



著者について
一言で言えば、Ctripのバックエンド開発マネージャーで、技術アーキテクチャ、パフォーマンスの最適化、輸送計画などの分野に重点を置いています。
1. 背景の紹介
輸送計画と輸送能力リソースの制限により、ユーザーが問い合わせた 2 つの場所の間、または大型休暇中は直接輸送ができない場合があります。 、直接輸送すべて完売しました。ただし、ユーザーは、 電車、飛行機、車、船などの双方向または多方向の乗り継ぎを利用して目的地に到着することができます。また、料金や時間の面で振替輸送の方が有利な場合もあります。たとえば、上海から運城までは、直通列車よりも電車で接続した方が速くて安い場合があります。
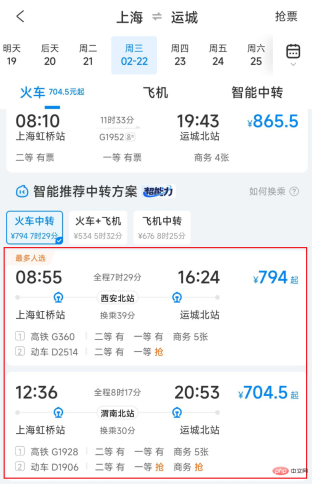
#図 1 Ctrip 列車乗り換え輸送リスト
乗り換え輸送ソリューションを提供する場合、非常に重要です1 つのリンクは、電車、飛行機、車、船などの 2 つ以上の移動をつなぎ合わせて、実現可能な移動計画を作成することです。交通交通の接続における最初の困難は、接続スペースが広大であることです。上海を交通都市として考えるだけでも、1 億近い組み合わせが生成される可能性があります。もう 1 つの困難は、生産ラインのデータが刻々と変化するため、リアルタイム性が要求されることです。電車、飛行機、自動車、船舶に関するデータをクエリします。トランジット トラフィック スプライシングには大量のコンピューティング リソースと IO オーバーヘッドが必要なため、パフォーマンスの最適化が特に重要です。
この記事では、読者に貴重な参考資料とインスピレーションを提供することを目的として、例を組み合わせて、転送トラフィック スプライシングのパフォーマンスを最適化するプロセスで実行される原理、分析、および最適化方法を紹介します。
2. 最適化の原則パフォーマンスの最適化には、ビジネス ニーズを満たすことを前提として、さまざまなリソースと制約の間でバランスを取り、トレードオフを行う必要があり、いくつかの主要な原則に従う必要があります。不確実性を排除し、問題の最適な解決策に近づきます。具体的には、転送トラフィック スプライシングの最適化プロセスでは、主に次の 3 つの原則に従います。
2.1 パフォーマンスの最適化は目的ではなく手段であるただし、この記事は、パフォーマンスの最適化ですが、それでも最初に強調する必要があります。最適化のための最適化はしないでください。ビジネス ニーズを満たす方法は数多くありますが、パフォーマンスの最適化はそのうちの 1 つにすぎません。問題が非常に複雑で多くの制限がある場合もありますが、ユーザー エクスペリエンスに大きな影響を与えることなく、制限を緩和するか他のプロセスを採用することでユーザーへの影響を軽減することも、パフォーマンスの問題を解決する良い方法です。ソフトウェア開発では、パフォーマンスを少し犠牲にすることで大幅なコスト削減が達成された例が数多くあります。たとえば、Redis のカーディナリティ統計 (重複の削除) に使用される HyperLogLog アルゴリズムは、わずか 12K のスペースで 264 個のデータをカウントでき、標準誤差は 0.81% です。
問題自体に戻ります。生産ライン データは頻繁にクエリする必要があり、大規模なスプライシング操作が実行されるため、各ユーザーがクエリ時に最新の転送計画をすぐに返す必要がある場合、コストが非常に高くなります。コストを削減するには、応答時間とデータの鮮度の間でバランスを取る必要があります。慎重に検討した結果、分単位のデータの不一致を受け入れることを選択しました。人気のないルートや日付については、初めてクエリを実行するときに適切な移動計画がない可能性があります。この場合は、ユーザーにページを更新するようガイドするだけです。
2.2 不適切な最適化が諸悪の根源であるDonald Knuth 氏は、「Go To ステートメントを使用した構造化プログラミング」で次のように述べています。「プログラマは、考えたり心配したりして多くの時間を無駄にします。クリティカルでないパスのパフォーマンスについて考え、パフォーマンスのこの部分を最適化しようとすると、コード全体のデバッグとメンテナンスに非常に深刻な悪影響が及ぶため、97% の場合、小さな最適化ポイントを忘れるべきです。」つまり、実際のパフォーマンスの問題が発見される前に、コード レベルで過剰かつ大げさな最適化を行うと、パフォーマンスが向上しないだけでなく、エラーの増加につながる可能性があります。ただし、著者は「残りの重要な 3% については、最適化の機会を逃すべきではない」とも強調しました。したがって、常にパフォーマンスの問題に注意を払い、パフォーマンスに影響を与える決定を下さず、必要に応じて適切な最適化を行う必要があります。
2.3 パフォーマンスを定量的に分析し、最適化の方向性を明確にする
前のセクションで説明したように、最適化をより的を絞った最適化を行うために、最適化する前にまずパフォーマンスを定量化し、ボトルネックを特定する必要があります。 。パフォーマンスの定量的な分析には、時間のかかる監視、Profiler パフォーマンス分析ツール、Benchmark ベンチマーク テスト ツールなどを使用して、特に時間がかかる領域や実行頻度が特に高い領域に焦点を当てることができます。アムダールの法則は次のように述べています。「システム内の特定のコンポーネントに対してより高速な実行方法を使用することによって得られるシステム パフォーマンスの向上の程度は、この実行方法が使用される頻度、または合計実行時間の割合に依存します。 」
さらに、パフォーマンスの最適化は長期戦であることに注意することも重要です。ビジネスが発展し続けるにつれて、アーキテクチャとコードは常に変化するため、パフォーマンスを継続的に定量化し、ボトルネックを継続的に分析し、最適化効果を評価することがさらに必要になります。
3. パフォーマンス分析への道
3.1 ビジネス プロセスの整理
パフォーマンス分析の前に、まずビジネス プロセスを整理する必要があります。乗り換え輸送計画の結合には、主に次の 4 つのステップが含まれます:
#a. 南京乗り換え経由で北京から上海などのルート マップを読み込み、ルート自体の情報のみが表示されます。
b. 列車、飛行機、自動車、船舶の出発時刻、到着時刻、出発駅などの生産ライン データを確認します。到着駅、料金と残りのチケット情報など;
c. 実行可能なすべての乗り換え交通手段を組み合わせるために、主に考慮すべきことは、乗り換え時間が短すぎて避けられないことです。転送を完了できないことと同時に、待ち時間が長くなりすぎないようにする必要があります。実現可能なソリューションをつなぎ合わせた後も、合計金額、合計所要時間、乗り換え情報などのビジネス フィールドを改善する必要があります;
d. 一定のルールに従って、から実現可能な転送ソリューションの中から、ユーザーにとって興味深いと思われるいくつかのソリューションが選択されます。
3.2 定量分析パフォーマンス
(1) 時間のかかるモニタリングの増加
時間-消費モニタリングは、各段階の時間のかかる状況をマクロの観点から観察する最も直観的な方法です。ビジネスプロセスの各段階での時間の価値と時間の割合を表示するだけでなく、長期にわたる時間の変化傾向を観察することもできます。
時間のかかる監視では、社内のインジケータ監視およびアラーム システムを使用して、交通輸送ソリューションを接続する主要なプロセスに時間のかかる管理を追加できます。これらのプロセスには、ルート マップのロード、シフト データのクエリとスプライシング、スプライシング プランのフィルタリングと保存などが含まれます。各段階の時間のかかる状況を図 2 に示します。スプライシング (生産ライン データを含む) が時間のかかる部分で最も高い割合を占めていることがわかり、今後の重要な最適化ターゲットとなっています。
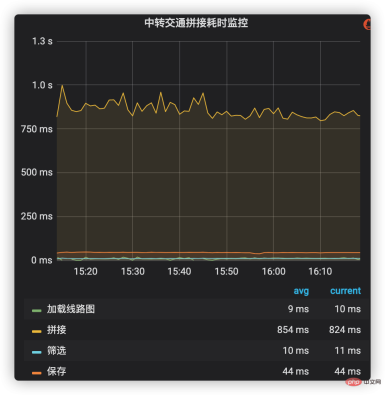
図 2 時間のかかるトランジット トラフィック スプライシングのモニタリング
(2) プロファイラパフォーマンス分析
時間のかかる管理はビジネス コードに侵入し、パフォーマンスに影響を与える可能性があるため、多すぎないようにし、メイン プロセスの監視に適しています。対応する Profiler パフォーマンス分析ツール (Async-profiler など) は、より具体的なコール ツリーと各関数の CPU 使用率を生成できるため、クリティカル パスとパフォーマンスのボトルネックを分析して特定するのに役立ちます。

#図 3 スプライシング コール ツリーと CPU 比率
図 3 に示すように、スプライシング スキームは(combineTransferLines) が 53.80% を占め、クエリ生産ライン データ (querySegmentCacheable、キャッシュ使用) が 21.45% を占めます。スプライシング スキームでは、スキーム スコアの計算 (computeTripScore、48.22% を占める)、スキーム エンティティの作成 (buildTripBO、4.61% を占める)、およびスプライシングの実現可能性の確認 (checkCombineMatchCondition、0.91% を占める) が 3 つの最大のリンクです。

最も高い割合で計算計画スコア (computeTripScore) の分析を続けると、それは主に、計画を表示するために使用される直接呼び出しを含む、カスタム文字列書式設定関数 (StringUtils.format) に関連していることがわかりました。スコアの詳細)、および getTripId を介した間接的な呼び出し(スキームの ID の生成に使用されます)。カスタマイズされた StringUtils.format の最も高い割合は java/lang/String.replace です。Java 8 のネイティブ文字列置換は正規表現によって実装されており、比較的非効率的です (この問題は Java 9 以降は改善されました)。 (3)Benchmark ベンチマーク テスト Benchmark ベンチマーク テスト ツールを使用すると、次のことを測定できます。コードのパフォーマンスをより正確に実行時間に反映します。表 1 では、JMH (Java Microbenchmark Harness) を使用して、3 つの文字列フォーマット方法と 1 つの文字列スプライシング方法について時間のかかるテストを実行しています。テスト結果は、Java8 の replace メソッドを使用した文字列フォーマットのパフォーマンスが最も悪いのに対し、Apache の文字列スプライシング関数を使用した場合のパフォーマンスが最も優れていることを示しています。 #表 1 文字列のフォーマットとスプライシングのパフォーマンスの比較
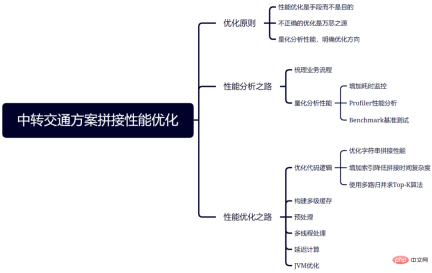
## を使用して実装された StringUtils.format ##1417.474 ##116.812 ## 通过以上的性能分析,我们发现拼接和查询产线数据是性能瓶颈,字符串格式化影响尤其大。因此,我们将致力于优化这些部分,以提高性能表现。 优化代码逻辑是最简单且性价比最高的方法,可以是修正有问题的代码或替换为更好的实现。不同的实现,哪怕减上几纳秒,累加起来也是很可观的。借助一些经典算法或数据结构(如快速排序、红黑树等)可以在时间和空间复杂度方面带来显著优势。回到中转交通方案拼接性能优化本身,优化的代码逻辑主要包括: (1)优化字符串拼接性能 如前面的JMH的结果所示,自定义的字符串格式化函数性能最差,因此作为重点优化目标。优化前后的对比如下所示: 根据JMH的测试结果,即使是优化后的格式化函数,其性能也不是最优的。在不显著影响可读性的前提下,应尽量使用性能更优的StringUtils.join函数。 为进一步提升性能,可以在computeTripScore 函数中添加一个开关,仅在调试模式下才展示评分细节,这将确保该字符串格式化函数仅在需要时才被调用。 优化后的CPU占比如图5所示,此时字符串格式化已经不再是性能瓶颈。 图5 优化后的拼接调用树和CPU占比 (2)增加索引降低拼接时间复杂度 图6 增加索引降低拼接时间复杂度 在中转拼接过程中,我们需要将第一程每个班次的到达时间与第二程每个班次的出发时间进行比较,以判断中转时间是否过短或过长。为简化说明,假设换乘时间间隔需要满足大于30分钟且小于6小时。以北京到上海经南京中转的两程火车为例,3月9日北京到南京有66个班次,南京到上海有275个班次,考虑到隔夜车,还需要算上3月10日南京到上海的275个班次,那么最多需要比较36300(66*275*2)次。 为避免频繁比较,参考了MySQL B+树索引的思想,将第二程南京到上海的所有火车班次数据构建成红黑树。其中,树的键为秒级时间戳,例如2023-03-09 11:29出发的G367键为1677247680,值为G367的班次数据。有了索引树,最多只需要10次比较,就可以找到最近的满足最小换乘时间要求的班次。同理,最多需要10次比较,就能找到满足最大换乘时间要求的最晚班次。两者之间的所有班次都满足耗时要求,直接进行拼接即可。改进后最多需要比较1320(66*(10+10))次,约为原来的1/27.5。 (3)使用多路归并求Top-K算法 在筛选方案时,会存在以下场景:有多个中转点,每个中转点都有数百个得分较高的方案(内部已按得分由高到低排序,通过小根堆实现)。最终需要将这些方案合并,并从中筛选出得分最高的K个方案。 最简单的方法是使用快速排序将所有的方案排序,然后选取前K个,时间复杂度约为O(nlog2n)。然而,这并没有利用到每个队列自身有序的特点。通过多路归并算法时间复杂度可降为O(nlog2k),具体步骤为: a. 从每个队列中拿出第一个元素(得分最高的方案),放入大根堆中; b. ビッグ ルート ヒープの最上位から最大の要素を取得し、それを結果セットに追加します; c. キューに要素が残っている場合要素が配置されている場所に次の要素をヒープに追加します; d. 結果セットに K 個の要素が含まれるか、すべてのキューが空になるまで、手順 2 と 3 を繰り返します。 #図 7 マルチパス マージ Top-K アルゴリズム キャッシュは、データと計算結果をキャッシュできる典型的なスペースフォータイム戦略です。データをキャッシュするとアクセス効率が向上し、結果をキャッシュすると計算の繰り返しが回避されます。キャッシュによってパフォーマンスが向上する一方で、新たな問題も発生します。 乗り換え輸送ソリューションをつなぎ合わせるプロセスでは、大量の基本データ (駅、管理エリアなど) と膨大な動的データ (シフト データなど) )を使用する必要があります。上記の要素に基づいて、交通輸送スプライシングのビジネス特性と組み合わせて、キャッシュ アーキテクチャは次のように設計されます。 4.3 前処理 スプライス処理では、異なる転写点を持つ数十本のラインを処理する必要があります。各ラインのスプライシングは互いに独立しているため、マルチスレッドを使用でき、処理時間を最小限に抑えることができます。ただし、ライン シフトの数とキャッシュ ヒット率の影響により、異なるラインのスプライシング時間を一貫させることは困難です。多くの場合、2 つのスレッドに同じ数のタスクが割り当てられている場合、1 つのスレッドの実行がすぐに終了したとしても、次のステップに進む前に、もう 1 つのスレッドの実行が終了するまで待たなければなりません。この状況を回避するために、ForkJoinPool のワークスチール メカニズムが使用されます。このメカニズムにより、各スレッドが独自のタスクを完了した後、他のスレッドの未完了の作業を確実に共有し、同時実行効率を向上させ、アイドル時間を短縮することができます。 ただし、マルチスレッドは万能ではありません。使用する場合は、次の点に注意する必要があります。 必要な時点まで計算を遅延させることにより、多くの冗長なオーバーヘッドを回避することができます。たとえば、転送計画を結合した後、計画エンティティを構築してビジネス フィールドを改善する必要があり、この部分でもリソースが消費されます。また、すべてのスプライスされたソリューションが選別されるわけではありません。つまり、これらの選別されていないソリューションは引き続きコンピューティング リソースを消費する必要があります。したがって、完全なソリューション エンティティ オブジェクトの構築が遅れます。スプライシング プロセスの数万のソリューションは、最初に軽量の中間オブジェクトとして保存され、完全なソリューション エンティティは、スクリーニング後に数百の中間オブジェクトに対してのみ構築されます。 トランジット トラフィック スプライシング プロジェクトは Java 8 に基づいており、G1 (ガベージ ファースト) ガベージ コレクターを使用し、8C8G マシンにデプロイされます。 G1 は、一時停止時間の要件を可能な限り満たしながら、高いスループットを実現します。システム アーキテクチャ部門によって設定されたデフォルトのパラメータは、ほとんどのシナリオにすでに適しており、通常は特別な最適化を必要としません。 ただし、回線転送方式が多すぎるため、パケットが大きすぎてリージョン サイズ (8G、デフォルトのリージョン サイズは 2M) の半分を超えてしまい、若い世代に直接入力されるべき大きなオブジェクト 古い時代に入ると、この状況を回避するために、リージョン サイズを 16M に変更します。 上記の分析と最適化による、スプライシング時間の消費量の変化を図 9 に示します。 ##図 9 転送輸送スキーム スプライシングのパフォーマンス最適化効果 各ビジネスとシナリオには独自の特性がありますが、パフォーマンスの最適化には特定の分析も必要です。ただし、原理は同じなので、この記事で説明されている分析および最適化の方法を引き続き参照できます。この記事のすべての分析および最適化手法の概要を図 10 に示します。
図 10 移送輸送計画のスプライシング最適化の概要// 计算方案评分(computeTripScore) 中调用的StringUtils.format代码示例
StringUtils.format("AAAA-{0},BBBB-{1},CCCC-{2},DDDD-{3},EEEE-{4},FFFF-{5},GGGG-{6},HHHH-{7},IIII-{8},JJJJ-{9}",
aaaa, bbbb, cccc, dddd, eeee, ffff, gggg, hhhh, iiii, jjjj)
// getTripId 中调用StringUtils.format代码示例
StringUtils.format("{0}_{1}_{2}_{3}_{4}_{5}_{6}", aaaa, bbbb, cccc, dddd, eeee, ffff)
// 通过Java replace实现的自定义format函数
public static String format(String template, Object... parameters) {
for (int i = 0; i < parameters.length; i++) {
template = template.replace("{" + i + "}", parameters[i] + "");
}
return template;
}
##実装
1000回の実行にかかる平均時間(us)
##Java8 の replace を使用して実装された StringUtils.format
1988.982 #Apache replace #Java8 には String.format が付属しています
四、性能优化之路
4.1 优化代码逻辑
// 优化前,通过Java replace实现的format函数
public static String format(String template, Object... parameters) {
for (int i = 0; i < parameters.length; i++) {
template = template.replace("{" + i + "}", parameters[i] + "");
}
return template;
}
// 优化后,通过Apache replace实现的format函数
public static String format(String template, Object... parameters) {
for (int i = 0; i < parameters.length; i++) {
String temp = new StringBuilder().append('{').append(i).append('}').toString();
template = org.apache.commons.lang3.StringUtils.replace(template, temp, String.valueOf(parameters[i]));
}
return template;
}// 优化前
StringUtils.format("{0}_{1}_{2}_{3}_{4}_{5}_{6}", aaaa, bbbb, cccc, dddd, eeee, ffff)
// 优化后
StringUtils.join("_", aaaa, bbbb, cccc, dddd, eeee, ffff)if (Config.getBoolean("enable.score.detail", false)) {
scoreDetail = StringUtils.format("AAAA-{0},BBBB-{1},CCCC-{2},DDDD-{3},EEEE-{4},FFFF-{5},GGGG-{6},HHHH-{7},IIII-{8},JJJJ-{9}",
aaaa, bbbb, cccc, dddd, eeee, ffff, gggg, hhhh, iiii, jjjj);
}


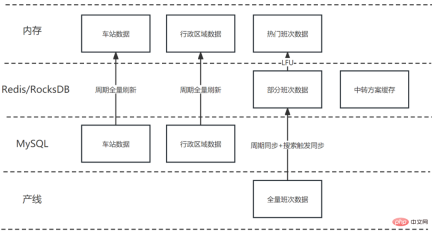
4.4 マルチスレッド処理
4.5 遅延計算
4.6 JVM の最適化
5. 概要

以上がCtripの移送輸送計画のスプライシングパフォーマンスを最適化するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Microsoft Work Trend Index 2025は、職場の容量の緊張を示していますApr 24, 2025 am 11:19 AM
Microsoft Work Trend Index 2025は、職場の容量の緊張を示していますApr 24, 2025 am 11:19 AMAIの急速な統合により悪化した職場での急成長能力の危機は、増分調整を超えて戦略的な変化を要求します。 これは、WTIの調査結果によって強調されています。従業員の68%がワークロードに苦労しており、BURにつながります
 AIは理解できますか?中国の部屋の議論はノーと言っていますが、それは正しいですか?Apr 24, 2025 am 11:18 AM
AIは理解できますか?中国の部屋の議論はノーと言っていますが、それは正しいですか?Apr 24, 2025 am 11:18 AMジョン・サールの中国の部屋の議論:AIの理解への挑戦 Searleの思考実験は、人工知能が真に言語を理解できるのか、それとも真の意識を持っているのかを直接疑問に思っています。 チャインを無知な人を想像してください
 中国の「スマート」AIアシスタントは、マイクロソフトのリコールのプライバシーの欠陥をエコーしますApr 24, 2025 am 11:17 AM
中国の「スマート」AIアシスタントは、マイクロソフトのリコールのプライバシーの欠陥をエコーしますApr 24, 2025 am 11:17 AM中国のハイテク大手は、西部のカウンターパートと比較して、AI開発の別のコースを図っています。 技術的なベンチマークとAPI統合のみに焦点を当てるのではなく、「スクリーン認識」AIアシスタントを優先しています。
 Dockerは、おなじみのコンテナワークフローをAIモデルとMCPツールにもたらしますApr 24, 2025 am 11:16 AM
Dockerは、おなじみのコンテナワークフローをAIモデルとMCPツールにもたらしますApr 24, 2025 am 11:16 AMMCP:AIシステムに外部ツールにアクセスできるようになります モデルコンテキストプロトコル(MCP)により、AIアプリケーションは標準化されたインターフェイスを介して外部ツールとデータソースと対話できます。人類によって開発され、主要なAIプロバイダーによってサポートされているMCPは、言語モデルとエージェントが利用可能なツールを発見し、適切なパラメーターでそれらを呼び出すことができます。ただし、環境紛争、セキュリティの脆弱性、一貫性のないクロスプラットフォーム動作など、MCPサーバーの実装にはいくつかの課題があります。 Forbesの記事「人類のモデルコンテキストプロトコルは、AIエージェントの開発における大きなステップです」著者:Janakiram MSVDockerは、コンテナ化を通じてこれらの問題を解決します。 Docker Hubインフラストラクチャに基づいて構築されたドキュメント
 6億ドルのスタートアップを構築するために6つのAIストリートスマート戦略を使用するApr 24, 2025 am 11:15 AM
6億ドルのスタートアップを構築するために6つのAIストリートスマート戦略を使用するApr 24, 2025 am 11:15 AM最先端のテクノロジーと巧妙なビジネスの洞察力を活用して、コントロールを維持しながら非常に収益性の高いスケーラブルな企業を作成する先見の明のある起業家によって採用された6つの戦略。このガイドは、建設を目指している起業家向けのためのものです
 Googleフォトの更新は、すべての写真の見事なウルトラHDRのロックを解除しますApr 24, 2025 am 11:14 AM
Googleフォトの更新は、すべての写真の見事なウルトラHDRのロックを解除しますApr 24, 2025 am 11:14 AMGoogle Photosの新しいウルトラHDRツール:画像強化のゲームチェンジャー Google Photosは、強力なウルトラHDR変換ツールを導入し、標準的な写真を活気のある高ダイナミックレンジ画像に変換しました。この強化は写真家に利益をもたらします
 Descopeは、AIエージェント統合の認証フレームワークを構築しますApr 24, 2025 am 11:13 AM
Descopeは、AIエージェント統合の認証フレームワークを構築しますApr 24, 2025 am 11:13 AM技術アーキテクチャは、新たな認証の課題を解決します エージェントアイデンティティハブは、AIエージェントの実装を開始した後にのみ多くの組織が発見した問題に取り組んでいます。
 Google Cloud Next2025と現代の仕事の接続された未来Apr 24, 2025 am 11:12 AM
Google Cloud Next2025と現代の仕事の接続された未来Apr 24, 2025 am 11:12 AM(注:Googleは私の会社であるMoor Insights&Strategyのアドバイザリークライアントです。) AI:実験からエンタープライズ財団まで Google Cloud Next 2025は、実験機能からエンタープライズテクノロジーのコアコンポーネント、ストリームへのAIの進化を紹介しました


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません
ホットトピック
 7697
7697 15164014139352128725122929
15164014139352128725122929