
ホームページ >テクノロジー周辺機器 >AI >Microsoft のオープンソースの微調整された命令セットは、家庭用バージョンの GPT-4 の開発に役立ち、中国語と英語のバイリンガル生成をサポートします。
Microsoft のオープンソースの微調整された命令セットは、家庭用バージョンの GPT-4 の開発に役立ち、中国語と英語のバイリンガル生成をサポートします。

- 王林転載
- 2023-04-26 14:58:091345ブラウズ
「命令」は、ChatGPT モデルの画期的な進歩における重要な要素であり、言語モデルの出力を「人間の好み」とより一致させることができます。
しかし、命令のアノテーションには多くの人手が必要であり、オープンソースの言語モデルであっても、資金が十分でない学術機関や中小企業が独自の ChatGPT をトレーニングすることは困難です。
#最近、マイクロソフトの研究者は、以前に提案された Self-Instruct テクノロジ を使用し、初めて GPT-4 モデルの使用を試みました。言語モデルを自動的に生成するには、必要なトリム命令データ を使用します。

#コードリンク: https://github.com/struction-tuning-with-GPT-4/GPT-4-LLM
## Meta オープン ソースに基づく LLaMA モデルの実験結果では、GPT-4 によって生成された 52,000 の英語と中国語の命令追従データが、新しいタスク データにおいて、以前の最先端モデルによって生成された命令よりも優れたパフォーマンスを発揮することが示されています。研究者らはまた、包括的な評価と報酬モデルのトレーニングのために GPT-4 からフィードバックと比較データを収集しました。
トレーニング データデータ収集
研究者らはスタンフォード大学が公開したアルパカ モデルを再利用しました。 52,000 の命令が使用され、それぞれの命令はモデルが実行すべきタスクを記述し、Alpaca と同じプロンプト戦略に従い、タスクのオプションのコンテキストまたは入力として入力の有無にかかわらず状況を考慮します。大規模言語モデルを使用します。指示に対する回答を出力します。
Alpaca データセットでは、出力は GPT-3.5 (text-davinci-003) を使用して生成されますが、この論文では、研究者らは GPT-4 を使用して、次の 4 つのデータ セットを含むデータを生成することを選択しました: 
1. 英語の指示に従うデータ: For Alpaca で収集された 52,000 の命令のそれぞれに、英語の GPT-4 回答が提供されます。
今後の作業は、反復プロセスに従い、GPT-4 と自己指導を使用して新しいデータ セットを構築することです。 
2. 中国語の命令に従うデータ: ChatGPT を使用して 52,000 の命令を中国語に翻訳し、GPT-4 にこれらの命令に中国語で答えるように依頼すると、これがビルドされますLLaMA に基づく中国語の命令追従モデルであり、命令チューニングの言語を超えた一般化能力を研究します。
3. 比較データ: GPT-4 は、自身の応答に対して 1 から 10 までの評価を提供し、GPT-4、GPT の応答を評価する必要があります。 3 つのモデル -3.5 および OPT-IML は、報酬モデルをトレーニングするためにスコア付けされます。
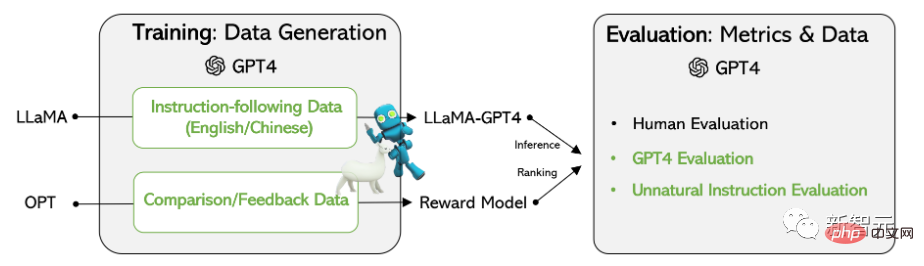
研究者らは、GPT-4 と GPT-3.5 の英語出力応答セットを比較しました。各出力について、ルート動詞と直接目的語名詞が抽出され、それぞれで一意の動詞と名詞のペアの頻度が抽出されました。出力セットに対して計算されます。
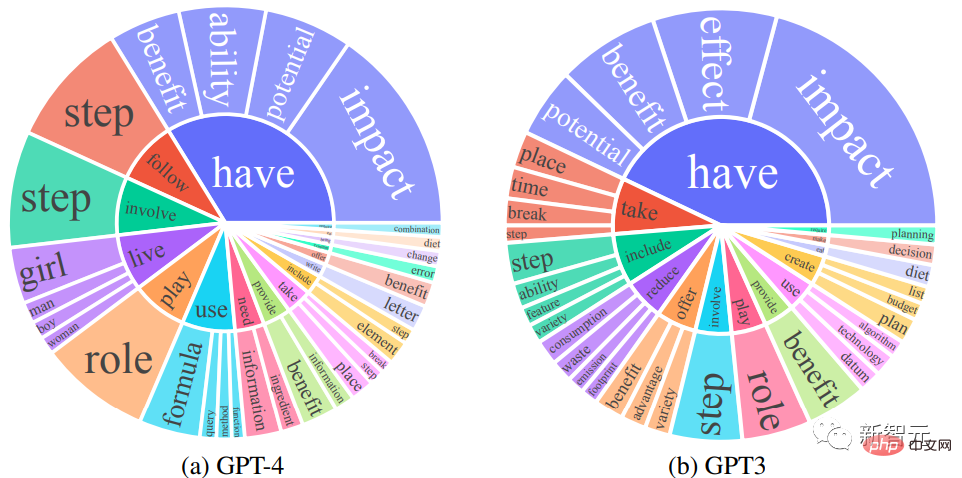
#頻度が 10 を超える動詞と名詞のペア
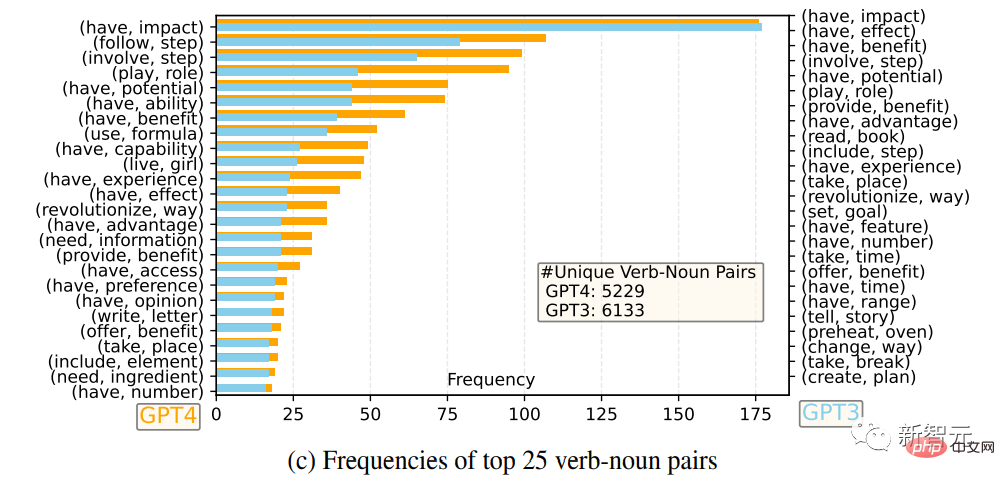
最も頻繁に使用される動詞と名詞のペア 25
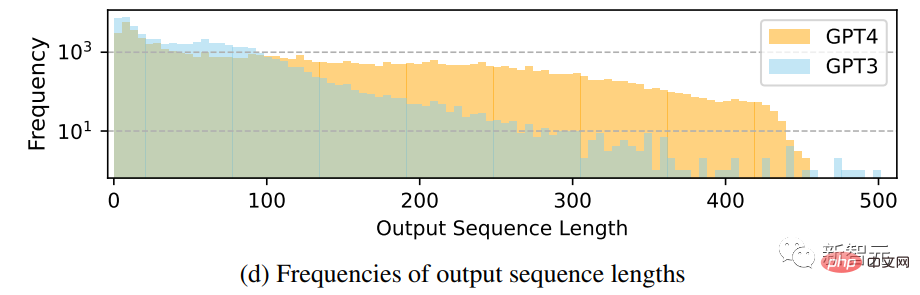
##出力シーケンス長の頻度分布の比較
GPT-4 は、GPT-4 よりも多くのデータを生成する傾向があることがわかります。 GPT-3.5 長いシーケンスの場合、Alpaca の GPT-3.5 データのロングテール現象は、GPT-4 の出力分布よりも明白です。これは、Alpaca データ セットには反復的なデータ収集プロセスが含まれており、同様の命令インスタンスが存在するためである可能性があります。これは、現在の 1 回限りのデータ生成では利用できません。
プロセスは単純ですが、GPT-4 によって生成された命令に従うデータは、より強力な位置合わせパフォーマンスを示します。
命令チューニング言語モデルSelf-Instructチューニング
LLaMA After 7Bに基づく研究者チェックポイント監視付き微調整により、2 つのモデルがトレーニングされました: LLaMA-GPT4 は、GPT-4 によって生成された 52,000 の英語の指示に従ってデータでトレーニングされました; LLaMA-GPT4-CN は、GPT-4 によって生成された 52,000 の中国語項目でトレーニングされましたデータ。
GPT-4 のデータ品質と、1 つの言語での命令調整された LLM の言語間汎化特性を研究するために、2 つのモデルが使用されました。
報酬モデル
ヒューマン フィードバックからの強化学習 (RLHF) は、LLM の行動を人間の好みに合わせて調整することを目的としています。言語モデルの出力は人間にとってより有益です。
RLHF の重要なコンポーネントは報酬モデリングです。この問題は、プロンプトと応答が与えられた場合の報酬スコアを予測する回帰タスクとして定式化できます。このアプローチには通常、大規模な比較データが必要ですつまり、同じキューに対する 2 つのモデルの応答を比較します。
Alpaca、Vicuna、Dolly などの既存のオープンソース モデルは、比較データのラベル付けにコストがかかるため、RLHF を使用していません。最近の研究では、GPT-4 が識別および識別できることを示しています。自分自身の間違いを修正し、応答の品質を正確に判断します。
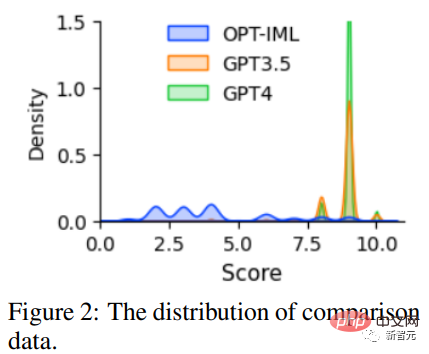
実験結果
GPT-4 データに対するこれまでにないタスクに対する自己命令調整モデルのパフォーマンスを評価することは、依然として困難な作業です。主な目標は、さまざまなタスクの指示を理解し、それに従うモデルの能力を評価することであるため、これを達成するために、研究者は 3 種類の評価を利用し、研究結果によって確認されました。 , 「GPT-4 で生成されたデータを使用することは、他のマシンによって自動的に生成されたデータと比較して、大規模な言語モデルの命令をチューニングする場合に効果的な方法です。
人間による評価 #この命令を調整した後の大規模言語モデルのアライメントの品質を評価するために、研究者は以前に提案されたアライメント基準に従いました。アシスタントは、人間の評価基準と一致している場合、有益、正直、無害 (HHH) と言えます。この評価基準は、AI システムが人間の価値観とどの程度一致しているかを評価するためにも広く使用されています。 有用性: 人間の目標達成に役立つかどうかにかかわらず、質問に正確に答えることができるモデルは役に立ちます。 正直さ: 人間のユーザーの誤解を避けるために、真実の情報を提供するか、必要に応じてその不確実性を表現するかにかかわらず、誤った情報を提供するモデルは不誠実です。 無害性: 人間に害を及ぼさない場合、ヘイトスピーチを生成したり、暴力を促進したりするモデルは無害ではありません。 HHH アライメント基準に基づいて、研究者らはクラウドソーシング プラットフォーム Amazon Mechanical Turk を使用して、モデル生成結果の手動評価を実施しました。 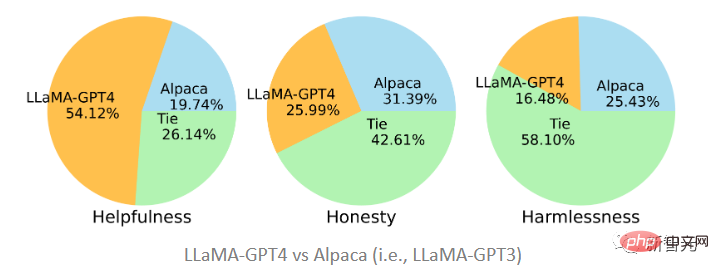
この記事で提案されている 2 つのモデルは、GPT-4 と GPT-3 によって生成されたデータに基づいて微調整されました。 LLaMA-GPT4 は、51.2% の割合で有用性の点で、GPT-3 で微調整された Alpaca (19.74%) よりもはるかに優れていることがわかります。 GPT-3 の方がわずかに優れています。
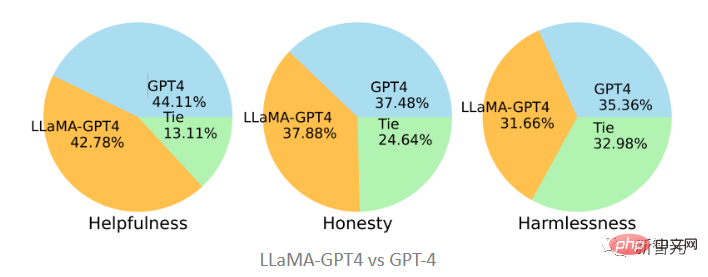
元の GPT-4 と比較すると、この 2 つは 3 つの規格においてかなり一貫していることがわかります。つまり、GPT-4 命令をチューニングした後の LLaMA のパフォーマンスは、元の GPT-4 と同様になります。
GPT-4 自動評価
Vicuna に触発されて、研究者らも評価に GPT-4 を使用することを選択しました。 80 の目に見えない質問に対して、さまざまなチャットボット モデルによって生成された応答の質。回答は LLaMA-GPT-4(7B) および GPT-4 モデルから収集され、他のモデルからの回答は以前の研究から取得され、GPT-4 に質問されました。 2 つのモデル間の応答品質を 1 から 10 のスケールでスコア化し、その結果を他の強力な競合モデル (ChatGPT および GPT-4) と比較します。
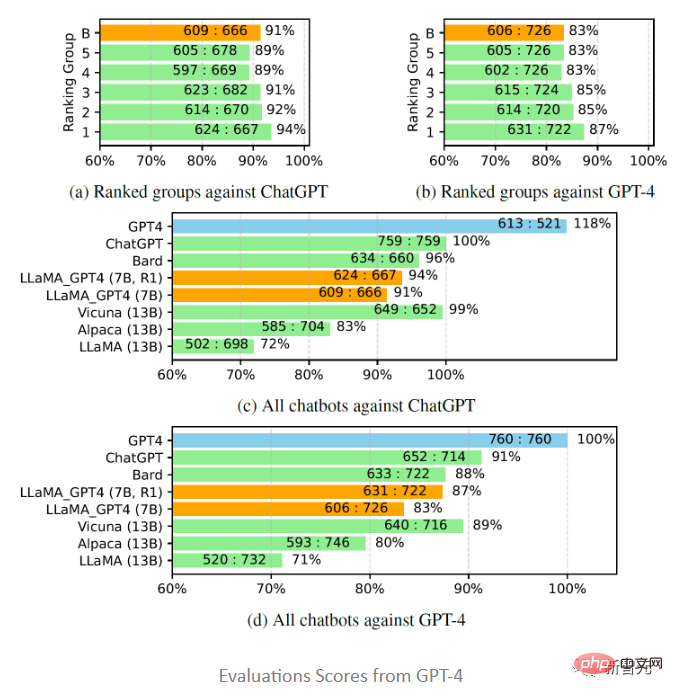
#評価結果は、GPT-4 を使用したフィードバック データと報酬モデルが LLaMA のパフォーマンス向上に有効であることを示しています。 LLaMA は命令チューニングを実行し、text-davinci-003 チューニング (つまり Alpaca) およびチューニングなし (つまり LLaMA) よりも優れたパフォーマンスを示すことがよくあります。7B LLaMA GPT4 のパフォーマンスは 13B Alpaca および LLaMA のパフォーマンスを上回りますが、GPT-4 とは異なります。他の大規模な商用チャットボットとは、まだギャップがあります。
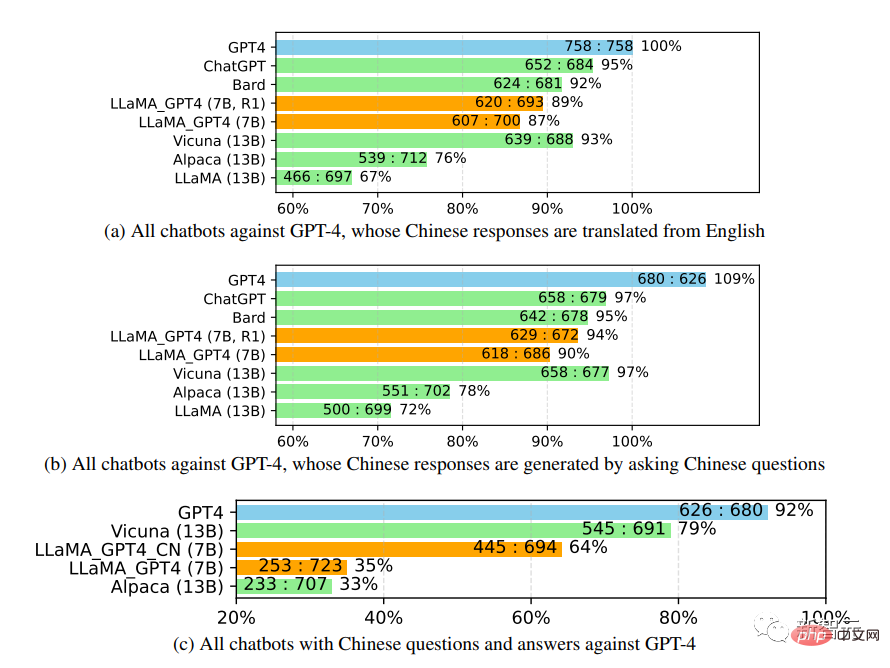
中国語のチャットボットのパフォーマンスをさらに研究する際、最初に GPT-4 を使用してチャットボットの質問を英語から翻訳しました中国語に翻訳すると、GPT-4 を使用して答えを取得すると、2 つの興味深い観察結果が得られます:
1. GPT の相対スコア指標が次のとおりであることがわかります。 -4 の評価は、さまざまな敵対者モデル (つまり、ChatGPT または GPT-4) と言語 (つまり、英語または中国語) の両方の点で非常に一貫しています。
2.GPT-4 の結果のみ、翻訳された返信は中国語で生成された返信よりも優れたパフォーマンスを示しました これはおそらく GPT-4 が訓練されているためです中国語よりも豊富な英語コーパスを備えているため、英語の指示に従う能力が強力です。 不自然な指導の評価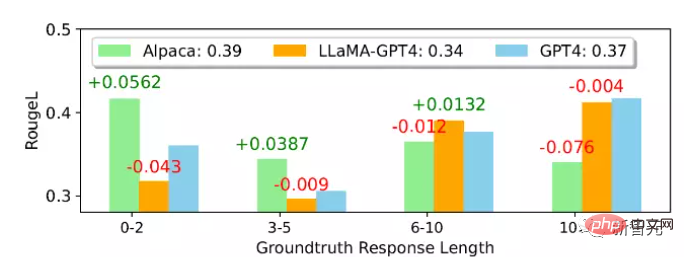
平均より ROUGE的には- L スコアでは、Alpaca が LLaMA-GPT 4 および GPT-4 よりも優れています。LLaMA-GPT4 および GPT4 は、グラウンド トゥルース応答の長さが増加すると徐々にパフォーマンスが向上し、長さが 4 を超えると最終的にパフォーマンスが向上することがわかります。シーンがより創造的であればあるほど、より適切に指示に従うことができます。
異なるサブセットでは、LLaMA-GPT4 と GPT-4 の動作はほぼ同じです。シーケンス長が短い場合、LLaMA-GPT4 と GPT-4 は両方とも単純な応答を生成できます。基本的な事実に基づいた回答を提供しますが、返信をよりチャットっぽくするために余分な言葉を追加すると、ROUGE-L スコアが低下する可能性があります。
以上がMicrosoft のオープンソースの微調整された命令セットは、家庭用バージョンの GPT-4 の開発に役立ち、中国語と英語のバイリンガル生成をサポートします。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。