



データ サイエンスの場合、通常、Python はデータの処理と変換に広く使用されています。Python は、データ処理をより柔軟にするための強力なデータ構造処理関数を提供します。ここでの「柔軟性」とは何を意味しますか?
これは、 Python では同じ結果を達成するには常に複数の方法がありますが、常にさまざまな方法があり、使いやすく、時間を節約し、より適切に制御できる方法を選択する必要があります。
これらの方法をすべてマスターすることは不可能です。そこで、あらゆる種類のデータを扱うときに知っておくべき Python の 4 つのヒントのリストをここに示します。

リスト内包表記 リスト内包表記は、リストを作成するためのエレガントで最も Python フレンドリーな方法です。 for ループや if ステートメントと比較すると、リスト内包表記では、既存のリストの値に基づいて新しいリストを作成するための構文がはるかに短くなります。それでは、この機能がリストのコピーをどのように取得するかを見てみましょう。
リスト内包表記を使用したリストのコピー
既存のリストのコピーを作成する必要がある場合があります。最も単純な答えは .copy() です。これを使用すると、あるリストの内容を別の (新しい) リストにコピーできます。
たとえば、整数のリストoriginal_list。
original_list = [10,11,20,22,30,34]
このリストは、.copy() メソッドを使用して簡単にコピーできます。
duplicated_list = original_list.copy()
リスト内包表記はまったく同じ出力を取得できます。リストのコピーは、リストの内包理解を理解するための良い例です。
以下のコードを見てください。
duplicated_list = [item for item in original_list]
これは、リストをコピーするときにリスト内包表記を使用する方が良いと言っているわけではありませんが、このケースがリスト内包表記の作業方法を導入するのに最適であると言っているのです。
次に、リストの内包表記によって、リストの各要素に対して数学的演算を実行する際の作業がどのように簡単になるかを見てみましょう。
リスト内の要素を乗算する
乗算の最も簡単または直接的な方法は、乗算演算子を使用することです。これは、*
たとえば、スカラー (つまり、数値 5) リスト内の各項目を乗算します。ここでは、リストのコピーが 5 つ作成されるため、original_list*5 を使用することはできません。
このシナリオでは、次に示すように、リスト内包表記が最適な答えになります。
original_list = [10,11,20,22,30,34] multiplied_list = [item*5 for item in original_list] # Output [50, 55, 100, 110, 150, 170]
ここでの演算は数値の乗算に限定されません。元のリストの各要素に対して複雑な操作を実行できます。
たとえば、各項の平方根の 3 乗を計算するとします。これは 1 行で解決できます。
multiplied_list = [math.sqrt(item)**3 for item in original_list] # Output [31.6227766016838, 36.4828726939094, 89.4427190999916, 103.18914671611546, 164.31676725154983, 198.25236442474025]
数値の平方根の計算に使用される関数 sqrt はライブラリ math に属しているため、この例で使用する前にインポートする必要があります。
上記の組み込み関数と同様に、リストの各要素でユーザー定義関数を使用することもできます。
たとえば、次のような単純な関数です。
def simple_function(item): item1 = item*10 item2 = item*11 return math.sqrt(item1**2 + item2**2)
このユーザー定義関数は、リスト内の各項目に適用できます。
multiplied_list = [simple_function(item) for item in original_list] # Output [148.66068747318505, 163.52675622050356, 297.3213749463701, 327.0535124410071, 445.9820624195552, 505.4463374088292]
リスト内包表記は、実際のシナリオではさらに役立ちます。通常、分析タスクでは、nan 要素を削除するなど、リストから特定の種類の要素を削除する必要があります。リスト内包表記は、これらのタスクに最適なツールです。
リストからの要素の削除
特定の基準に基づいてデータをフィルタリングすることは、目的のデータ セットを選択する一般的なタスクの 1 つであり、同じロジックがリスト内包表記でも使用されます。
以下に示す数値のリストがあるとします。
original_list = [10, 22, -43, 0, 34, -11, -12, -0.1, 1]
このリストからは正の値のみを保持したいとします。したがって、論理的には、条件項目 > 0 について TRUE と評価される項目のみを保持したいと考えます。
new_list = [item for item in original_list if item > 0] # Output [10, 22, 34, 1]
if 句は負の値を削除するために使用されます。 if 句を使用して任意の条件を適用し、リストから任意の項目を削除できます。
たとえば、平方が 200 未満の項目をすべて削除したい場合は、以下のようにリスト合成で条件項目 **2 > 200 を指定するだけです。
new_list = [item for item in original_list if item**2 > 200] # Output [22, -43, 34]
実際のデータ セットを扱う場合、リスト項目をフィルタリングするための条件ははるかに複雑になる可能性がありますが、この方法は高速で理解しやすいです。
2 つのリストを辞書のキーと値のペアに変換するには、dict() を使用します。
2 つのリストの値から辞書を作成する必要がある場合があります。それらを 1 つずつ入力する代わりに、辞書内包表記 (dictionary comprehension) を使用できます。これは、辞書を作成するためのエレガントで簡潔な方法です!
Itはリスト内包表記とまったく同じように機能しますが、唯一の違いは、リスト内包表記を作成する場合は、すべてを [] などの角括弧で囲みますが、辞書内包表記では、すべてを中括弧で囲みます ({} など)。
以下に示すように、フィールドと詳細という 2 つのリストがあるとします。
fields = [‘name’, ‘country’, ‘age’, ‘gender’] details = [‘pablo’, ‘Mexico’, 30, ‘Male’]
簡単な方法は、次のような辞書内包表記を使用することです -
new_dict = {key: value for key, value in zip(fields, details)}
# Output
{'name': 'pablo', 'country': 'Mexico', 'age': 30, 'gender': 'Male'}ここで理解することが重要なのは、関数 zip がどのように機能するかです。
Python では、zip 関数は文字列、リスト、辞書などの反復可能なオブジェクトを入力として受け取り、それらをタプルに集約して返します。
つまり、この場合、zip はリスト フィールドと詳細から各項目のペアを形成します。辞書内包表記で key:value を使用する場合は、このタプルを個々のキーと値のペアに解凍するだけです。
Python の組み込み dict() コンストラクター (辞書作成用) を使用すると、dict() は辞書内包表記より少なくとも 1.3 倍高速になるため、このプロセスはさらに高速になります。
したがって、このコンストラクターを zip() 関数で使用する必要があります。その構文ははるかに単純です - dict(zip(fields,details))
概要
で述べたように、まず、Python は同じ結果を達成する方法が複数あるため、非常に柔軟です。タスクの複雑さに応じて、それを達成するための最適な方法を選択する必要があります。
この記事があなたのお役に立てれば幸いです。この記事で述べたのと同じことを行う別の方法がある場合は、お知らせください。
以上がコードをより効率的にするための 4 つの Python 演繹的開発テクニックの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Nuitka简介:编译和分发Python的更好方法Apr 13, 2023 pm 12:55 PM
Nuitka简介:编译和分发Python的更好方法Apr 13, 2023 pm 12:55 PM译者 | 李睿审校 | 孙淑娟随着Python越来越受欢迎,其局限性也越来越明显。一方面,编写Python应用程序并将其分发给没有安装Python的人员可能非常困难。解决这一问题的最常见方法是将程序与其所有支持库和文件以及Python运行时打包在一起。有一些工具可以做到这一点,例如PyInstaller,但它们需要大量的缓存才能正常工作。更重要的是,通常可以从生成的包中提取Python程序的源代码。在某些情况下,这会破坏交易。第三方项目Nuitka提供了一个激进的解决方案。它将Python程序编
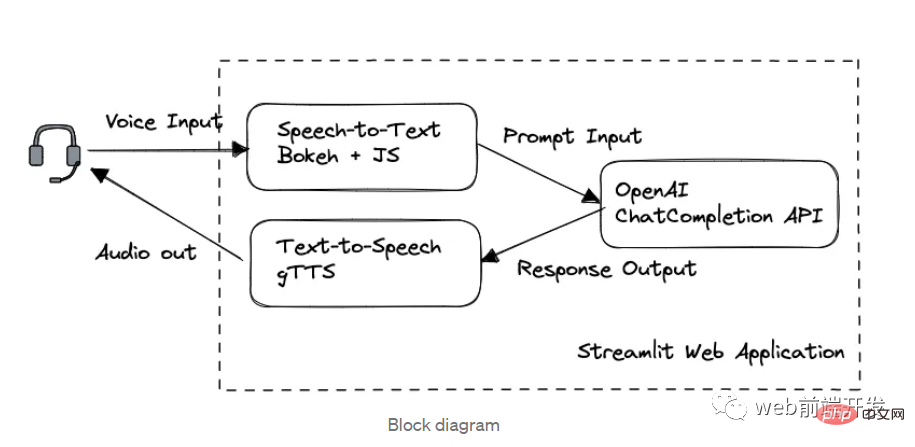 我创建了一个由 ChatGPT API 提供支持的语音聊天机器人,方法请收下Apr 07, 2023 pm 11:01 PM
我创建了一个由 ChatGPT API 提供支持的语音聊天机器人,方法请收下Apr 07, 2023 pm 11:01 PM今天这篇文章的重点是使用 ChatGPT API 创建私人语音 Chatbot Web 应用程序。目的是探索和发现人工智能的更多潜在用例和商业机会。我将逐步指导您完成开发过程,以确保您理解并可以复制自己的过程。为什么需要不是每个人都欢迎基于打字的服务,想象一下仍在学习写作技巧的孩子或无法在屏幕上正确看到单词的老年人。基于语音的 AI Chatbot 是解决这个问题的方法,就像它如何帮助我的孩子要求他的语音 Chatbot 给他读睡前故事一样。鉴于现有可用的助手选项,例如,苹果的 Siri 和亚马
 ChatGPT 的五大功能可以帮助你提高代码质量Apr 14, 2023 pm 02:58 PM
ChatGPT 的五大功能可以帮助你提高代码质量Apr 14, 2023 pm 02:58 PMChatGPT 目前彻底改变了开发代码的方式,然而,大多数软件开发人员和数据专家仍然没有使用 ChatGPT 来改进和简化他们的工作。这就是为什么我在这里概述 5 个不同的功能,以提高我们的日常工作速度和质量。我们可以在日常工作中使用它们。现在,我们一起来了解一下吧。注意:切勿在 ChatGPT 中使用关键代码或信息。01.生成项目代码的框架从头开始构建新项目时,ChatGPT 是我的秘密武器。只需几个提示,它就可以生成我需要的代码框架,包括我选择的技术、框架和版本。它不仅为我节省了至少一个小时
 解决Batch Norm层等短板的开放环境解决方案Apr 26, 2023 am 10:01 AM
解决Batch Norm层等短板的开放环境解决方案Apr 26, 2023 am 10:01 AM测试时自适应(Test-TimeAdaptation,TTA)方法在测试阶段指导模型进行快速无监督/自监督学习,是当前用于提升深度模型分布外泛化能力的一种强有效工具。然而在动态开放场景中,稳定性不足仍是现有TTA方法的一大短板,严重阻碍了其实际部署。为此,来自华南理工大学、腾讯AILab及新加坡国立大学的研究团队,从统一的角度对现有TTA方法在动态场景下不稳定原因进行分析,指出依赖于Batch的归一化层是导致不稳定的关键原因之一,另外测试数据流中某些具有噪声/大规模梯度的样本
 摔倒检测-完全用ChatGPT开发,分享如何正确地向ChatGPT提问Apr 07, 2023 pm 03:06 PM
摔倒检测-完全用ChatGPT开发,分享如何正确地向ChatGPT提问Apr 07, 2023 pm 03:06 PM哈喽,大家好。之前给大家分享过摔倒识别、打架识别,今天以摔倒识别为例,我们看看能不能完全交给ChatGPT来做。让ChatGPT来做这件事,最核心的是如何向ChatGPT提问,把问题一股脑的直接丢给ChatGPT,如:用 Python 写个摔倒检测代码 是不可取的, 而是要像挤牙膏一样,一点一点引导ChatGPT得到准确的答案,从而才能真正让ChatGPT提高我们解决问题的效率。今天分享的摔倒识别案例,与ChatGPT对话的思路清晰,代码可用度高,按照GPT返回的结果完全可以开
 17 个可以实现高效工作与在线赚钱的 AI 工具网站Apr 11, 2023 pm 04:13 PM
17 个可以实现高效工作与在线赚钱的 AI 工具网站Apr 11, 2023 pm 04:13 PM自 2020 年以来,内容开发领域已经感受到人工智能工具的存在。1.Jasper AI网址:https://www.jasper.ai在可用的 AI 文案写作工具中,Jasper 作为那些寻求通过内容生成赚钱的人来讲,它是经济实惠且高效的选择之一。该工具精通短格式和长格式内容均能完成。Jasper 拥有一系列功能,包括无需切换到模板即可快速生成内容的命令、用于创建文章的高效长格式编辑器,以及包含有助于创建各种类型内容的向导的内容工作流,例如,博客文章、销售文案和重写。Jasper Chat 是该
 为什么特斯拉的人形机器人长得并不像人?一文了解恐怖谷效应对机器人公司的影响Apr 14, 2023 pm 11:13 PM
为什么特斯拉的人形机器人长得并不像人?一文了解恐怖谷效应对机器人公司的影响Apr 14, 2023 pm 11:13 PM1970年,机器人专家森政弘(MasahiroMori)首次描述了「恐怖谷」的影响,这一概念对机器人领域产生了巨大影响。「恐怖谷」效应描述了当人类看到类似人类的物体,特别是机器人时所表现出的积极和消极反应。恐怖谷效应理论认为,机器人的外观和动作越像人,我们对它的同理心就越强。然而,在某些时候,机器人或虚拟人物变得过于逼真,但又不那么像人时,我们大脑的视觉处理系统就会被混淆。最终,我们会深深地陷入一种对机器人非常消极的情绪状态里。森政弘的假设指出:由于机器人与人类在外表、动作上相似,所以人类亦会对
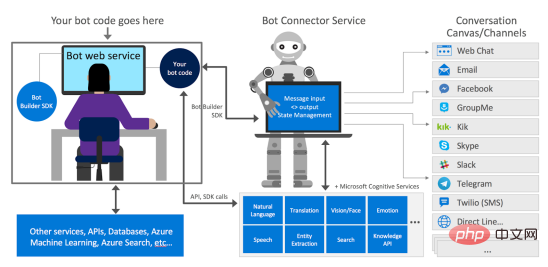 如何使用Azure Bot Services创建聊天机器人的分步说明Apr 11, 2023 pm 06:34 PM
如何使用Azure Bot Services创建聊天机器人的分步说明Apr 11, 2023 pm 06:34 PM译者 | 李睿审校 | 孙淑娟信使、网络服务和其他软件都离不开机器人(bot)。而在软件开发和应用中,机器人是一种应用程序,旨在自动执行(或根据预设脚本执行)响应用户请求创建的操作。在本文中, NIX United公司的.NET开发人员Daniil Mikhov介绍了使用微软Azure Bot Services创建聊天机器人的一个例子。本文将对想要使用该服务开发聊天机器人的开发人员有所帮助。 为什么使用Azure Bot Services? 在Azure Bot Services上开发聊


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

Dreamweaver Mac版
ビジュアル Web 開発ツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません
ホットトピック
 7412
7412 15135952
15135952