度の拡張にとって重要です。 純粋な「データ駆動型」 AlphaCode の導入が機械学習モデルの開発における重要なステップであることは疑いの余地がありません。 興味深いことに、AlphaCode には、コンピューター コードの構造に関する明示的な組み込み知識が含まれていません。 代わりに、純粋に「データ駆動型」のコード記述アプローチに依存しており、大量の既存のコードを観察するだけでコンピューター プログラムの構造を学習します。 記事アドレス: https://www.science.org/doi/10.1126/science.add8258 基本的に、競技プログラミング タスクにおいて AlphaCode が他のシステムよりも優れている理由は、次の 2 つの主な特性に帰着します: 1. トレーニング データ 2. 候補解決策の後処理 しかし、コンピュータ コードは高度に構造化された媒体であり、プログラムは定義された構文に準拠し、明示的な前処理を生成する必要があります。ソリューションのさまざまな部分での事後条件。 AlphaCode がコードを生成するときに使用する方法は、他のテキスト コンテンツを生成するときとまったく同じです。一度に 1 トークンずつ実行され、プログラムの正しさはプログラム全体の生成後にのみチェックされます。書かれた。 。 適切なデータとモデルの複雑さを考慮すると、AlphaCode は一貫した構造を生成できます。ただし、この順次生成手順の最終レシピは LLM のパラメーターの奥深くに埋め込まれており、わかりにくいものです。 しかし、AlphaCode がプログラミングの問題を本当に「理解」できるかどうかに関係なく、コーディング コンテストでは人間の平均的なレベルに達しています。 「プログラミング コンテストの問題を解決することは非常に困難であり、人間には優れたコーディング スキルと問題解決の創造力が必要です。AlphaCode はこの分野で成功を収めることができます。」私はその進歩に感銘を受け、モデルがステートメントの理解をどのように利用してコードを生成し、確率的探索をガイドして解決策を作成するかを見るのが楽しみです。」 # —Petr Mitrichev、Google ソフトウェア エンジニア、世界-クラスの競争力のあるプログラマー AlphaCode はプログラミング コンテストの上位 54% にランクインし、ディープ ラーニング モデルが思考のタスクにおいて批判的思考の可能性をどのように必要とするかを実証しました。 これらのモデルは、最新の機械学習をエレガントに活用して、問題の解決策をコードとして表現し、数十年前の AI の象徴的推論のルーツを思い出させます。 そして、これはほんの始まりにすぎません。 将来的には、より強力な問題解決AIが誕生するでしょう、その日もそう遠くないかもしれません。 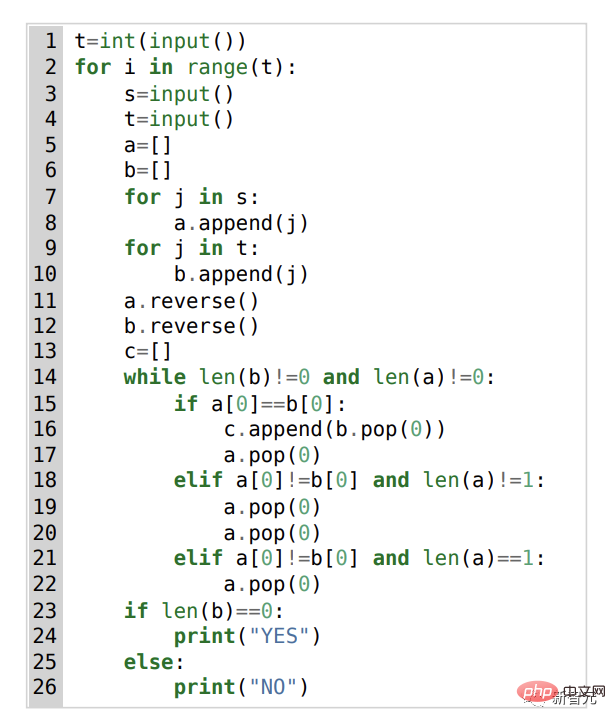

以上が超プログラムされたAIがサイエンス誌の表紙に登場! AlphaCode プログラミング コンテスト: プログラマーの半数が出場の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。