
ホームページ >バックエンド開発 >Python チュートリアル >一般的に使用される Python データ視覚化ライブラリは何ですか?
一般的に使用される Python データ視覚化ライブラリは何ですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-22 16:16:081440ブラウズ

Python でのデータ視覚化にはどのライブラリを使用しますか?
今日は、Python データ視覚化ライブラリの強力なメンバーである Altair を紹介します。
これは非常にシンプルでフレンドリーで、強力な Vega-Lite JSON 仕様に基づいて構築されており、短いコードだけで美しく効果的なビジュアライゼーションを生成できます。
Altair とは
Altair は統計視覚化 Python ライブラリであり、現在 GitHub に 3,000 個以上のスターが登録されています。
Altair を使用すると、データ自体とその意味の理解により多くのエネルギーと時間を集中でき、複雑なデータ視覚化プロセスから解放されます。
簡単に言えば、Altair は、インタラクティブなビジュアル デザインを作成、保存、共有するためのビジュアル文法および宣言型言語であり、JSON 形式を使用して視覚的な外観とインタラクション プロセスを記述し、ネットワーク ベースのイメージを生成できます。
Altair を使用して作成されたビジュアライゼーション効果を見てみましょう。
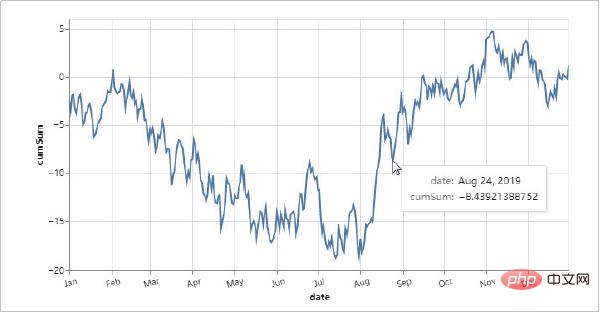
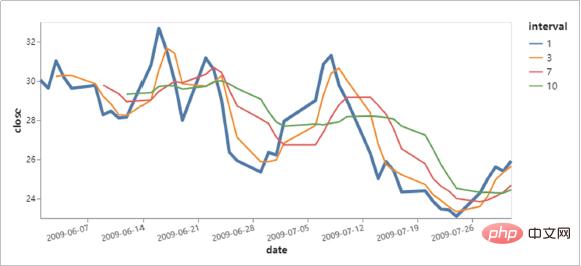
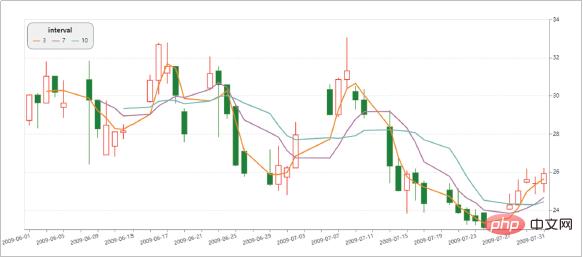
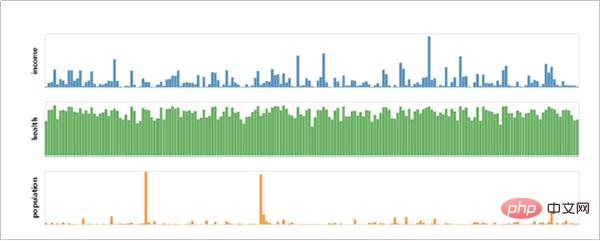
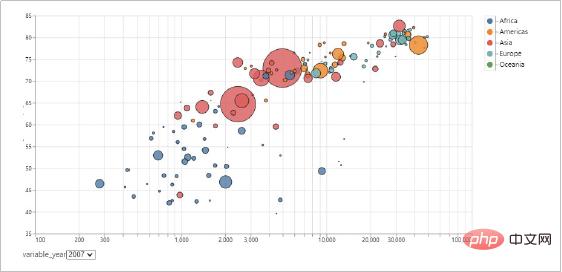
- グラフィカル構文に基づく宣言型 Python API。
- Vega-Lite の JSON 構文ルールに基づいて Altair の Python コードを生成します。
- 起動した Jupyter Notebook、JupyterLab、interact での統計可視化プロセスを表示します。
- ビジュアライゼーション作業を PNG/SVG 形式の画像、独立して実行できる HTML 形式の Web ページとしてエクスポートしたり、オンライン Vega-Lite エディタで実行中の効果を表示したりできます。
import altair as alt import pandas as pd data = pd.read_excel( "Index_Chart_Altair.xlsx", sheet_name="Sales", parse_dates=["Year"] ) alt.Chart( data )クイック テスト - 棒グラフの作成Altair変数の区別とタイプの組み合わせに重点を置きます。変数の値はデータであり、数値、文字列、日付などの形式で表現できる差異があります。変数はデータのストレージ コンテナであり、データは変数のストレージ ユニットの内容です。 一方、統計的サンプリングの観点から見ると、変数は母集団、データはサンプルであり、母集団の調査と分析にはサンプルを使用する必要があります。統計グラフは、データをより直観的に理解できるように、さまざまな変数タイプを相互に組み合わせて生成できます。 異なる変数の型の組み合わせに応じて、変数の型の組み合わせは次のタイプに分類できます。
- 名目変数 量的変数。
- 時間型変数 数量型変数。
- 時間変数 名目上の変数。
- 量的変数 量的変数。
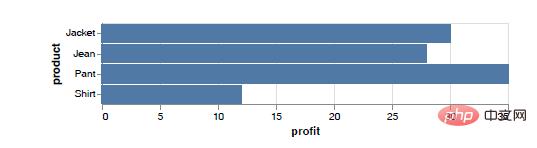
chart = alt.Chart(df).mark_bar().encode(x="profit:Q",y="product:N")複雑なグラフも非常にシンプルです さまざまな年の月平均降水量をパーティションごとに示してみましょう。
我们可以使用面积图描述西雅图从2012 年到2015 年的每个月的平均降雨量统计情况。接下来,进一步拆分平均降雨量,以年份为分区标准,使用阶梯图将具体年份的每月平均降雨量分区展示,如下图所示。
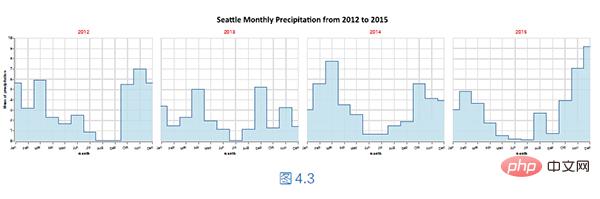
核心的实现代码如下所示。
…
chart = alt.Chart(df).mark_area(
color="lightblue",
interpolate="step",
line=True,
opacity=0.8
).encode(
alt.X("month(date):T",
axis=alt.Axis(format="%b",
formatType="time",
labelAngle=-15,
labelBaseline="top",
labelPadding=5,
title="month")),
y="mean(precipitation):Q",
facet=alt.Facet("year(date):Q",
columns=4,
header=alt.Header(
labelColor="red",
labelFontSize=15,
title="Seattle Monthly Precipitation from 2012 to 2015",
titleFont="Calibri",
titleFontSize=25,
titlePadding=15)
)
0)
…在类alt.X()中,使用month 提取时间型变量date 的月份,映射在位置通道x轴上,使用汇总函数mean()计算平均降雨量,使用折线作为编码数据的标记样式。
在实例方法encode()中,使用子区通道facet 设置分区,使用year 提取时间型变量date 的年份,作为拆分从2012 年到2015 年每个月的平均降雨量的分区标准,从而将每年的不同月份的平均降雨量分别显示在对应的子区上。使用关键字参数columns设置子区的列数,使用关键字参数header 设置子区序号和子区标题的相关文本内容。
具体而言,使用Header 架构包装器设置文本内容,也就是使用类alt.Header()的关键字参数完成文本内容的设置任务,关键字参数的含义如下所示。
- labelColor:序号标签颜色。
- labelFontSize:序号标签大小。
- title:子区标题。
- titleFont:子区字体。
- titleFontSize:子区字体大小。
- titlePadding:子区标题与序号标签的留白距离。
以上が一般的に使用される Python データ視覚化ライブラリは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。