
ホームページ >テクノロジー周辺機器 >AI >Meta の革新的な SOTA モデルは、一文に基づいて素晴らしいビデオを生成し、インターネットの流行を引き起こします。
Meta の革新的な SOTA モデルは、一文に基づいて素晴らしいビデオを生成し、インターネットの流行を引き起こします。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-23 09:22:071610ブラウズ
段落をあげてビデオを作ってもらいますが、できますか?
メタは、「私にはできる」と言いました。
そのとおりです。AI を使用すると、映画製作者になることもできます。
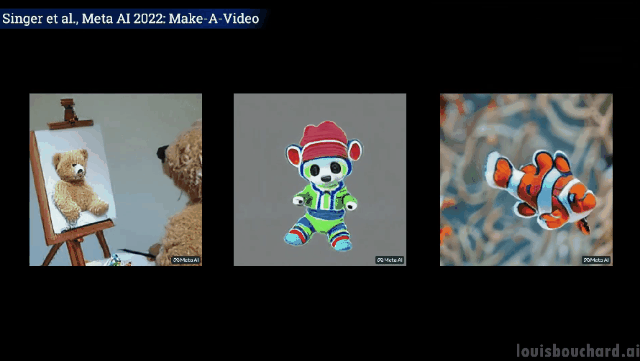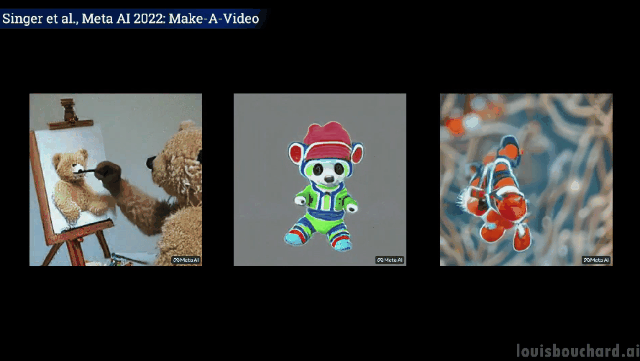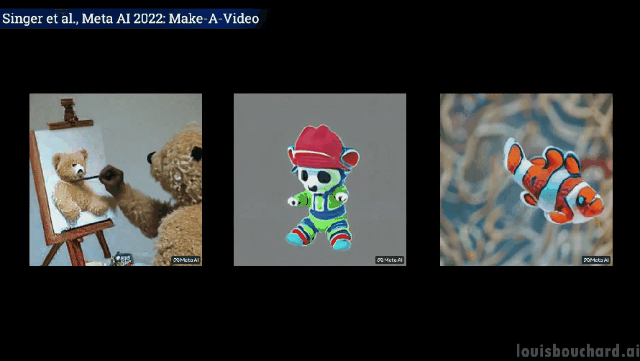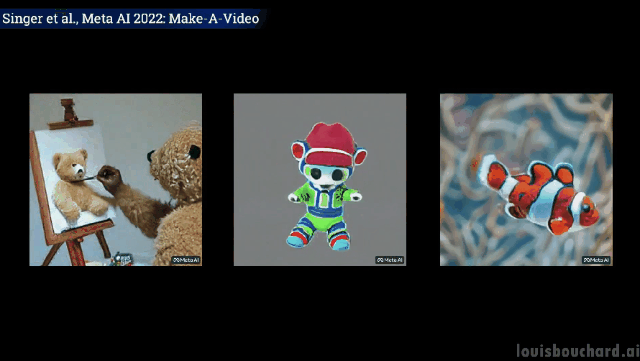
最近、Meta は Make-A-Video という非常にわかりやすい名前の新しい AI モデルを発表しました。
#このモデルはどのくらい強力ですか?
たった一文で「三頭の馬が疾走する」シーンが実現します。

ルカンでさえ、来るはずのものは必ず来ると言いました。

早速、その効果を見てみましょう。
#2 頭のカンガルーが台所で忙しく料理をしています (食べられるかどうかは別問題です)








もちろん、テキストをビデオに変換することに加えて、Make-A-Video は静止画像を Gif に変換することもできます。 ############入出力:############# ##
入力:

出力: (光が少し場違いに見えます)

静止画 2 枚を GIF に変換し、隕石画像を入力


#入力出力:
 入力出力:
入力出力:
technicalprinciple
 #紙のアドレス: https://makeavideo.studio/Make-A-Video.pdf
#紙のアドレス: https://makeavideo.studio/Make-A-Video.pdf
#このモデルが登場する前に、すでに安定拡散がありました。

賢い科学者はすでに AI に、たった 1 文で画像を生成するよう依頼しています。彼らは次に何をするのでしょうか?
明らかに、それはビデオを生成するためです。 
#赤いマントをかぶったスーパーヒーローの犬が空を飛ぶ
##画像の生成に比べて、ビデオの生成ははるかに困難です。同じ被写体やシーンの複数のフレームを生成する必要があるだけでなく、それらをタイムリーかつ一貫性のあるものにする必要もあります。
これにより、画像生成タスクが複雑になります。DALLE を使用して 60 枚の画像を生成し、それらをビデオにつなぎ合わせるだけでは済みません。効果は非常に乏しく、非現実的です。
したがって、より強力な方法で世界を理解し、このレベルの理解に基づいて一貫した一連の画像を生成できるモデルが必要です。そうして初めて、画像をシームレスに融合させることができます。

言い換えれば、私たちの目標は、世界をシミュレートし、その記録をシミュレートすることです。どうやってするの?
以前のアイデアによれば、研究者はモデルをトレーニングするために多数のテキストとビデオのペアを使用することになりますが、現在の状況では、この処理方法は現実的ではありません。これらのデータは入手が難しく、トレーニングのコストが非常に高価であるためです。
したがって、研究者たちは心を開いて、まったく新しいアプローチを採用しました。
彼らは、テキストから画像へのモデルを開発し、それをビデオに適用することを選択しました。
偶然にも、しばらく前に、Meta はテキストから画像へのモデルである Make-A-Scene を開発しました。
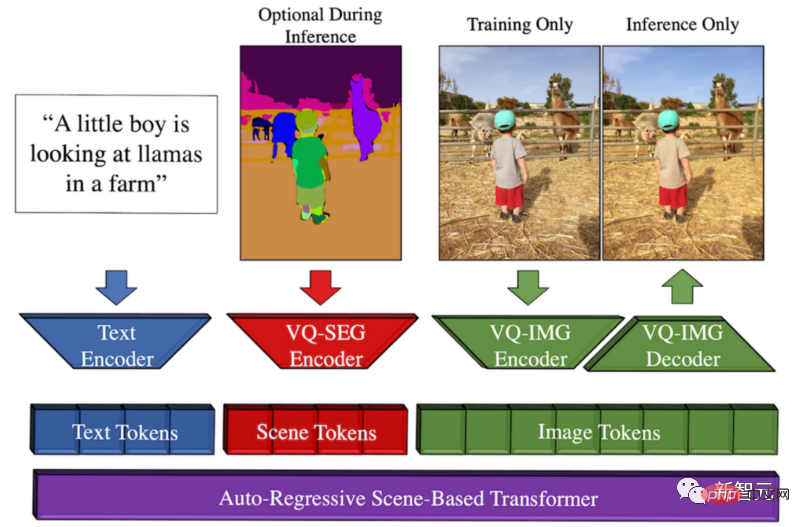
#Make-A-Scene メソッドの概要
このモデルは、チャンスは、Meta が、このテキストから画像へのトレンドと以前のスケッチから画像へのモデルを組み合わせて、クリエイティブな表現を促進したいと考えていることです。その結果、テキストとスケッチ条件付き画像生成の間の素晴らしい融合が実現します。
これは、猫をすばやくスケッチして、どのような画像が必要かを書き出すことができることを意味します。スケッチとテキストのガイダンスに従って、このモデルは私たちが望む完璧なイラストを数秒で作成します。

このマルチモーダルな生成 AI アプローチは、生成をより詳細に制御できる Dall-E モデルと考えることができます。これは、クイック スケッチも実行できるためです。入力として使用されます。
マルチモーダルと呼ばれる理由は、テキストや画像などの複数のモダリティを入力として受け取ることができるためです。対照的に、Dall-E はテキストからのみ画像を生成できます。
ビデオを生成するには、時間の次元を追加する必要があるため、研究者はメイク・ア・シーン モデルに時空間パイプラインを追加しました。
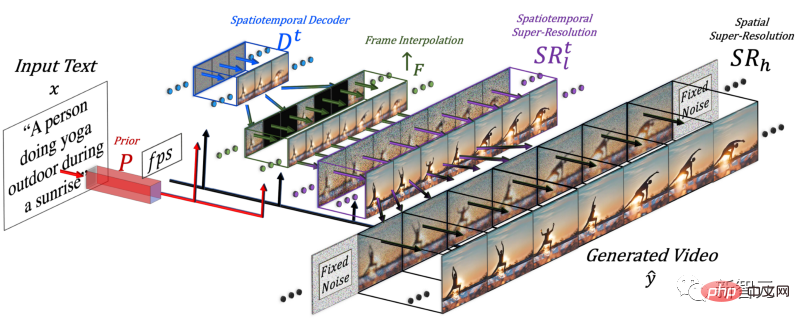
時間ディメンションを追加した後、このモデルは 1 枚の画像だけを生成するのではなく、16 枚の低解像度画像を生成して、一貫した短いビデオを作成します。 。
この方法は実際にはテキストから画像へのモデルに似ていますが、従来の 2 次元の畳み込みに基づいて 1 次元の畳み込みを追加する点が異なります。
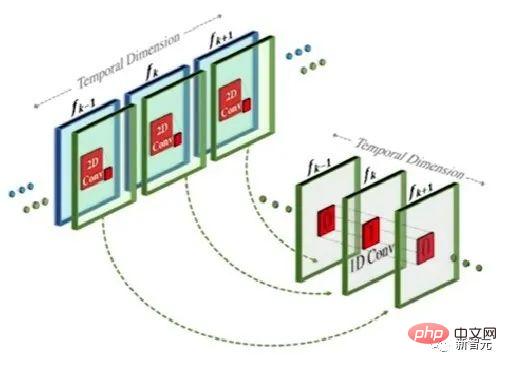
1 次元の畳み込みを追加するだけで、研究者は時間次元を追加しながら、事前にトレーニングされた 2 次元の畳み込みを変更せずに維持することができました。 。研究者は、Make-A-Scene 画像モデルのコードとパラメータの多くを再利用して、最初からトレーニングすることができます。
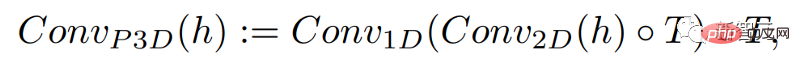
同時に、研究者らはテキスト入力を使用してこのモデルをガイドしたいとも考えています。これは、CLIP 埋め込みを使用した画像モデルと非常によく似ています。 。
この場合、研究者らは、上記と同じ方法を使用して、テキストの特徴と画像の特徴を混合するときに空間次元を増加しました。つまり、Make-A-Scene モデルにアテンション モジュールを保持し、そして、時間用の 1 次元アテンション モジュールを追加します。画像ジェネレーター モデルをコピー&ペーストし、もう 1 次元に対して生成モジュールを繰り返して、16 個の初期フレームを取得します。
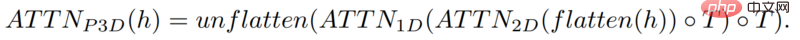
研究者は、これら 16 個のメイン フレームから高解像度ビデオを作成する必要があります。彼らのアプローチは、以前と将来のフレームにアクセスし、それらを時間次元と空間次元の両方で同時に反復的に補間することです。 このようにして、これらの 16 個の最初のフレームの間に、前後のフレームに基づいて新しい大きなフレームが生成されるため、動きが一貫性を持ち、ビデオ全体がスムーズになりました。 。 これはフレーム補間ネットワークを通じて行われ、既存の画像を取得してギャップを埋め、中間情報を生成できます。空間次元でも同じことを行います。画像を拡大し、ピクセルの隙間を埋め、画像をより高解像度にします。 要約すると、ビデオを生成するために、研究者たちはテキストから画像へのモデルを微調整しました。彼らは、すでにトレーニング済みの強力なモデルを使用し、ビデオに合わせて微調整し、トレーニングしました。 空間モジュールと時間モジュールが追加されたため、モデルを再トレーニングすることなく、この新しいデータにモデルを適応させるだけで、大幅なコストが節約されます。 この種の再トレーニングでは、ラベルのないビデオを使用し、モデルにビデオとビデオ フレームの一貫性を理解するように教えるだけでよいため、データ セットの構築が容易になります。 最後に、研究者らは画像最適化モデルを再度使用して空間解像度を向上させ、フレーム補間コンポーネントを使用してフレームを追加してビデオをより滑らかにしました。 もちろん、Make-A-Video の現在の結果には、テキストから画像へのモデルと同様に、まだ欠点があります。しかし、AI 分野の進歩がいかに急速であるかは誰もが知っています。 さらに詳しく知りたい場合は、リンクにある Meta AI の論文を参照してください。コミュニティは PyTorch 実装も開発しているため、自分で実装したい場合は注目してください。 この論文には多くの中国人研究者が参加しています: ying Xi、An Jie、Zhang Songyang、Qiyuan Hu 。 イン・シー、FAIR 研究科学者。以前は Microsoft で Microsoft Cloud と AI の上級アプリケーション サイエンティストとして働いていました。彼は、2013 年にミシガン州立大学のコンピューター科学工学部で博士号を取得し、武漢大学で電気工学の学士号を取得しました。主な研究分野は、マルチモーダル理解、大規模ターゲット検出、顔推論などです。 Anjie は、ロチェスター大学のコンピューター サイエンス学部の博士課程の学生です。ロジャー・ボー教授に師事。以前は2016年と2019年に北京大学で学士号と修士号を取得しています。研究対象には、コンピューター ビジョン、深層生成モデル、AI アートなどがあります。 Make-A-Videoのリサーチにインターンとして参加。 Zhang Songyang は、ロチェスター大学コンピューター サイエンス学部の博士課程の学生で、ロジャー ボー教授の下で勉強しています。東南大学で学士号を取得し、浙江大学で修士号を取得しました。研究対象には、自然言語モーメントローカリゼーション、教師なし文法帰納、スケルトンベースの動作認識などが含まれます。 Make-A-Videoのリサーチにインターンとして参加。 当時 FAIR の AI レジデントだった Qiyuan Hu は、人間の創造性を向上させるマルチモーダル生成モデルの研究に従事していました。彼女はシカゴ大学で医学物理学の博士号を取得し、AI を利用した医療画像解析に取り組みました。現在、Tempus Labs で機械学習科学者として働いています。 少し前に、Google や他の大手企業が、Parti などの独自のテキストから画像へのモデルをリリースしました。 テキストからビデオへの生成モデルはまだしばらく先のことだと考える人もいます。 予想外なことに、今回メタは爆弾を投下しました。 実際、現在、ICLR 2023 に提出されたテキストからビデオへの生成モデル Phenaki もあります。まだブラインドレビューの段階にあるため、作成者の機関はまだ不明です。 ネチズンは、DALLE から Stable Diffuson、Make-A-Video まで、すべての出来事があまりにも速すぎると述べました。 
著者紹介
ネチズンはショックを受けました


 #
#
以上がMeta の革新的な SOTA モデルは、一文に基づいて素晴らしいビデオを生成し、インターネットの流行を引き起こします。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。