
ホームページ >Java >&#&チュートリアル >職場での Java ロック使用シナリオの分析
職場での Java ロック使用シナリオの分析

- PHPz転載
- 2023-04-28 15:34:141120ブラウズ
1. synchronized
Synchronized は、ReentrantLock ロック関数に似た再入可能な排他ロックです。synchronized が使用されているほぼどこでも使用できます。両者の最大の類似点は、リエントラント排他ロックです。両者の主な違いは次のとおりです:
ReentrantLock には、条件の提供、ロック API など、より豊富な機能があります。ロック キューを満たす可能性のある中断された複雑なシナリオなど。;
再入ロックは公正なロックと不公平なロックに分類できますが、同期は両方とも不公平なロックです。
両者の利用姿勢も異なり、ReentrantLock はロックとロック解除の API があることを明記する必要があるのに対し、synchronized はコードブロックのロックとロック解除を自動で行うため、synchronized の方が便利です。使うと便利です。
synchronized と ReentrantLock は同様の機能があるため、synchronized を例に説明します。
1.1. 共有リソースの初期化
分散システムでは、プロジェクトの開始時にいくつかの無効な設定リソースを JVM メモリにロックし、設定時にリクエストがこれらのリソースを取得できるようにすることを好みます。リソースが共有されると、毎回データベースから取得する必要がなく、メモリから直接取得できるため、時間のオーバーヘッドが削減されます。
通常、このような共有リソースには、無効なビジネス プロセス構成や無効なビジネス ルール構成が含まれます。
共有リソースの初期化の手順は一般的に次のとおりです: プロジェクトの起動 -> 初期化アクションのトリガー -> 単一スレッドでデータベースからデータを取得 -> 必要なデータ構造にアセンブル -> JVM への配置メモリ 。
プロジェクトの開始時に、共有リソースが複数回読み込まれるのを防ぐために、1 つのスレッドが共有リソースの読み込みを完了した後、別のスレッドが読み込みを継続できるように、排他ロックを追加することがよくあります。 , 排他的ロック ロックには synchronized または ReentrantLock を選択できます. synchronized を例として、次のようにモック コードを作成しました:
// 共享资源
private static final Map<String, String> SHARED_MAP = Maps.newConcurrentMap();
// 有无初始化完成的标志位
private static boolean loaded = false;
/**
* 初始化共享资源
*/
@PostConstruct
public void init(){
if(loaded){
return;
}
synchronized (this){
// 再次 check
if(loaded){
return;
}
log.info("SynchronizedDemo init begin");
// 从数据库中捞取数据,组装成 SHARED_MAP 的数据格式
loaded = true;
log.info("SynchronizedDemo init end");
}
}@PostConstruct アノテーションが見つかったかどうかはわかりません@PostConstruct アノテーションの機能は、Spring コンテナが初期化されると、このアノテーションが付けられたメソッドが実行される、つまり Spring コンテナの起動時に上図の init メソッドがトリガーされることです。
デモ コードをダウンロードし、DemoApplication スタートアップ ファイルを見つけ、DemoApplication ファイルを右クリックして [実行] をクリックして Spring Boot プロジェクト全体を開始し、init メソッドにブレークポイントを設定してデバッグできます。
コード内で synchronized を使用して、1 つのスレッドだけが共有リソースの初期化操作を同時に実行できるようにし、共有リソースの読み込み完了フラグ (loaded) を追加して、読み込みが完了したかどうかを判断します。ロードが完了すると、他のロード スレッドは直接戻ります。
synchronized を ReentrantLock に置き換える場合、実装は同じですが、明示的に ReentrantLock の API を使用してロックとロックの解放を行う必要がある点が異なります。ロック、ロックの解放は、finally メソッド ブロックで行います。これにより、try でロックを追加した後に例外が発生した場合でも、finally で正しくロックを解放できます。
学生の中には、「ConcurrentHashMap を直接使用できないの?なぜロックする必要があるの?」と尋ねる人もいるかもしれません。 ConcurrentHashMap がスレッド セーフであることは確かですが、スレッド セーフを保証できるのは Map の内部データ操作中のみであり、マルチスレッド状況では、データベースのクエリとデータの組み立てというアクション全体が 1 回だけ実行されることは保証できません。 add synchronized locks が操作全体であり、操作全体が 1 回だけ実行されることが保証されます。
2. CountDownLatch
2.1. シナリオ
1: Xiao Ming は、淘宝網で商品を購入しましたが、良くないと感じたので、商品を返品しました (商品はまだ届いていません)単一製品の返金がバックグラウンド システムで実行される場合、全体の消費時間は 30 ミリ秒です。
2: ダブル 11 の期間中、シャオ ミンはタオバオで 40 個の商品を購入し、同じ注文を生成しました (実際には複数の注文が生成される可能性がありますが、説明の便宜上、それらを 1 つと呼びます)。そのうち、衝動買いした商品が30点あり、30点をまとめて返品する必要があります。
2.2. 実装
現時点では、バックエンドには単一の商品を返金する機能のみがあり、製品のバッチを返金する機能はありません (一度に 30 個の商品を返品すると呼ばれます)この関数を迅速に実装するために、学生 A は次の計画に従って実行しました: for ループで 1 つの製品の返金インターフェイスを 30 回呼び出しました。QA 環境テスト中に、30 個の製品が返金される場合、かかる時間: 30 * 30 = 900 ミリ秒。他のロジックと組み合わせると、30 個の商品を返金するのにほぼ 1 秒かかりますが、実際には長い時間がかかります。当時、クラスメート A がこの質問を提起し、みんなが最適化に協力してくれることを願っていました。シナリオ全体の消費時間。
同学 B 当时就提出,你可以使用线程池进行执行呀,把任务都提交到线程池里面去,假如机器的 CPU 是 4 核的,最多同时能有 4 个单商品退款可以同时执行,同学 A 觉得很有道理,于是准备修改方案,为了便于理解,我们把两个方案都画出来,对比一下:
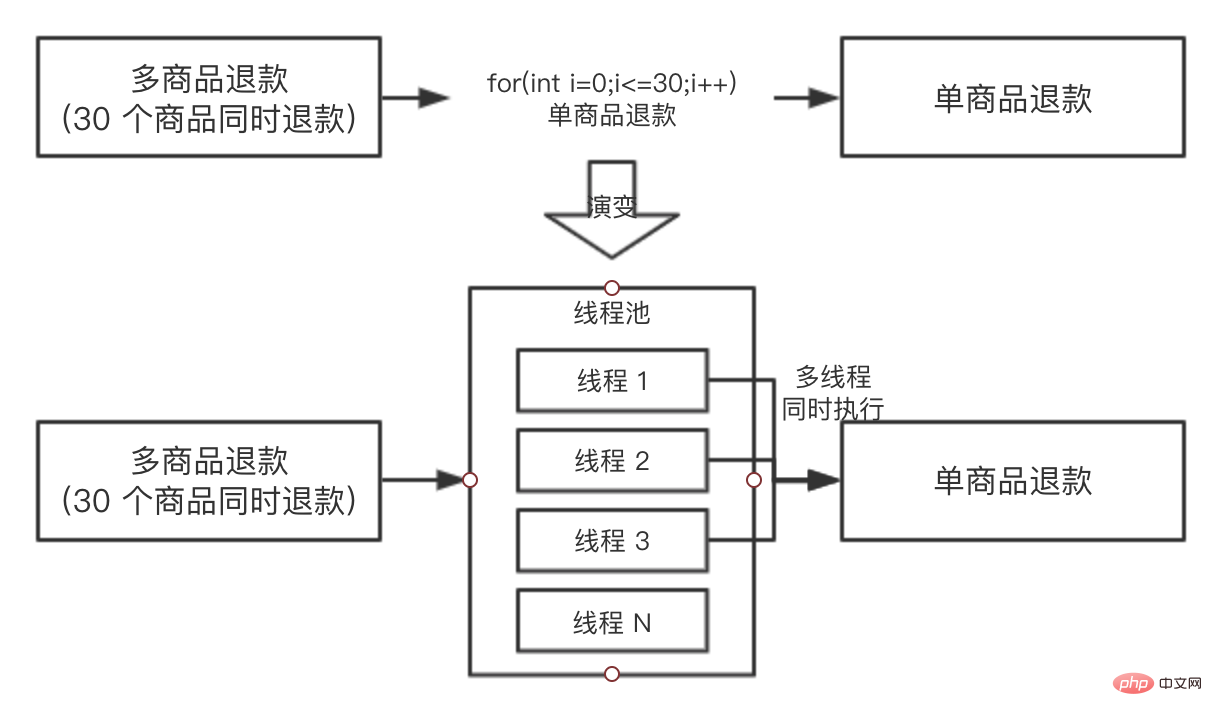
同学 A 于是就按照演变的方案去写代码了,过了一天,抛出了一个问题:向线程池提交了 30 个任务后,主线程如何等待 30 个任务都执行完成呢?因为主线程需要收集 30 个子任务的执行情况,并汇总返回给前端。
大家可以先不往下看,自己先思考一下,我们前几章说的那种锁可以帮助解决这个问题?
CountDownLatch 可以的,CountDownLatch 具有这种功能,让主线程去等待子任务全部执行完成之后才继续执行。
此时还有一个关键,我们需要知道子线程执行的结果,所以我们用 Runnable 作为线程任务就不行了,因为 Runnable 是没有返回值的,我们需要选择 Callable 作为任务。
我们写了一个 demo,首先我们来看一下单个商品退款的代码:
// 单商品退款,耗时 30 毫秒,退款成功返回 true,失败返回 false
@Slf4j
public class RefundDemo {
/**
* 根据商品 ID 进行退款
* @param itemId
* @return
*/
public boolean refundByItem(Long itemId) {
try {
// 线程沉睡 30 毫秒,模拟单个商品退款过程
Thread.sleep(30);
log.info("refund success,itemId is {}", itemId);
return true;
} catch (Exception e) {
log.error("refundByItemError,itemId is {}", itemId);
return false;
}
}
}接着我们看下 30 个商品的批量退款,代码如下:
@Slf4j
public class BatchRefundDemo {
// 定义线程池
public static final ExecutorService EXECUTOR_SERVICE =
new ThreadPoolExecutor(10, 10, 0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(20));
@Test
public void batchRefund() throws InterruptedException {
// state 初始化为 30
CountDownLatch countDownLatch = new CountDownLatch(30);
RefundDemo refundDemo = new RefundDemo();
// 准备 30 个商品
List<Long> items = Lists.newArrayListWithCapacity(30);
for (int i = 0; i < 30; i++) {
items.add(Long.valueOf(i+""));
}
// 准备开始批量退款
List<Future> futures = Lists.newArrayListWithCapacity(30);
for (Long item : items) {
// 使用 Callable,因为我们需要等到返回值
Future<Boolean> future = EXECUTOR_SERVICE.submit(new Callable<Boolean>() {
@Override
public Boolean call() throws Exception {
boolean result = refundDemo.refundByItem(item);
// 每个子线程都会执行 countDown,使 state -1 ,但只有最后一个才能真的唤醒主线程
countDownLatch.countDown();
return result;
}
});
// 收集批量退款的结果
futures.add(future);
}
log.info("30 个商品已经在退款中");
// 使主线程阻塞,一直等待 30 个商品都退款完成,才能继续执行
countDownLatch.await();
log.info("30 个商品已经退款完成");
// 拿到所有结果进行分析
List<Boolean> result = futures.stream().map(fu-> {
try {
// get 的超时时间设置的是 1 毫秒,是为了说明此时所有的子线程都已经执行完成了
return (Boolean) fu.get(1,TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
return false;
}).collect(Collectors.toList());
// 打印结果统计
long success = result.stream().filter(r->r.equals(true)).count();
log.info("执行结果成功{},失败{}",success,result.size()-success);
}
}上述代码只是大概的底层思路,真实的项目会在此思路之上加上请求分组,超时打断等等优化措施。
我们来看一下执行的结果:
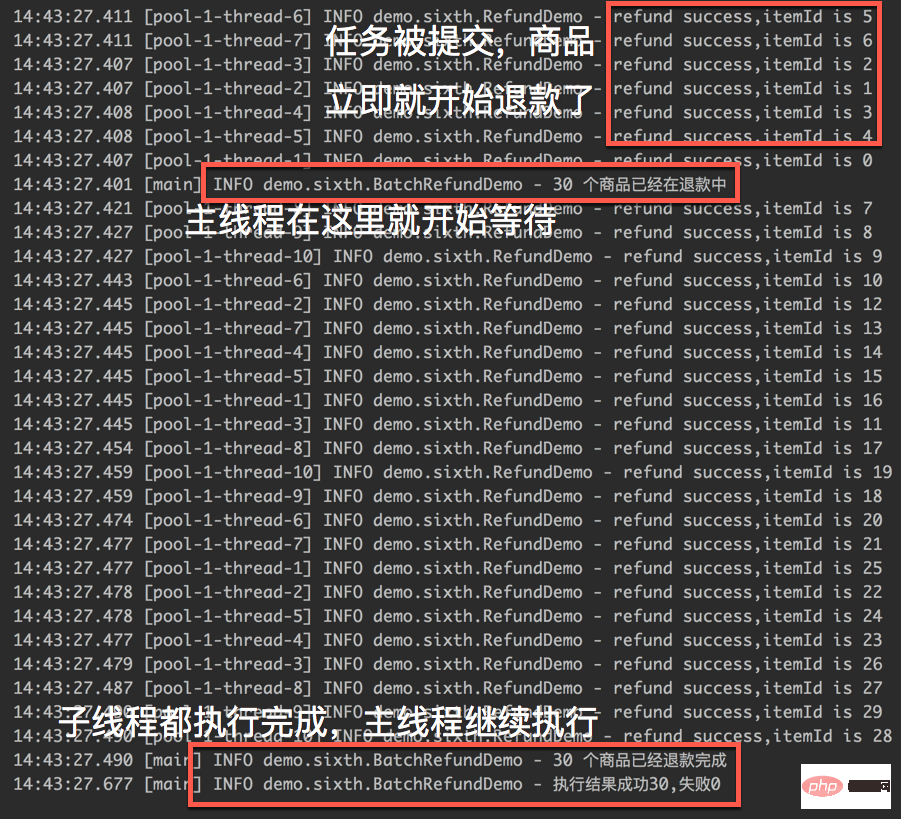
从执行的截图中,我们可以明显的看到 CountDownLatch 已经发挥出了作用,主线程会一直等到 30 个商品的退款结果之后才会继续执行。
接着我们做了一个不严谨的实验(把以上代码执行很多次,求耗时平均值),通过以上代码,30 个商品退款完成之后,整体耗时大概在 200 毫秒左右。
而通过 for 循环单商品进行退款,大概耗时在 1 秒左右,前后性能相差 5 倍左右,for 循环退款的代码如下:
long begin1 = System.currentTimeMillis();
for (Long item : items) {
refundDemo.refundByItem(item);
}
log.info("for 循环单个退款耗时{}",System.currentTimeMillis()-begin1);性能的巨大提升是线程池 + 锁两者结合的功劳。
以上が職場での Java ロック使用シナリオの分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。