
ホームページ >テクノロジー周辺機器 >AI >研究により、類似性に基づく重み付けインターリーブ学習が深層学習における「健忘」問題に効果的に対処できることが示されています。
研究により、類似性に基づく重み付けインターリーブ学習が深層学習における「健忘」問題に効果的に対処できることが示されています。

- 王林転載
- 2023-04-26 21:40:07879ブラウズ
人間とは異なり、人工ニューラル ネットワークは新しいことを学習すると以前に学習した情報をすぐに忘れてしまうため、古い情報と新しい情報をインターリーブして再学習する必要がありますが、古い情報をすべてインターリーブするのは非常に時間がかかるため、必要ない場合もあります。新しい情報と実質的に同様の古い情報のみをインターリーブするだけで十分な場合がある。
最近、米国科学アカデミー紀要 (PNAS) は、研究員の研究員が執筆した「類似性加重インターリーブ学習によるディープ ニューラル ネットワークと脳の学習」という論文を発表しました。カナダ王立協会の承認を受け、著名な神経科学者ブルース・マクノートンのチームによって出版されました。彼らの研究では、類似性を重み付けしたインターリーブで古い情報を新しい情報とトレーニングすることで、ディープネットワークが新しいことを迅速に学習でき、忘却率が低下するだけでなく、使用するデータも大幅に削減できることがわかりました。
著者らはまた、最近活動したニューロンの進行中の興奮性の軌跡と神経力学的アトラクターのダイナミクスを追跡することによって、脳内で類似性の重み付けを達成できるという仮説を立てています。これらの発見は、神経科学と機械学習のさらなる進歩につながる可能性があります。
研究の背景
脳が生涯を通じてどのように学習するかを理解することは、依然として長期的な課題です。
人工ニューラル ネットワーク (ANN) では、新しい情報を迅速に統合すると、以前に取得した知識が突然失われる壊滅的な干渉が発生する可能性があります。相補学習システム理論 (CLST) は、新しい記憶を既存の知識と交互に挿入することによって、新皮質に徐々に統合できることを示唆しています。
CLST では、脳は相補的な学習システムに依存していると述べています。海馬 (HC) は新しい記憶を迅速に獲得し、新皮質 (NC) は新しいデータをコンテキストに徐々に統合します。 . 無関係な構造化された知識。睡眠中や静かに目覚めている間などの「オフライン期間」中、HC は NC での最近のエクスペリエンスの再生をトリガーしますが、NC は既存のカテゴリの表現を自発的に取得してインターリーブします。インターリーブ再生により、勾配降下法で NC シナプスの重みを段階的に調整して、新しい記憶をエレガントに統合し、壊滅的な干渉を克服するコンテキストに依存しないカテゴリ表現を作成できます。多くの研究では、インターリーブ再生を使用してニューラル ネットワークの生涯学習を達成することに成功しています。
ただし、CLST を実際に適用する場合、解決する必要がある重要な問題が 2 つあります。まず、脳がすべての古いデータにアクセスできない場合、情報の包括的なインターリーブはどのようにして行われるのでしょうか?考えられる解決策の 1 つは「疑似リハーサル」です。これは、以前に学習した例に明示的にアクセスせずに、ランダムな入力によって内部表現の生成的再生を引き出すことができます。アトラクターのようなダイナミクスにより、脳は「疑似リハーサル」を完了できる可能性がありますが、「疑似リハーサル」の内容はまだ解明されていません。したがって、2 番目の疑問は、新しい学習活動が行われるたびに、以前に学習したすべての情報を織り交ぜるのに十分な時間が脳にあるかどうかです。
類似性加重インターリーブ学習 (SWIL) アルゴリズムは、2 番目の問題の解決策と考えられています。このアルゴリズムは、インターリーブのみが新しい情報との表現上の実質的な類似性を持ち、古い情報でも十分である可能性があることを示しています。実証的な行動研究により、一貫性の高い新しい情報はほとんど干渉せずに NC 構造化知識に迅速に統合できることが示されています。これは、新しい情報が統合される速度は、事前の知識との一貫性に依存することを示唆しています。この行動結果に触発され、以前に得られたカテゴリ間の壊滅的な干渉の分布を再調査することによって、McClelland らは、SWIL が 2 つの上位概念カテゴリ (例: 「果物」は「リンゴ」と「バナナ」) のコンテキストで使用できることを実証しました。 "")、各エポックは新しい情報を学習するために 2.5 倍未満のデータ量を使用し、すべてのデータでネットワークをトレーニングした場合と同じパフォーマンスを達成します。しかし、研究者らは、より複雑なデータセットを使用した場合には同様の効果を発見できず、アルゴリズムのスケーラビリティについて懸念が生じました。
実験では、深層非線形人工ニューラル ネットワークが、新しい情報と表現上の類似性を大量に共有する古い情報のサブセットのみをインターリーブすることによって、新しい情報を学習できることが示されています。 SWIL アルゴリズムを使用することにより、ANN は、各エポックで提示される非常に少量の古い情報を使用しながら、同様のレベルの精度と最小限の干渉で新しい情報を迅速に学習できます。これは、高いデータ利用率と迅速な学習を意味します。
同時に、SWIL はシーケンス学習フレームワークにも適用できます。さらに、新しいカテゴリを学習すると、データの利用率が大幅に向上します。古い情報が以前に学習したカテゴリとの類似性がほとんどない場合、提示される古い情報の量ははるかに少なくなり、これが人間の学習の実際のケースである可能性があります。
最後に、著者らは、新しい情報の重なりに比例する興奮性バイアスを伴う SWIL が脳内でどのように実装されるかについての理論モデルを提案します。
画像分類データセットに適用された DNN ダイナミクス モデル
McClelland らによる実験では、ネットワーク内に 1 つの隠れ層があり、深さでは線形であることが示されました。 , SWIL は、古いカテゴリ全体と新しいカテゴリをインターリーブする完全インターリーブ学習 (FIL) と同様に、新しいカテゴリを学習できますが、使用されるデータ量は 40% 削減されます。
ただし、ネットワークは上位概念カテゴリが 2 つだけある非常に単純なデータセットでトレーニングされたため、アルゴリズムのスケーラビリティについて疑問が生じます。
まず、より複雑なデータセット (Fashion-MNIST など) 用の 1 つの隠れ層を備えた深層線形ニューラル ネットワークで、さまざまなカテゴリの学習がどのように進化するかを調べます。 「ブーツ」と「バッグ」カテゴリを削除した後、モデルは残りの 8 つのカテゴリで 87% のテスト精度を達成しました。次に、作成者チームは、2 つの異なる条件下で (新しい) 「ブート」クラスを学習するようにモデルを再トレーニングし、それぞれ 10 回繰り返しました:
- 集中学習 (FoL)、つまり、新しい「ブート」クラスのみが学習されます。提示;
- 完全インターリーブ学習 (FIL)、つまり、すべてのクラス (以前に学習された新しいクラス) が等しい確率で提示されます。どちらの場合も、エポックごとに合計 180 枚の画像が表示され、各エポックでは同一の画像が表示されます。
ネットワークは、合計 9000 枚の未見の画像でテストされました。テスト データセットは、「バッグ」クラスを除く、クラスごとに 1000 枚の画像で構成されていました。ネットワークのパフォーマンスが漸近線に達すると、トレーニングは停止します。
予想通り、FoL は古いカテゴリへの干渉を引き起こしましたが、FIL はこれを克服しました (図 1、列 2)。上で述べたように、FoL による古いデータへの干渉はカテゴリによって異なります。これは SWIL の元のインスピレーションの一部であり、新しい「ブート」カテゴリと古いカテゴリの間の階層的な類似関係を示唆しています。たとえば、「スニーカー」(「スニーカー」)と「サンダル」(「サンダル」)の想起率は、「ズボン」(「パンツ」)の想起率よりも速く減少しています(図 1、列 2)。これはおそらく、 new 「ブーツ」クラスは、「スニーカー」クラスと「サンダル」クラスを表すシナプス ウェイトを選択的に変更し、より多くの干渉を引き起こします。
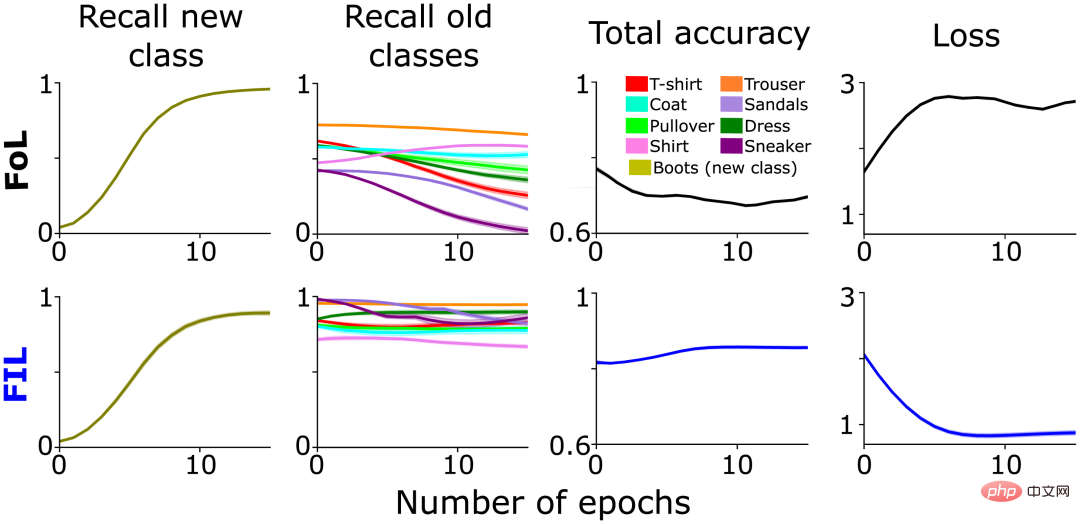
図 1: 2 つの新しい「ブート」クラスを学習する際の事前トレーニング済みネットワークのパフォーマンスの比較分析状況: FoL (上) と FIL (下)。左から右へ、新しい「ブート」クラスを予測するための再現率(オリーブ色)、既存のクラスの再現率(異なる色でプロット)、全体的な精度(高スコアは誤差が低いことを意味します)、およびクロスエントロピー損失(全体的な誤差の尺度)曲線は、保持されたテスト データ セットのエポック数の関数です。
異なるカテゴリ間の類似性を計算する
FoL が新しいカテゴリを学習すると、類似した古いカテゴリの分類パフォーマンスが大幅に低下します。
マルチカテゴリ属性の類似性と学習との関係は以前に調査されており、深層線形ネットワークは既知の一貫した属性を迅速に取得できることが示されています。対照的に、一貫性のない属性の新しいブランチを既存のカテゴリ階層に追加するには、時間をかけて徐々に段階的に学習する必要があります。
現在の研究では、著者チームは提案された方法を使用して特徴レベルでの類似性を計算します。簡単に言うと、ターゲットの隠れ層 (通常は最後から 2 番目の層) 内の既存のクラスと新しいクラスのクラスごとの平均アクティベーション ベクトル間のコサイン類似度が計算されます。図 2A は、ファッション MNIST データセットに基づいて新しい「ブート」カテゴリと古いカテゴリの事前トレーニング済みネットワークの最後から 2 番目の層活性化関数に基づいて著者チームによって計算された類似度行列を示しています。
カテゴリ間の類似性は、オブジェクトに対する私たちの視覚認識と一致しています。たとえば、階層クラスタリング図 (図 2B) では、「ブーツ」クラスと「スニーカー」および「サンダル」クラスの間の関係、および「シャツ」(「シャツ」) と「シャツ」クラスの間の関係を観察できます。 「-shirt」(「T シャツ」)はカテゴリ間の類似性が高くなります。類似度行列 (図 2A) は、混同行列 (図 2C) に正確に対応します。類似性が高いほど混同しやすくなります。たとえば、カテゴリ「シャツ」はカテゴリ「T シャツ」、「ジャンパー」、「ジャケット」と混同されやすくなります。これは、類似性の尺度が学習ダイナミクスを予測していることを示しています。ニューラルネットワークの。
前のセクションの FoL 結果グラフ (図 1) では、古いカテゴリの再現曲線に類似クラス類似度曲線があります。さまざまな古いカテゴリ (「ズボン」など) と比較すると、FoL は新しい「ブーツ」カテゴリを学習すると、同様の古いカテゴリ (「スニーカー」や「サンダル」) をすぐに忘れてしまいます。
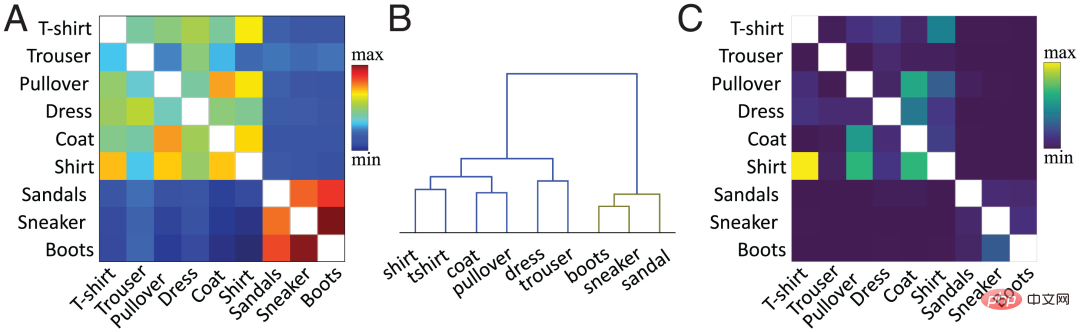
図 2: (A) 著者のチームは、プレ層の最後から 2 番目の層活性化関数に基づいて現在の値を計算しました。 -訓練されたネットワーク クラスと新しい「ブート」クラスを含む類似性マトリックスでは、対角値 (同じクラスの類似性は白でプロットされます) が削除されます。 (B) A の類似度行列の階層的クラスタリング。 (C) 「ブート」クラスを学習するトレーニング後に FIL アルゴリズムによって生成された混同行列。スケーリングを明確にするために、対角線の値が削除されました。
ディープリニアニューラルネットワークは、新しいことの高速かつ効率的な学習を実現します
次に、最初の 2 つの条件に基づいて、3 つの新しい条件が追加されます。 、新しい分類学習ダイナミクスが研究され、各条件が 10 回繰り返されました:
- FoL (合計 n=6000 画像/エポック);
- FIL (合計 n=54000 画像/エポック、6000 画像/クラス);
- 部分的にインターリーブされた学習 (部分的)インターリーブ学習、PIL) は、画像の小さなサブセット (合計 n=350 画像/エポック、約 39 画像/クラス) を使用し、各カテゴリ (新しいカテゴリ、既存のカテゴリ) の画像に等しい確率が割り当てられます。 レンダリング;
- SWIL、PIL と同じ合計イメージ数を使用して各エポックを再トレーニングしますが、(新しい) 「ブート」クラスとの類似性に基づいて既存のクラス イメージに重み付けを行います。
- Equally Weighted Interleaved Learning (EqWIL)、 SWIL と同じ数の「ブート」クラス イメージを使用して再学習しますが、既存のクラス イメージの重みは同じです (図 3A)。
著者チームは、上記と同じテスト データ セットを使用しました (合計 n=9000 画像)。ニューラル ネットワークのパフォーマンスが各条件で漸近線に達すると、トレーニングが停止されます。エポックごとに使用されるトレーニング データは少なくなりますが、新しい「ブート」クラスの予測精度は漸近線に達するまでに時間がかかり、PIL は FIL と比較して再現率が低くなります (H=7.27、P
SWIL の場合、類似度計算を使用して、インターリーブされる既存の古いカテゴリ画像の割合を決定します。これに基づいて、作成者チームは、各古いカテゴリから重み付けされた確率で入力画像をランダムに描画します。他のカテゴリと比較して、「スニーカー」カテゴリと「サンダル」カテゴリは最も類似しており、その結果、インターリーブされる割合が高くなります (図 3A)。
樹状図 (図 2B) によると、作成者チームは「スニーカー」クラスと「サンダル」クラスを類似の古いクラスとして参照し、残りを異なる古いクラスとして参照しています。新しいクラスの再現率 (図 3B の列 1 および表 1 の「新しいクラス」列)、合計精度および PIL の損失 (H=5.44、P0.05) は FIL と同等です。 EqWIL での新しい「ブート」クラスの学習 (H=10.99、P
著者チームは、SWIL と FIL を比較するために次の 2 つの方法を使用します。
- メモリ比率、つまり、保存されている画像の数の比率FIL と SWIL では、ストレージを表します データ量が削減されます;
- 新しいカテゴリの呼び出しの飽和精度を達成するための、FIL と SWIL で表示されるコンテンツの総数の比率である高速化率は、次のことを示します新しいカテゴリを学習するのに必要な時間が短縮されるということです。
SWIL は、少ないデータ要件で新しいコンテンツを学習できます。メモリ比 = 154.3x (54000/350)、さらに高速です。加速比 = 77.1x ( 54000/(350) ×2))。新しいコンテンツに関連する画像の数が少ない場合でも、モデルの事前知識の階層構造を活用する SWIL を使用することで、モデルは同じパフォーマンスを達成できます。 SWIL は PIL と EqWIL の間に中間バッファを提供し、既存のカテゴリへの影響を最小限に抑えながら新しいカテゴリを統合できるようにします。
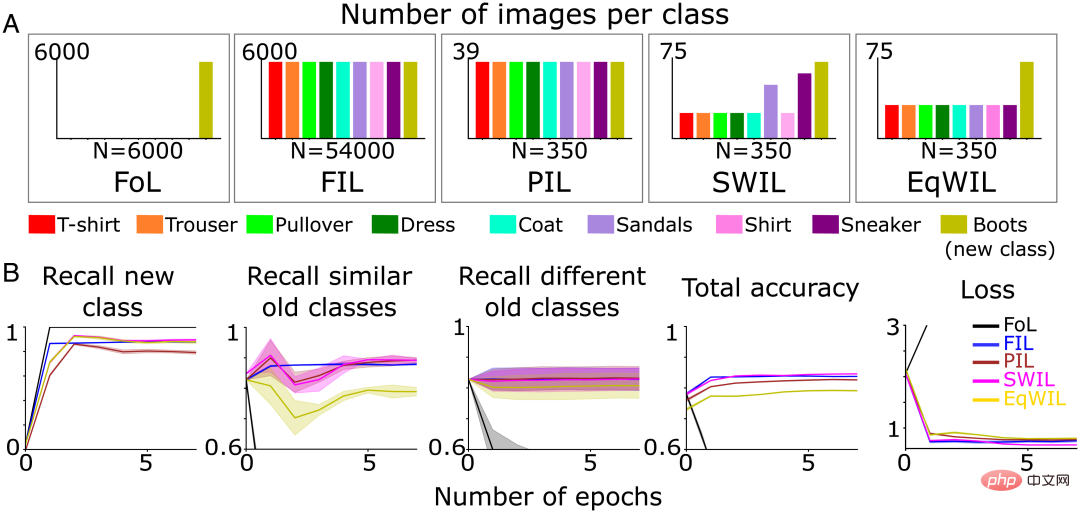
図 3 (A) 著者チームは、新しい「ブート」カテゴリを学習するためにニューラル ネットワークを事前トレーニングしました (オリーブ)緑) パフォーマンスが安定するまで: 1) FoL (合計 n=6000 画像/エポック); 2) FIL (合計 n=54000 画像/エポック); 3) PIL (合計 n=350 画像/エポック); 4 ) SWIL (合計 n=350 画像/エポック) および 5) EqWIL (合計 n=350 画像/エポック)。 (B) FoL (黒)、FIL (青)、PIL (茶色)、SWIL (マゼンタ)、および EqWIL (金) は、新しいカテゴリ、類似の古いカテゴリ (「スニーカー」と「サンダル」)、および異なる古いカテゴリを予測します。再現率、すべてのカテゴリを予測する合計精度と、テスト データ セットのクロス エントロピー損失。横軸はエポック数です。
CIFAR10 に基づく SWIL を使用した CNN の新しいカテゴリの学習
次に、SWIL がより複雑な環境で機能するかどうかをテストするために、著者チームは、CIFAR10 データセット内の残りの 8 つの異なるカテゴリ (「猫」と「車」を除く) の画像を認識するために、完全に接続された出力層を備えた 6 層の非線形 CNN (図 4A) をトレーニングしました。また、以前に定義された 5 つの異なるトレーニング条件 (FoL、FIL、PIL、SWIL、および EqWIL) の下で「cat」クラスを学習するようにモデルを再トレーニングしました。図 4C は、5 つの条件における各カテゴリの画像の分布を示しています。 SWIL、PIL、および EqWIL 条件ではエポックあたりの画像の総数は 2400 でしたが、FIL と FoL ではエポックあたりの画像の総数はそれぞれ 45000 と 5000 でした。著者のチームは、パフォーマンスが安定するまで、状況ごとにネットワークを個別にトレーニングしました。
彼らは、これまでに見たことのない合計 9,000 個の画像 (「車」クラスを除く、クラスあたり 1,000 個の画像) でモデルをテストしました。図 4B は、CIFAR10 データセットに基づいて著者のチームによって計算された類似性行列です。 「猫」クラスは「犬」クラスにより似ていますが、他の動物クラスは同じブランチに属します (図 4B 左)。
樹形図 (図 4B) によると、「トラック」(「トラック」)、「船」(「船」)、および「飛行機」(「航空機」) というカテゴリは、「」を除き、異なる古いカテゴリと呼ばれています。猫" "カテゴリの外にある動物の残りのカテゴリは、同様の古いカテゴリと呼ばれます。 FoL の場合、モデルは新しい「cat」クラスを学習しますが、古いクラスは忘れます。 Fashion-MNIST データセットの結果と同様に、「犬」クラス (「猫」クラスに最も似ている) と「トラック」クラス (「猫」クラスに最も似ていない) の両方に干渉勾配があります。 )、このうち「犬」の忘れ物率が最も高く、「トラック」の忘れ物率が最も低いです。
図 4D に示すように、FIL アルゴリズムは、新しい「cat」クラスを学習する際に壊滅的な干渉を克服します。 PIL アルゴリズムの場合、モデルは新しい「cat」クラスを学習するために各エポックで 18.75 倍のデータ量を使用しますが、「cat」クラスの再現率は FIL の再現率よりも高くなります (H=5.72、P##) #0.05; 表 2 および図 4D を参照)。 SWIL は、PIL よりも新しい「猫」クラスの再現率が高くなります (H=7.89、P
FIL、PIL、SWIL、および EqWIL は、さまざまな古いカテゴリの予測において同等のパフォーマンスを示します (H=0.6、P>0.05)。 SWI には、PIL よりも優れた新しい「cat」クラスが組み込まれており、EqWIL での観測干渉を克服するのに役立ちます。 FIL と比較すると、SWIL を使用した新しいカテゴリの学習は高速であり、加速比 = 31.25x (45000×10/(2400×6)) であり、使用するデータ量は少なくなります (メモリ比 = 18.75 倍)。これらの結果は、SWIL が非線形 CNN やより現実的なデータセット上でも新しいカテゴリの物事を効果的に学習できることを示しています。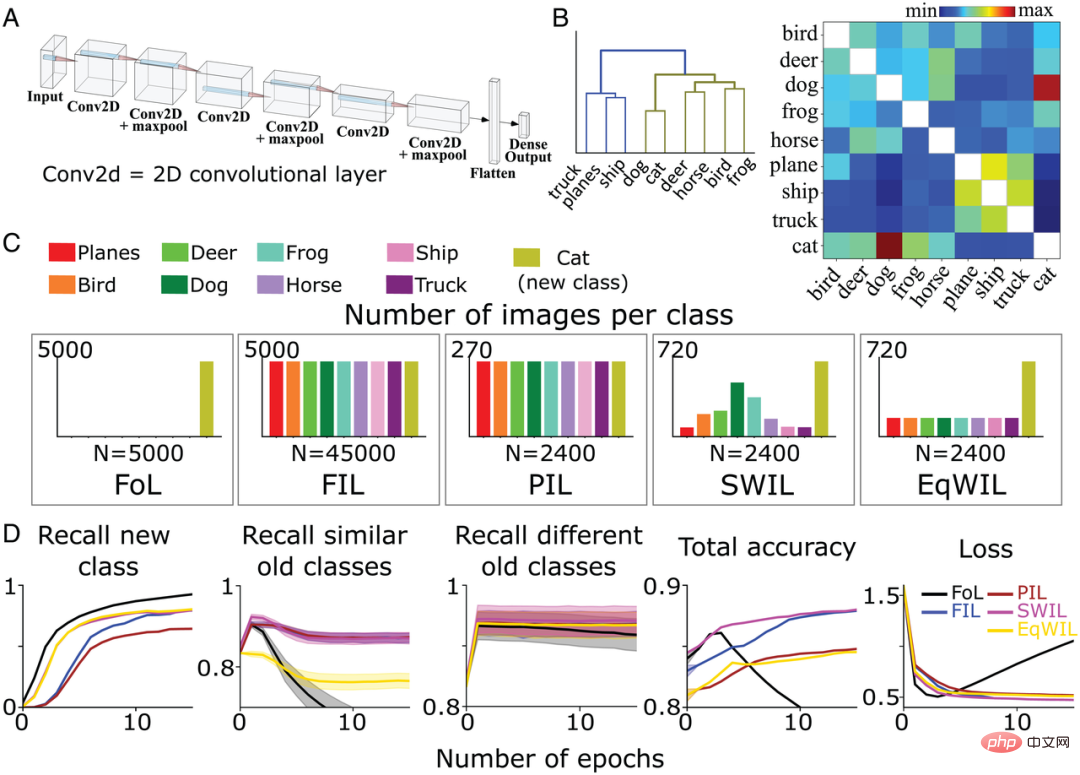
図 4: (A) 著者チームは、完全に接続された出力層を持つ 6 層の非線形 CNN を使用して、 CIFAR10 データを学ぶ 8 つのカテゴリーに焦点を当てます。 (B) 類似度行列 (右) は、新しい「cat」クラスを提示した後の最後の畳み込み層の活性化関数に基づいて著者チームによって計算されます。類似性行列 (左) に階層的クラスタリングを適用すると、樹状図内の 2 つの上位カテゴリ動物 (オリーブ グリーン) と車両 (青) のグループ化が表示されます。 (C) 著者チームは、パフォーマンスが安定するまで 5 つの異なる条件下で新しい「猫」クラス (オリーブ グリーン) を学習するように CNN を事前トレーニングしました: 1) FoL (合計 n=5000 画像/エポック); 2) FIL (合計 n =45000 画像/エポック)、3) PIL (合計 n=2400 画像/エポック)、4) SWIL (合計 n=2400 画像/エポック)、5) EqWIL (合計 n=2400 画像/エポック)。各条件を 10 回繰り返しました。 (D) FoL (黒)、FIL (青)、PIL (茶色)、SWIL (マゼンタ)、および EqWIL (金) は、新しいクラス、同様の古いクラス (CIFAR10 データセット内の他の動物クラス)、および異なる古いクラスを予測します ( "平面「」、「船」、「トラック」)、すべてのカテゴリの合計予測精度、およびテスト データ セットのクロス エントロピー損失。横軸はエポック数です。
新しいコンテンツと古いカテゴリの一貫性が学習時間と必要なデータに与える影響 新しいコンテンツを前 ネットワークに大きな変更を必要とせずに学習されたカテゴリでは、この 2 つは一貫していると言われます。このフレームワークに基づいて、既存のカテゴリの数が少ない(一貫性が高い)新しいカテゴリを学習する方が、複数の既存のカテゴリに干渉する(一貫性が低い)新しいカテゴリを学習するよりも簡単にネットワークに統合できます。 上記の推論をテストするために、著者チームは、前のセクションで事前トレーニングされた CNN を使用して、前述の 5 つの学習条件すべての下で新しい「自動車」カテゴリを学習しました。図 5A は「自動車」カテゴリの類似度マトリクスを示しており、既存の他のカテゴリである「自動車」と「トラック」、「船舶」と「飛行機」が同一階層ノードに属しており、より類似していることがわかります。さらに確認するために、著者チームは類似性計算に使用される活性化層に対して t-SNE 次元削減可視化解析を実行しました (図 5B)。この研究では、「車」クラスは他の乗り物クラス(「トラック」、「船」、「飛行機」)と大きく重複し、「猫」クラスは他の動物クラス(「犬」、「カエル」、 「馬」(「馬」)、「鳥」(「鳥」)、「鹿」(「鹿」))が重なっています。 著者のチームの予想に沿って、FoL は「車」カテゴリを学習するときに壊滅的な干渉を生成し、同様の古いカテゴリへの干渉がさらに大きくなります。これは、FIL を使用することで克服されます (図5D)。 PIL、SWIL、および EqWIL の場合、エポックごとに合計 n = 2000 の画像があります (図 5C)。 SWIL アルゴリズムを使用すると、モデルは、既存のカテゴリ (類似のカテゴリや異なるカテゴリを含む) への干渉を最小限に抑えながら、FIL と同様の精度 (H=0.79、P>0.05) で新しい「自動車」カテゴリを学習できます。図 5D の列 2 に示すように、EqWIL を使用すると、モデルは SWIL と同じ方法で新しい「自動車」クラスを学習しますが、他の同様のカテゴリ (例: 「トラック」) との干渉の程度が高くなります (H=53.81) 、P<0.05)。FIL と比較すると、SWIL は新しいコンテンツをより速く学習でき、加速比 = 48.75x (45000×12/(2000×6))、メモリ要件が削減され、メモリ比 = 22.5 倍になります。 「猫」(48.75 倍対 31.25 倍) と比較すると、「車」はインターリーブするクラス (「トラック」、「船」、「飛行機」など) が少ないため、より速く学習できますが、「猫」にはより多くのカテゴリ (「トラック」、「船」、「飛行機」など) があります。 「犬」、「蛙」、「馬」、「蛙」、「鹿」)が重なっています。これらのシミュレーション実験は、新しいカテゴリのクロスオーバーおよび加速学習に必要な古いカテゴリのデータの量が、新しい情報と事前の知識の一貫性に依存することを示しています。
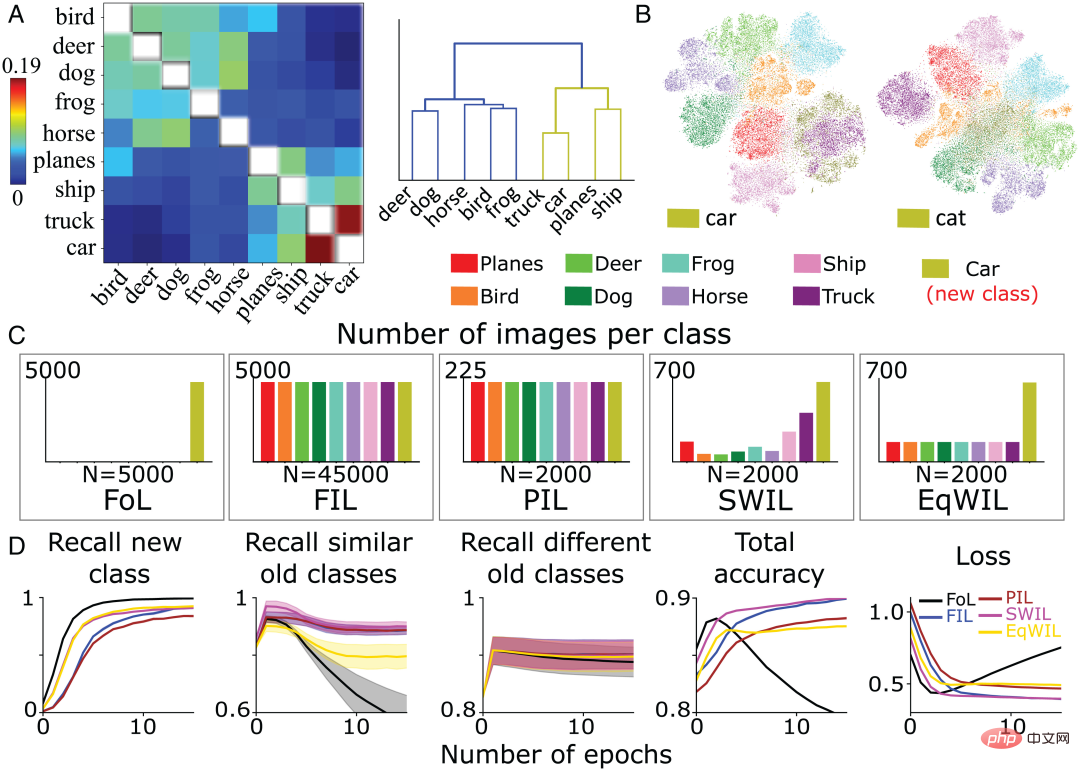
図 5: (A) 著者チームは、最後から 2 番目の層活性化関数に基づいて類似度行列を計算しました (左) 、および新しい「自動車」カテゴリを提示した後の類似度行列の階層的クラスタリングの結果 (右)。 (B) モデルは新しい「車」カテゴリと「猫」カテゴリをそれぞれ学習し、最後の畳み込み層が活性化関数を通過した後、著者チームは t-SNE 次元削減の可視化結果を実行します。 (C) 著者チームは、パフォーマンスが安定するまで 5 つの異なる条件下で新しい「車」クラス (オリーブ グリーン) を学習するように CNN を事前トレーニングしました: 1) FoL (合計 n=5000 画像/エポック); 2) FIL (合計 n =45000 画像/エポック)、3) PIL (合計 n=2000 画像/エポック)、4) SWIL (合計 n=2000 画像/エポック)、5) EqWIL (合計 n=2000 画像/エポック)。 (D) FoL (黒)、FIL (青)、PIL (茶)、SWIL (マゼンタ)、EqWIL (金) は、新しいカテゴリ、同様の古いカテゴリ (「飛行機」、「船」、「トラック」) とリコールを予測します。さまざまな古いカテゴリ (CIFAR10 データセット内の他の動物カテゴリ) の割合、すべてのカテゴリの合計予測精度、テスト データセットのクロス エントロピー損失。横軸はエポック数です。各グラフは 10 回の反復の平均を示し、影付きの領域は ±1 SEM です。
SWIL をシーケンス学習に使用する
次に、著者チームは、SWIL を使用してシリアル化された形式で提示された新しいコンテンツを学習できるかどうかをテストしました (シーケンス学習フレーム)。この目的を達成するために、彼らは、図 4 のトレーニング済み CNN モデルを採用して、FIL および SWIL 条件下で CIFAR10 データセットの「猫」クラス (タスク 1) を学習し、CIFAR10 の残りの 9 つのカテゴリについてのみトレーニングし、その後、各条件でトレーニングしました。次に、新しい「car」クラスを学習するためにモデルをトレーニングします (タスク 2)。図 6 の最初の列は、SWIL 条件下で「自動車」カテゴリを学習した場合の他のカテゴリの画像数の分布を示しています (合計 n=2500 画像/エポック)。 「cat」クラスを予測すると、新しい「car」クラスも相互学習されることに注意してください。モデルのパフォーマンスは FIL 条件下で最高であるため、SWIL は結果を FIL とのみ比較しました。
図 6 に示すように、新しいカテゴリと古いカテゴリを予測する SWIL の能力は FIL と同等です (H=14.3、P>0.05)。このモデルは SWIL アルゴリズムを使用して、新しい「自動車」カテゴリをより高速に学習し、45 倍の加速比 (50000×20/(2500×8)) を実現し、各エポックのメモリ フットプリントは FIL の 20 分の 1 です。モデルが「猫」と「車」のカテゴリを学習すると、SWIL 条件でエポックごとに使用される画像の数 (メモリ比と高速化比はそれぞれ 18.75 倍と 20 倍) は、FIL でエポックごとに使用されるデータ全体よりも少なくなります。条件セット (メモリ率とスピードアップ率はそれぞれ 31.25 倍と 45 倍) でありながら、新しいカテゴリを迅速に学習します。このアイデアを拡張すると、学習されたカテゴリの数が増加し続けるにつれて、モデルの学習時間とデータ ストレージが指数関数的に削減され、新しいカテゴリをより効率的に学習できるようになり、おそらく人間の脳が実際に学習するときに何が起こるかを反映していると、著者チームは期待しています。
実験結果は、SWIL がシーケンス学習フレームワークに複数の新しいクラスを統合できるため、ニューラル ネットワークが干渉することなく学習を継続できることを示しています。
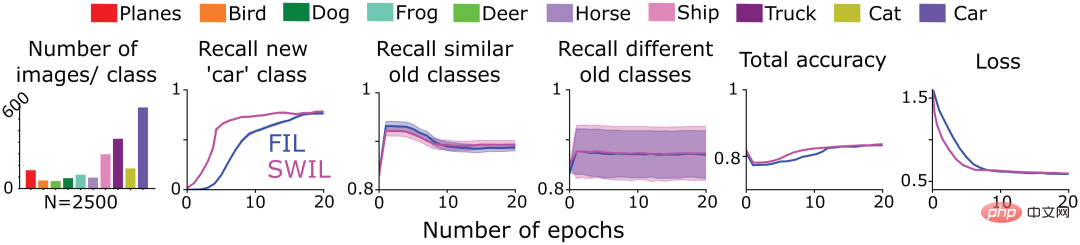
図 6: 著者チームは、新しい「cat」クラスを学習するために 6 層 CNN をトレーニングしました (タスク 1) )、次の 2 つのケースでパフォーマンスが安定するまで「car」クラス (タスク 2) を学習しました。 1) FIL: すべての古いクラス (異なる色で描画) と同じ確率で表示される新しいクラス (「cat」/」が含まれます) car ") image; 2) SWIL: 新しいカテゴリ (「猫」/「車」) との類似性によって重み付けされ、古いカテゴリの例を比例して使用します。タスク 1 で学習した「猫」クラスも含め、タスク 2 で学習した「車」クラスの類似性に基づいて重み付けします。最初の部分図は各エポックで使用された画像の数の分布を示し、残りの部分図はそれぞれ、新しいカテゴリ、類似の古いカテゴリ、および異なる古いカテゴリの予測における FIL (青) と SWIL (マゼンタ) の再現率を示します。すべてのカテゴリの再現率、全体の精度、およびテスト データ セットのクロス エントロピー損失 (横軸はエポック数)。
SWIL を使用してカテゴリ間の距離を広げ、学習時間とデータ量を削減します
著者チームは最終的に SWIL アルゴリズムの一般化をテストしましたより多くのカテゴリを含むデータ セットを学習できるかどうか、およびより複雑なネットワーク アーキテクチャに適しているかどうかを検証します。
彼らは、CIFAR100 データセット (トレーニング セット 500 画像/カテゴリ、テスト セット 100 画像/カテゴリ) で複雑な CNN モデル VGG19 (合計 19 層) をトレーニングし、90 のカテゴリを学習しました。その後、ネットワークは新しいカテゴリを学習するために再トレーニングされます。図 7A は、CIFAR100 データセットに基づく最後から 2 番目の層の活性化関数に基づいて著者のチームによって計算された類似度行列を示しています。図 7B に示すように、新しい「電車」クラスは、「バス」(「バス」)、「路面電車」(「トラム」)、「トラクター」(「トラクター」) などの多くの既存の交通機関クラスと互換性があります。 )は非常によく似ています。
FIL と比較して、SWIL は新しいことをより速く学習でき (スピードアップ = 95.45 倍 (45500×6/(1430×2)))、使用するデータが少なくなります (メモリ比率 = 31.8 倍)。パフォーマンスは基本的に同じでしたが、大幅に減少しました (H=8.21、P>0.05)。図 7C に示すように、PIL (H=10.34、P
同時に、異なるカテゴリの表現間の大きな距離がモデル学習を加速するための基本条件を構成するかどうかを調査するために、著者チームは 2 つの追加のニューラル ネットワーク モデルをトレーニングしました。
- 6 層 CNN (CIFAR10 に基づく図 4 および図 5 と同じ);
- VGG11 (11 層) は、FIL と 2 つの条件下でのみ、CIFAR100 データセット内の 90 カテゴリを学習します。 SWIL 新しい「train」クラスをトレーニングします。
図 7B に示すように、上記の 2 つのネットワーク モデルでは、新しい「電車」クラスと交通機関クラスの間の重複が高くなりますが、VGG19 モデルでは比較すると、各カテゴリの分離度は低くなります。 FIL と比較すると、SWIL が新しいことを学習する速度は、層数の増加にほぼ直線的です (傾き = 0.84)。この結果は、カテゴリ間の表現距離を増やすと学習が加速され、記憶負荷が軽減されることを示しています。
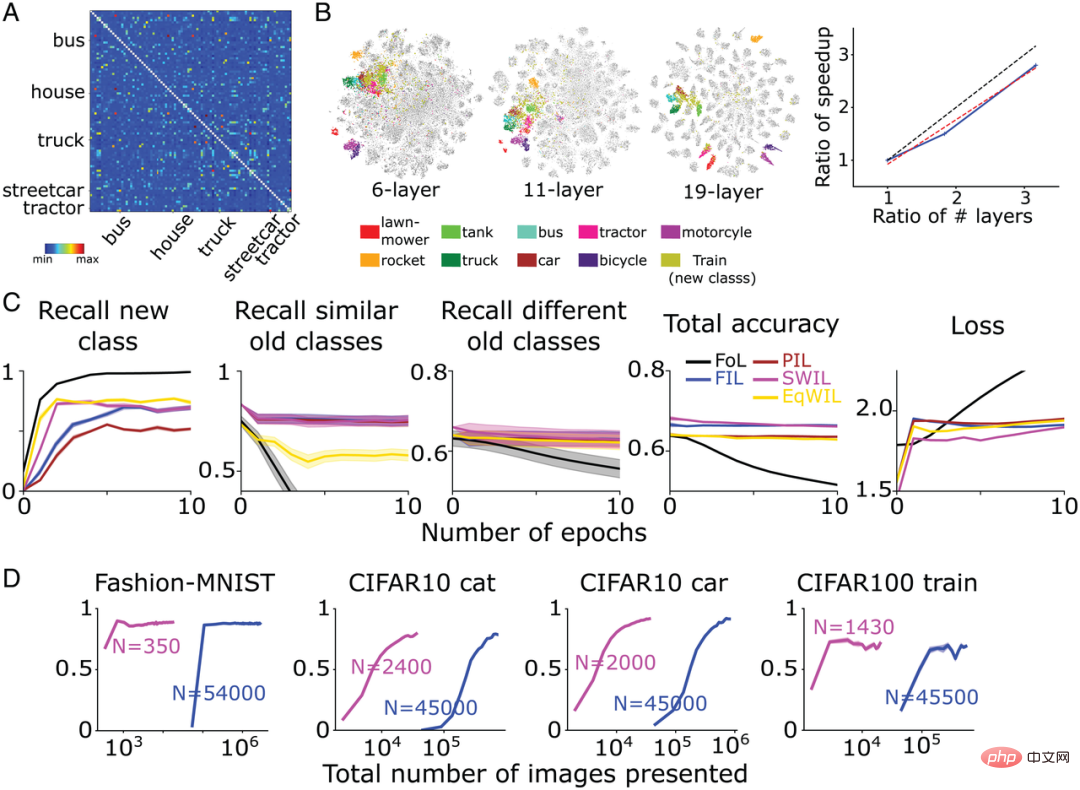
図 7: (A) VGG19 が新しい「train」クラスを学習した後、作成者チームは最後から 2 番目のクラスに基づいてレイヤー 活性化関数によって計算された類似度行列。 「電車」に最も似ているのは、「トラック」、「路面電車」、「バス」、「住宅」、「トラクター」の 5 つのカテゴリです。類似度行列から対角要素を除外します (similarity=1)。 (B、左) 活性化関数の最後から 2 番目の層を通過した後の、6 層 CNN、VGG11、および VGG19 ネットワークに対する著者チームの t-SNE 次元削減視覚化結果。 (B、右) 縦軸は高速化率 (FIL/SWIL) を表し、横軸は 6 層 CNN に対する 3 つの異なるネットワークの層数の比を表します。黒の点線、赤の点線、青の実線は、それぞれ傾き = 1 の標準線、最良の適合線、シミュレーション結果を表します。 (C) VGG19 モデルの学習状況: FoL (黒)、FIL (青)、PIL (茶色)、SWIL (マゼンタ)、EqWIL (金) は、新しい「電車」クラス、同様の古いクラス (交通クラス) とリコールを予測します。さまざまな古いカテゴリ (輸送カテゴリを除く) の割合、すべてのカテゴリの合計予測精度、およびテスト データ セットのクロス エントロピー損失。横軸はエポック番号です。各グラフは 10 回の反復の平均を示し、影付きの領域は ±1 SEM です。 (D) モデルは左から右に、Fashion-MNIST「ブーツ」クラス (図 3)、CIFAR10 「猫」クラス (図 4)、CIFAR10 「車」クラス (図 5)、およびCIFAR100「トレーニング」クラス SWIL (マゼンタ) と FIL (青) で使用される画像の総数 (対数スケール) の関数としてのレート。 「N」は、各学習条件における各エポックで使用された画像の総数を表します(新旧カテゴリーを含む)。
ネットワークがより多くの非重複クラスでトレーニングされ、表現間の距離がより大きい場合、速度はさらに向上しますか?
この目的を達成するために、著者チームは深層線形ネットワーク (図 1-3 の Fashion-MNIST の例に使用) を採用し、8 ファッション - を組み合わせたデータセットを学習するようにトレーニングしました。 MNIST カテゴリ (「バッグ」および「ブーツ」カテゴリを除く) と 10 Digit-MNIST カテゴリを学習し、新しい「ブーツ」カテゴリを学習するようにネットワークをトレーニングします。
著者チームの予想どおり、「ブーツ」は古いカテゴリの「サンダル」や「スニーカー」に似ており、残りのファッション MNIST カテゴリがそれに続きます。 (主に衣類カテゴリの画像を含む)、最後に Digit-MNIST クラス (主にデジタル画像を含む)。
これに基づいて、作成者チームはまず、より類似した古いカテゴリのサンプルをインターリーブし、次に Fashion-MNIST および Digit-MNIST カテゴリのサンプルをインターリーブしました (合計 n=350 画像/エポック) 。実験結果によると、FIL と同様に、SWIL は干渉なしに新しいカテゴリのコンテンツを迅速に学習できますが、使用するデータ サブセットははるかに小さく、メモリ比は 325.7 倍 (114000/350)、加速比は 162.85 倍 (228000/228000) です。 /350)、1400)。著者チームは、Fashion-MNIST データセットと比較して、現在の結果で 2.1 倍 (162.85/77.1) の高速化を観察し、カテゴリ数 (18/8) が 2.25 倍増加しました。
このセクションの実験結果は、SWIL がより複雑なデータセット (CIFAR100) およびニューラル ネットワーク モデル (VGG19) に適用できることを判断するのに役立ち、アルゴリズムの一般化を証明します。また、カテゴリ間の内部距離を広げるか、重複しないカテゴリの数を増やすと、学習速度がさらに向上し、メモリ負荷が軽減される可能性があることも実証しました。
#概要 人工ニューラル ネットワークは、継続学習において重大な課題に直面しており、壊滅的な干渉を引き起こすことがよくあります。この問題を克服するために、多くの研究では、新しいコンテンツと古いコンテンツを相互学習してネットワークを共同トレーニングする完全インターリーブ学習 (FIL) が使用されています。 FIL では、新しい情報を学習するたびに既存の情報をすべて織り交ぜる必要があるため、生物学的にありえない、時間のかかるプロセスとなります。最近、一部の研究では、FIL は必要ない可能性があり、新しいコンテンツと表現上の実質的な類似性がある古いコンテンツをインターリーブすること、つまり、類似性加重インターリーブ学習 (SWIL) 手法を使用することによってのみ、同じ学習効果を達成できることが示されています。ただし、SWIL のスケーラビリティについては懸念が表明されています。 このペーパーでは、SWIL アルゴリズムを拡張し、さまざまなデータセット (Fashion-MNIST、CIFAR10、および CIFAR100) とニューラル ネットワーク モデル (ディープ線形ネットワークと CNN) に基づいてテストします。すべての条件において、類似性加重インターリーブ学習 (SWIL) と等加重インターリーブ学習 (EqWIL) は、部分インターリーブ学習 (PIL) と比較して、新しいカテゴリの学習において優れたパフォーマンスを示しました。 SWIL と EqWIL は古いカテゴリと比較して新しいカテゴリの相対頻度を増加させるため、これは作成者チームの予想と一致しています。 この論文では、同様のコンテンツを慎重に選択して織り交ぜることにより、既存のカテゴリを均等にサブサンプリングする (つまり EqWIL 法) と比較して、同様の古いカテゴリによる壊滅的な干渉が軽減されることも示しています。 SWIL は、新規および既存のカテゴリの予測において FIL と同様に機能しますが、必要なトレーニング データを大幅に削減しながら、新しいコンテンツの学習を大幅に高速化します (図 7D)。 SWIL はシーケンス学習フレームワークで新しいカテゴリを学習でき、一般化機能をさらに実証します。 最後に、多くの古いカテゴリと類似点を共有する新しいカテゴリよりも、以前に学習したカテゴリとの重複が少ない (距離が長い) 場合、統合時間を短縮でき、データ効率が向上します。全体として、実験結果は、脳が非現実的なトレーニング時間を短縮することによって、元の CLST モデルの主要な弱点の 1 つを実際に克服しているという洞察を提供する可能性があります。以上が研究により、類似性に基づく重み付けインターリーブ学習が深層学習における「健忘」問題に効果的に対処できることが示されています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。