
ホームページ >テクノロジー周辺機器 >AI >DAMO-YOLO: 速度と精度の両方を考慮した効率的なターゲット検出フレームワーク
DAMO-YOLO: 速度と精度の両方を考慮した効率的なターゲット検出フレームワーク

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-28 16:43:062013ブラウズ

1. ターゲット検出の概要
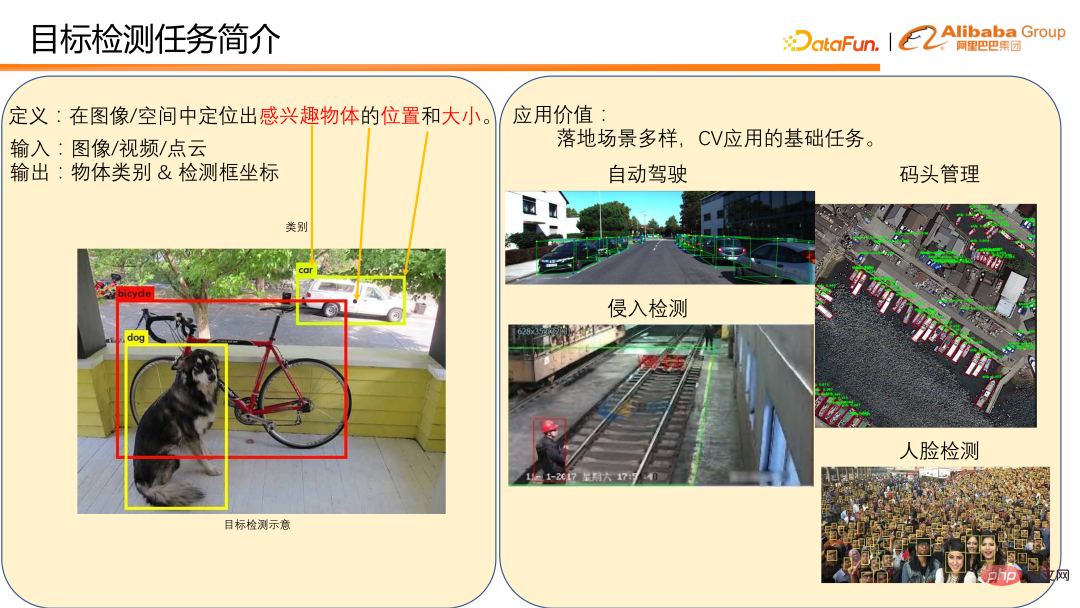
ターゲット検出の定義は、画像内で関心のあるオブジェクトを見つけることです。 /space の場所とサイズ。
# 通常、画像、ビデオ、または点群を入力し、オブジェクトのカテゴリと検出フレームの座標を出力します。左下の図は、画像上の物体検出の例です。自動運転シナリオにおける車両や歩行者の検出、ドック管理における停泊検出など、ターゲット検出には多くのアプリケーション シナリオがあります。これらはどちらも物体検出への直接の応用です。ターゲット検出は、工場で使用される侵入検出や顔認識など、多くの CV アプリケーションの基本タスクでもあり、検出タスクを完了するための基礎として歩行者検出と顔検出が必要です。ターゲット検出は日常生活において多くの重要な用途に使用されており、CV 実装におけるその位置も非常に重要であるため、この分野は競争が激しい分野です。
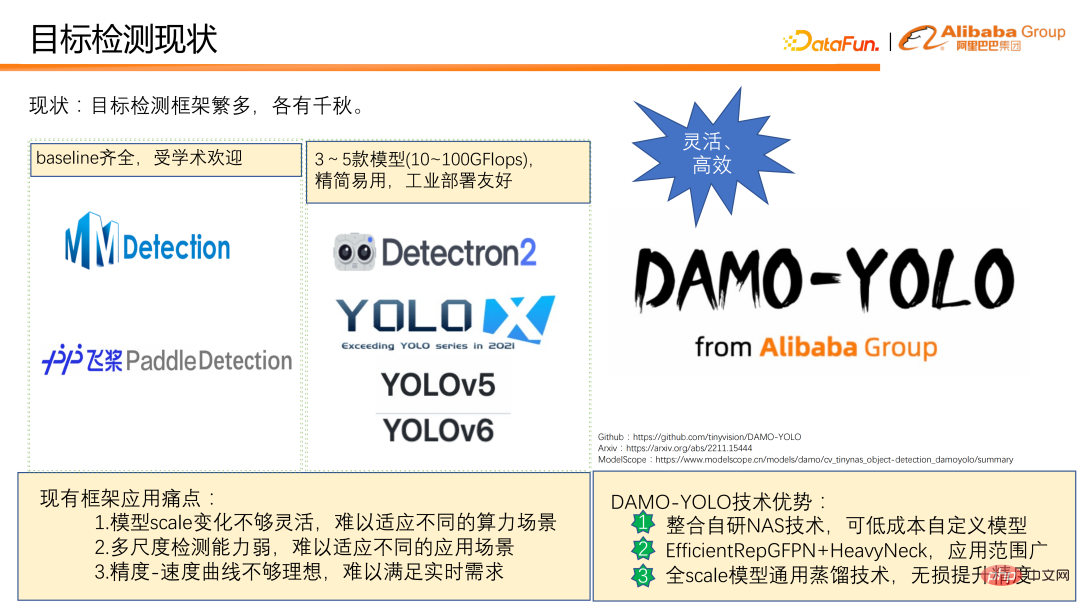
現在、独自の特徴を持つ多くのターゲット検出フレームワークが存在します。蓄積された実際の使用経験に基づいて、現在の検出フレームワークには実用化において次のような課題があることがわかりました。
① モデルスケールの変更が不十分柔軟だが、さまざまなコンピューティング能力のシナリオに適応するのは難しい。たとえば、YOLO シリーズの検出フレームワークは通常、12 フロップから 100 フロップを超える範囲の 3 ~ 5 モデルの計算量しか提供しないため、さまざまな計算能力シナリオをカバーすることが困難になります。
② マルチスケール検出機能は弱く、特に小さなオブジェクトの検出パフォーマンスが低いため、モデルの適用シナリオが非常に限定されます。たとえば、ドローン検出シナリオでは、その結果が理想的でないことがよくあります。
③ 速度/精度曲線は十分に理想的ではなく、速度と精度を同時に両立させることは困難です。
上記の状況に対応して、私たちは DAMO-YOLO を設計し、オープンソース化しました。 DAMO-YOLO は主に産業上の実装に焦点を当てています。他のターゲット検出フレームワークと比較して、これには 3 つの明らかな技術的利点があります。
① 自社開発の NAS テクノロジーを統合し、低コストでモデルをカスタマイズできるため、ユーザーはチップ コンピューティングを最大限に活用できます。力。 。
#② 効率的な RepGFPN と HeavyNeck モデル設計パラダイムを組み合わせることで、モデルのマルチスケール検出機能を大幅に向上させ、モデルの適用範囲を拡大できます。
#③ 小型、中型、大型モデルの精度を容易に向上できる本格的な万能蒸留技術を提案。
# 以下では、3 つの技術的利点の価値から DAMO-YOLO をさらに分析します。
2. DAMO-YOLO の技術価値
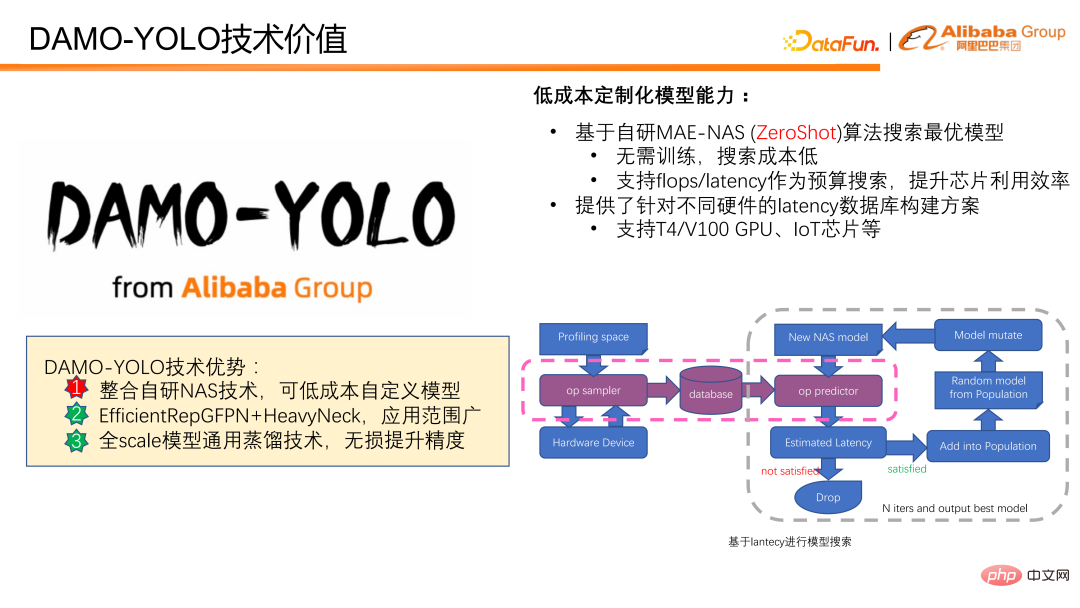
DAMO-YOLO は独自のモデルベースで低コストのモデルカスタマイズを実現します。開発されたMAE-NASアルゴリズム。モデルは、レイテンシーまたは FLOPS の予算に基づいて低コストでカスタマイズできます。モデル評価スコアを提供するためにモデルのトレーニングや実際のデータの参加を必要とせず、モデル検索のコストが低くなります。 FLOPS をターゲットにすると、チップのコンピューティング能力を最大限に活用できます。予算に合わせて遅延を指定して検索することは、遅延に関する厳しい要件があるさまざまなシナリオに非常に適しています。また、さまざまなハードウェア遅延シナリオに対応したデータベース構築ソリューションも提供しており、遅延をターゲットにした検索を誰でも簡単に行うことができます。
次の図は、モデル検索に時間遅延を使用する方法を示しています。まず、ターゲット チップまたはターゲット デバイスをサンプリングして、考えられるすべてのオペレーターの遅延を取得し、遅延データに基づいてモデルの遅延を予測します。予測されたモデルの大きさが事前に設定された目標を満たしている場合、モデルは後続のモデル更新とスコア計算に入ります。最後に、反復更新の後、遅延制約を満たす最適なモデルが取得されます。
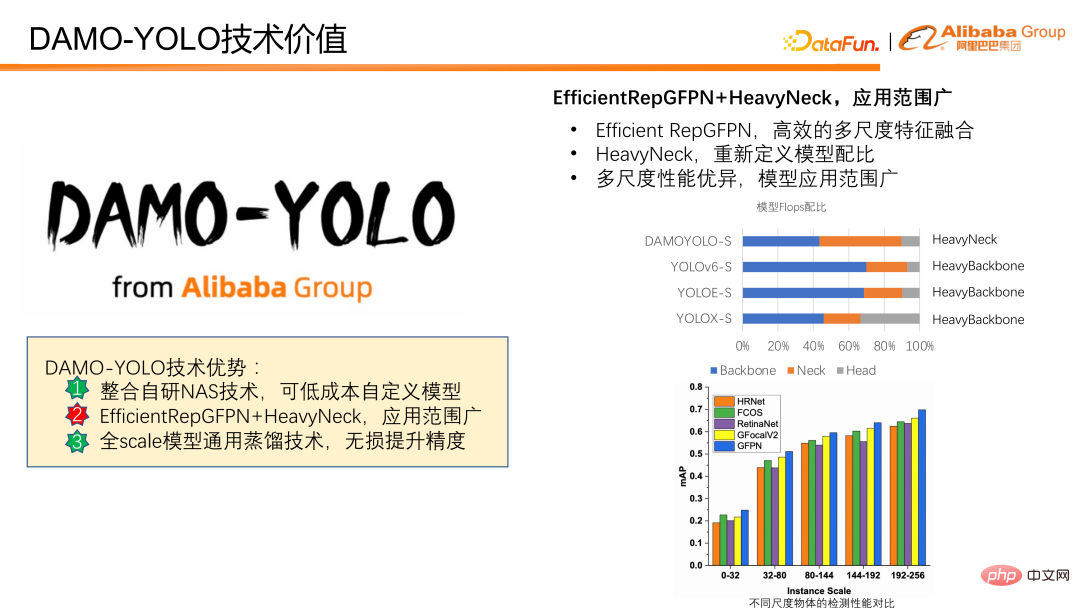
# 次に、モデルのマルチスケール検出機能を強化する方法を紹介します。 。 DAMO-YOLO は、提案された Efficient RepGFPN と革新的な HeavyNeck を組み合わせて、マルチスケール検出機能を大幅に向上させます。効率的な RepGFPN は、マルチスケールの特徴融合を効率的に完了できます。 HeavyNeck パラダイムは、モデルの大量の FLOPS を機能融合レイヤーに割り当てることを指します。モデルの FLOPS 比テーブルなど。 DAMO-YOLO-Sを例に挙げると、ネックの計算量がモデル全体の半分近くを占めており、主にバックボーンに計算量を配置する他のモデルとは大きく異なります。
3. DAMO-YOLO アプリケーションの値
# #上記の技術価値をもとに、どの程度の応用価値に換算できるでしょうか?以下では、DAMO-YOLO と他の現在の SOTA 検出フレームワークとの比較を紹介します。
DAMO-YOLO 現在のSOTAと比較して、同じ精度でモデル速度が20%~40%速くなり、計算量が15%削減されます-50%、パラメータは 6%-50% 減少し、すべてのスケールと広い適用範囲で明らかな増加ポイントがあります。さらに、小さなオブジェクトと大きなオブジェクトの両方で明らかな改善が見られます。
上記のデータの比較から、DAMO-YOLO は高速で、フロップスが低く、幅広いアプリケーションを備えていることがわかります。また、チップの使用効率を向上させるために、計算能力に合わせてモデルをカスタマイズします。
ModelScope上に関連モデルが公開されており、3行~5行のコード構成で推論や学習が可能で、利用体験が可能です。使用中に質問や問題がある場合は、コメント欄でコメントをお待ちしています。
# 次に、DAMO-YOLO の 3 つの技術的利点に焦点を当て、その背後にある原則を紹介します。誰もが DAMO-YOLO をよりよく理解し、使用できるようにするためです。 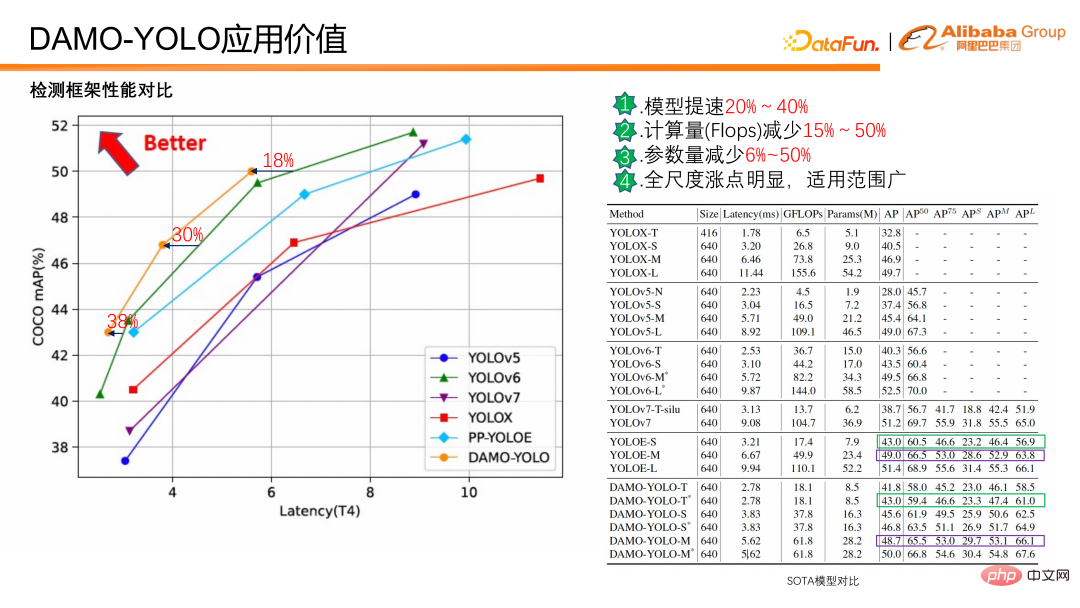
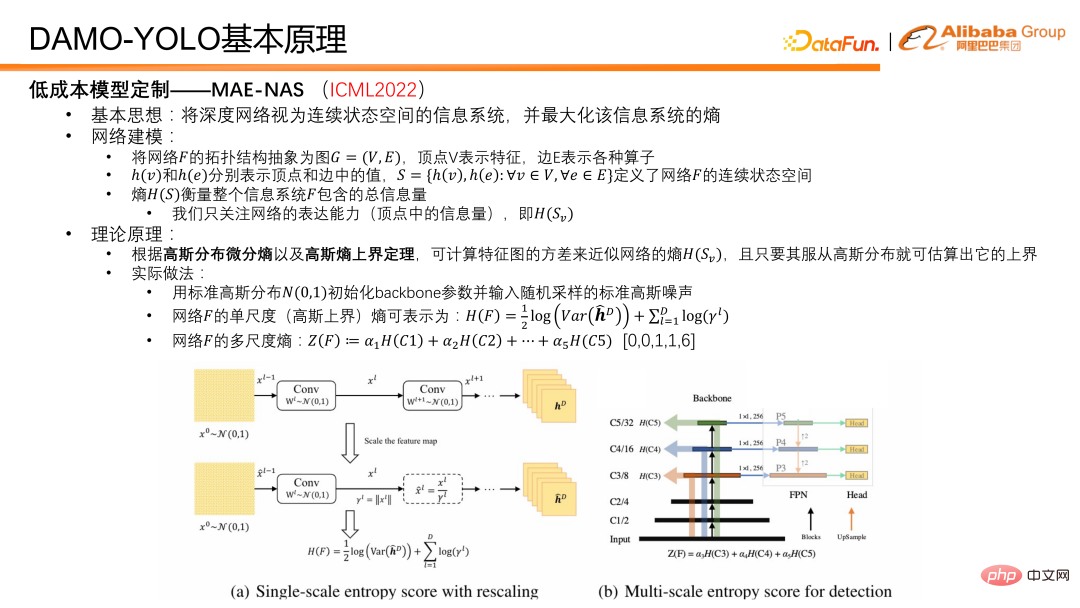
4. DAMO-YOLO の原理紹介まず、低コストモデルカスタマイズ機能 MAE-NAS のキーテクノロジーを紹介します。その基本的な考え方は、ディープネットワークを連続状態空間を持つ情報システムとみなして、情報システムを最大化できるエントロピーを求めるというものである。
ネットワーク モデリングのアイデアは次のとおりです。ネットワーク F のトポロジー構造をグラフ G=(V,E) に抽象化します。頂点 V は特徴を表し、エッジ E はさまざまな演算子を表します。 。これに基づいて、h(v) と h(e) を使用してそれぞれ頂点と辺の値を表すことができ、ネットワークの連続状態空間とエントロピーを定義する集合 S を生成できます。集合 S は、ネットワークまたは情報システム F 内の情報の総量を表すことができます。頂点の情報量はネットワークの表現力を測り、エッジの情報量はネットワークの複雑さを測るエッジのエントロピーでもあります。 DAMO-YOLO オブジェクト検出タスクの場合、私たちの主な関心はネットワークの表現能力を最大化することです。実際のアプリケーションでは、ネットワーク特徴のエントロピーのみが考慮されます。ガウス分布微分エントロピーとガウス エントロピー上限定理に従って、特徴マップの分散を使用してネットワーク特徴エントロピーの上限を近似します。
実際の操作では、最初にネットワーク バックボーンの重みを標準ガウス分布で初期化し、標準ガウス ノイズ イメージを入力として使用します。ガウス ノイズが順方向パスのためにネットワークに供給された後、いくつかの特徴を取得できます。次に、各スケール特徴の単一スケール エントロピー、つまり分散が計算され、重み付けによってマルチスケール エントロピーが取得されます。重み付けプロセスでは、さまざまなスケールでの特徴の表現力のバランスをとるために先験的な係数が使用され、このパラメーターは通常 [0,0,1,1,6] に設定されます。このように設定する理由は以下の通りである。検出モデルでは一般特徴量を1/2から1/32までの5段階、つまり5段階の解像度に分けているためである。機能の効率的な利用を維持するために、最後の 3 つのステージのみを利用します。したがって、実際には、最初の 2 つのステージはモデルの予測に関与していないため、0 と 0 になります。他の 3 つについては、広範な実験を行った結果、1、1、および 6 がより優れたモデル比であることがわかりました。
上記の基本原則に基づいて、次のマルチスケール エントロピーを使用できます。ネットワークをパフォーマンス プロキシとして使用し、ネットワーク構造を検索するための基本フレームワークとして浄化アルゴリズムを使用し、完全な MAE-NAS を構成します。 NAS には多くの利点があります。まず、複数の推論バジェット制限をサポートしており、FLOPS、パラメーター量、レイテンシー、ネットワーク層数を使用してモデル検索を実行できます。第 2 に、きめの細かいネットワーク構造の非常に多くのバリエーションもサポートしています。ここではネットワーク検索の実行に進化的アルゴリズムが使用されるため、サポートされるネットワーク構造のバリエーションが増えるほど、検索時のカスタマイズの程度と柔軟性が高まります。さらに、ユーザーが検索プロセスをカスタマイズしやすいように、公式チュートリアルを提供しています。最後に、そして最も重要なことですが、MAE-NAS はゼロショートです。つまり、その検索には実際のデータの参加や実際のモデルのトレーニングは必要ありません。 CPU 上で数十分かけて検索し、現在の制約の下で最適なネットワーク結果を生成できます。
DAMO-YOLO では、MAE-NAS を使用して遅延の異なる T/S/M モデルのバックボーン ネットワークを検索対象として検索します。インフラストラクチャはパッケージ化されており、小規模モデルは ResStyle を使用し、大規模モデルは CSPStyle を使用します。
以下の表からわかるように、CSP-Darknet は CSP 構造を使用して手動で設計されたネットワークであり、YOLO v 5 でもある程度の成果を上げています。 /V6 幅広い用途に対応。 MAE-NAS を使用して基本構造を生成し、それを CSP でパッケージ化した後、モデルの速度と精度が大幅に向上したことがわかりました。さらに、小さいモデルでも MAE-ResNet フォームが表示され、精度が高くなります。 48.7 に達する可能性がある大型モデルで CPS 構造を使用することには明らかな利点があります。

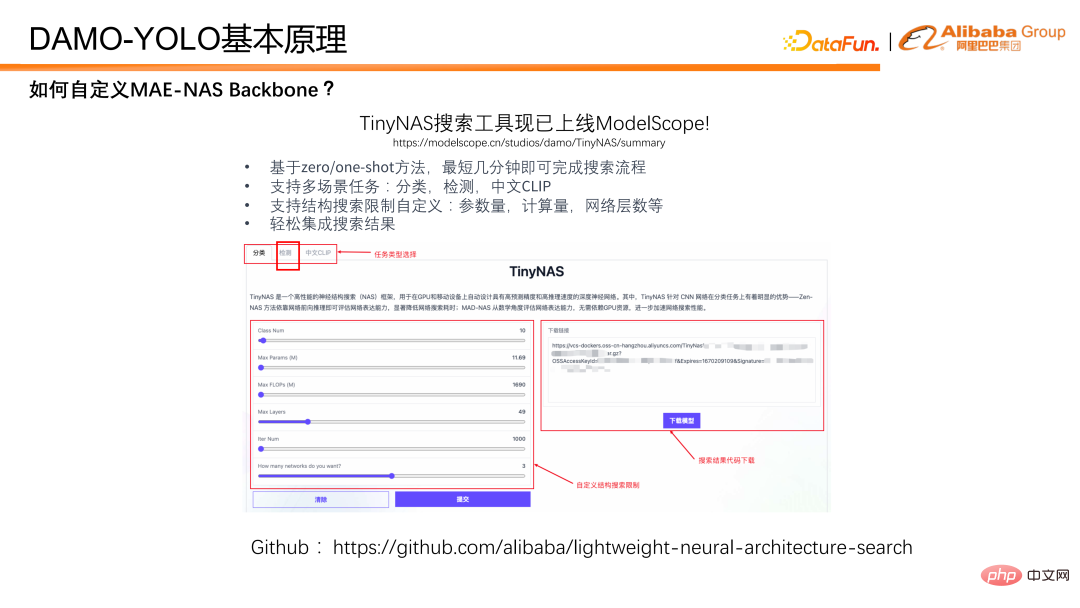
MAE-NAS を使用してバックボーンを検索するにはどうすればよいですか?ここでは、ModelScope ですでにオンラインになっている TinyNAS ツールボックスを紹介します。Web ページ上の視覚的な設定を通じて、目的のモデルを簡単に入手できます。同時に、MAE-NAS も github 上でオープンソース化されており、興味のある学生はオープンソースコードを基に、より自由に目的のモデルを探すことができます。
次に、DAMO-YOLO がネットワークのさまざまなスケールの機能の融合に依存するマルチスケールの検出機能をどのように改善するかを紹介します。以前の検出ネットワークでは、さまざまなスケールでの特徴の深さは大きく異なります。たとえば、高解像度の特徴は小さなオブジェクトの検出に使用されますが、その特徴の深さは浅いため、小さなオブジェクトの検出パフォーマンスに影響します。
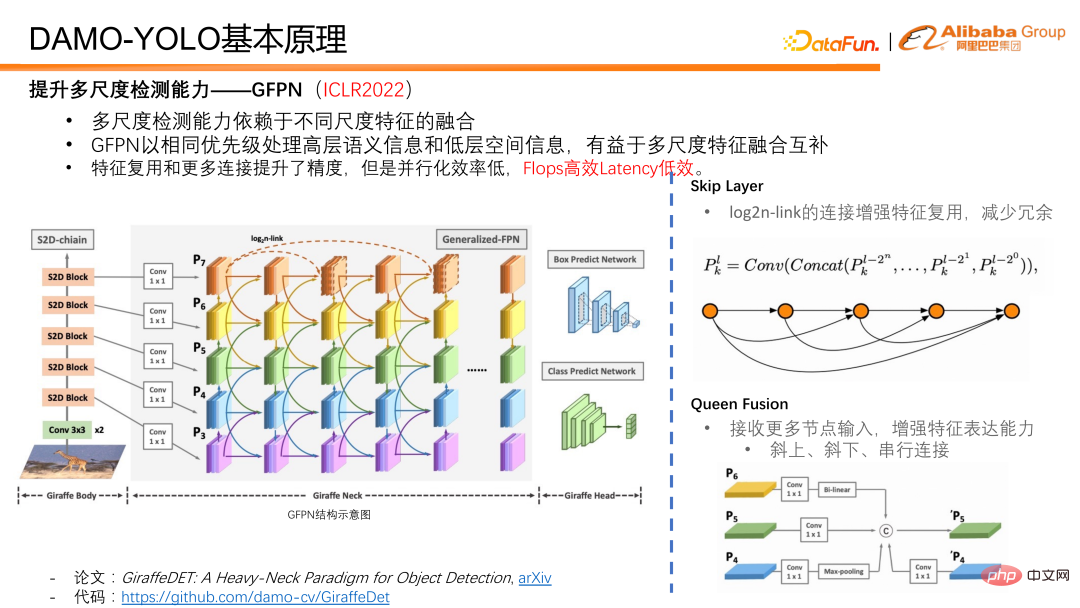
ICLR2022 - GFPN で提案した作品は、高レベルの意味情報と低レベルの空間情報を同じ優先度で同時に処理し、マルチスケール機能の融合と補完に非常に適しています。 。 GFPNの設計では、GFPNをより深く設計できるようにするために、まずスキップ層を導入しました。 log2n-link を使用して機能を再利用し、冗長性を削減します。
クイーンフュージョンは、異なるスケールのフィーチャと異なる深さのフィーチャのインタラクティブなフュージョンを増やすことです。クイーン フュージョンの各ノードは、斜めの上下で異なるスケール フィーチャを受信することに加えて、同じフィーチャ深度で異なるスケール フィーチャも受信します。これにより、フィーチャ フュージョン中の情報量が大幅に増加し、同じ深度でのマルチスケール情報が促進されます。フュージョンオン。
#GFPN の機能の再利用と独自の接続設計により、モデルの精度が向上しました。スキップ レイヤーとクイーン フュージョンは、アップサンプリングおよびダウンサンプリング操作だけでなく、マルチスケール フィーチャ ノード上でフュージョン操作を実行するため、推論にかかる時間が大幅に増加し、業界の実装要件を満たすことが困難になります。したがって、実際には、GFPN は FLOPS 効率は高いものの、遅延効率が低い構造です。 GFPN のいくつかの欠陥を考慮して、その理由を次のように分析して考えました。
① まず第一に、異なる規模の機能が実際にはチャネル数を共有しています。機能が冗長であり、ネットワーク構成が十分に柔軟ではありません。
② 次に、Queen 機能にはアップサンプリング接続とダウンサンプリング接続があり、アップサンプリング演算子とダウンサンプリング演算子の時間消費が大幅に改善されます。
③ 第三に、ノードがスタックされている場合、同じ機能深度でのシリアル接続により GPU の並列効率が低下し、各スタックによってシリアル パスの増大がもたらされます。重要な意味を持ちました。
#これらの問題に対処するために、対応する最適化を行い、Efficient RepGFPN を提案しました。
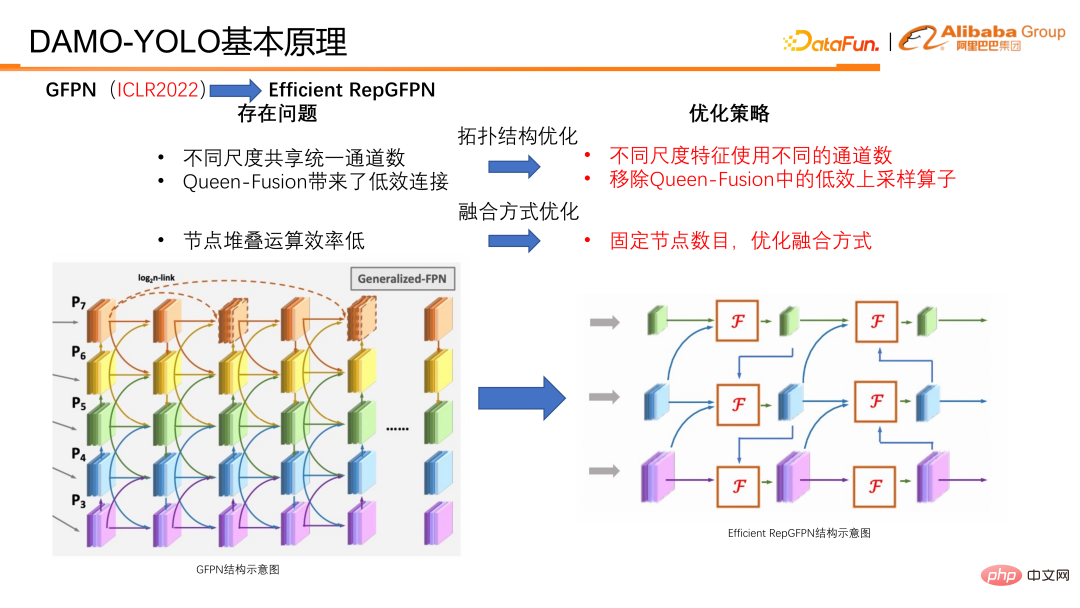
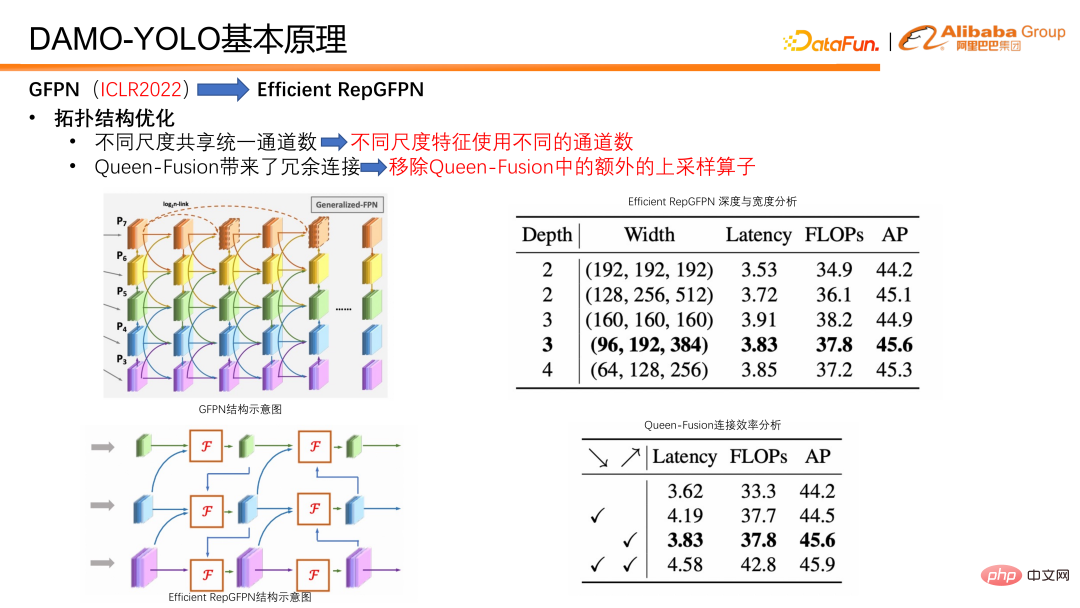
最適化には主に 2 つのカテゴリに分けられ、1 つはトポロジ構造の最適化です。 . 、もう 1 つのカテゴリは融合手法の最適化です。 トポロジ最適化の観点から、Efficient RepGFPN は、スケールの異なる機能に対して異なるチャネル番号を使用するため、軽量計算の制約の下で高レベルの機能と低レベルの機能を柔軟に制御できます。 . 表現力。 FLOPS と遅延近似の場合、柔軟な構成により最高の精度と速度効率を実現できます。さらに、クイーンフュージョンにおける接続の効率解析も行ったところ、アップサンプリングオペレータには多大な負担があるものの、精度の向上は小さく、ダウンサンプリングオペレータのメリットに比べてはるかに低いことがわかりました。そこで、クイーン フュージョンのアップサンプリング接続を削除しました。表でわかるように、実際には斜め下にある目盛りはアップサンプリング、斜め上にある目盛りはダウンサンプリングです。左の図と比較すると、小さな解像度が下に行くほど徐々に大きな解像度になっていることがわかります。右下は、低解像度の特徴をアップサンプリングし、高解像度の特徴に接続し、高解像度の特徴に融合することが目的です。最終的な結論は、ダウンサンプリング オペレーターのリターンは高く、アップサンプリング オペレーターのリターンは非常に低いということです。そのため、GFPN 全体の効率を向上させるために、Queen 機能のアップサンプリング接続を削除しました。
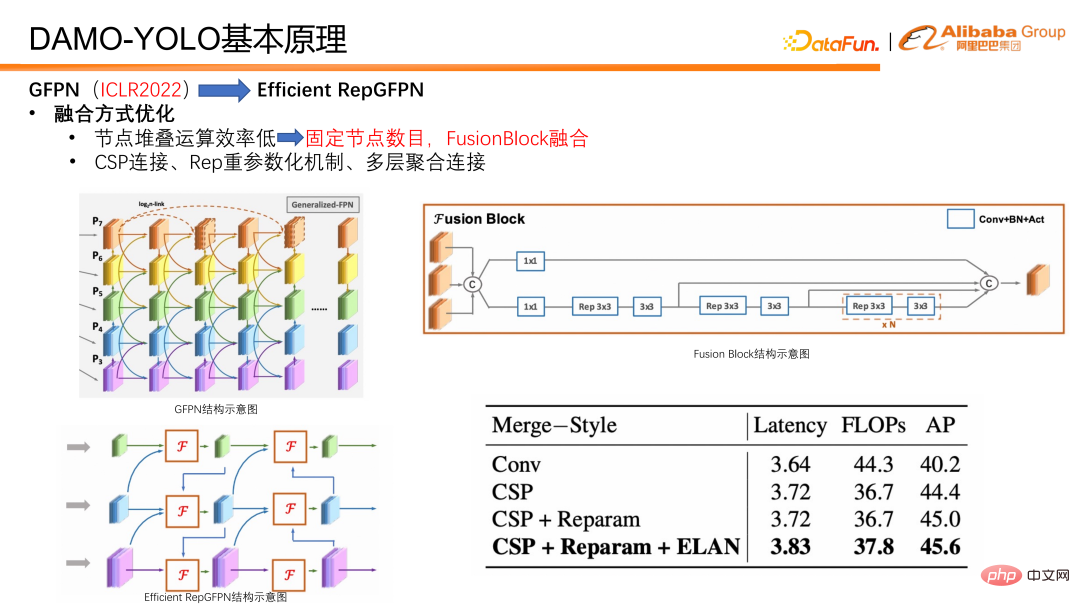
統合方法に関しても、いくつかの最適化を行いました。まず、以前のようにより深い GFPN を作成するために継続的にフュージョンを積み重ねるのではなく、各モデルで 2 つのフュージョンのみが実行されるようにフュージョン ノードの数を修正します。これにより、シリアル リンクの継続的な増加によって引き起こされる並列効率が回避されます。さらに、機能融合用に融合ブロックを特別に設計しました。 fusion block では、融合効果をさらに向上させるために、重いパラメータ化メカニズムや多層アグリゲーション接続などのテクノロジーを導入します。
#ネックに加えて、検出ヘッドヘッドも検出の重要な部分です。モデル。 Neck によって出力された特徴を入力として受け取り、回帰および分類の結果を出力します。私たちは、Efficient RepGFPN と Head の間のトレードオフを検証するために実験を設計しました。その結果、モデルの遅延が厳密に制御されている場合、Efficient RepGFPN が深いほど優れていることがわかりました。したがって、ネットワーク設計では、計算量は主に Efficient RepGFPN に割り当てられ、Head 部分には分類および回帰タスク用に線形投影の 1 層だけが確保されます。 1 つの分類層と 1 つの回帰非線形マッピング層のみを持つヘッドを ZeroHead と呼びます。この計算負荷を主に Neck に割り当てる設計パターンは、HeavyNeck パラダイムと呼ばれます。
DAMO-YOLO の最終的なモデル構造を次の図に示します。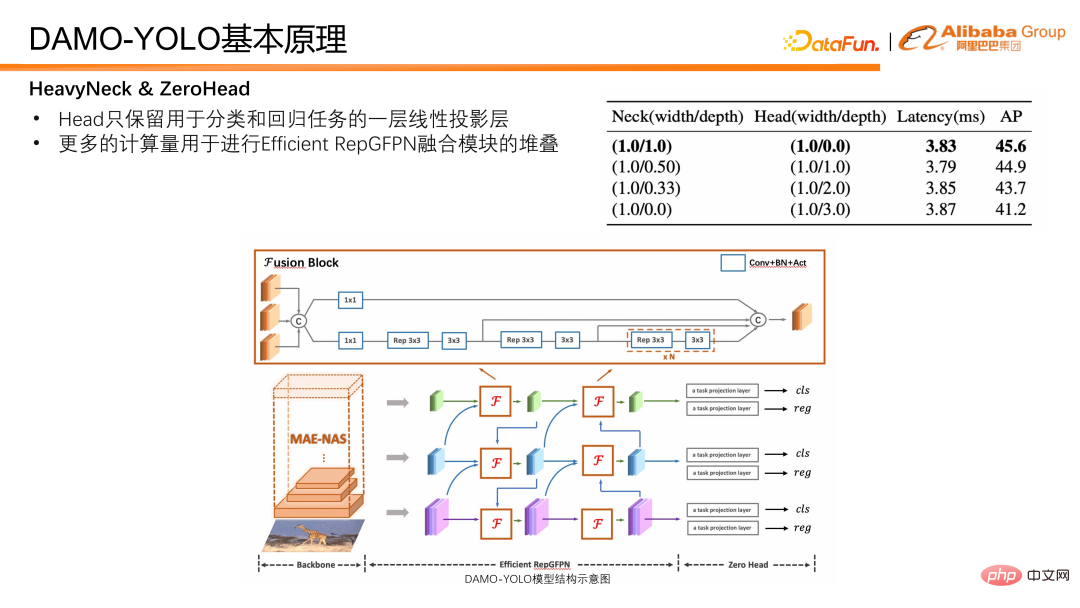
上記は、モデル設計における についての考えです。最後に蒸留スキームを紹介しましょう。
DAMO-YOLO から Efficient RepGFPN の出力特徴を蒸留のために取得します。生徒機能はまず alignmodule を通過して、チャネル番号を教師に合わせます。モデル自体の偏りを取り除くために、生徒と教師の特徴を不偏 BN で正規化し、蒸留損失の計算を実行します。蒸留中に、過剰な損失が生徒自身の分類ブランチの収束を妨げることが観察されました。そこで、トレーニングとともに減衰する動的ウェイトを使用することにしました。実験結果から、動的均一蒸留重量は T/S/M モデルに対してロバストです。
DAMO-YOLO の蒸留チェーンは、L 蒸留 M、M 蒸留 S です。 M が S を蒸留する場合、M は CSP パッケージングを使用し、S は Res パッケージングを使用することに注意してください。構造的に言えば、M と S は異性体です。ただし、DAMO-YOLO 蒸留スキーム (M で S を蒸留) を使用すると、蒸留後に 1.2 ポイント改善する可能性もあり、この蒸留スキームが異性化に対しても堅牢であることを示しています。要約すると、DAMO-YOLO の蒸留スキームには自由なパラメーターがあり、あらゆるモデルをサポートし、異種混合で堅牢です。
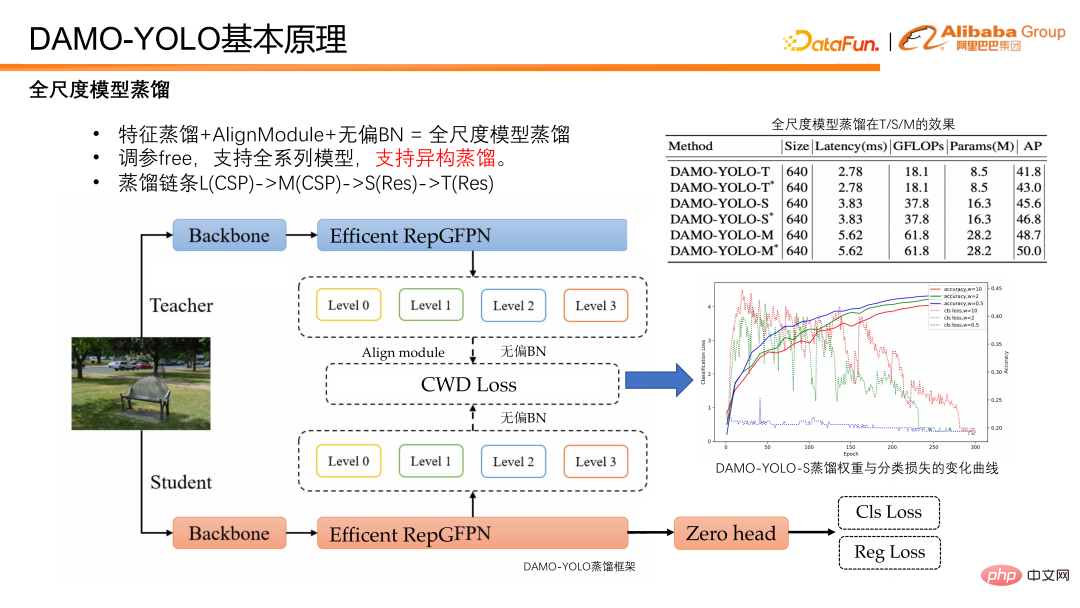
最後に、DAMO-YOLO についてまとめます。 DAMO-YOLO は、MAE-NAS テクノロジーを組み合わせて、低コストのモデルのカスタマイズを可能にし、チップのコンピューティング能力を最大限に活用します。効率的な RepGFPN および HeavyNeck パラダイムと組み合わせることで、マルチスケール検出機能が向上し、幅広いモデル アプリケーションを実現します。スケール蒸留スキームにより、モデル効率をさらに向上させることができます。

5. DAMO-YOLO 開発計画
DAMO-YOLO はリリースされたばかりですが、まだたくさんあります。改善すべき点や改善すべき点を最適化するところ。短期的には展開ツールを改善し、ModelScope をサポートする予定です。さらに、UAV 小型ターゲット検出や回転ターゲット検出など、グループ内の競争チャンピオン ソリューションに基づいて、より多くのアプリケーション例が提供される予定です。また、デバイス用の Nano モデルやクラウド用の Large モデルなど、さらに多くのサンプル モデルをリリースする予定です。最後に、皆さんが注目して肯定的なフィードバックを提供してくれることを願っています。

以上がDAMO-YOLO: 速度と精度の両方を考慮した効率的なターゲット検出フレームワークの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。