
ホームページ >テクノロジー周辺機器 >AI >「MiniGPT-4 は、その驚くべき画像認識能力と複数の機能を証明しています。画像によるチャット、スケッチによる Web サイトの構築など。」
「MiniGPT-4 は、その驚くべき画像認識能力と複数の機能を証明しています。画像によるチャット、スケッチによる Web サイトの構築など。」

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-24 11:16:151005ブラウズ
人間にとって絵の情報を理解することは些細なことであり、何も考えずに絵の意味を何気なく伝えることができます。下の写真のように、携帯電話が接続されている充電器はやや不適切です。人間なら一目で問題が分かるが、AIにとってはまだ非常に難しい。
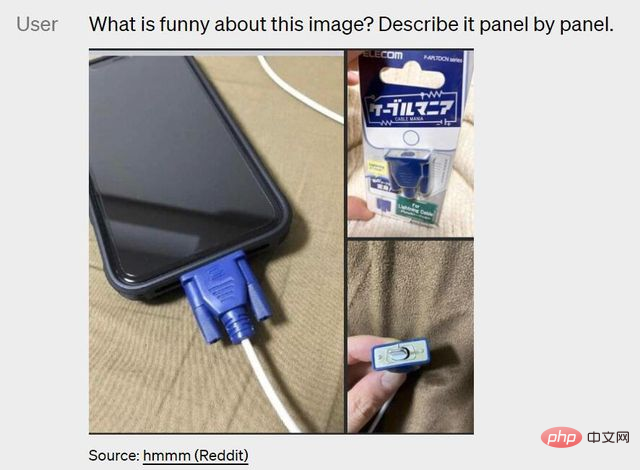
GPT-4 の登場により、これらの問題が簡素化され始め、次のような問題をすぐに指摘できるようになります: VGA ケーブルによる iPhone の充電。
実のところ、GPT-4 の魅力はこれだけではありません。さらに魅力的なのは、手描きのスケッチを使用して Web サイトを直接生成し、その上に走り書きの図を描くことです。原稿を書き、写真を撮って送信します。 GPT-4 を与えて、図に従って Web サイトのコードを書き込ませます。おお、GPT-4 が Web ページのコードを書き込みます。
しかし、残念ながらGPT-4のこの機能はまだ一般公開されておらず、実際に使い始めて体験することはできません。しかし、これ以上待ちきれない人もおり、キング アブドラ科学技術大学 (KAUST) のチームが GPT-4 と同様の製品である MiniGPT-4 を開発しました。チームの研究者には、Zhu Deyao、Chen Jun、Shen Xiaoqian、Li Xiang、Mohamed H. Elhoseiny が含まれており、全員が KAUST の Vision-CAIR 研究グループの出身です。

- 論文アドレス: https://github.com/Vision-CAIR/MiniGPT- 4 /blob/main/MiniGPT_4.pdf
- Paper ホームページ: https://minigpt-4.github.io/
- コードアドレス: https://github.com/Vision-CAIR/MiniGPT-4
MiniGPT-4 写真を見るだけで話しやすい
MiniGPT-4の効果は何ですか?いくつかの例から始めましょう。さらに、MiniGPT-4 をより良く使用するために、テストには英語入力を使用することをお勧めします。まず、MiniGPT-4 の画像記述機能を調べてみましょう。左側の写真について、MiniGPT-4 が出した答えはおおよそ次のとおりです。「この写真は、凍った湖の上で成長するサボテンを描いています。サボテンの周りには巨大な氷の結晶があり、遠くには雪を頂いた山々があります...」 「このシナリオは現実世界で起こり得るでしょうか?」と尋ねると、 MiniGPT-4 が出した答えは、この画像は現実世界では一般的ではない、そしてその理由です。


## MiniGPT-4 を使用すると、写真に広告スローガンを書くことが非常に簡単になりました。 MiniGPT-4 に、左側のカップの広告コピーを書いてもらいます。 MiniGPT-4 は、コーヒー愛好家や猫愛好家に最適なカップ上の眠そうな猫のパターンを正確に指摘し、カップの素材なども指摘しました。  MiniGPT-4 は写真に基づいてレシピを生成することもでき、あなたをキッチンの専門家に変えます:
MiniGPT-4 は写真に基づいてレシピを生成することもでき、あなたをキッチンの専門家に変えます:
 人気のミームについて説明します:
人気のミームについて説明します:
## 写真に基づいて詩を書きます: 
さらに、MiniGPT-4 デモが公開されており、オンラインでプレイできることにも言及する価値があります。実際に体験してみることもできます(英語テストの利用をお勧めします): 
##デモアドレス: https:// 0810e8582bcad31944.gradio.live/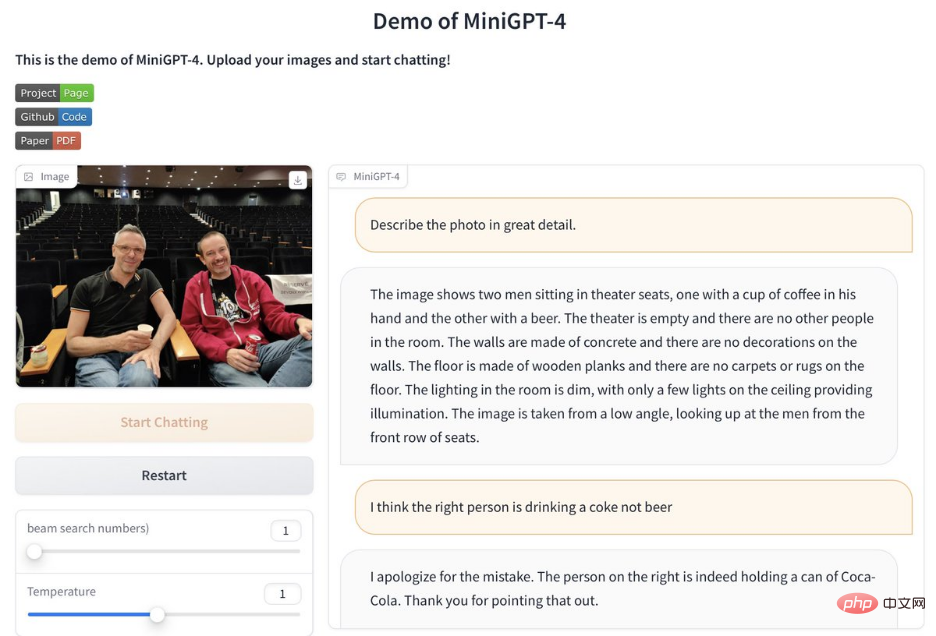
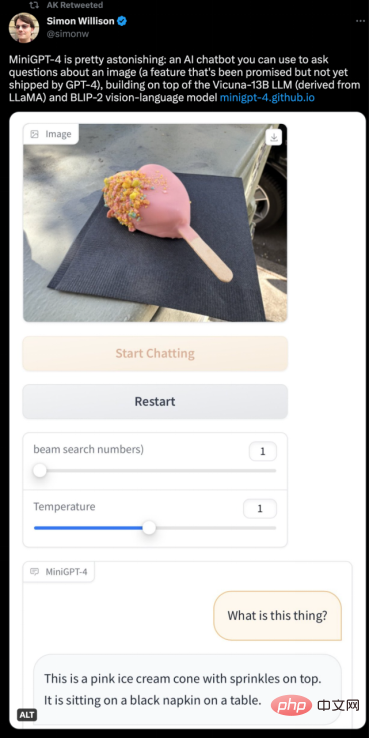
このプロジェクトが公開されると、ネチズンから幅広い注目を集めました。たとえば、MiniGPT-4 で写真内のオブジェクトを説明してみましょう:
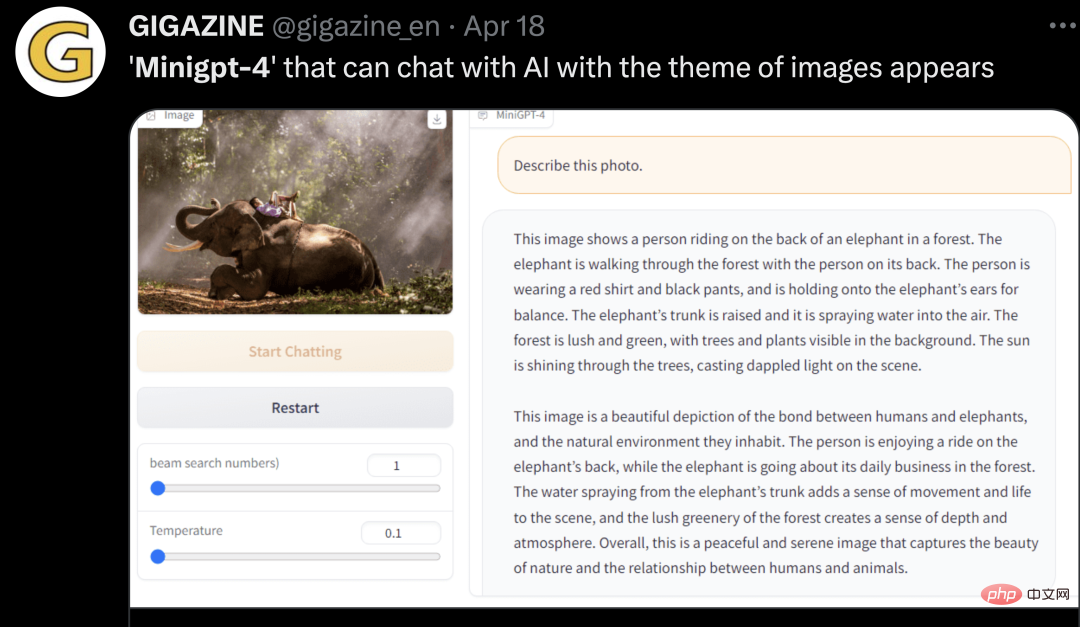
##ネチズンからのその他のテスト体験は以下の通りです:
 ##メソッドの紹介
##メソッドの紹介
Author It GPT-4 の高度なラージ言語モデル (LLM) が、その高度なマルチモーダル生成機能の主な理由であると考えられています。この現象を研究するために、著者らは、投影層を使用してフリーズされたビジュアル エンコーダとフリーズされた LLM (Vicuna) を位置合わせする MiniGPT-4 を提案しています。
#MiniGPT-4 は 2 段階でトレーニングされました。最初の従来の事前トレーニング段階では、約 500 万個の位置合わせされた画像とテキストのペアを使用して 4 つの A100 GPU でトレーニングするのに 10 時間かかりました。最初の段階の後、ビクーニャは画像を理解できるようになりました。しかし、Vicuna のテキスト生成能力は大きな影響を受けました。
この問題を解決し、使いやすさを向上させるために、研究者は、モデル自体と ChatGPT を通じて高品質の画像とテキストのペアを作成する新しい方法を提案しました。これに基づいて、研究では小規模だが高品質のデータセット (合計 3500 ペア) を作成しました。 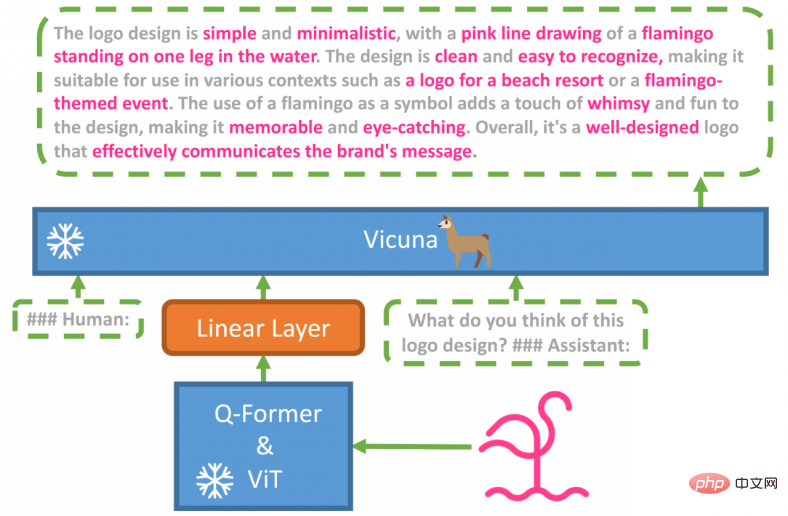
2 番目の微調整ステージは、会話テンプレートを使用してこのデータセットでトレーニングされ、生成の信頼性と全体的な使いやすさが大幅に向上します。このステージは計算効率が高く、A100GPU を必要とするだけで完了までに約 7 分かかります。
その他の関連作品:
- VisualGPT: https://github.com/Vision-CAIR/VisualGPT
- ChatCaptioner: https://github.com/Vision-CAIR/ChatCaptioner
さらに、BLIP2 などのオープンソース コード ライブラリも使用されますプロジェクトでは、ラヴィスとビクーニャ。
以上が「MiniGPT-4 は、その驚くべき画像認識能力と複数の機能を証明しています。画像によるチャット、スケッチによる Web サイトの構築など。」の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。