



Python の組み込み型の詳細な理解 - dict
注: この記事は、チュートリアルに記録されたメモに基づいています。リンクが必要なため、内容の一部はチュートリアルと同じです。転載用に記入する必要がありますが、それはありませんので、オリジナルの内容を記入してください。違反がある場合は、直接削除されます。
「Python の組み込み型の詳細な理解」のこのセクションでは、Python で一般的に使用されるさまざまな組み込み型をソース コードの観点から紹介します。
dict は、日常の開発で最も一般的に使用される組み込み型の 1 つであり、Python 仮想マシンの操作も dict オブジェクトに大きく依存します。 dict の基礎知識をマスターすると、データ構造の基礎知識の理解や開発効率の向上などに役立つはずです。
1 実行効率
Java の Hashmap であっても、Python の dict であっても、どちらも非常に効率的なデータ構造です。ハッシュマップは、Java インタビューにおける基本的なテスト ポイントでもあります。配列、リンク リスト、および赤黒ツリー ハッシュ テーブルは、非常に時間効率が高くなります。同様に、Python の dict も、基礎となるハッシュ テーブル構造により、挿入、削除、検索などの操作の平均複雑さは O(1) (最悪の場合は O(n)) になります。ここでは list と dict を比較して、この 2 つの 検索効率 の違いがどれほど大きいかを確認します: (データは元の記事から取得したもので、自分でテストできます)
| コンテナ スケール | スケール増加係数 | 消費時間を辞書に出す | 消費時間の増加係数を辞書に出す | 消費時間をリストする | 時間のかかる成長係数をリストアップ |
|---|---|---|---|---|---|
| 1 | 0.000129s | 1 | 0.036s | 1 | |
| 10 | 0.000172s | 1.33 | 0.348s | 9.67 | |
| 100 | 0.000216s | 1.67 | 3.679s | 102.19 | |
| 1000 | 0.000382s | 2.96 | 48.044s | 1335.56 |
| 哈希表规模 | entries表规模 | 旧方案所需内存(B) | 新方案所需内存(B) | 节约内存(B) |
|---|---|---|---|---|
| 8 | 8 * 2/3 = 5 | 24 * 8 = 192 | 1 * 8 + 24 * 5 = 128 | 64 |
| 256 | 256 * 2/3 = 170 | 24 * 256 = 6144 | 1 * 256 + 24 * 170 = 4336 | 1808 |
| 65536 | 65536 * 2/3 = 43690 | 24 * 65536 = 1572864 | 2 * 65536 + 24 * 43690 = 1179632 | 393232 |
5 dict中哈希表
这一节主要介绍哈希函数、哈希冲突、哈希攻击以及删除操作相关的知识点。
5.1 哈希函数
根据哈希表性质,键对象必须满足以下两个条件,否则哈希表便不能正常工作:
i. 哈希值在对象的整个生命周期内不能改变
ii. 可比较,并且比较结果相等的两个对象的哈希值必须相同
满足这两个条件的对象便是可哈希(hashable)对象,只有可哈希对象才可作为哈希表的键。因此,像dict、set等底层由哈希表实现的容器对象,其键对象必须是可哈希对象。在Python的内建类型中,不可变对象都是可哈希对象,而可变对象则不是:
>>> hash([])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
hash([])
TypeError: unhashable type: 'list'dict、list等不可哈希对象不能作为哈希表的键:
>>> {[]: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
{[]: 'list is not hashable'}
TypeError: unhashable type: 'list'
>>> {{}: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
{{}: 'list is not hashable'}
TypeError: unhashable type: 'dict'而用户自定义的对象默认便是可哈希对象,对象哈希值由对象地址计算而来,且任意两个不同对象均不相等:
>>> class A:
pass
>>> a = A()
>>> b = A()
>>> hash(a), hash(b)
(160513133217, 160513132857)
>>>a == b
False
>>> a is b
False那么,哈希值是如何计算的呢?答案是——哈希函数。哈希值计算作为对象行为的一种,会由各个类型对象的tp_hash指针指向的哈希函数来计算。对于用户自定义的对象,可以实现__hash__()魔法方法,重写哈希值计算方法。
5.2 哈希冲突
理想的哈希函数必须保证哈希值尽量均匀地分布于整个哈希空间,越是接近的值,其哈希值差别应该越大。而一方面,不同的对象哈希值有可能相同;另一方面,与哈希值空间相比,哈希表的槽位是非常有限的。因此,存在多个键被映射到哈希索引同一槽位的可能性,这就是哈希冲突。
-
解决哈希冲突的常用方法有两种:
i. 链地址法(seperate chaining)
ii. 开放定址法(open addressing)
为每个哈希槽维护一个链表,所有哈希到同一槽位的键保存到对应的链表中
这是Python采用的方法。将数据直接保存于哈希槽位中,如果槽位已被占用,则尝试另一个。一般而言,第i次尝试会在首槽位基础上加上一定的偏移量di。因此,探测方法因函数di而异。常见的方法有线性探测(linear probing)以及平方探测(quadratic probing)
线性探测:di是一个线性函数,如:di = 2 * i
平方探测:di是一个二次函数,如:di = i ^ 2
线性探测和平方探测很简单,但同时也存在一定的问题:固定的探测序列会加大冲突的概率。Python对此进行了优化,探测函数参考对象哈希值,生成不同的探测序列,进一步降低哈希冲突的可能性。Python探测方法在lookdict()函数中实现,关键代码如下:
static Py_ssize_t _Py_HOT_FUNCTION
lookdict(PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject **value_addr)
{
size_t i, mask, perturb;
PyDictKeysObject *dk;
PyDictKeyEntry *ep0;
top:
dk = mp->ma_keys;
ep0 = DK_ENTRIES(dk);
mask = DK_MASK(dk);
perturb = hash;
i = (size_t)hash & mask;
for (;;) {
Py_ssize_t ix = dk_get_index(dk, i);
// 省略键比较部分代码
// 计算下个槽位
// 由于参考了对象哈希值,探测序列因哈希值而异
perturb >>= PERTURB_SHIFT;
i = (i*5 + perturb + 1) & mask;
}
Py_UNREACHABLE();
}源码分析:第20~21行,探测序列涉及到的参数是与对象的哈希值相关的,具体计算方式大家可以看下源码,这里我就不赘述了。
5.3 哈希攻击
Python在3.3之前,哈希算法只根据对象本身计算哈希值。因此,只要Python解释器相同,对象哈希值也肯定相同。执行Python2解释器的两个交互式终端,示例如下:(来自原文章)
>>> import os >>> os.getpid() 2878 >>> hash('fashion') 3629822619130952182
>>> import os >>> os.getpid() 2915 >>> hash('fashion') 3629822619130952182
如果我们构造出大量哈希值相同的key,并提交给服务器:例如向一台Python2Web服务器post一个json数据,数据包含大量的key,这些key的哈希值均相同。这意味哈希表将频繁发生哈希冲突,性能由O(1)直接下降到了O(n),这就是哈希攻击。
-
产生上述问题的原因是:Python3.3之前的哈希算法只根据对象本身来计算哈希值,这样会导致攻击者很容易构建哈希值相同的key。于是,Python之后在计算对象哈希值时,会加盐。具体做法如下:
i. Python解释器进程启动后,产生一个随机数作为盐
ii. 哈希函数同时参考对象本身以及盐计算哈希值
这样一来,攻击者无法获知解释器内部的随机数,也就无法构造出哈希值相同的对象了。
5.4 删除操作
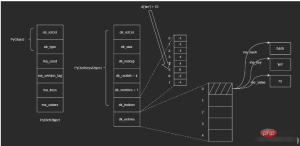
示例:向dict依次插入三组键值对,键对象依次为key1、key2、key3,其中key2和key3发生了哈希冲突,经过处理后重新定位到dk_indices[6]的位置。图示如下:

如果要删除key2,假设我们将key2对应的dk_indices[1]设置为-1,那么此时我们查询key3时就会出错——因为key3初始对应的操作就是dk_indices[1],只是发生了哈希冲突蔡最终分配到了dk_indices[6],而此时dk_indices[1]的值为-1,就会导致查询的结果是key3不存在。因此,在删除元素时,会将对应的dk_indices设置为一个特殊的值DUMMY,避免中断哈希探索链(也就是通过标志位来解决,很常见的做法)。
哈希槽位状态常量如下:
#define DKIX_EMPTY (-1) #define DKIX_DUMMY (-2) /* Used internally */ #define DKIX_ERROR (-3)
对于被删除元素在dk_entries中对应的存储单元,Python是不做处理的。假设此时再插入key4,Python会直接使用dk_entries[3],而不会使用被删除的key2所占用的dk_entries[1]。这里会存在一定的浪费。
5.5 问题
删除操作不会将dk_entries中的条目回收重用,随着插入地进行,dk_entries最终会耗尽,Python将创建一个新的PyDictKeysObject,并将数据拷贝过去。新PyDictKeysObject尺寸由GROWTH_RATE宏计算。这里给大家简单列下源码:
static int
dictresize(PyDictObject *mp, Py_ssize_t minsize)
{
/* Find the smallest table size > minused. */
for (newsize = PyDict_MINSIZE;
newsize < minsize && newsize > 0;
newsize <<= 1)
;
// ...
}源码分析:
如果此前发生了大量删除(没记错的话是可用个数为0时才会缩容,这里大家可以自行看下源码),剩余元素个数减少很多,PyDictKeysObject尺寸就会变小,此时就会完成缩容(大家还记得前面提到过的dk_usable,dk_nentries等字段吗,没记错的话它们在这里就发挥作用了,大家可以自行看下源码)。总之,缩容不会在删除的时候立刻触发,而是在当插入并且dk_entries耗尽时才会触发。
函数dictresize()的参数Py_ssize_t minsize由GROWTH_RATE宏传入:
#define GROWTH_RATE(d) ((d)->ma_used*3)
static int
insertion_resize(PyDictObject *mp)
{
return dictresize(mp, GROWTH_RATE(mp));
}这里的for循环就是不断对newsize进行翻倍变化,找到大于minsize的最小值
扩容时,Python分配新的哈希索引数组和键值对数组,然后将旧数组中的键值对逐一拷贝到新数组,再调整数组指针指向新数组,最后回收旧数组。这里的拷贝并不是直接拷贝过去,而是逐个插入新表的过程,这是因为哈希表的规模改变了,相应的哈希函数值对哈希表长度取模后的结果也会变化,所以不能直接拷贝。
以上がPython組み込み型辞書ソースコード解析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Pythonアレイで実行できる一般的な操作は何ですか?Apr 26, 2025 am 12:22 AM
Pythonアレイで実行できる一般的な操作は何ですか?Apr 26, 2025 am 12:22 AMPythonArraysSupportVariousoperations:1)SlicingExtractsSubsets、2)Appending/ExtendingAdddesements、3)inSertingSelementSatspecificpositions、4)remvingingDeletesements、5)sorting/verversingsorder、and6)listenionsionsionsionsionscreatenewlistsebasedexistin
 一般的に使用されているnumpy配列はどのようなアプリケーションにありますか?Apr 26, 2025 am 12:13 AM
一般的に使用されているnumpy配列はどのようなアプリケーションにありますか?Apr 26, 2025 am 12:13 AMnumpyarraysAressertialentionsionceivationsefirication-efficientnumericalcomputations andDatamanipulation.theyarecrucialindatascience、mashineelearning、物理学、エンジニアリング、および促進可能性への適用性、scaledatiencyを効率的に、forexample、infinancialanalyyy
 Pythonのリスト上の配列を使用するのはいつですか?Apr 26, 2025 am 12:12 AM
Pythonのリスト上の配列を使用するのはいつですか?Apr 26, 2025 am 12:12 AMUseanArray.ArrayOverAlistinPythonは、Performance-criticalCode.1)homogeneousdata:araysavememorywithpedelements.2)Performance-criticalcode:Araysofterbetterbetterfornumerumerumericaleperations.3)interf
 すべてのリスト操作は配列でサポートされていますか?なぜまたはなぜですか?Apr 26, 2025 am 12:05 AM
すべてのリスト操作は配列でサポートされていますか?なぜまたはなぜですか?Apr 26, 2025 am 12:05 AMいいえ、notallistoperationSaresuptedbyarrays、andviceversa.1)arraysdonotsupportdynamicoperationslikeappendorintorintorinsertizizing、whosimpactsporformance.2)リスト
 Pythonリストの要素にどのようにアクセスしますか?Apr 26, 2025 am 12:03 AM
Pythonリストの要素にどのようにアクセスしますか?Apr 26, 2025 am 12:03 AMtoaccesselementsinapythonlist、useindexing、negativeindexing、slicing、oriteration.1)indexingstartsat0.2)negativeindexingAcsesess.3)slicingextractStions.4)reterationSuseSuseSuseSuseSeSeS forLoopseCheckLentlentlentlentlentlentlenttodExeror。
 Pythonを使用した科学コンピューティングでアレイはどのように使用されていますか?Apr 25, 2025 am 12:28 AM
Pythonを使用した科学コンピューティングでアレイはどのように使用されていますか?Apr 25, 2025 am 12:28 AMArraysinpython、特にvianumpy、arecrucialinscientificComputing fortheirefficienty andversitility.1)彼らは、fornumericaloperations、data analysis、andmachinelearning.2)numpy'simplementation incensuresfasteroperationsthanpasteroperations.3)arayableminablecickick
 同じシステムで異なるPythonバージョンをどのように処理しますか?Apr 25, 2025 am 12:24 AM
同じシステムで異なるPythonバージョンをどのように処理しますか?Apr 25, 2025 am 12:24 AMPyenv、Venv、およびAnacondaを使用して、さまざまなPythonバージョンを管理できます。 1)Pyenvを使用して、複数のPythonバージョンを管理します。Pyenvをインストールし、グローバルバージョンとローカルバージョンを設定します。 2)VENVを使用して仮想環境を作成して、プロジェクトの依存関係を分離します。 3)Anacondaを使用して、データサイエンスプロジェクトでPythonバージョンを管理します。 4)システムレベルのタスク用にシステムPythonを保持します。これらのツールと戦略を通じて、Pythonのさまざまなバージョンを効果的に管理して、プロジェクトのスムーズな実行を確保できます。
 標準のPythonアレイでnumpyアレイを使用することの利点は何ですか?Apr 25, 2025 am 12:21 AM
標準のPythonアレイでnumpyアレイを使用することの利点は何ですか?Apr 25, 2025 am 12:21 AMnumpyarrayshaveveraladvantages-averstandardpythonarrays:1)thealmuchfasterduetocベースのインプレンテーション、2)アレモレメモリ効率、特にlargedatasets、および3)それらは、拡散化された、構造化された形成術科療法、


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター
ホットトピック
 7724
7724 15164314139752129025123329
15164314139752129025123329