
ホームページ >テクノロジー周辺機器 >AI >技術分析と実践の共有: デュアルエンジン GPU コンテナ仮想化におけるユーザー モードとカーネル モード
技術分析と実践の共有: デュアルエンジン GPU コンテナ仮想化におけるユーザー モードとカーネル モード

- 王林転載
- 2023-04-23 15:40:101194ブラウズ
ハードウェアのコンピューティング能力の効率を最大化する方法は、すべてのリソース オペレーターとユーザーにとって大きな関心事です。 AI の大手企業である Baidu は、おそらく業界で最も包括的な AI アプリケーション シナリオを持っています。
この記事では、複雑な AI シナリオにおける GPU コンテナー仮想化ソリューションと工場内のベスト プラクティスについて共有し、説明します。
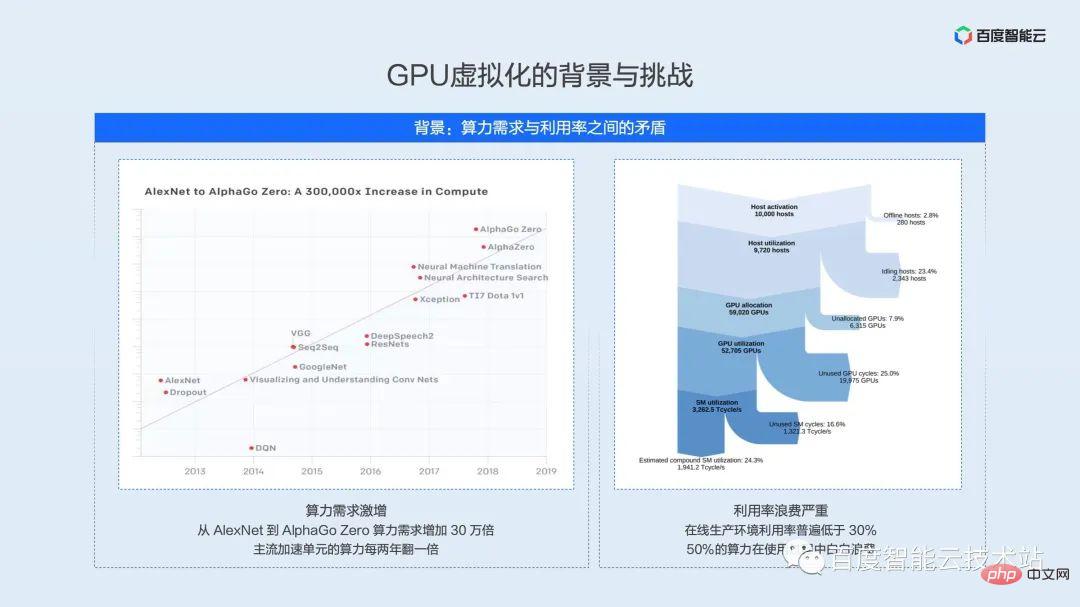
下の図の左側と右側の部分は、さまざまな機会に何度も示されています。これらをここに置く主な目的は、コンピューティング パワーの需要、つまりハードウェアのコンピューティング パワーとその使用率の指数関数的な増加を強調することです。実際のアプリケーションシナリオでは、効率の低さとリソースの無駄の間の矛盾。
左側の部分は OpenAI からの統計です。2012 年以来、モデルのトレーニングに必要な計算能力は 3.4 か月ごとに 2 倍になっています。AlphaGoZero のような大規模なモデルでは、トレーニングの計算能力が増加しています。300,000 倍、そしてその傾向は続いています。一方で、コンピューティング能力の需要が高まるにつれて、主流の AI アクセラレーション ユニットのコンピューティング パフォーマンスも 2 年ごとに 2 倍になっています。一方で、リソースの利用効率により、ハードウェアのパフォーマンスを最大限に活用することが制限されます。
右側の部分は、2021 年の Facebook のデータセンター機械学習負荷分析の結果です。障害、スケジューリング、タイム スライスの無駄、スペース ユニットの無駄などのリンクで AI のコンピューティング能力が大量に失われ、実際のコンピューティング能力の使用率は 30% 未満です。これは国内大手インフラ事業者の現状でもあると考えております。
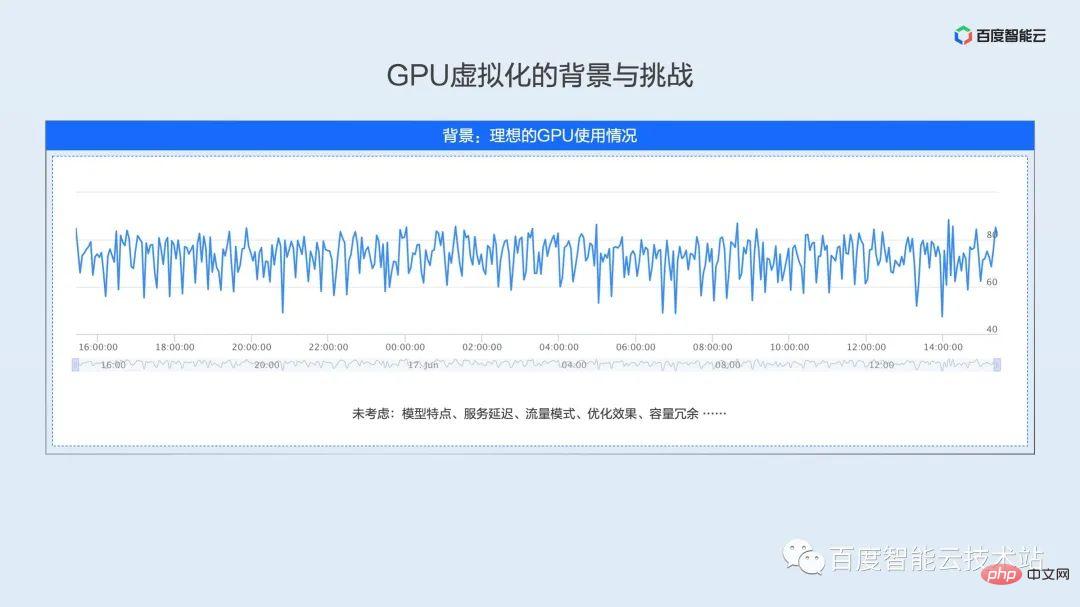
先ほど、オンライン クラスターの利用率が 30% 未満であると述べましたが、これは多くの学生の認識と一致しない可能性があります。オンラインの学生の多くはモデルやアルゴリズムの開発者である可能性があります。私たちの一般的な理解では、トレーニング中やテスト中に使用率が非常に高い状態を維持し、使用率が 100% に達することもあります。
しかし、モデルが実稼働環境で起動されると、多くの制約を受けることになり、これらの制約により、使用率が予想を大きく下回ります。
限られたスペースを使って主な制約を要約しましょう:
- モデルの特性: 各モデル ネットワークは異なり、呼び出される基礎となる演算子の組み合わせも異なります。 GPU 使用率に影響します。
- サービス SLA: さまざまなシナリオのサービスには、さまざまな SLA が必要です。一部のサービスには高いリアルタイム要件があり、10 ミリ秒以内に厳密に制御する必要さえあります。その場合、これらのサービスは、バッチサイズを増やしても使用率を向上させることはできません。バッチサイズでさえ、使用率を向上させることはできません。 1.
- トラフィック パターン: さまざまなモデル アルゴリズムが、作業中に頻繁に呼び出される OCR 認識などのさまざまなアプリケーション シナリオに対応します。音声認識は、通勤時間や娯楽やレジャー中に呼び出されることが多く、そのため 1 日を通して GPU 使用率の山と谷の変動が生じます。
- 最適化効果: モデルの反復頻度とさまざまなカバレッジ シナリオに応じて、モデルの最適化の粒度も異なります。最適化が不十分なモデルの利用率は高い水準に達することが難しいと考えられます。
- 容量の冗長性: モデルをオンラインにする前に、最大トラフィックはいくらか、複数のリージョンが必要かどうかなど、詳細な容量計画を実行する必要があります。このプロセスでは、無視することが困難な容量の冗長性が確保されます。これらの冗長性は通常、平常時に使用されますが、計算能力の無駄も発生します。
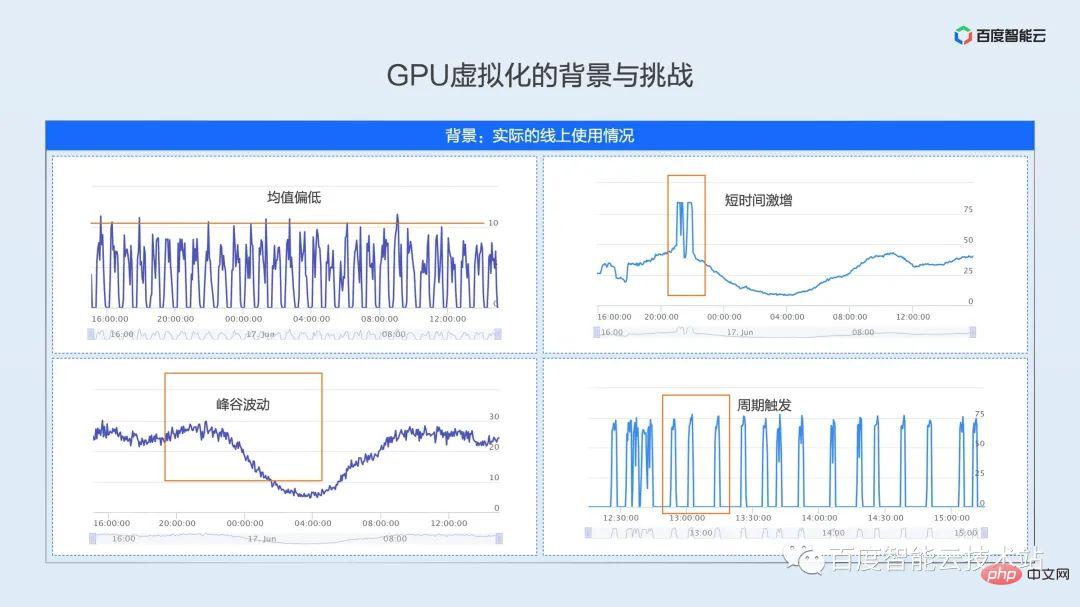
上記の制約の下で、実際の運用環境の使用率が次に表示したいものになる可能性があります。私たちは、複雑で変化するオンライン制作環境からこれらの利用パターンを抽象化します。
- 低平均型: 左上図に示すように、本格的なオンライン推論ビジネスですが、モデル特性とサービス SLA の制限により、GPU のピーク使用率はわずか 10% であり、平均使用率はさらに低くなります。
- 山谷変動型:下図左図のように、日中にサービスがピークに達し、利用率が低下するオンライン推論ビジネスの典型的な利用パターンです。稼働率が低いのは深夜から翌朝までで、1日の平均稼働率は20%程度で、低い稼働率は10%未満です。
- 短期サージ タイプ: 右上の図に示すように、使用率曲線は基本的に左下の図と一致していますが、夜間のゴールデンタイムに 2 つの明らかな使用率のピークがあり、ピーク使用率は 80% と高く、ピーク時のサービス品質を満たすために、サービスは導入プロセス中に大きなバッファを確保し、平均リソース使用率は 30% 強です。
- 定期トリガータイプ: 右下の図に示すように、典型的なオンライン トレーニング シナリオの利用モードです。オンライン トレーニング タスクは、オフライン トレーニングとオンライン推論の間にあります。これは定期的なバッチ処理です。タスク。たとえば、データのバッチは 15 分ごとに到着しますが、このデータのバッチのトレーニングには 2 ~ 3 分しかかからず、GPU は長時間アイドル状態になります。
AI アプリケーションのシナリオは複雑で変化しやすいため、上記では代表的なシナリオを 4 つだけ挙げています。複雑なシナリオでビジネス パフォーマンスとリソース効率のバランスを取る方法は、GPU 仮想化で最初に直面する課題です。
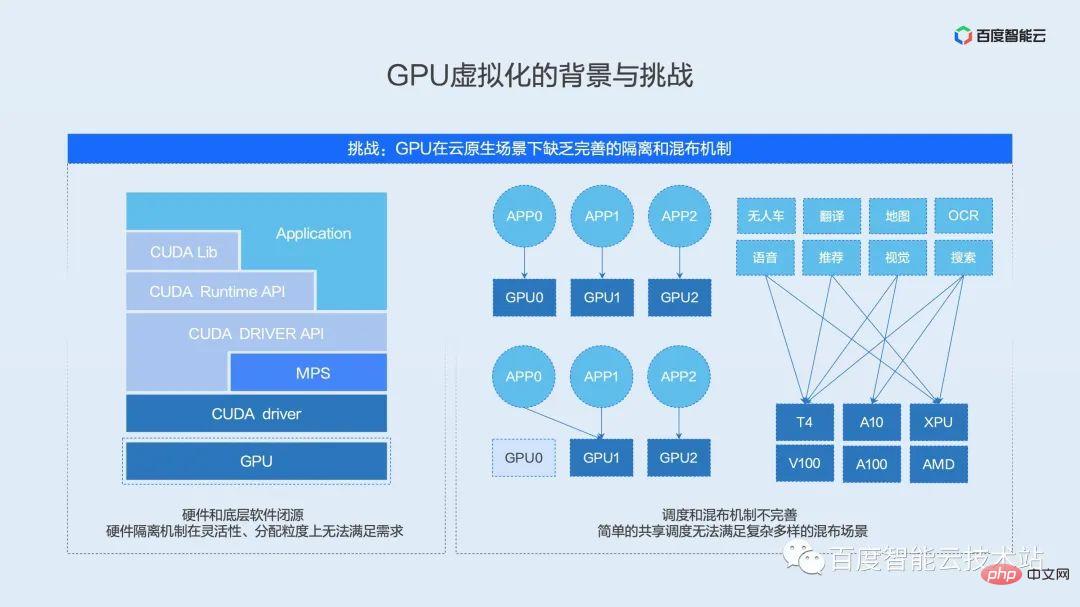
#GPU 仮想化中に直面する 2 番目の課題は、完全な GPU 分離および混合メカニズムが欠如していることです。
現在の主流の NVIDIA GPU を例として取り上げます。一般的な AI ソフトウェアとハードウェアのエコシステムは、アプリケーションとフレームワーク層、ランタイム層、ドライバー層、ハードウェア層のいくつかのレベルに分かれています。
まず第一に、最上位層はユーザーのアプリケーションであり、これには PaddlePaddle、TensorFlow、PyTorch などのさまざまな一般的なフレームワークが含まれています。アプリケーション層の下には、さまざまな共通オペレーター・ライブラリーやハードウェア・ランタイム・アクセス・インターフェースなど、ハードウェア・プロバイダーによってカプセル化された API インターフェース層があります。 API インターフェイスのこの層の下には、ハードウェアと通信するドライバー層があり、この層はカーネル状態に位置し、デバイスと直接通信するソフトウェア インターフェイス層です。一番下には、オペレーターの実行を担当する実際の AI アクセラレーション ハードウェアがあります。
従来の仮想化ソリューションは、ドライバーのカーネル状態とハードウェア仮想化ロジックと組み合わせて実装されます。これら 2 つのレベルはハードウェア プロバイダーのコア IP であり、通常はクローズド ソースです。後述するように、現在の GPU ネイティブ分離メカニズムは、柔軟性と割り当て強度の点でクラウドネイティブ シナリオでの使用要件を満たすことができません。
分離メカニズムに加えて、既存のハイブリッド分散メカニズムも複雑なシナリオのニーズを満たすことが困難です。業界には共有スケジューリング用のオープン ソース ソリューションが多数存在することがわかりました。これらのオープン ソース ソリューションリソース レベルから 2 つのタスクを組み合わせるだけで、カードにディスパッチされます。実際のシナリオでは、単純な共有はビジネス間の相互影響、ロングテール遅延、さらにはスループットの低下を引き起こすため、単純な共有を運用環境に真に適用することはできません。
上記の利用モデル分析セクションでは、さまざまなビジネスやさまざまなシナリオにはさまざまな利用モデルがあることがわかりました。ビジネス シナリオを抽象化し、ハイブリッド ソリューションをカスタマイズする方法が、運用環境を実装するための鍵となります。
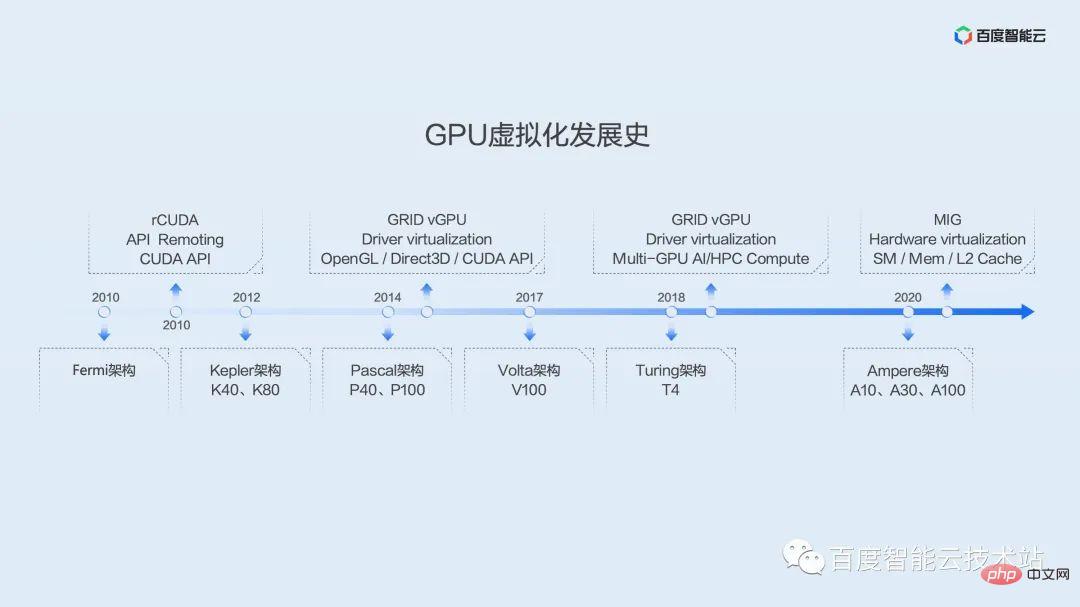
GPU の開発と仮想化の歴史をより包括的に理解していただくために、ここでは GPU 仮想化の開発の歴史を写真で示します。
一般的なコンピューティングにおける GPU のアプリケーションは、G80 時代の Tesla アーキテクチャにまで遡ることができます。これは、統合シェーダを実装するための第一世代のアーキテクチャです。ジェネラル プロセッサ SM を使用して、元のグラフィックスと個別の画像処理を置き換えます。頂点およびピクセルのパイプライン、デバイス。
Baidu によって導入された最初の GPU は、Fermi アーキテクチャにまで遡ることができます。この時点以来、業界では多数の仮想化ソリューションが登場しており、そのほとんどは API ハイジャックに焦点を当てています。その代表格である rCUDA は、もともと学術団体が維持しているプロジェクトで、最近まで一定の更新頻度とイテレーションを維持していましたが、学術研究に重点を置いているようで、本番環境ではあまり普及していません。
Baidu の大規模な GPU 導入は Kepler アーキテクチャに基づいており、Kepler アーキテクチャは Baidu が自社開発したスーパー AI コンピュータ X-MAN の時代を切り開きました。 X-MAN 1.0は、シングルマシン16カード構成を初めて実装し、PCIeハードウェアレベルでの動的バインディングとCPUとGPUの柔軟な比率を実現できます。 1 枚のカードのパフォーマンスによって制限があったため、当時は細分化よりも拡張性が重視されました。
その後の Pascal アーキテクチャ、Volta アーキテクチャ、および Turing アーキテクチャのパフォーマンスは急速に向上し、仮想化の需要がますます明らかになりました。初期の Kepler アーキテクチャから、NV は GRID vGPU 仮想化ソリューションを正式に提供しており、当初はグラフィック レンダリングとリモート デスクトップ シナリオを対象としていたことがわかりました。 2019年頃には、AIやハイパフォーマンスコンピューティングのシナリオ向けのソリューションも提供されるようになった。ただし、これらのソリューションは仮想マシンに基づいており、AI シナリオではほとんど使用されません。
Ampere 世代では、NV は MIG インスタンス セグメンテーション ソリューションを発表しました。これは、SM、MEM、L2 キャッシュなどの複数のハードウェア リソースのセグメンテーションをハードウェア レベルで実現し、優れたハードウェア分離パフォーマンスを提供します。ただし、このソリューションは Ampere アーキテクチャからサポートされており、カード モデルには特定の制限があります。 A100 と A30 の一部のモデルのみがサポートしています。また、スライス後でも、単一インスタンスのパフォーマンスは T4 の計算能力を超えており、現在の運用環境の効率の問題を十分に解決できません。
皆さんが GPU アーキテクチャと仮想化の歴史についてある程度の印象を持った後、GPU 仮想化を実現するための主要なレベル、つまり技術的なルートを詳しく紹介しましょう。
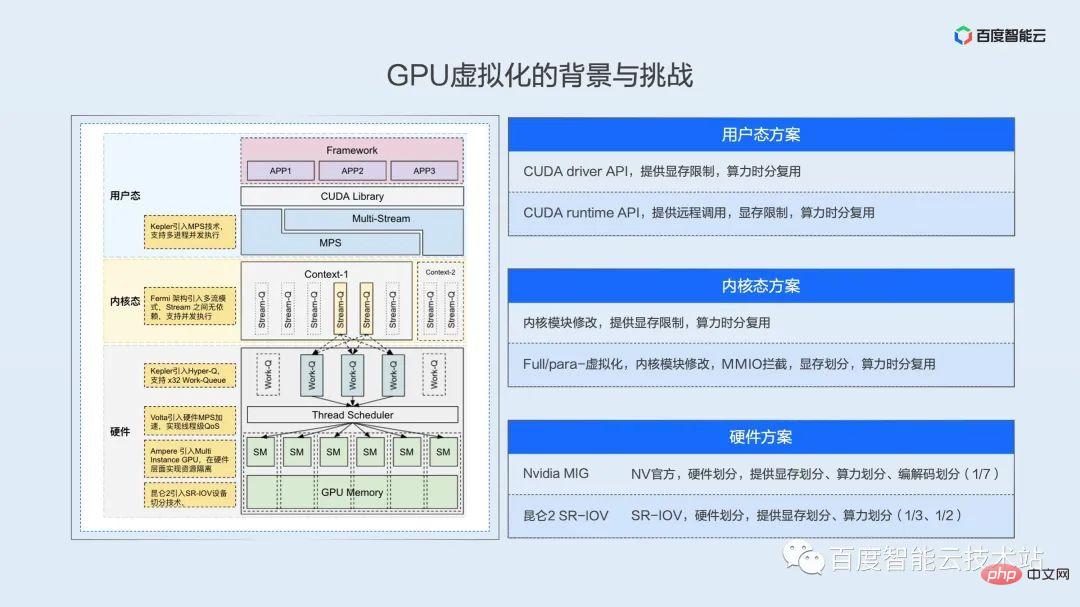
リソースの仮想化と分離を実現するには、まずリソースが時間または空間の次元で分離可能である必要があり、ユーザーの観点から見ると、複数のタスクを同時または並行して実行できます。
ここでは、ユーザー モード、カーネル モード、およびハードウェアの複数のレベルでの並列または同時実行スペースについて説明します。
NV のソフトウェアおよびハードウェア エコシステムはクローズド ソースであるため、ここでの概略図は、包括的なアーキテクチャ ホワイト ペーパー、リバース ペーパー、および私たち自身の理解に基づいて作成されています。
ユーザー モード ソリューション
この図を上から下に見てみましょう まず、GPU の観点から見ると、複数のプロセスは自然に並行、つまり時分割多重化されています。ドライバーとハードウェアは、タイム スライスのローテーションでタスクを切り替える役割を果たします。このメカニズム層を使用すると、API レベルでコンピューティング リソースとビデオ メモリ リソースに制限を実装し、仮想化効果を実現できます。ここの API は 2 つの層に分けることができます。最初の層はドライバー API です。この API 層はドライバーに近く、すべての上位層呼び出しが GPU にアクセスするための唯一の方法です。この層を制御している限り、これが唯一の方法です。 API の場合、ユーザーのリソース アクセスを制御することに相当します。ここで、NV が提供する MPS テクノロジーは、空間分割多重を実現でき、ビジネスパフォーマンスのさらなる最適化の可能性も提供します。後続の実装実践パートで詳しく説明します。
カーネル状態ソリューション
次の層は、仮想マシン レベルでの完全仮想化または準仮想化、または過去 2 年間の主要なクラウド ベンダーのコンテナ ソリューションのいずれであっても、カーネル状態です。システム コールのインターセプトと MMIO ハイジャックはカーネル層で実装されます。カーネル状態の最大の問題は、多くのレジスタと MMIO の動作が十分に文書化されていないため、複雑なリバース エンジニアリングが必要になることです。
ハードウェア ソリューション
カーネル状態の下にハードウェア層があります。NV の MIG テクノロジであっても、Baidu Kunlun の SR-IOV テクノロジであっても、この層では実際の並列処理が保証されています。計算能力は分割されています。ハードウェア ロジックで真の並列処理と空間分割多重化を実現します。たとえば、Kunlun は 1/3 および 1/2 のハードウェア パーティショニングを実現でき、A100 は最小粒度 1/7 のリソース パーティショニングを実現できます。
上記では、GPU 仮想化の課題と現状について多くのスペースを割いて紹介してきましたが、次に、Baidu が内部でこれらの課題にどのように対応しているかを見てみましょう。
この図は、Baidu Smart Cloud - デュアルエンジン GPU コンテナ仮想化アーキテクチャを示しています。
ここでコンテナーが強調されているのは、将来、AI フルリンク アプリケーションが徐々にクラウド ネイティブ プラットフォームに収束し、完全なコンテナーの開発、トレーニング、推論が実現されると考えているためです。 Gartner の調査によると、2023 年には AI タスクの 70% がコンテナーに導入される予定です。 Baidu の内部コンテナ化は 2011 年に始まり、現在では 10 年以上の展開と最適化の経験があり、実生活で磨かれた製品機能と最適化の経験のこの部分をコミュニティと大多数のユーザーに貢献することにも取り組んでいます。
ここではデュアル エンジンも強調されています。全体的なアーキテクチャでは、ユーザー モードとカーネル モードの 2 セットの分離エンジンを使用して、分離、パフォーマンス、効率などの側面に対するユーザーのさまざまなニーズに対応します。
分離エンジンの上には、リソース プーリング レイヤーがあります。このレイヤーは、ソフトウェアおよびハードウェア システムに対する深い理解に基づいており、AI で高速化されたリソースの分離、リモート性、およびプーリングを段階的に実装します。これは、将来のインフラストラクチャのために構築されるプールです. 抽象化レイヤー。
リソース プーリング レイヤーの上には、Matrix/k8s 統合リソース スケジューリング レイヤーがあります (ここでの Matrix は、Baidu 工場のコンテナ化されたスケジューリング システムです)。スケジューリング メカニズムの上に、さまざまなビジネス シナリオに基づいて、さまざまな共有混合、プリエンプティブ混合、タイムシェアリング混合、潮汐混合などを含む混合戦略の抽象化が行われます。これらの混合配布戦略については、後続の実践編で詳しく説明します。
リソースの分離とリソースのスケジューリングに依存することは、モデル開発、モデルのトレーニング、オンライン推論を含む AI ビジネスのフルリンク シナリオです。

# 次に、ユーザー モード分離エンジンとカーネル モード分離エンジンの実装をそれぞれ紹介します。
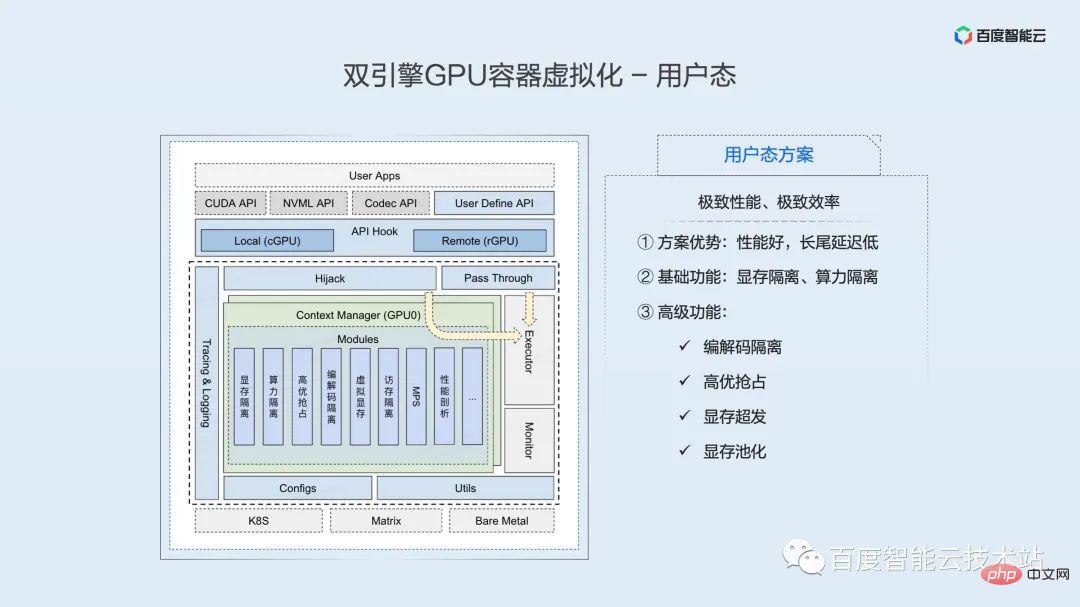
次の図は、ユーザー空間分離エンジンのコア アーキテクチャの概略図です。アーキテクチャ図の一番上にあるのはユーザー アプリケーションで、これには PaddlePaddle、TensorFlow、PyTorch などの一般的に使用されるさまざまなフレームワークが含まれています。
ユーザー アプリケーションの下には一連の API フック インターフェイスがあり、この一連のインターフェイスに基づいて、GPU リソースのローカル使用とリモート マウントを実現できます。フレームワークが依存する基礎となる動的ライブラリを置き換えることにより、リソースの制御と分離が実現されます。このソリューションはアプリケーションに対して完全に透過的であり、必要なライブラリ置換操作はコンテナ エンジンとスケジュール部分によって自動的に完了することに注意することが重要です。
CUDA API は、フック後の 2 つのパスを介して最終的にエグゼキューターに到達します。ここで、デバイス管理 API などの大部分の API は、フックを通過した後に操作を実行せず、実行のためにエグゼキュータに直接パススルーします。リソース アプリケーションに関連する少数の API はインターセプト層を通過し、これを通じてユーザー空間仮想化の一連の機能を実装できます。この層のロジックは十分に効率的に実装されており、パフォーマンスへの影響はほとんど無視できます。
現在、ユーザー モード分離エンジンは、基本的なビデオ メモリ分離やコンピューティング電源分離など、豊富な分離および制御機能を提供できます。また、エンコーダー分離、高品質プリエンプション、ビデオ メモリの過剰配分、ビデオ メモリ プーリングなど、多くの高度な機能も拡張しました。
ユーザー モード ソリューションの利点は、優れたパフォーマンスと低いロングテール遅延であり、遅延に敏感なオンライン推論ビジネスなど、メカニズムのパフォーマンスと極めて効率を追求するビジネス シナリオに適しています。
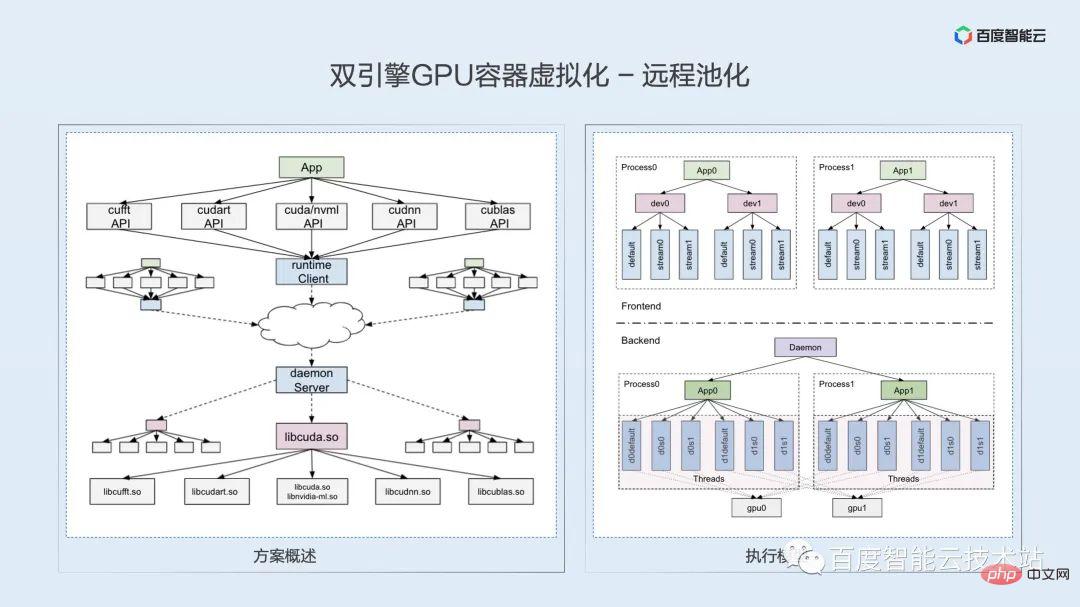
分離をベースに、リモート機能を提供します。リモートの導入により、リソース構成の柔軟性と使用効率が大幅に向上します。これについては、この記事は終わりです。
この共有はテクノロジーの共有です。ここでは、皆さんのビジネス アイデアや技術的な議論を刺激することを期待して、リモート テクノロジーの重要な点と困難さを少しのスペースを使って詳しく説明します。
前回の仮想化の課題で述べたソフトウェアとハードウェアのテクノロジ スタックによると、GPU へのリモート アクセスは通常、ハードウェア リンク層、ドライバ層、ランタイム層、およびユーザー層で実装できます。 -深さ 技術分析とビジネスシナリオの理解に基づいて、現時点で最も適しているのはランタイム層であると考えられます。
ランタイム層の技術的ルートとその実装方法を決定しますか?テクノロジーのポイントは何ですか?私たちは、それは主に意味上の一貫性の問題であると考えています。実行時のリモート性に基づいて、元のローカル プロセスをクライアントとサーバーの 2 つのプロセスに分割する必要があります。 CUDA ランタイムはクローズド ソースであり、内部実装ロジックを調査することはできません。プロセスを分割した後、元のプログラム ロジックと API セマンティクスが確実に維持されるようにするにはどうすればよいですか? ここでは、1 対 1 のスレッド モデルを使用して、API 内のロジックとセマンティクスの整合性を確保します。
リモート実装の難しさは、多数の API の問題です。libcudart.so 動的ライブラリに加えて、ランタイムには、cuDNN、cuBLAS、cuFFT などの一連の動的ライブラリと API も含まれており、数千ものさまざまな API インターフェイスの。コンパイル技術を使用してヘッダー ファイルの自動解析とコードの自動生成を実現し、リバース エンジニアリングを通じて隠し API の分析を完了します。
リモート ソリューション 0-1 の解決策 適応後、その後の下位互換性は実際には比較的簡単に解決できます。現時点では、CUDA API は比較的安定しているようで、新しいバージョンでは少量の段階的な適応のみが必要です。
- 時分割多重化: 名前が示すように、タイム スライス レベルで多重化します。これは CPU プロセスのスケジューリングに似ており、単一のタイム スライスでは 1 つの GPU プロセスのみが実行されます。複数の GPU プロセスはマイクロ レベルで交互に実行され、同時実行のみが可能です。これにより、特定のタイム スライス内で、プロセスがコンピューティング リソースを有効に活用できない場合、これらのコンピューティング リソースが無駄になることになります。
- 空間分割多重化: 時分割多重化とは異なり、空間分割多重化では、GPU のリソースが完全に不足していない限り、特定のマイクロ瞬間に複数のプロセスを GPU 上で同時に実行できます。 2 つのプロセスのカーネルはインターリーブされてマイクロ レベルで実行され、真の並列処理が実現され、GPU リソースがさらに活用されます。
概要セクションで紹介したように、カーネル状態仮想化や NVIDIA vGPU 仮想化など、現在一般的な仮想化手法は、実際には、最下位レベルでのタイム スライス ローテーションに基づく時分割多重ソリューションです。
NV は、マルチプロセス同時実行シナリオ向けのマルチプロセス サービス ソリューションである MPS を開始しました。このソリューションは空間分割多重化を実現でき、現在、効率とパフォーマンスの両方を考慮した唯一のソリューションです。
ここでは、MPS について簡単に紹介します。MPS は、2 つのプロセスのコンテキストを 1 つのプロセスにマージすることと同じです。マージされたプロセスは、起動のために前の 2 つのプロセスのカーネルを織り交ぜます。これには 2 つの利点があります。
- プロセス間でコンテキストを切り替える必要がないため、コンテキスト切り替えのオーバーヘッドが軽減されます。
- 同時に、さまざまなプロセスのカーネルがインターリーブされるため、リソース空間の使用率が向上します。
MPS について言えば、批判されている欠点について言及する必要があります。それは、障害分離の問題です。
この MPS の安定性の問題を解決するにはどうすればよいでしょうか? Baidu Intelligent Cloud は、スケジューリング、コンテナ エンジン、ビジネス キープアライブを組み合わせて、プロセス統合および共有ソリューションの完全なセットを提案します。
- kill コマンドのリダイレクトによりビジネス プロセスの正常な終了を実現
- MPS 状態検出機構によりヘルス チェックと一時停止アニメーションの検出を実現
- サービス キープにより自動ユーザー プロセスを実現-alive Restart
このソリューションは商用 (遅延に敏感な重要なサービス) リソースの 90% をカバーしており、2 年以上実行されています。究極のパフォーマンスを提供しながら、ニーズを満たすことができると信じています。安定性の必要性。
MPS がますます受け入れられるようになるにつれて、NV は MPS の安定性を強化し続けています。事前に良いニュースがあります.NV は今年後半に MPS の安定性を大幅に強化します, 一時停止アニメーション状態の検出と正常なプロセス終了を含む. これらの機能は MPS 製品の一部となり、安定性と使いやすさが向上しますMPSの更なる向上を推進します。
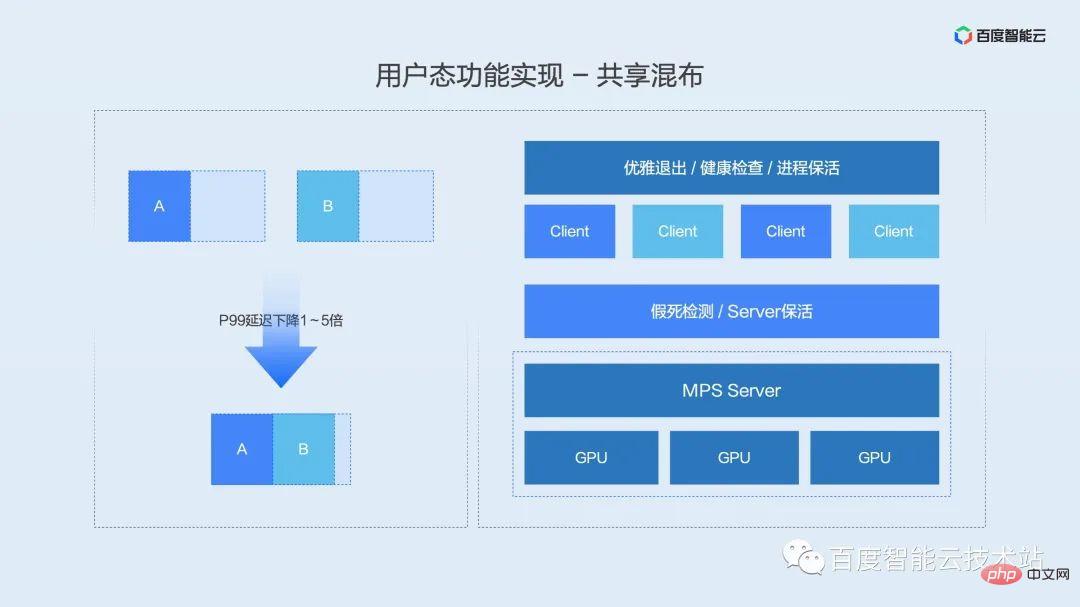
高品質プリエンプション機能を紹介する前に、まず高品質プリエンプションのビジネス シナリオについて説明します。工場内外のさまざまなユーザーとのディスカッションによると、ほとんどの AI アプリケーション制作環境は、遅延の感度に基づいて、オンライン、ニアライン、オフラインの 3 種類のタスクに分類できます。
- オンライン タスクはレイテンシーが最も高く、通常はユーザーのリクエストにリアルタイムで応答する推論タスクです。
- ニアライン タスクは通常、バッチ処理タスクであり、遅延の要件はありません。単一のログですが、データのバッチの完了時間には数時間から数分の範囲の要件があります。
- オフライン タスクには遅延に関する要件はなく、スループットのみに焦点を当てており、通常はモデル トレーニング タスクです。
遅延に敏感なタスクを高品質のタスクとして定義し、遅延に影響されないニアラインおよびオフラインのタスクを低品質のタスクとして定義するとします。そして、2 種類のタスクが混在する場合、異なるタスク優先度に応じて異なるカーネル起動優先度が定義されます。これが、上で説明した高品質なプリエンプション機能です。
実装原理は次の図に示されており、ユーザー モード分離エンジンは高品質タスクと低品質タスクの論理カーネル キューを維持します。全体の負荷が低い場合、2 つのキューが同時にカーネルを起動することが許可され、このとき 2 つのキューのカーネルはインターリーブされて一緒に実行されます。負荷が増加すると、階層型起動モジュールは、高品質のタスクの実行遅延を確実にするために、低品質のキューの起動を直ちに待機します。
この機能の利点は、オンライン タスクの影響を軽減または回避しながら、オフライン スループットを確保できることです。
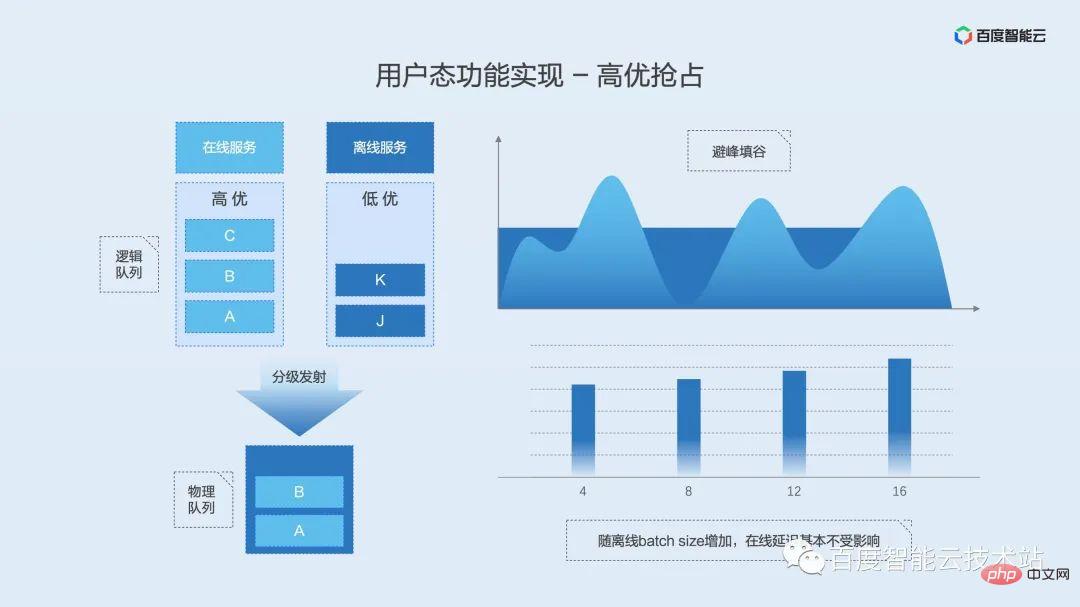
同様に、最初にタイムシェアリングミキシングの定義とシナリオを紹介します。
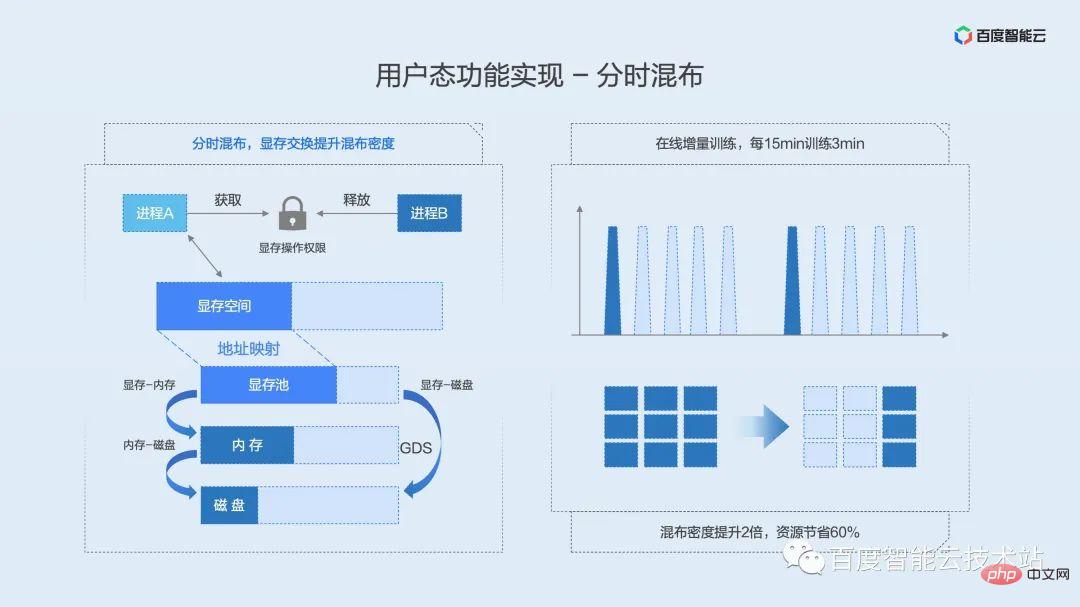
タイムシェアリングミキシングは、ミキシングモードでタイムスライスを回転させる共有ミキシングに似ています。違いは、タイムシェアリング ハイブリッド分散では、ビデオ メモリのビデオ メモリ スワップ ソリューションが提案されないことです。これは、ビデオ メモリが長時間占有されているものの、コンピューティング能力が断続的に使用されたり、時々トリガーされたりするシナリオで役立ちます。プロセスが計算能力を必要とするとき、プロセスはビデオ メモリへのアクセス権を取得します。プロセスが計算を完了すると、ビデオ メモリへのアクセス権を解放し、許可を待っている他のプロセスが実行の機会を得ることができるようにします。断続的なアイドル状態の GPU リソースを最大限に活用できます。
タイムシェアリングミキシングのコアテクノロジーはビデオメモリスワップです。これを CPU メモリ スワップに例えると、特定のプロセスのメモリが不足している場合、システムは特定の戦略に従ってシステム メモリ リソースの一部をディスクにスワップアウトし、実行中のプロセス用のスペースを解放します。
ビデオ メモリ スワップの実装原理を次の図に示します。ビデオ メモリの物理アドレスでビデオ メモリ プールを維持し、上位層はリソース ロックを使用して、どのプロセスに GPU の使用許可があるかを決定します。プロセスがロックを取得すると、ビデオ メモリはメモリまたはディスクから物理ビデオ メモリ プールに移動され、さらにプロセスが使用できるように仮想アドレス空間にマッピングされます。プロセスがロックを解放すると、プロセスの仮想メモリ空間が予約され、物理メモリがメモリまたはディスクに移動されます。ロックは相互に排他的です。1 つのプロセスのみがロックを取得できます。他のプロセスは待機キューで保留され、FIFO 方式でリソース ロックを取得します。
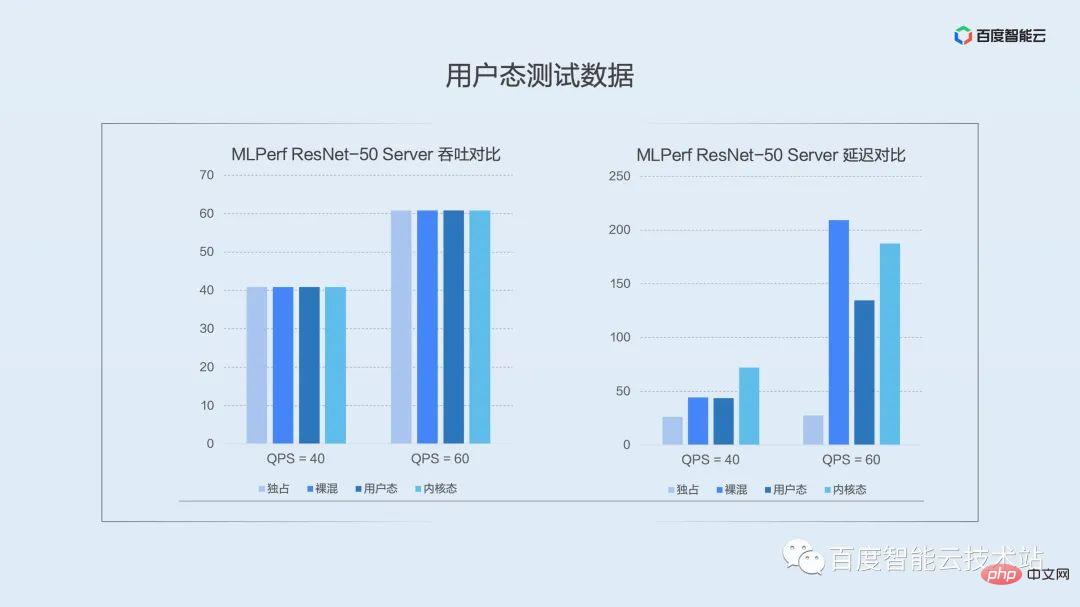
上記ではユーザーモード分離エンジンの機能実装を紹介しましたが、実際のアプリケーションではパフォーマンスはどうで、ユーザーへの影響はどうなのでしょうか?ここで、テストデータに直接進みます。
次の図は、公開テスト セット MLPerf で代表的なモデル ResNet-50 サーバーを選択したシナリオでのデータ比較です。図の列は、左から右に、排他的、ネイキッド混合、ユーザー モード分離、およびカーネル モード分離におけるパフォーマンスを表しています。
左側の図は平均スループットの比較です。推論シナリオでは、リクエストが断続的にトリガーされます。どのソリューションでもスループット下の圧力値に直接到達できることがわかります。ここで説明したいのは、推論シナリオのスループットでは仮想化のパフォーマンスを十分に実証できないため、運用環境に実装する場合はレイテンシにもっと注意を払う必要があるということです。
右の図は、P99 分位点遅延の比較です。低圧 (QPS = 40) 下のユーザー モードでは、ネイキッド ミキシングがロングテール遅延に及ぼす影響は基本的に同じですが、カーネル モードの方がロングテール遅延にわずかに大きな影響を与えていることがわかります。時分割多重化の使用。圧力を高め続けます。QPS = 60 になると、ユーザー モードの利点が明らかになります。空間分割多重化により、ロングテール遅延への影響が大幅に軽減されます。圧力がさらに高まるにつれて、ユーザーモードのプロセス融合ソリューションは他のハイブリッド分散方法よりも桁違いに優れています。
ロングテール遅延制御はユーザー モードほど優れていませんが、カーネル モードには分離の点で利点があり、強力な分離要件があるシナリオに重点を置いています。
カーネル状態分離エンジンの技術的な実装を見てみましょう。
最初に、次のようなカーネル状態の仮想化実装の特性を見てみましょう:
カーネル状態の実装、優れた分離: ビデオ メモリ、計算能力、障害分離をサポート、ビデオの MB レベルの分離メモリ、コンピューティング能力 1% レベルの割り当て、P4、V100、T4、A100/A10/A30 およびその他の主流の GPU をサポート、410 ~ 510 の GPU ドライバー バージョンをサポート、ユーザー モードのオペレーティング環境を変更する必要はありません、コンテナ化された展開をサポートします。
ユーザー モードの実装とは異なり、カーネル モード仮想化の GPU 分離機能はカーネル モードで実装されます。以下の図の左半分は、カーネル状態の仮想化実装のアーキテクチャ図であり、下から順に、GPU ハードウェア、カーネル層、ユーザー層となっています。
ハードウェア レベルは GPU です。この GPU はベア メタル GPU またはトランスペアレント GPU です。
カーネル層の下には、実際にGPUの機能を制御するGPUの独自ドライバーがあり、実際にGPUを動作させるのはこのドライバーであり、GPUドライバーの上にはGPU仮想化のためのカーネルモジュールがあるつまり、GPU インターセプト ドライバーは黄色の部分で、メモリ インターセプト、計算能力インターセプト、計算能力スケジューリングの 3 つの機能が含まれています。ビデオ メモリの分離とコンピューティング電源の分離は個別に実装されます。
ユーザー層、最初はインターセプトインターフェイスです。このインターフェイスはインターセプト モジュールによって提供され、2 つの部分に分かれています。1 つはデバイス ファイル インターフェイスで、もう 1 つはインターセプト モジュールを設定するためのインターフェイスです。デバイス ファイルはコンテナに提供されます。まずコンテナについて見てみましょう。コンテナの上にはアプリケーションがあり、下には cuda ランタイムがあり、その下にはドライバー api/nvml api などを含む cuda の基礎となるライブラリがあります。デバイス ファイルを偽のデバイス ファイルとしてコンテナに提供することで、上位層の CUDA がアクセスする際にデバイス ファイルにアクセスすることになり、CUDA の基盤ライブラリによる GPU ドライバーへのアクセスの傍受が完了します。
カーネル内のインターセプト モジュールは、アクセスされたすべてのシステム コールをインターセプトし、インターセプトして解析し、実際の GPU の基礎となるドライバーに実際のアクセスをリダイレクトします。 GPU の基礎となるドライバーが処理を完了すると、インターセプト モジュールに結果が返され、インターセプト モジュールで再度処理され、最後にコンテナ内の基礎となるライブラリに結果が返されます。
簡単に言うと、デバイス ファイルをシミュレートすることによって、基になるライブラリから GPU ドライバーへのアクセスを傍受し、傍受、解析、挿入などの操作を通じてビデオ メモリと計算能力の傍受を完了します。
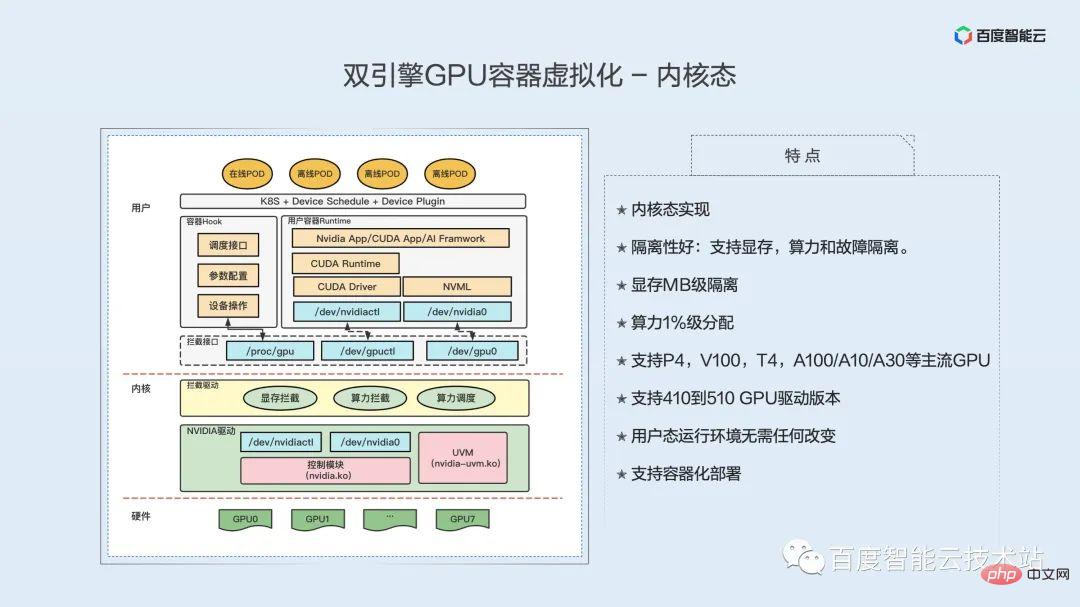
現在、ビデオ メモリの分離は、主にビデオ メモリ情報、ビデオ メモリの割り当て、およびビデオ メモリの解放を含むすべてのビデオ メモリ関連のシステム コールをインターセプトすることによって実現されます。さらに、現在のメモリ分離は静的にのみ設定でき、動的に変更することはできません。ユーザー モードはビデオ メモリの過剰開発をサポートできますが、カーネル モードはビデオ メモリの過剰開発をサポートできません。
コンピューティング電源の分離に関しては、プロセスの CUDA コンテキストをインターセプトすることで関連情報が取得されます。スケジューリング オブジェクトは、プロセス関連の CUDA コンテキストです。 CUDA Contextに対応する計算資源には、計算資源(Execution)とメモリコピー(Copy)資源が含まれる。各 GPU には、この GPU 上のすべての CUDA コンテキストをスケジュールする 1 つのカーネル スレッドがあります。

4 つのカーネル状態のコンピューティング能力スケジューリング アルゴリズムを実装しました。
- 固定シェア: 各 POD は、固定のコンピューティング能力リソースを割り当てます。 GPU 全体の計算能力は n 個の部分に固定的に分割され、各 POD は 1/n の計算能力に分割されます。
- 均等共有: すべてのアクティブな POD は計算能力リソースを均等に共有します。つまり、アクティブな POD の数は n で、各 POD は計算能力の 1/n を共有します。
- 重みシェア: 各 POD は重みに従って計算能力リソースを割り当てます。つまり、GPU 全体の計算能力が重み値に従って各 POD に割り当てられます。 POD にビジネス負荷があるかどうかに関係なく、計算能力は重みに応じて割り当てられます。
- バースト ウェイト シェア: アクティブ POD は重みに従って計算能力リソースを割り当てます。つまり、各 POD には重み値が割り当てられ、アクティブ POD には重みの比率に従って計算能力が割り当てられます。

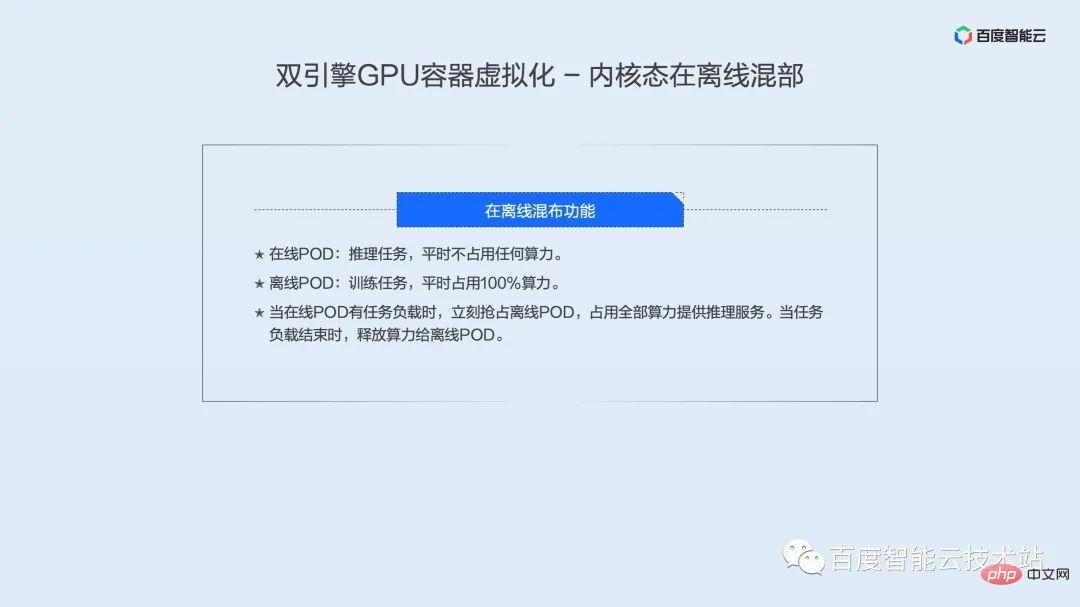
カーネル状態はタイム スライスを通じてコンピューティング能力をスケジュールするため、遅延に敏感なビジネスにはあまり適していません。当社は特別に開発したオフライン コロケーション テクノロジーを備えており、オンライン ビジネスとオフライン ビジネスのコロケーションを通じて、オンライン ビジネスの応答速度を大幅に向上させることができ、オフライン ビジネスが GPU コンピューティング リソースを共有して、GPU リソースの使用率を高めるという目標を達成することもできます。 . .オフライン混合展開の特徴は次のとおりです。
- オンライン POD: 推論タスク。通常、少量のコンピューティング パワーを占有します。
- オフライン POD: トレーニング タスク。通常、コンピューティング能力のほとんどを消費します。
オンライン POD にタスクの負荷がある場合、オンライン POD は直ちにオフライン POD を捕捉し、推論サービスを提供するためにすべてのコンピューティング能力を使用します。タスクのロードが終了すると、コンピューティング能力がオフライン POD に解放されます。
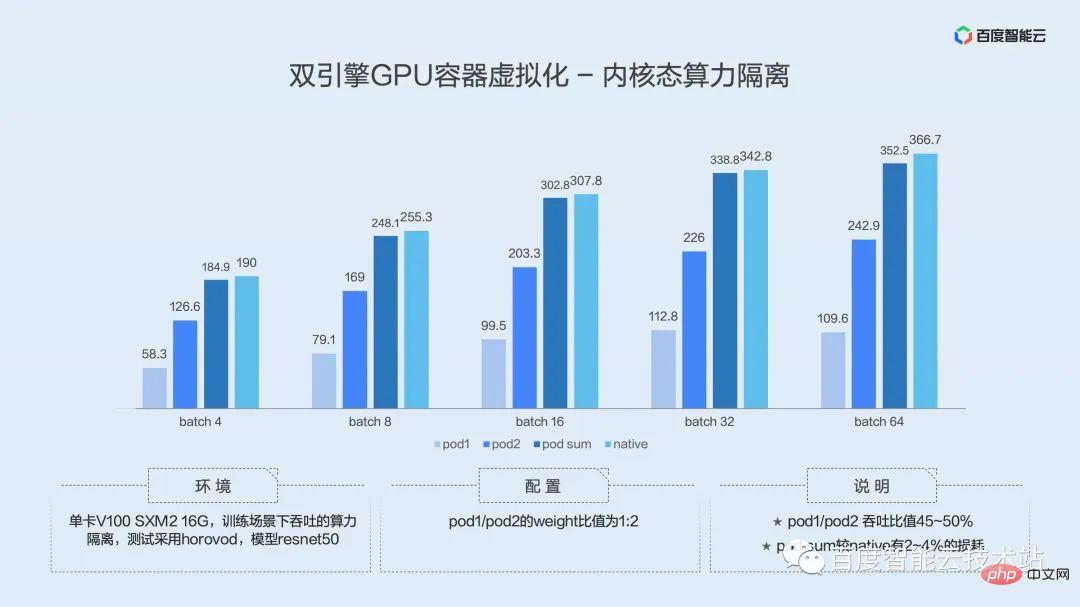
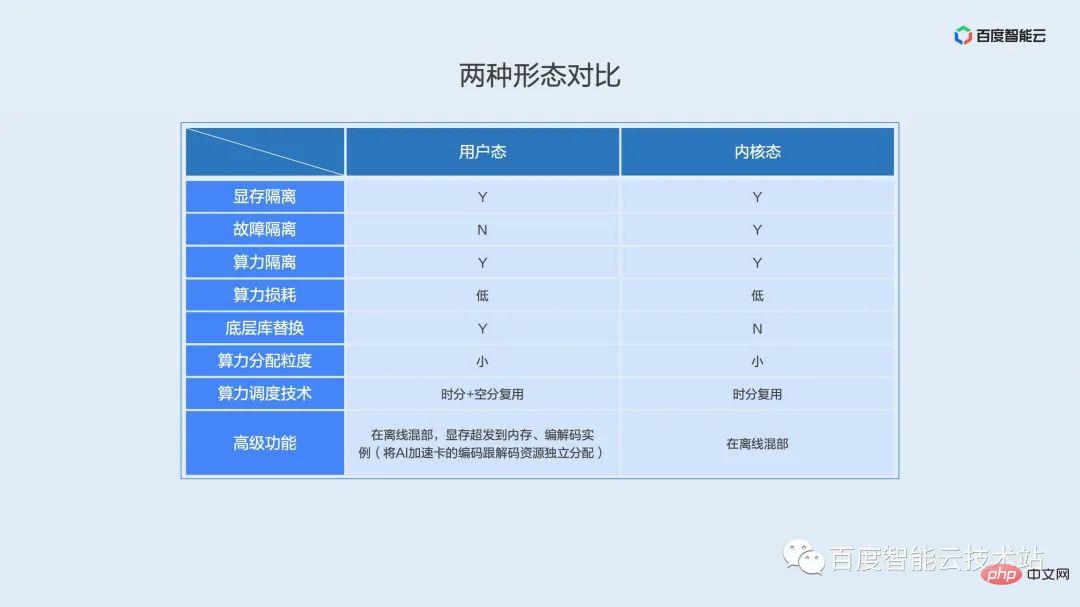
カーネルモードとユーザーモードの特徴を比較してみましょう。
障害の分離という点では、カーネル状態はユーザー状態よりも優れており、カーネル状態は基礎となるライブラリを置き換える必要がありません。ユーザー モードの計算能力スケジューリングは時分割と空間分割多重を採用し、カーネル モードは時分割多重を採用します。ユーザー モードの高度な機能には、オフライン コロケーション、ビデオ メモリのメモリへの過剰配分、エンコードおよびデコード インスタンス (AI アクセラレータ カードのエンコードおよびデコード リソースの独立した割り当て) が含まれ、また、オフライン コロケーションもサポートしています。カーネルモード。
AI シナリオで仮想化テクノロジーを使用して GPU 利用効率を向上させる方法 工場での実際の事例に基づいた大規模 AI シナリオのベスト プラクティスを共有しましょう。
まず、推論サービスの典型的なシナリオを見てみましょう。モデル独自のアーキテクチャまたは高いサービス待機時間要件により、一部のタスクはバッチサイズが非常に小さい構成でのみ実行できるか、バッチサイズが 1 の場合でも実行できます。これは長期的な GPU 使用率の低下に直接つながり、ピーク使用率でさえわずか 10% です。
このシナリオでは、まず、使用率の低い複数のタスクを混合することを考慮する必要があります。
このミキシング戦略を共有ミキシングとして要約します。開発、トレーニング、推論のいずれのシナリオでも、使用率の低い複数のタスク間で共有混合を使用できます。
上記のプロセス融合テクノロジーと組み合わせることで、サービス遅延を確保した上で 2 つのインスタンスまたは複数のインスタンスの共有混合を実現し、リソース使用率を 2 倍以上増加させることができます。
同時に、ほとんどの GPU は独立したエンコードおよびデコード リソースを持っています。ほとんどのシナリオでは、左下の図に示すように、リソースは長時間アイドル状態のままになります。共有コンピューティング リソースに基づいて、エンコードまたはデコードのインスタンスを混合して、リソースのパフォーマンスをさらに向上させ、アイドル状態のリソースをアクティブにすることができます。
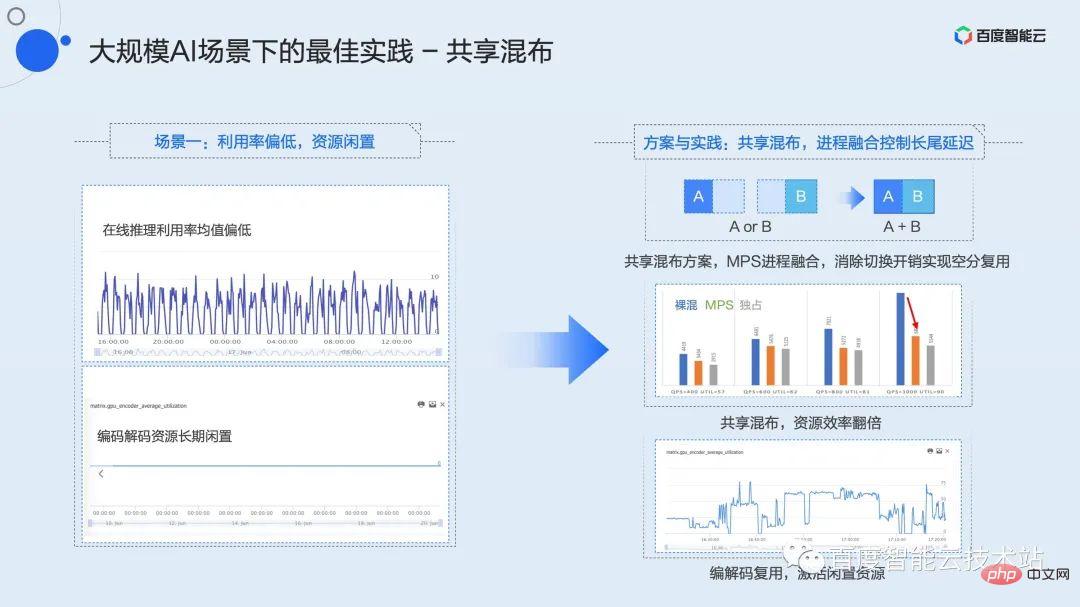
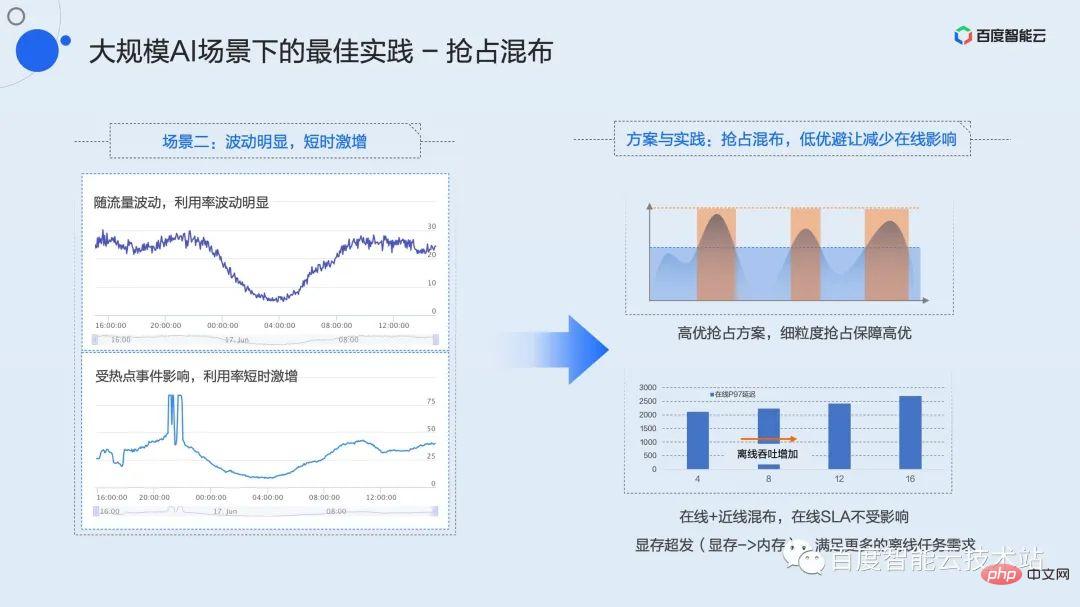
推論サービスの一般的な負荷パターンは、1 日を通して明らかなピークと谷の変動があり、予測できない短期間のトラフィックの急増が発生することです。これは、ピーク値は高いにもかかわらず、平均使用率が非常に低く、平均値が 30% 未満、さらには 20% 未満であることが多いことを示しています。
このような変動は明らかですが、短期サージサービスの効率を最適化するにはどうすればよいでしょうか?私たちはプリエンプティブな混合配信戦略を提案します。
プリエンプティブ ミキシングとは、遅延の影響を受けにくい低品質のタスクと、ピーク値が高く遅延の影響を受けやすい高品質のサービスを混合することです。ここでの高品質と低品質はユーザーによって定義され、リソースを申請するときに明示的に宣言されます。 Baidu の内部慣行では、ニアラインおよびオフラインのデータベース ブラッシングまたはトレーニング タスクを低品質と定義しています。この種のビジネスには、スループットに関する特定の要件があり、基本的に遅延に関する要件はありません。
仮想化機能の高品質プリエンプション機構を使用すると、高品質タスクが常にリソースを占有する主導権を持ちます。トラフィックが谷にあるときは、カード全体の負荷は高くなく、最適性の低いタスクは通常どおり実行できます。トラフィックがピークに達するか、短期間の急増が発生すると、最適性の高いプリエンプション メカニズムが機能します。リアルタイムで感知し、カーネル粒度でコンピューティング能力をプリエンプトします。現時点では、高品質タスクのサービス品質を確保するために、低品質タスクはフローが制限されるか、完全に保留されることもあります。
このハイブリッド モードでは、ビデオ メモリが不十分である可能性があり、計算能力に多くの冗長性が存在する可能性があります。この種のシナリオのために、暗黙的なビデオ メモリの過剰送信メカニズムを提供します。ユーザーは環境変数を使用して、低品質のタスク用にビデオ メモリを過剰に分散し、より多くのインスタンスをデプロイして、使用率の谷を埋めて全体的な使用効率を最大化するためにコンピューティング パワーを常に利用できるようにすることができます。
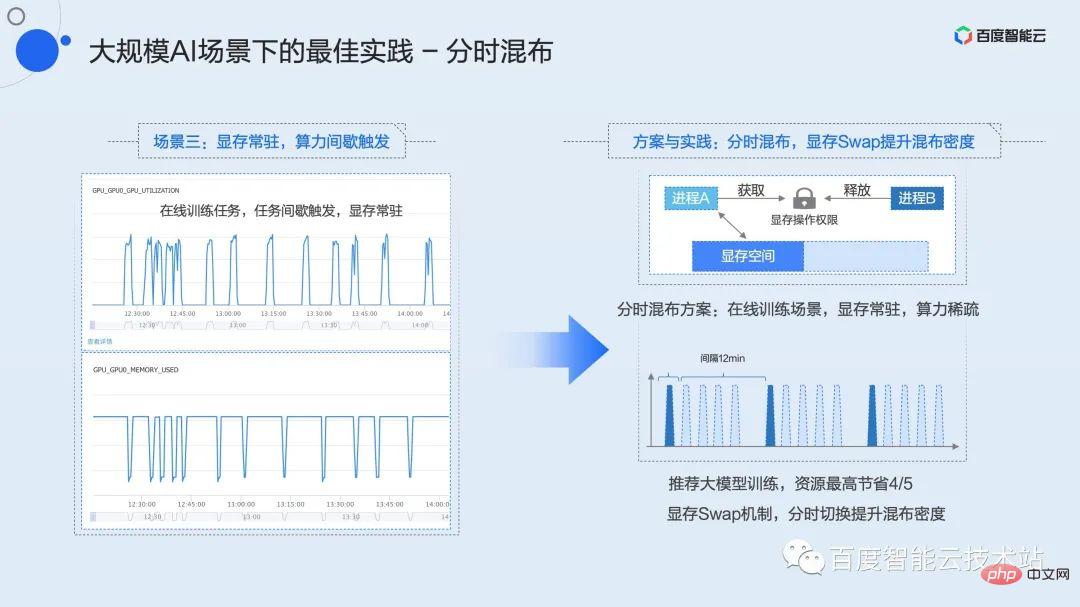
#3 番目のタイプのビジネス シナリオは、誰もがよく知っているかもしれませんが、これは、グラフィックス メモリが常駐し、コンピューティング パワーが断続的にトリガーされるシナリオです。代表的な業務としては、開発業務やオンライン研修などが挙げられます。
ここではオンライン トレーニングを例に挙げます。オンライン トレーニングが必要なレコメンデーション モデルなど、多くのモデルは日次または時間ごとのユーザー データに基づいてオンラインで更新する必要があることがわかっています。リアルタイムでスループットがフルになるオフライン トレーニングとは異なり、オンライン トレーニングではデータのバッチを蓄積し、トレーニング セッションをトリガーする必要があります。 Baidu 内では、典型的なモデルでは、データのバッチは 15 分で到着しますが、実際のトレーニング時間はわずか 2 ~ 3 分です。残りの時間では、トレーニング プロセスはビデオ メモリ内に常駐し、次の処理が行われるまでそこで待機します。データのバッチが上流から到着します。この期間、稼働率は長期間 0 であり、多くのリソースの無駄が発生していました。
このタイプのタスクでは、ビデオ メモリが基本的にいっぱいであるため、上記の共有ミキシングまたはプリエンプティブ ミキシングを使用できません。前述のビデオ メモリ スワップ メカニズムと組み合わせて、タイムシェアリング ミキシング戦略を提案しました。
タイムシェアリングミキシングは、タイムスライスローテーションの共有ミキシングに似ていますが、このとき、ビデオメモリもコンピューティングコンテキストとともにスワップインおよびスワップアウトされます。基盤となる仮想化層はビジネスで計算が必要なときを感知できないため、GPU カードごとにグローバル リソース ロックを維持します。また、ユーザーが呼び出せるように、対応する C インターフェイスと Python インターフェイスをカプセル化します。ユーザーは計算が必要な場合にのみこのロックを申請する必要があり、ビデオ メモリは他の領域からビデオ メモリ領域に自動的にスワップされ、計算が完了するとロックが解除され、対応するビデオ メモリが解放されます。メモリまたはディスク領域にスワップアウトされます。このシンプルなインターフェイスを使用すると、ユーザーは複数のタスクで GPU をタイムシェアリングおよび排他的に使用できます。オンライン トレーニング シナリオでは、タイムシェアリング ミキシングを使用すると、全体の使用率を高めながらリソースを最大 4/5 節約できます。
上記の 3 つのシナリオのベスト プラクティスは、Baidu の社内ビジネスで大規模に検証され、実装されています。 Baidu Baige・AI ヘテロジニアス コンピューティング プラットフォームでも関連機能が提供されており、すぐに申請して試すことができます。
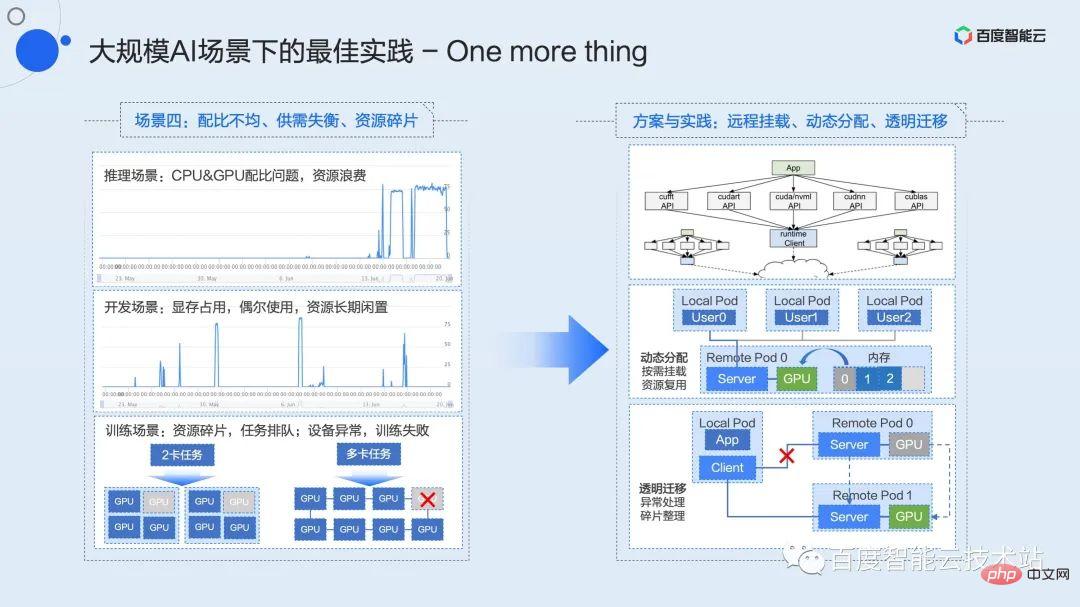
ここでは、まだ内部検証中の機能について 3 分ほどお話しします。これらの機能は近い将来、Baidu Baige プラットフォーム上で完成し、大規模な AI シナリオにおける一般的な構成の問題をさらに解決する予定です。 . 比率の不均一、需要と供給の不均衡、資源の細分化などの問題。
インフラストラクチャに取り組む学生は、リソースのデカップリングやプールなどの概念をよく耳にします。プーリングの概念を実装し、それを実際の生産性に変換する方法は、私たちが積極的に模索し、推進してきたことです。 2015 年の早い段階で、当社は PCIe ファブリック ソリューションに基づく業界初のハードウェア プーリング ソリューションを実装し、Baidu 内で大規模に実装しました。これが、先ほど触れた X-MAN 1.0 です (現在は 4.0 に進化しています)。 PCIe ファブリック ネットワークを介して CPU と GPU 間の相互接続を構成して、リソースの動的な割り当てを実現し、さまざまなシナリオでの比率の問題を解決します。ハードウェア接続とプロトコルによって制限されるため、このソリューションはキャビネット内のプーリングのみを解決できます。
ソフトウェア レイヤー プーリングは、より柔軟であると当社が考える技術的ソリューションです。データセンター ネットワークのアップグレードが進むにつれて、将来的には 100G または 200G ネットワークがインフラストラクチャの標準構成となり、高速ネットワークはリソース プールのための通信ハイウェイを提供します。
リソースの分離とプールにより、ビジネスの柔軟性が高まり、パフォーマンスの最適化のための想像力の余地が広がります。例えば、CPUとGPUの比率の問題、開発シナリオにおける長期的なリソース占有の需給不均衡と低効率の問題、トレーニングシナリオにおけるリソースの断片化タスクブロックの問題、機器の異常なトレーニング再起動の問題などです。このようなシナリオはすべて、プーリングおよび派生ソリューションで解決できます。
最後に、上記で共有したすべての仮想化テクノロジとベスト プラクティスが、Baidu Baige AI ヘテロジニアス コンピューティング プラットフォーム上で起動されました。 Baidu Intelligent Cloud の公式 Web サイトで「Baidu Baige」を検索すると、AI タスクが即座に加速され、ビジネスの想像力が刺激されます。
Q & A 注目の
Q: 一般的なリソースは、名前空間と cgroup を通じてコンテナ化されます。 GPU がリソース制御を実現するためにどのようなテクノロジーを使用しているかお聞きしてもよろしいでしょうか?
A: 名前空間と cgroup は両方ともカーネルによって提供されるメカニズムであり、基本的にハードウェアによって提供される関連機能に依存します。これは現在の GPU には存在しません。GPU は現在、そして今後も長い間クローズド ソースです。カーネル メインラインにアップストリームできるこれらの機能を提供できるのはハードウェア プロバイダーだけです。現在のサードパーティ ソリューションはすべてユーザー モードまたはカーネル モードでの非標準実装であり、現時点ではそれらを名前空間および cgroup カテゴリに含める方法はありません。しかし、GPU 仮想化が実装したいのは、これらのインターフェイスの下にある対応するメカニズムであると考えられ、それを標準化できるかどうかはさらに大きな問題です。
Q: GPGPU 仮想化技術に加えて、NPU 関連の仮想化技術も開発しましたか? NV テクノロジー スタックから切り離すかどうか。ありがとう!
A: ここで言及されている NPU は、一般的に現在のすべての AI アクセラレーション ハードウェアを指すネットワーク プロセッシング ユニットであると理解しています。私たちは他の AI 高速化ハードウェアの仮想化適応に取り組んでいます。 1 つ目は Kunlun コアで、上記の仮想化機能は既に Kunlun コアに適用されています。シーンが拡大するにつれて、他の主流のアクセラレーション ハードウェアも引き続き採用されることになります。
Q: ユーザー モードとカーネル モードは 2 つの異なる製品ですか?
A: 同じ製品ですが、基盤となる実装方法は異なりますが、ユーザー インターフェイス レベルは統一されています。
Q: ユーザーモード仮想化ではどの程度の粒度を実現できますか?
A: コンピューティング能力は 1% の粒度に分割され、ビデオ メモリは 1MB に分割されます。
Q: カーネル モード仮想化により、制御オーバーヘッドが増加しますか?
A: カーネル状態の仮想化はタイム スライシングに基づいています。ここでのオーバーヘッドはタイム スライシングによって引き起こされます。正確に分離すると、必然的にコンピューティング パワーの損失が生じます。アプリケーションのパフォーマンスに起因するオーバーヘッドを指す場合、カーネル モードがユーザー モードよりも大きくなるのは事実です。
Q: 時分割実施計画によると、自由競争の平均時間はオンライン推理の方が早いような気がします。
A: 当社のテスト結果によると、パフォーマンスの良い順は、プロセス融合、ネイキッドミキシング (自由競争)、およびハードリミット分離です。
Q: GPU の 2 つの仮想化方式は、k8s クラスター内で共存できますか?
A: 仕組みや原理的には共存可能です。しかし、現時点では、製品の観点からデザインをそれほど複雑にしたくないので、依然としてそれらを分離しています。今後の事業者からの要望が広がれば、同様の共存ソリューションの立ち上げも検討してまいります。
Q: k8s スケジューラを拡張する方法を詳しく紹介していただけますか?ノード上のエージェントは GPU トポロジと合計ボリュームを報告する必要がありますか?
A: はい、これにはスタンドアロン エージェントがリソース (ビデオ メモリ リソースやコンピューティング能力リソースを含む) とトポロジ情報をアップロードする必要があります。
Q: 時間とスペースの分の選択について何か提案はありますか?
A: 遅延に敏感なオンライン推論タスクの場合は、プロセス融合に基づく空間分割ソリューションを選択することをお勧めします。厳密な分離が必要なシナリオの場合は、タイムシェアリング ソリューションを選択することをお勧めします。その他のシーン選択では両者に違いはありません。
Q: カーネル モードはどの CUDA バージョンをサポートできますか? NV が更新される場合、Baidu Smart Cloud の更新サイクルにはどれくらい時間がかかりますか?
A: カーネル状態はカーネル内で仮想化されているため、CUDA のバージョンに特別な要件はありません。現在、すべての CUDA バージョンがサポートされています。 NV が CUDA を更新する場合、特別なサポート作業は必要ありません。
Q: カーネル モードを使用するには、Baidu Smart Cloud が提供する特別な OS イメージを使用する必要がありますか?専属ドライバー?
A: カーネル状態では、Baidu Smart Cloud が専用の OS イメージを提供する必要はありません。現在、centos7 と ubuntu をサポートしています。ただし、これを使用するには独自のデプロイメント フレームワークを使用する必要があります。コンテナー イメージには特別な要件はなく、すべて透過的にサポートできます。
Q: パブリック クラウドでのみ利用可能ですか?プライベートでも導入できるのでしょうか?
A: パブリック クラウドとプライベート クラウドの両方を導入して使用できます。
以上が技術分析と実践の共有: デュアルエンジン GPU コンテナ仮想化におけるユーザー モードとカーネル モードの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。