
ホームページ >テクノロジー周辺機器 >AI >ChatGPT と強化学習を使用して「Minecraft」をプレイ、Plan4MC が 24 の複雑なタスクを克服
ChatGPT と強化学習を使用して「Minecraft」をプレイ、Plan4MC が 24 の複雑なタスクを克服

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-25 08:37:061248ブラウズ
オープンな環境で複数のタスクを学習することは、汎用エージェントの重要な能力です。無限に生成される複雑な世界と多数のオープン タスクを備えた人気のオープンワールド ゲームである Minecraft は、近年、オープン ラーニング研究の重要なテスト環境となっています。
Minecraft で複雑なタスクを学習することは、現在の強化学習アルゴリズムにとって大きな課題です。一方で、エージェントは無限の世界で現地観察を通じて資源を探索し、探索の困難に直面します。一方、複雑なタスクは多くの場合、長い実行時間を必要とし、多くの暗黙的なサブタスクの完了を必要とします。たとえば、石のつるはしの作成には、木の伐採、木のつるはしの作成、原石の掘削など 10 を超えるサブタスクが含まれており、エージェントが完了するまでに数千のステップを実行する必要があります。エージェントはタスクを完了した場合にのみ報酬を受け取ることができ、まばらな報酬ではタスクを学習するのは困難です。

写真: Minecraft で石のつるはしを作るプロセス。
MineRL ダイヤモンド採掘競争に関する現在の研究では、一般に専門家によって実証されたデータセットが使用されていますが、VPT などの研究では多数のラベル付きデータ学習戦略が使用されています。追加のデータセットがない場合、強化学習を使用して Minecraft をトレーニングするタスクは非常に非効率的です。 MineAgent は、PPO アルゴリズムを使用していくつかの単純なタスクのみを完了できます。また、モデルベースの SOTA メソッド Dreamer-v3 では、環境シミュレーターを簡略化するときに原石の取得方法を学習するために 1,000 万ステップをサンプリングする必要があります。
北京大学と北京知源人工知能研究所のチームは、専門家のデータなしで Minecraft のマルチタスクを効率的に解決する方法である Plan4MC を提案しました。 。著者は強化学習と計画手法を組み合わせて、複雑なタスクの解決を基本スキルの学習とスキル計画の 2 つの部分に分解します。著者らは、内在的報酬強化学習法を使用して、3 種類のきめ細かい基本スキルを訓練します。エージェントは大規模な言語モデルを使用してスキル関係グラフを構築し、グラフ上の検索を通じてタスク計画を取得します。実験部分では、Plan4MC は現在 24 の複雑で多様なタスクを完了でき、成功率はすべてのベースライン手法と比較して大幅に向上しています。

- 論文リンク: https://arxiv.org/abs/2303.16563
- コード リンク: https://github.com/PKU-RL/Plan4MC
- プロジェクト ホームページ: https://sites.google.com/view/plan4mc
- 1. Minecraft マルチタスク
ワークベンチを初期化し、調理済みの牛肉を入手する」など、初期条件と対象項目の組み合わせとして定義されます。この課題を解決するには、「牛肉を入手する」「作業台と原石でかまどを作る」などのステップがあり、これらを細分化したステップをスキルと呼びます。人間は、それぞれのタスクを独立して学習するのではなく、このようなスキルを獲得し、組み合わせて、世界のさまざまなタスクを完了します。 Plan4MC の目標は、多数のスキルを習得するための戦略を学び、計画を通じてスキルをタスクに結合することです。
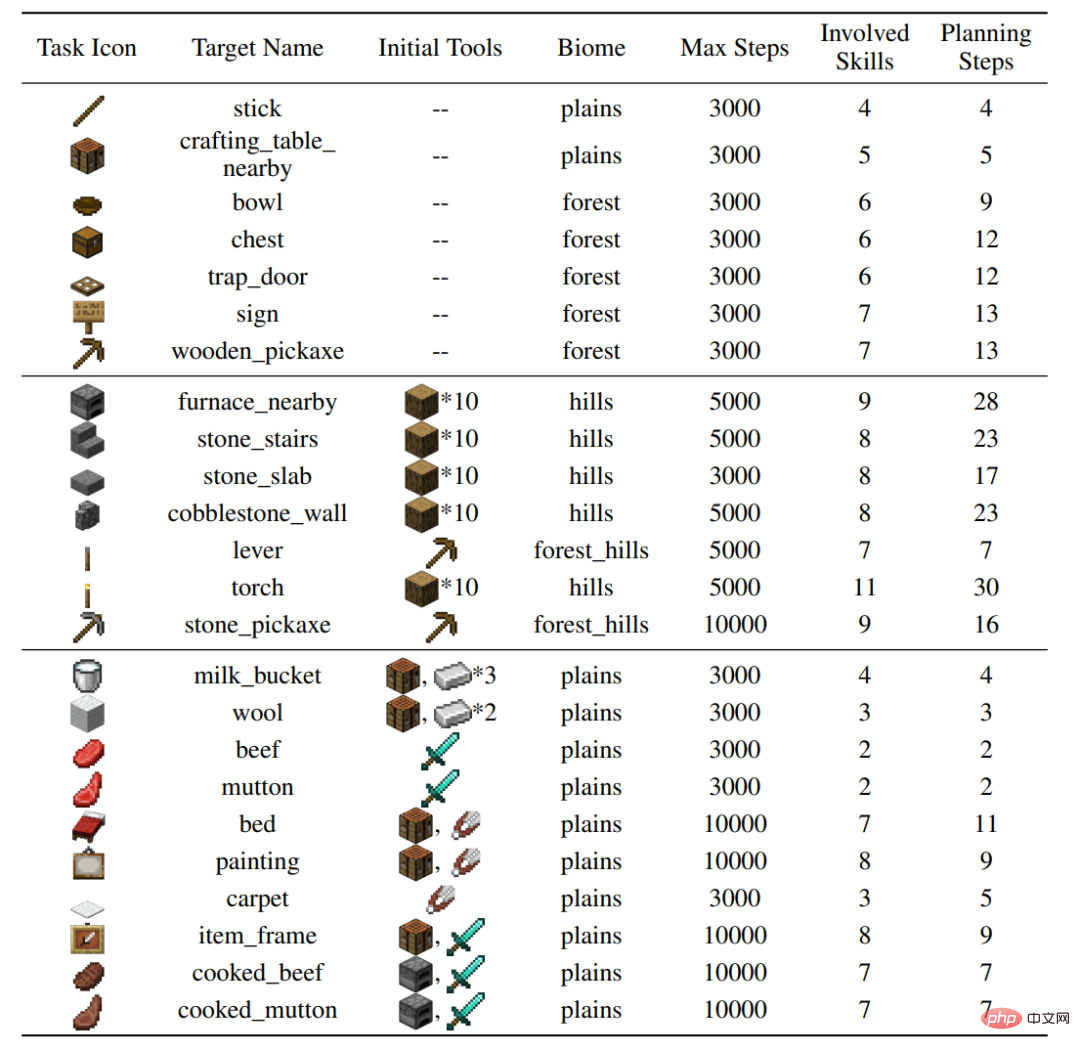
著者は、MineDojo シミュレーター上に 24 のテスト タスクを構築しました。これは、さまざまな行動 (木を切る、粗い岩を掘る、動物と対話する)、さまざまな地形をカバーし、37 のタスクが関係します。基本的なスキル。個々のタスクを完了するには、数十段階のスキルセットと数千段階の環境との相互作用が必要です。
2 、 Plan4MC メソッド
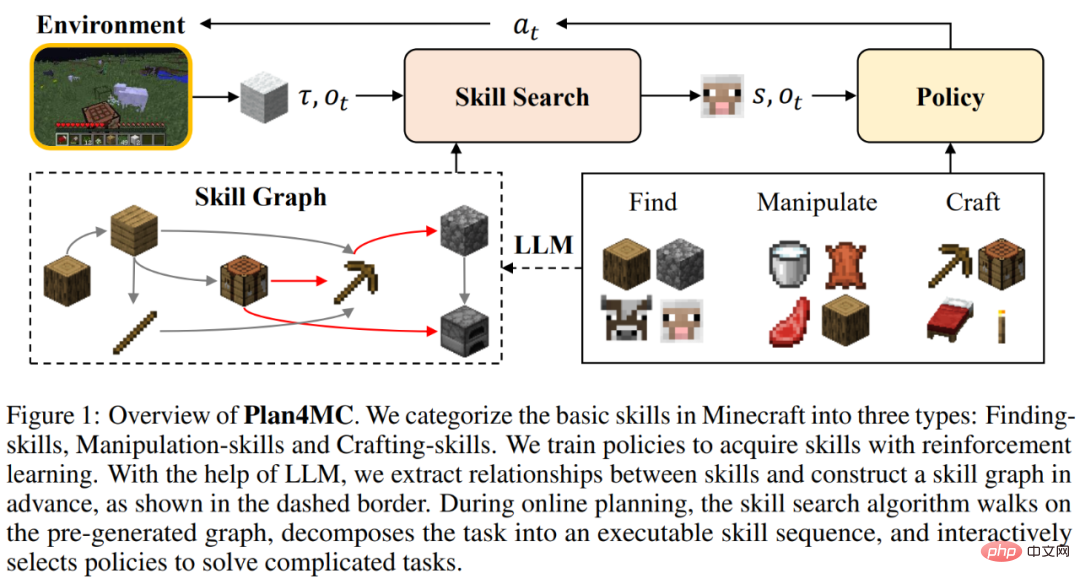
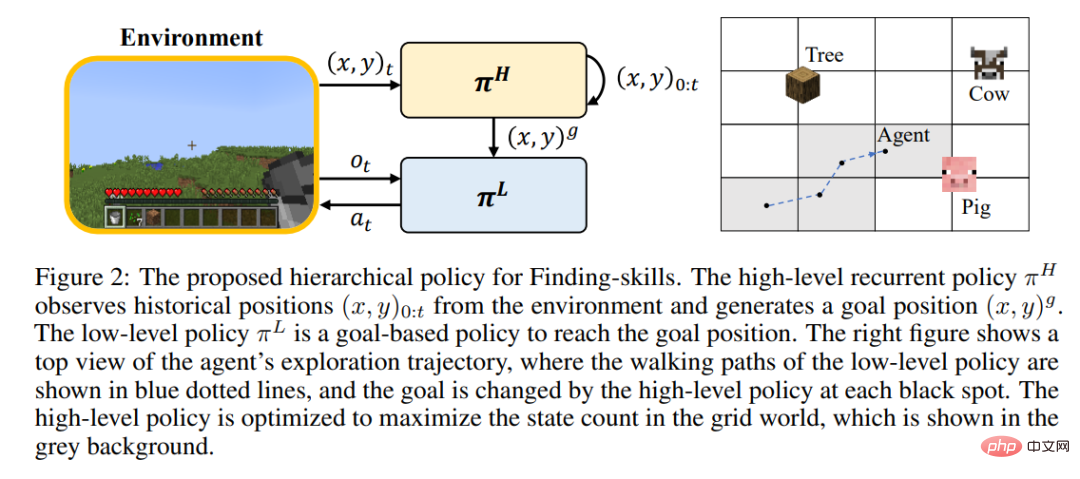
スキルの学習 強化学習により、プレーヤーがトレーニング中に大規模に世界を走ったり探索したりすることが困難になるため、多くのスキルはまだ習得できません。著者は、探索と探索のステップを分離し、「木を切る」スキルをさらに「木を見つける」と「木材を入手する」に洗練させることを提案しました。 Minecraft のすべてのスキルは、きめ細かい基本スキルの 3 つのカテゴリに分類されます。 著者は、スキルの種類ごとに、効率的な学習のための強化学習モデルと固有の報酬を設計します。探索スキルは階層的な戦略を使用しており、上位レベルの戦略はターゲットの場所を指定して探索範囲を拡大する役割を果たし、下位レベルの戦略はターゲット位置に到達する責任を負います。運用スキルは、PPO アルゴリズムと MineCLIP モデルの固有の報酬を組み合わせて使用してトレーニングされます。合成スキルは 1 つのアクションのみで完了します。修正されていない MineDojo シミュレーターでは、すべてのスキルを学習するのに必要な環境との対話のステップは 650 万ステップのみです。
計画アルゴリズム
Plan4MC 活用スキルたとえば、石のツルハシの入手と原石、木の棒、配置された作業台などのスキルの入手には次のような関係があることを考慮してください。

#作者は、大規模言語モデル ChatGPT と対話することですべてのスキル間の関係を生成し、スキル指向の非循環グラフを構築します。 。次の図に示すように、計画アルゴリズムはスキル グラフの深さ優先検索です。

3. 実験結果
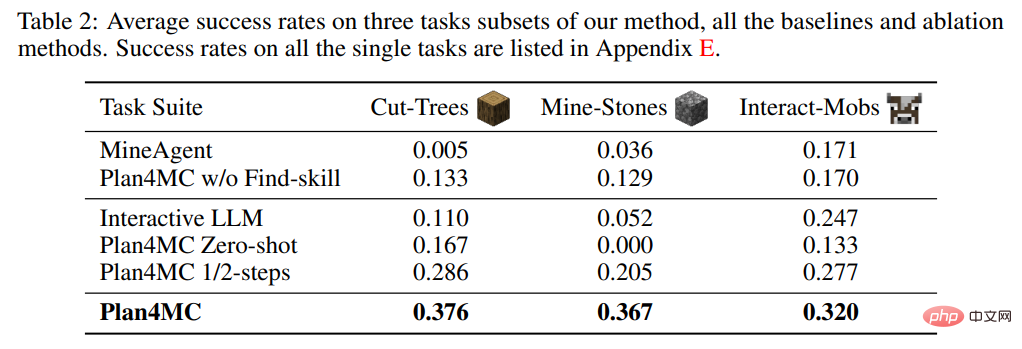
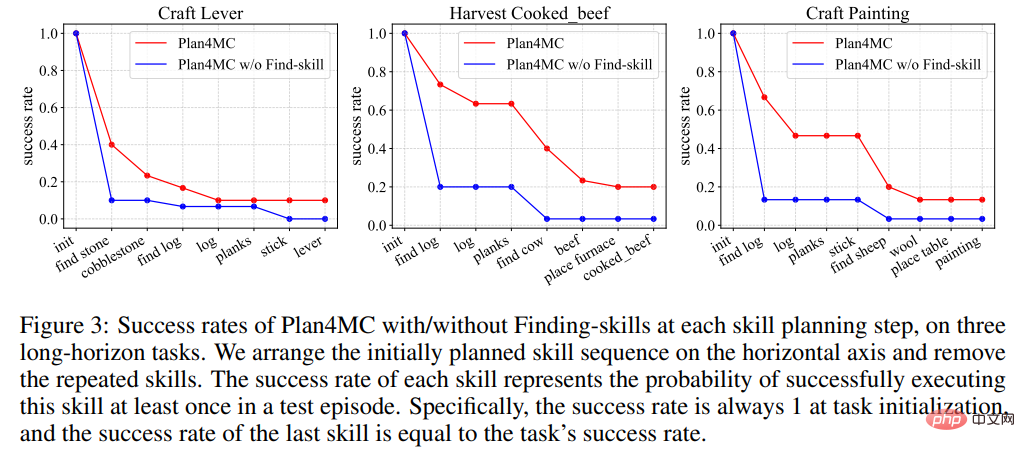
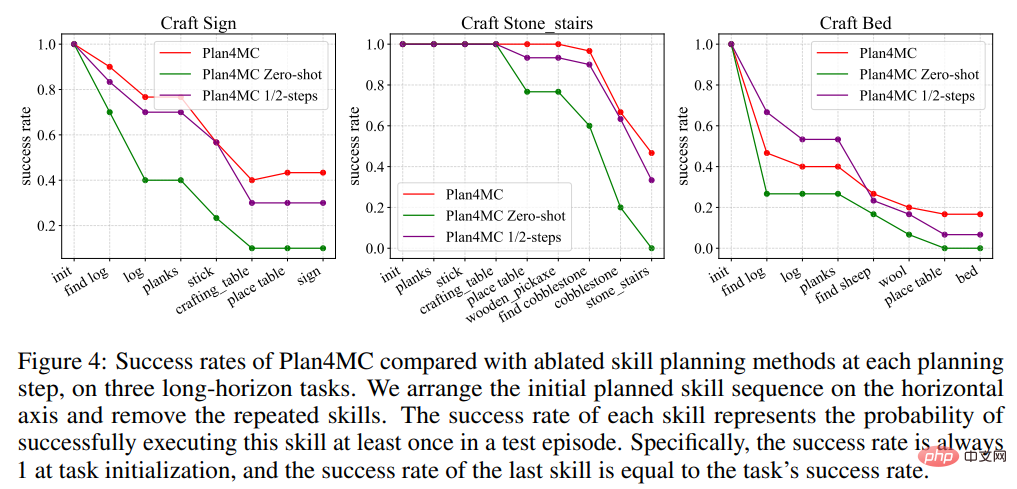
プランニングに関する研究では、対話型プランニングにChatGPTを用いたベースライン手法であるInteractive LLMと、スキル実行失敗時に再計画を行わないゼロショット手法とハーフショット手法の2つのアブレーション実験を紹介しました。 -使用されたメソッド 最大インタラクション ステップ数の 1/2 ステップ メソッド。表 2 は、Interactive LLM が動物との対話のタスク セットでは Plan4MC に近いパフォーマンスを示していますが、より多くの計画ステップが必要な他の 2 つのタスク セットではパフォーマンスが低いことを示しています。ゼロショット手法は、すべてのタスクでパフォーマンスが低下します。半分のステップ数での成功率は Plan4MC と比べてそれほど低くなく、Plan4MC の方が少ないステップ数で効率的にタスクを完了できるようです。
4. 概要
著者は、強化学習と計画を使用して Minecraft のマルチタスクを解決する Plan4MC を提案しました。探索の難易度とサンプル効率の問題を解決するために、著者は本質的報酬を備えた強化学習を使用して基本的なスキルをトレーニングし、大規模な言語モデルを使用してタスク計画のためのスキル グラフを構築します。著者らは、多数の困難な Minecraft タスクについて、ChatGPT を含むさまざまなベースライン手法と比較して、Plan4MC の利点を検証しました。
結論: 強化学習スキルの大規模言語モデル タスク計画には、ダニエル カーネマンが説明した System1/2 人間の意思決定モデルを実装できる可能性があります。
以上がChatGPT と強化学習を使用して「Minecraft」をプレイ、Plan4MC が 24 の複雑なタスクを克服の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。