
ホームページ >テクノロジー周辺機器 >AI >「安定拡散技術を利用した画像再現、関連研究がCVPRカンファレンスに採択されました」
「安定拡散技術を利用した画像再現、関連研究がCVPRカンファレンスに採択されました」

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-26 12:43:08840ブラウズ
人工知能があなたの想像力を読み取って、心の中のイメージを現実に変えることができたらどうなるでしょうか?

# これは少しサイバーパンクのように聞こえますが。しかし、最近発表された論文がAI界に波紋を引き起こした。
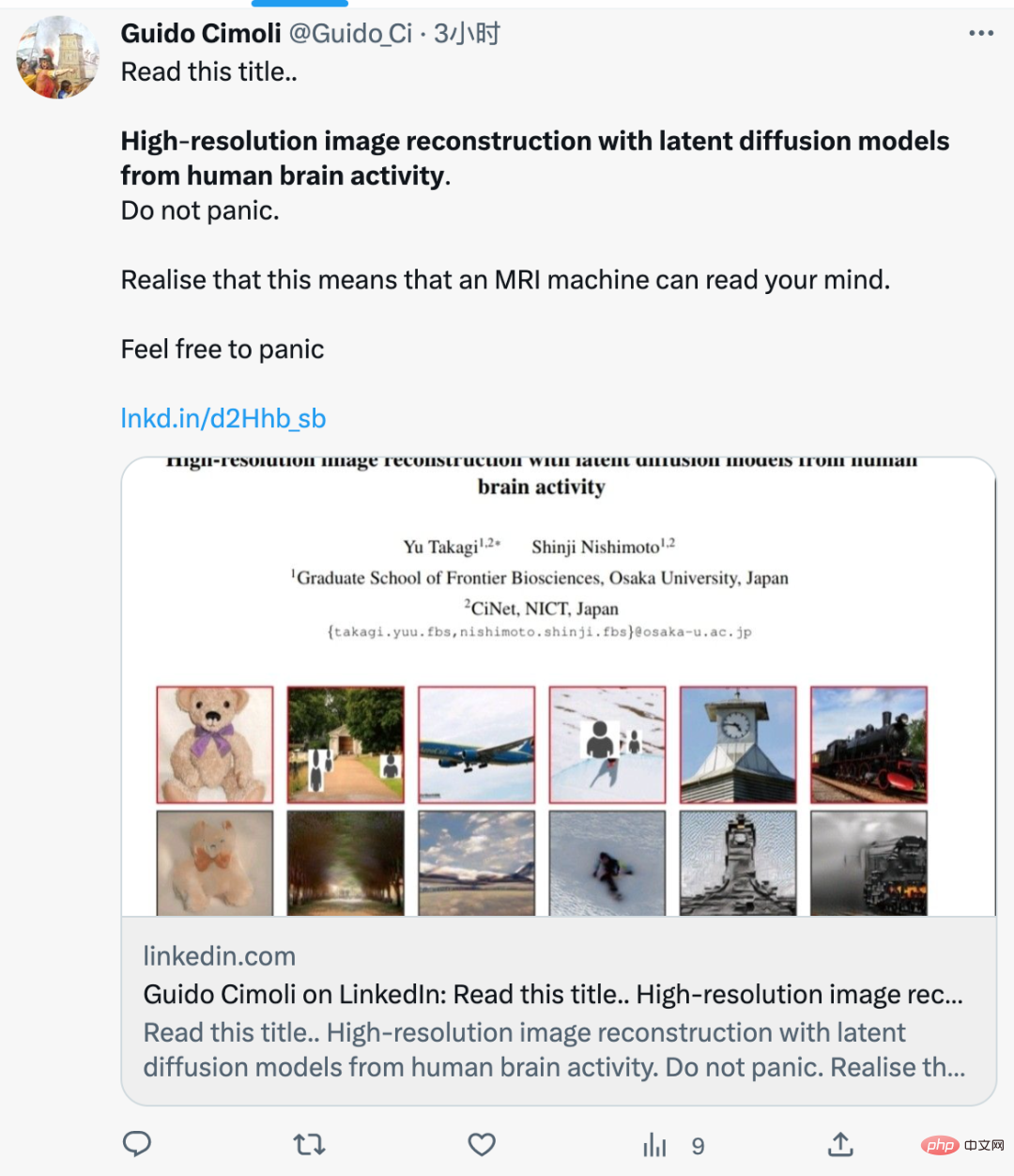
この論文では、最近非常に人気のある安定拡散を使用して、高解像度の脳活動を高効率で再構築していることがわかりました。高精度な画像。著者らは、これまでの研究とは異なり、これらの画像を作成するために人工知能モデルをトレーニングしたり微調整したりする必要はなかったと書いている。

- 紙のアドレス: https://www 。 biorxiv.org/content/10.1101/2022.11.18.517004v2.full.pdf
- ウェブページのアドレス: https://sites.google.com/view/stablediffusion -with-brain/
この研究では、著者らは安定拡散を使用して、機能的磁気共鳴画像法 (fMRI) によって取得された人間の脳活動の画像を再構成しました。著者はまた、脳関連機能のさまざまな要素(画像 Z の潜在ベクトルなど)を研究することによって、潜在拡散モデルのメカニズムを理解することも役立つと述べました。
この論文は CVPR 2023 にも採択されました。
この研究の主な貢献は次のとおりです:
- シンプルなフレームワークが脳活動から高い意味忠実度でデータを生成できることを実証する以下の図に示すように、特定のコンポーネントをさまざまな脳領域に対応するため、この研究では、神経科学の観点から LDM の各コンポーネントを定量的に説明します。
- この研究では、LDM によって実装されるテキストから画像への変換プロセスが、条件付きテキスト表現のセマンティックをどのように組み合わせるかについて客観的に説明します。元の画像の外観を維持しながら情報を保存します。
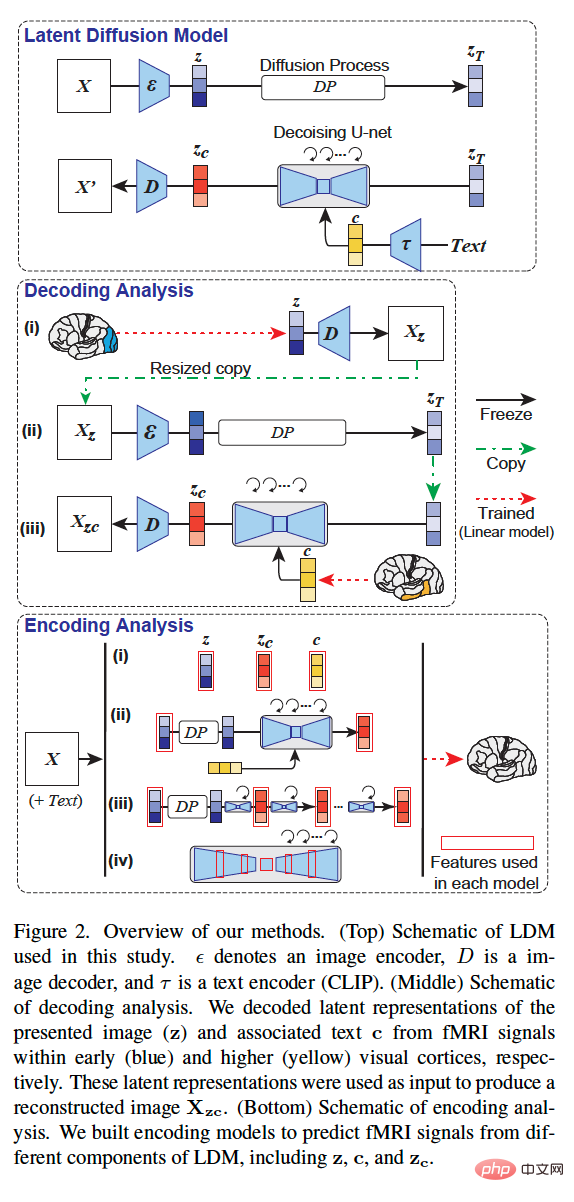
- 方法論の概要
- この研究の全体的な方法論を以下の図 2 に示します。図 2 (上) は、この研究で使用した LDM の概略図です。ε は画像エンコーダ、D は画像デコーダ、τ はテキスト エンコーダ (CLIP) を表します。
図 2 (下) は、この研究のコーディング分析の概略図です。 z、c、z_c などの LDM のさまざまなコンポーネントからの fMRI 信号を予測するためのエンコード モデルを構築しました。
#安定拡散については多くの人がよく知っていると思いますので、ここではあまり紹介しません。
 結果
結果
この研究の視覚的再構成結果を見てみましょう。
デコード
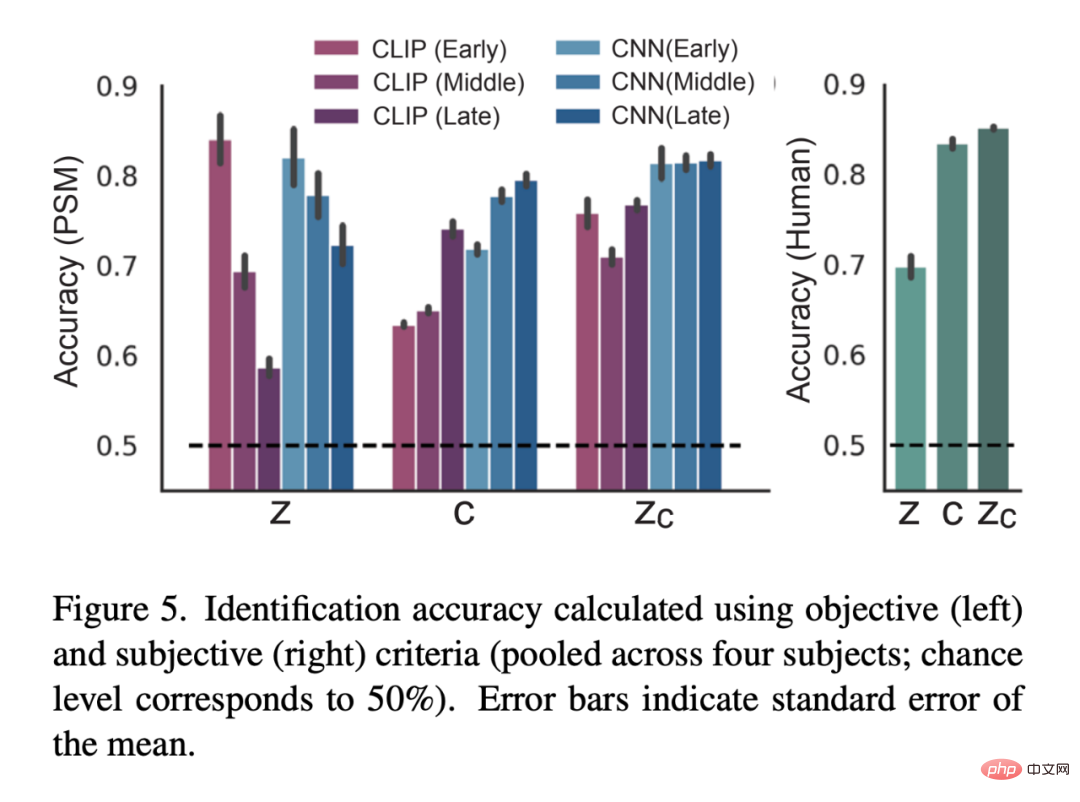
下の図 3 は、被験者 (subj01) の視覚的再構成結果を示しています。各テスト画像に対して 5 つの画像を生成し、PSM が最も高い画像を選択しました。一方で、z のみを使用して再構成された画像は、元の画像と視覚的に一致しますが、その意味的な内容を捉えることができません。一方、c のみを使用して再構成された画像は、意味論的忠実度が高い画像を生成しますが、視覚的には一貫性がありません。最後に、z_c 再構成イメージを使用すると、セマンティック忠実度の高い高解像度イメージを生成できます。

# 図 4 は、すべてのテスターによる同じ画像の再構成を示しています (すべての画像は z_c で生成されました)。全体として、テスター全体の再構成品質は安定していて正確でした。

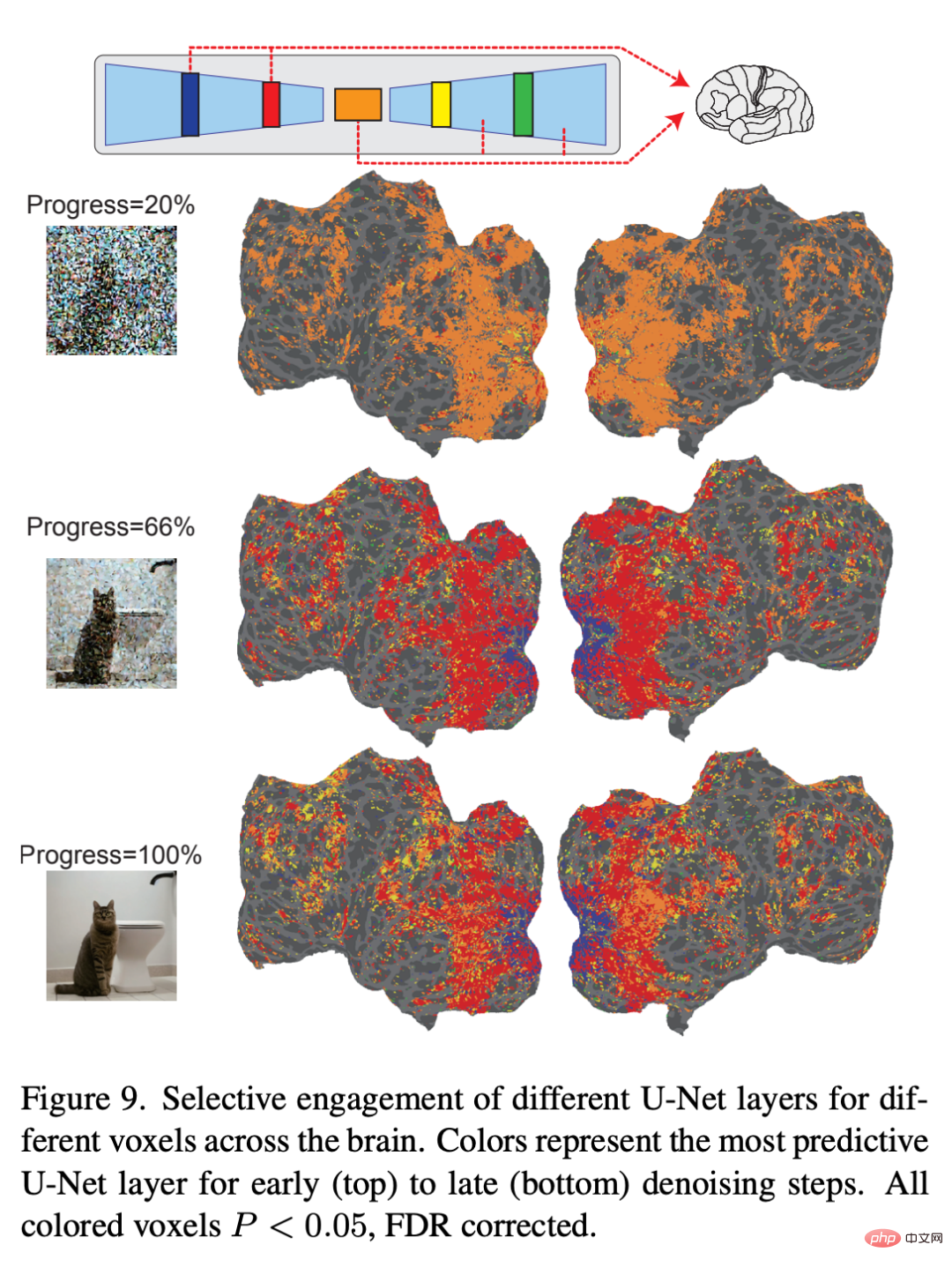
コーディング モデル ## 図 6 は、LDM に関連するコーディング モデルのペアを示しています。 3 つの潜在画像の予測精度: z、元の画像の潜在画像、c、画像テキスト注釈の潜在画像、および z_c、c によるクロスアテンション逆拡散プロセス後の z のノイズを含む潜在画像表現。
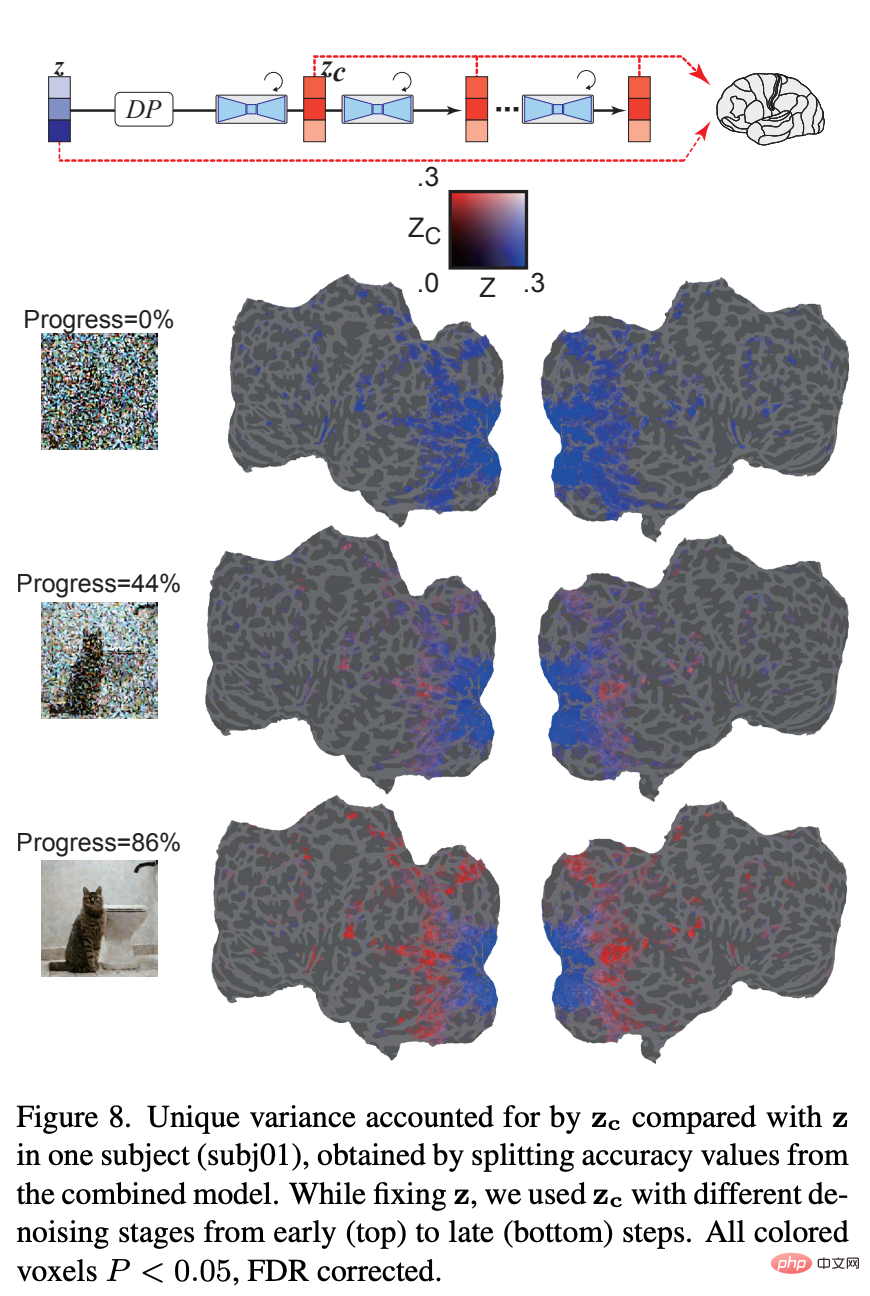
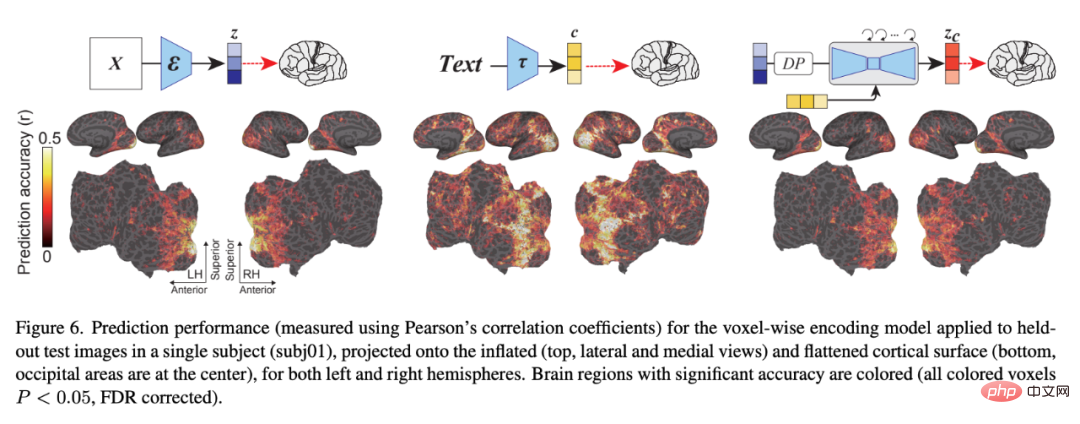 図 7 は、少量のノイズが追加された場合に、z が z_c よりも皮質全体のボクセル活動をより正確に予測することを示しています。興味深いことに、ノイズ レベルを増加すると、z_c は高視覚野のボクセル活動を z よりも正確に予測し、画像の意味内容が徐々に強調されることを示します。
図 7 は、少量のノイズが追加された場合に、z が z_c よりも皮質全体のボクセル活動をより正確に予測することを示しています。興味深いことに、ノイズ レベルを増加すると、z_c は高視覚野のボクセル活動を z よりも正確に予測し、画像の意味内容が徐々に強調されることを示します。

 研究の詳細については、元の論文をご覧ください。
研究の詳細については、元の論文をご覧ください。
以上が「安定拡散技術を利用した画像再現、関連研究がCVPRカンファレンスに採択されました」の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。