
ホームページ >テクノロジー周辺機器 >AI >OpenAIを再び打ち負かしましょう! Google、100以上の言語を自動的に認識して翻訳する20億パラメータのユニバーサルモデルをリリース
OpenAIを再び打ち負かしましょう! Google、100以上の言語を自動的に認識して翻訳する20億パラメータのユニバーサルモデルをリリース

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-25 12:04:061544ブラウズ
先週、OpenAI は ChatGPT API と Whisper API をリリースし、開発者間でカーニバルを引き起こしました。
#Google は 3 月 6 日、ベンチマーク モデル USM を発表しました。 100以上の言語をサポートしているだけでなく、パラメータの数も20億に達しています。
# もちろん、モデルはまだ公開されていませんが、「これはまさに Google です」!
簡単に言えば、USM モデルは 1,200 万時間の音声と 280 億の文をカバーします。 300 の異なる言語のラベルなしデータセットで事前トレーニングされ、ラベル付きの小さなトレーニング セットで微調整されます。
Google の研究者らは、微調整に使用されるアノテーション トレーニング セットは Whisper の 1/7 にすぎませんが、USM は同等かそれ以上の結果が得られると述べています。新しい言語やデータに効率的に適応する能力も必要です。

紙のアドレス: https://arxiv.org/abs/2303.01037
#結果は、USM が多言語自動音声認識および音声テキスト翻訳タスクの評価において SOTA を達成するだけでなく、実際に YouTube の字幕生成にも使用できることを示しています。#現在、自動検出と翻訳をサポートしている言語には、主流の英語、中国語、およびアッサム語などの小規模な言語が含まれています。
#最も重要なことは、昨年の IO カンファレンスで Google がデモンストレーションした将来の AR メガネのリアルタイム翻訳にも使用できることです。
Jeff Dean が個人的に発表しました: AI に 1,000 の言語をサポートさせましょう
## While Microsoft Google はどちらが優れた AI チャットボットを持っているかについて議論していますが、大規模な言語モデルはそれだけではないことにも使用できることを知っています。
昨年 11 月、Google は「世界で最も一般的に使用されている 1,000 の言語をサポートする人工知能言語モデルを開発する」という新しいプロジェクトを初めて発表しました。 。」

#最新モデルのリリースは、Google によってその目標に向けた「重要なステップ」であると説明されています。
# 言語モデルの構築に関しては、多くの英雄が競い合っていると言えます。
噂によると、Google は今年の年次 I/O カンファレンスで人工知能を活用した 20 以上の製品を展示する予定です。
現在、自動音声認識は多くの課題に直面しています:
従来の教師あり学習方法にはスケーラビリティが欠けています
- ##従来の方法では、時間とコストがかかる方法で音声データに手動でラベルを付ける必要があります。既存のトランスクリプションのソースから収集されますが、広範な表現が欠けている言語では見つけるのが難しい場合があります。
- #言語の範囲と品質を拡大しながら、計算効率の高い方法でモデルを改善する必要があります
これには、さまざまなソースからの大量のデータを使用でき、完全な再トレーニングを必要とせずにモデルの更新を可能にし、新しい言語やユースケースに一般化できるアルゴリズムが必要です。 微調整された自己教師あり学習
論文によると、USM トレーニングでは、ペアになっていないオーディオ データ セット、ペアになっていないテキスト データの 3 つのデータベースが使用されます。セット、ペアになった ASR コーパス。
- #ペアになっていない音声データセット
#ペアになっていないテキスト データ セット
- ##Web -NTL (1,140 以上の異なる言語で 280 億文)
対になった ASR コーパス
- YT-SUP および Pub-S コーパス (10,000 時間以上の音声コンテンツと一致するテキスト)
USM は標準のエンコーダ/デコーダ構造を使用します。デコーダには CTC、RNN -T、または LAS を使用できます。

#エンコーダの場合、USM は Conformor、つまり畳み込み強化された Transformer を使用します。
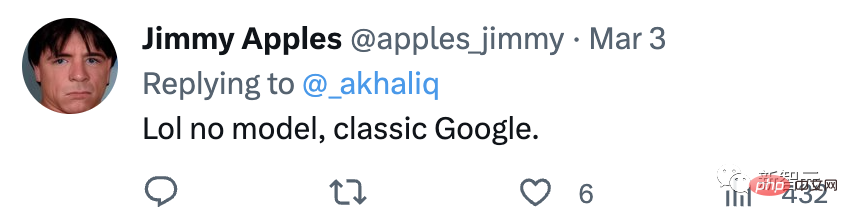
#トレーニング プロセスは 3 つの段階に分かれています。
#初期段階では、BEST-RQ (音声事前トレーニング用の BERT ベースのランダム射影量子化器) を使用して教師なし事前トレーニングが実行されます。目標は、RQ を最適化することです。
#次の段階では、音声表現学習モデルがさらにトレーニングされます。
MOST (Multi-Object Supervised Pre-training) を使用して、他のテキスト データからの情報を統合します。
このモデルでは、テキストを入力として受け取る追加のエンコーダー モジュールを導入し、音声エンコーダーとテキスト エンコーダーの出力を組み合わせてモデルを共同トレーニングするための追加レイヤーを導入しています。ラベルなしの音声、ラベル付きの音声、およびテキスト データ。
最後のステップは、ASR (自動音声認識) タスクと AST (自動音声翻訳) タスクを微調整することです。事前トレーニングされた USM モデルに必要なのは、少量の監視データでも良好なパフォーマンスを達成できます。
USM 全体的なトレーニング プロセス
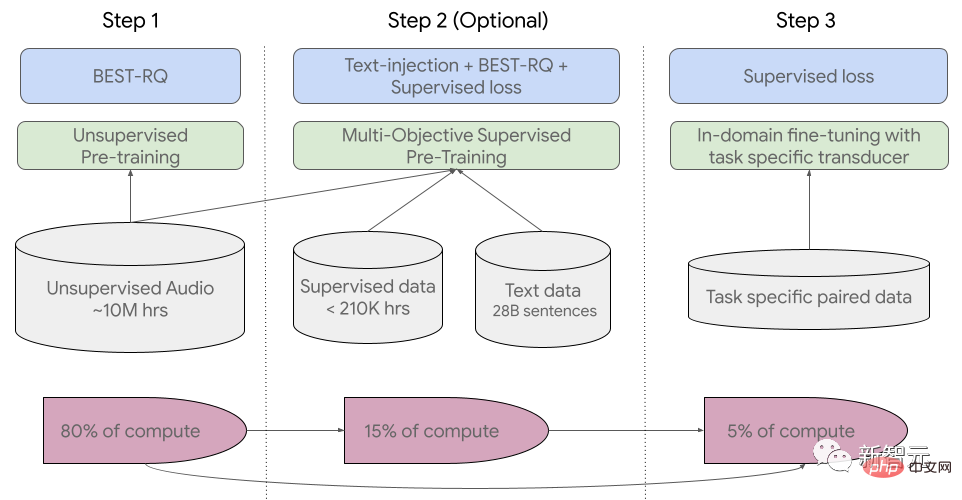
USM はどのように機能しますか? Google は、YouTube の字幕、ダウンストリーム ASR タスクの促進、および自動音声翻訳で USM をテストしました。
YouTube 多言語字幕でのパフォーマンス 監視付き YouTube データには 73 言語が含まれており、1 言語あたりのデータは平均 3,000 時間弱になります。監視データが限られているにも関わらず、このモデルは 73 言語にわたって平均単語誤り率 (WER) が 30% 未満を達成しました。これは、米国内の最先端のモデルよりも低い値です。 さらに、Google は、400,000 時間以上の注釈付きデータでトレーニングされた Whisper モデル (big-v2) と比較しました。 Whisper がデコードできる 18 言語のうち、デコード エラー率は 40% 未満ですが、USM の平均エラー率はわずか 32.7% です。 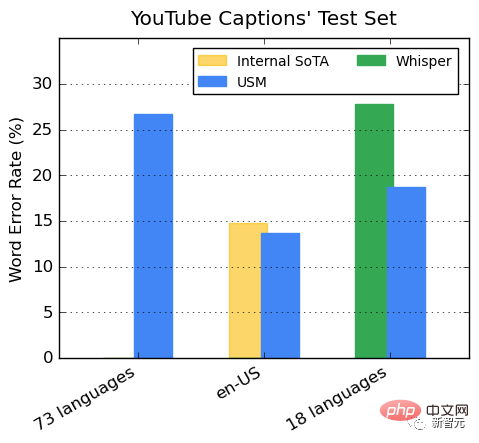
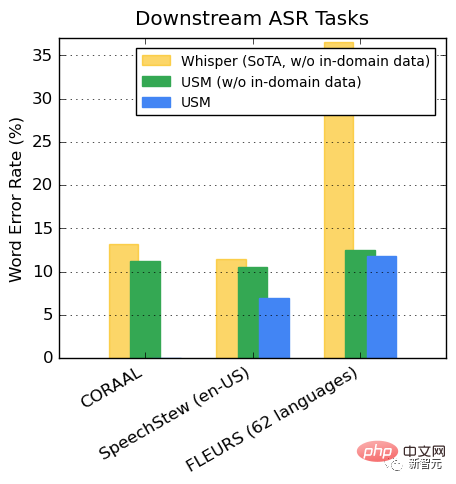
下流の ASR タスクの推進
公開されているデータセットでは、ドメイン内にあるかどうかに関係なく、USM は Whisper WER と比較して、CORAAL (アフリカ系アメリカ人の方言英語)、SpeechStew (英語 - 米国)、および FLEURS (102 言語) でパフォーマンスが低いことを示しています。トレーニングデータ。
#FLEURS の 2 つのモデルの違いは特に明らかです。
AST タスクのパフォーマンス
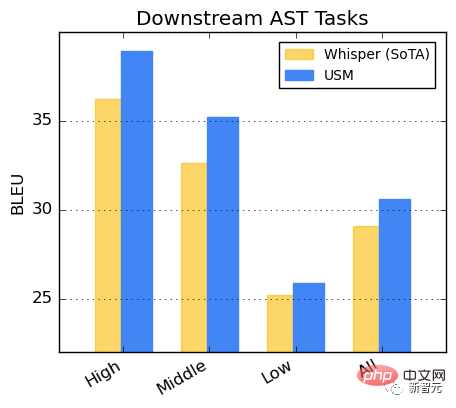
##CoVoST データセットでの USM の微調整。データセット内の言語を、リソースの可用性に応じて高、中、低の 3 つのカテゴリに分割し、BLEU スコアを計算します。各カテゴリ (高いほど良い) では、USM はどのカテゴリでも Whisper よりも優れたパフォーマンスを示します。
研究により、BEST-RQ 事前トレーニングが音声表現学習を大規模なデータセットに拡張する効果的な方法であることがわかりました。
MOST のテキスト インジェクションと組み合わせると、下流の音声タスクの品質が向上し、FLEURS および CoVoST 2 で最先端の結果が得られます。パフォーマンスのベンチマーク。
軽量の残留アダプター モジュールをトレーニングすることにより、MOST は新しいドメインに迅速に適応する能力を表します。これらの残りのアダプター モジュールはパラメーターを 2% 増加させるだけです。
#Google AR メガネ製品のリアルタイム翻訳も、将来的には多くのファンを魅了するでしょう。
#しかし、この技術の応用にはまだ長い道のりがあります。
#結局のところ、Google は世界に向けた IO 会議でのスピーチでも、アラビア語の文字を逆から書き、多くのネチズンの注目を集めました。
以上がOpenAIを再び打ち負かしましょう! Google、100以上の言語を自動的に認識して翻訳する20億パラメータのユニバーサルモデルをリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。