
ホームページ >テクノロジー周辺機器 >AI >高品質の言語データの世界的な在庫は不足しており、無視することはできません。
高品質の言語データの世界的な在庫は不足しており、無視することはできません。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-26 11:37:071618ブラウズ
人工知能の 3 つの要素の 1 つとして、データは重要な役割を果たします。
しかし、考えたことはありますか。ある日、世界中のすべてのデータが使い果たされたらどうなるでしょうか?
実は、この質問をした人は精神的には全く問題ありません。その日はもうすぐやってくるかもしれません。 ! !
最近、研究者のパブロ・ヴィラロボス氏らは、「データは枯渇するのか?」というタイトルの記事を発表しました。論文「機械学習におけるデータセット スケーリングの限界の分析」 が arXiv で公開されました。
データセットサイズの傾向に関する以前の分析に基づいて、言語および視覚分野におけるデータセットサイズの増加を予測し、利用可能なラベルなしデータの総ストックの発展傾向を推定しました。今後数十年以内に。
彼らの研究によると、高品質の言語データは早ければ 2026 年に枯渇することがわかっています。その結果、機械学習の開発ペースも遅くなるでしょう。本当に楽観的ではありません。
2 つの方法が双方向で使用されていますが、結果は楽観的ではありません
この論文の研究チームは、11 人の研究者と 3 人のコンサルタントで構成されており、あらゆる国のメンバーが参加しています。技術開発と AI 戦略の間の AI ギャップの縮小に専念し、AI の安全性に関する主要な意思決定者にアドバイスを提供しています。

Chinchilla は、DeepMind の研究者によって提案された新しい予測コンピューティング最適化モデルです。
実際、チンチラに関する以前の実験中に、ある研究者は「大規模な言語モデルを拡張する際には、トレーニング データがすぐにボトルネックになるだろう」と示唆したことがあります。
そこで彼らは、自然言語処理とコンピューター ビジョンの機械学習データセットのサイズの増加を分析し、過去の増加率を使用する方法と、将来の予測される 2 つの方法を使用して推定しました。最適なデータ セット サイズを計算するために計算予算が見積もられます。
これに先立ち、彼らはトレーニング データなどを含む機械学習の入力傾向に関するデータを収集し、また、インターネット上で入手可能なラベルなしデータの総ストックを推定することによって、データを収集してきました。今後数十年間、データ使用量の増加を調査するため。
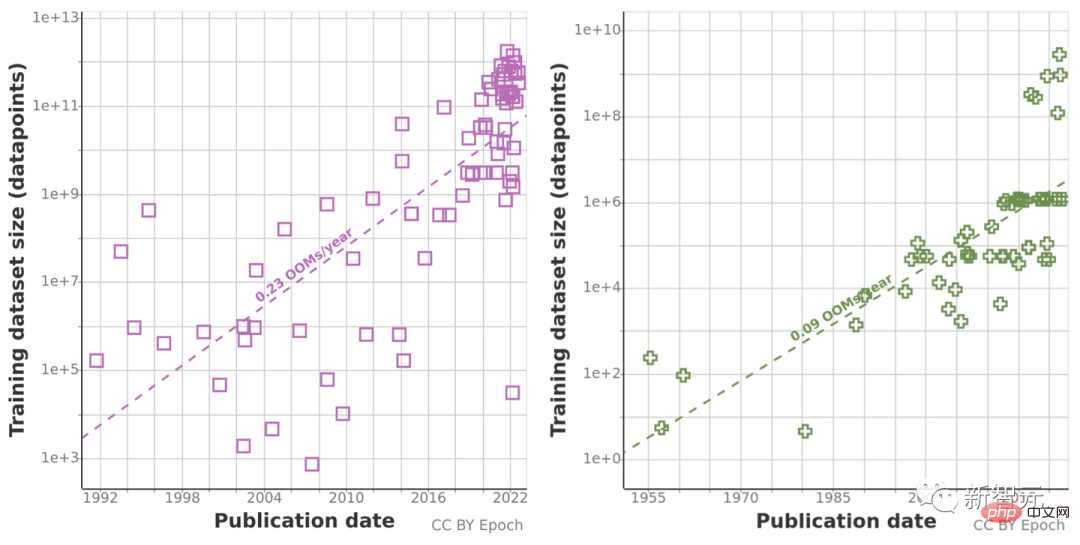
過去 10 年間のコンピューティング量の異常な増加により、過去の予測傾向が「誤解を招く」可能性があるため、研究チームはチンチラのスケーリング則も使用しました。計算結果の精度を向上させるために、今後数年間のデータセットのサイズを推定します。
最終的に、研究者らは一連の確率モデルを使用して、今後数年間の英語および画像データの総在庫を推定し、トレーニング データ セットのサイズと総データの予測を比較しました。図に示すように、結果は次のようになります。
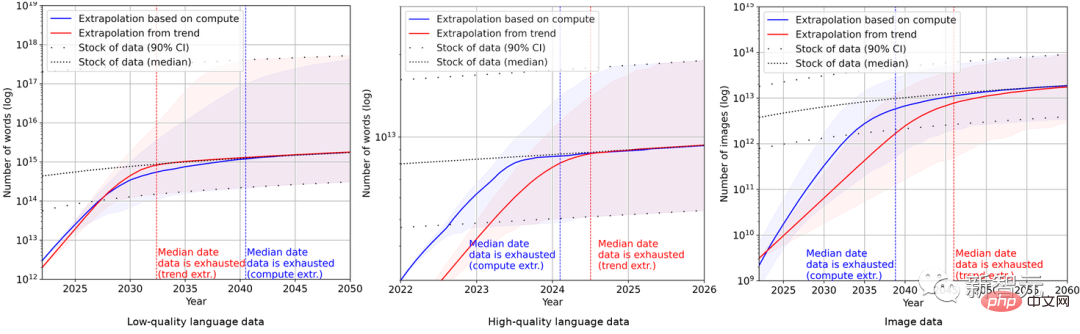
#これは、データ セットの増加率がデータ ストレージよりもはるかに速いことを示しています。
したがって、このままの傾向が続けば、データストックが枯渇することは避けられません。以下の表は、予測曲線の各交点における枯渇までの年数の中央値を示しています。
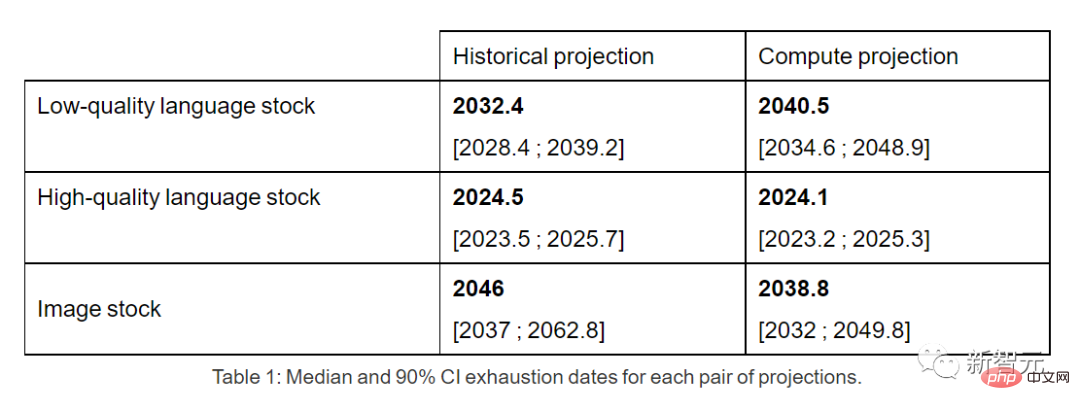
高品質の言語データの在庫は、早ければ 2026 年までに枯渇する可能性があります。
これに対して、低品質の言語データと画像データの状況は若干良くなり、前者は 2030 年から 2050 年までに使い尽くされ、後者は 2030 年までに使い尽くされる見通しです。と2060年の間。
研究チームは論文の最後で次のように結論付けています: データ効率が大幅に改善されない場合、または新しいデータソースが利用可能な場合、現在、拡大し続ける巨大なデータセットに依存している機械学習モデルの成長傾向は、速度が低下する可能性があります。
ネチズン: 心配は杞憂です、Efficient Zero についてもっと調べましょう
しかし、この記事のコメント欄では、ほとんどのネチズンは著者が次のように考えています。根拠のない。
Reddit で、ktpr という名前のネチズンは次のように述べました:
「自己教師あり学習の何が問題なのでしょうか?タスクが適切に指定されていれば、組み合わせてデータセットのサイズを拡張することもできます。」
lostmsn という名前のネチズンはさらに不親切でした。彼は率直にこう言った:
# 「効率ゼロのことも理解していないのですか? 著者は深刻に時代感覚を失っていると思います。」
##Efficient Zero は、清華大学の Gao Yang 博士によって提案された、効率的にサンプリングできる強化学習アルゴリズムです。
Efficient Zero は、限られたデータ量の場合、強化学習のパフォーマンスの問題をある程度解決しており、アルゴリズムの汎用テスト ベンチマークである Atari Game で検証されています。
この論文の著者チームのブログでは、彼ら自身も認めています:
"私たちの結論はすべて、機械学習データの使用と生産における現在の傾向が、データ効率の大幅な改善なしに継続するという非現実的な仮定に基づいています。」
「より信頼性の高いモデルには、機械学習データの効率の向上、合成データの使用、その他のアルゴリズム的および経済的要因が考慮されます。"
"つまり、実際的な観点から言えば、この分析には重大な限界があります。モデルの不確実性"
"しかし、全体的には、トレーニング データの不足により、2040 年までに機械学習モデルが拡張される可能性は約 20% であると依然として考えられています。速度が大幅に低下します。」
以上が高品質の言語データの世界的な在庫は不足しており、無視することはできません。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。