
ホームページ >テクノロジー周辺機器 >AI >画像翻訳用の 5 つの有望な AI モデル
画像翻訳用の 5 つの有望な AI モデル

- 王林転載
- 2023-04-23 10:55:071934ブラウズ
画像間の変換
Solanki、Nayyar、および Naved が論文で提供した定義によれば、画像間の変換は、あるドメインから別のドメインに画像を変換するプロセスです。入力画像と出力画像の間のマッピングを学習することが目的です。
言い換えれば、モデルがマッピング関数 f を学習することで、ある画像 a を別の画像 b に変換できることを期待しています。

これらのモデルの用途や人工知能の世界との関連性について疑問に思う人もいるかもしれません。アートやグラフィックデザインに限定されず、多くの用途がある傾向があります。たとえば、画像を撮影し、それを別の画像に変換して合成データ (セグメント化された画像など) を作成できることは、自動運転車のモデルをトレーニングするのに非常に役立ちます。テスト済みのもう 1 つのアプリケーションは地図デザインです。モデルは両方の変換 (航空写真から地図へ、またはその逆) を実行できます。画像反転変換は建築にも適用でき、モデルは未完成のプロジェクトを完了する方法について推奨を行います。
画像変換の最も魅力的なアプリケーションの 1 つは、単純な描画を美しい風景や絵画に変換することです。
5 画像翻訳に最も有望な AI モデル
ここ数年にわたり、生成モデルを活用して画像間の翻訳の問題を解決するためのいくつかの方法が開発されてきました。最も一般的に使用される方法は、次のアーキテクチャに基づいています:
- 敵対的生成ネットワーク (GAN)
- バリエーション オートエンコーダー (VAE)
- 拡散モデル (DVAE)
- Transformers
Pix2Pix
Pix2Pix は、条件付き GAN ベースのモデルです。これは、そのアーキテクチャが Generator network (G) と Discriminator (D) で構成されていることを意味します。どちらのネットワークも敵対的ゲームでトレーニングされます。G の目標はデータセットに似た新しい画像を生成することであり、D は画像が生成されたもの (偽) かデータセットから生成されたもの (真) かを決定する必要があります。
Pix2Pix と他の GAN モデルの主な違いは次のとおりです: (1) 最初のジェネレーターは生成プロセスを開始するために画像を入力として受け取りますが、通常の GAN はランダム ノイズを使用します; (2) Pix2Pix は完全に監視されていますこれは、データセットが 2 つのドメインの画像のペアで構成されていることを意味します。
この論文で説明されているアーキテクチャは、ジェネレーター用の U-Net と、識別器用のマルコフ識別器またはパッチ識別器によって定義されています:
- U-Net: 2 つで構成されます。モジュール (ダウンサンプリングとアップサンプリング)。入力画像は畳み込み層を使用して小さな画像のセット (特徴マップと呼ばれる) に縮小され、元の入力次元に達するまで転置畳み込みによってアップサンプリングされます。ダウンサンプリングとアップサンプリングの間にはスキップ接続があります。
- Patch Discriminator: 畳み込みネットワーク。その出力は行列で、各要素は画像の一部 (パッチ) の評価結果です。これには、生成されたイメージと実際のイメージの間の L1 距離が含まれており、ジェネレーターが入力イメージを考慮して正しい関数をマッピングすることを確実に学習します。異なるパッチのピクセルが独立しているという前提に基づいているため、マルコフとも呼ばれます。
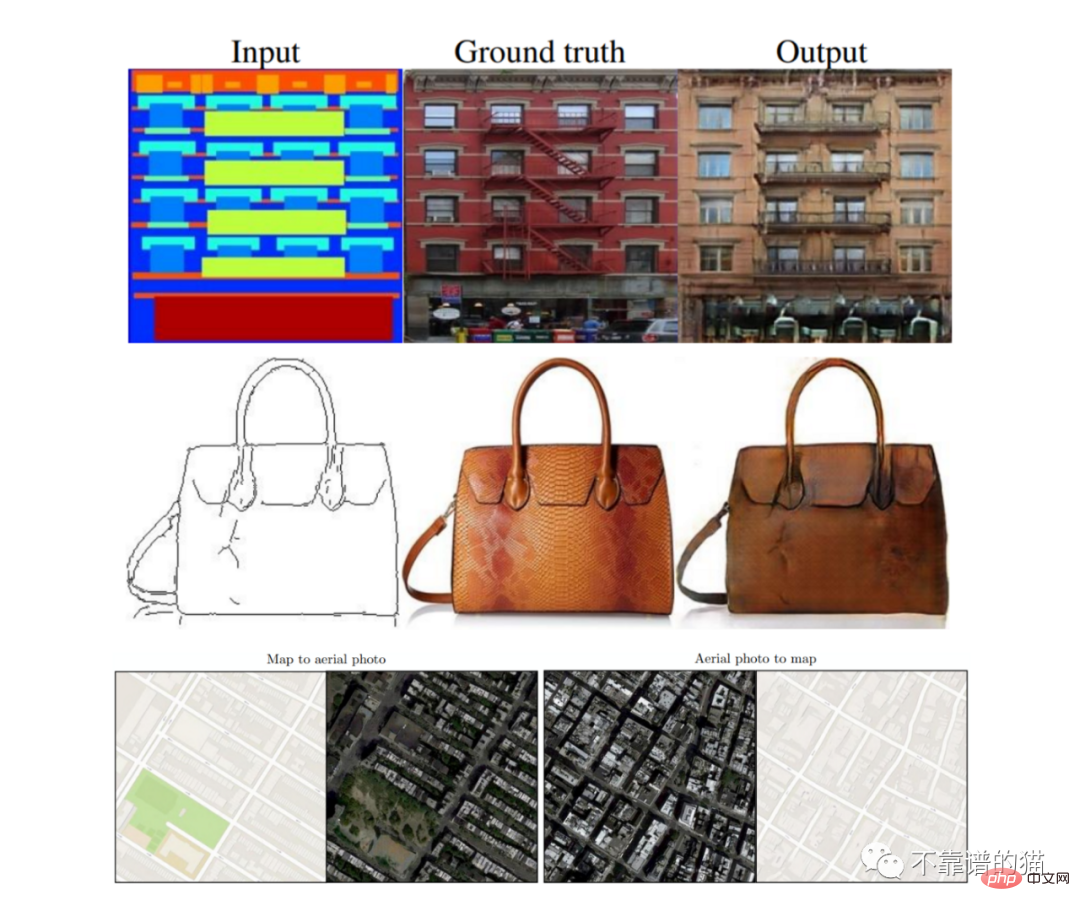
Pix2Pix の結果
教師なし画像から画像への変換 (UNIT)
Pix2Pix では、トレーニング プロセスは完全に監視されています (つまり、画像入力のペアが必要です)。 UNIT メソッドの目的は、2 つのペアの画像でトレーニングせずに、画像 A を画像 B にマッピングする関数を学習することです。
モデルは、2 つのドメイン (A と B) が共通の潜在空間 (Z) を共有すると仮定することから始まります。直観的には、この潜在空間はイメージ ドメイン A と B の間の中間段階と考えることができます。したがって、絵画から画像への例を使用すると、同じ潜在空間を使用して絵画画像を後方に生成したり、素晴らしい画像を前方に表示したりすることができます (図 X を参照)。
図中: (a) 共有潜在空間。 (b) UNIT アーキテクチャ: X1 はピクチャ、G2 ジェネレータ、D1、D2 ディスクリミネータです。破線はネットワーク間の共有レイヤーを表します。
UNIT モデルは、エンコーダーの最後の層 (E1、E2) とジェネレーターの最初の層 (G1、G2) が共有される VAE-GAN アーキテクチャのペア (上記を参照) に基づいて開発されます。

UNIT の結果
Palette
Palette は、カナダの Google 研究チームによって開発された条件付き拡散モデルです。モデルは、画像変換に関連する 4 つの異なるタスクを実行するようにトレーニングされ、高品質の結果が得られます。
(i) カラー化: グレースケール画像に色を追加します。
(ii) 修復: 色を塗りつぶします。リアルなコンテンツを含むユーザー指定の画像領域
(iii)切り抜き解除: 画像フレームの拡大
(iv)JPEG 回復:破損した JPEG 画像の回復
この論文では、著者らはマルチタスクの一般モデルと複数の特殊モデルの違いを調査しており、どちらも 100 万回の反復でトレーニングされています。モデルのアーキテクチャは、Dhariwal and Nichol 2021 のクラス条件付き U-Net モデルに基づいており、100 万のトレーニング ステップに対して 1024 画像のバッチ サイズを使用します。ノイズ プランをハイパーパラメータとして前処理および調整し、トレーニングと予測にさまざまなプランを使用します。

パレットの結果
ビジョン トランスフォーマー (ViT)
次の 2 つのモデルは画像変換用に特別に設計されたものではないことに注意してください。しかし、それらは、変圧器のような強力なモデルをコンピュータ ビジョンの分野に持ち込む上で明らかな前進です。
Vision Transformers (ViT) は、Transformers アーキテクチャ (Vaswani et al.、2017) を修正したもので、画像分類のために開発されました。モデルは画像を入力として受け取り、定義された各クラスに属する確率を出力します。
主な問題は、Transformer が 2 次元行列ではなく 1 次元シーケンスを入力として受け取るように設計されていることです。著者らは、並べ替えの際、画像を小さなチャンクに分割し、画像をシーケンス (または NLP の文) として、チャンクをトークン (または単語) として考えることを推奨しています。
簡単にまとめると、プロセス全体を 3 つの段階に分けることができます。
1) 埋め込み: 小さな部分を分割して平坦化する → 線形変換を適用する → クラス タグを追加する (このタグは画像として分類時に考慮される概要)→Position Embedding
2) Transformer-Encoder ブロック: 埋め込まれたパッチを一連の Transformer Encoder ブロックに配置します。注意メカニズムは、画像のどの部分に焦点を当てるかを学習します。
3) 分類 MLP ヘッダー: MLP ヘッダーを通じてクラス トークンを渡し、画像が各クラスに属する最終確率を出力します。
ViT を使用する利点: 配置は変更されません。 CNN と比較して、Transformer は画像内の移動 (要素の位置の変更) の影響を受けません。
欠点: トレーニングには大量のラベル付きデータが必要です (少なくとも 1,400 万の画像)
TransGAN
TransGAN は、画像生成と画像生成のために設計された変換ベースの GAN モデルです。畳み込み層は使用しません。代わりに、ジェネレーターとディスクリミネーターは、アップサンプリング ブロックとダウンサンプリング ブロックによって接続された一連のトランスフォーマーで構成されています。
ジェネレーターのフォワード パスは、ランダム ノイズ サンプルの 1 次元配列を取得し、MLP に渡します。直観的には、配列を文、ピクセル値を単語と考えることができます (64 要素の配列は 1 チャンネルの 8✕8 画像に再形成できることに注意してください)。次に、著者は一連の Transformer を適用します。ブロックの後に、配列 (画像) のサイズを 2 倍にするアップサンプリング レイヤーが続きます。
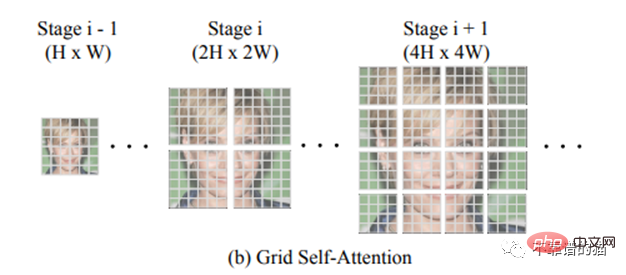
TransGAN の重要な機能は、グリッドセルフアテンションです。高次元の画像 (つまり、非常に長い配列 32✕32 = 1024) に到達する場合、1024 配列の各ピクセルを 255 個の可能なピクセルすべてと比較する必要があるため、トランスフォーマーを適用するとセルフ アテンション メカニズムのコストが爆発的に増加する可能性があります ( RGB 次元)。したがって、グリッド セルフ アテンションは、特定のトークンと他のすべてのトークンの間の対応を計算する代わりに、全次元の特徴マップをいくつかの重複しないグリッドに分割し、各ローカル グリッドでのトークンの相互作用を計算します。
識別器のアーキテクチャは、前に引用した ViT と非常によく似ています。

さまざまなデータセットでの TransGAN の結果
以上が画像翻訳用の 5 つの有望な AI モデルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。