



コホート分析
コホート分析の概念
コホートとは、文字通り、異なる性別や異なる年齢などの (共通の特性または類似の行動を持つ) 人々のグループを意味します。
コホート分析: 類似したグループの変化を経時的に比較します。
製品は、開発とテスト中に繰り返し行われるため、製品リリースの最初の週に参加したユーザーは、その後に参加したユーザーとは異なるエクスペリエンスを得ることができます。たとえば、各ユーザーは、無料試用から有料使用、そして最終的に使用停止というライフサイクルを経ます。同時に、この期間中、ビジネス モデルの調整を常に行っています。したがって、製品発売後最初の 1 か月で「カニを食べる」ユーザーは、4 か月後に入会したユーザーとは異なるオンボーディング エクスペリエンスを体験するはずです。これは解約率にどのような影響を及ぼしますか?それを調べるためにコホート分析を使用しました。
ユーザーの各グループはコホートを形成し、実験プロセス全体に参加します。さまざまなコホートを比較することで、主要な指標の全体的なパフォーマンスが向上しているかどうかを知ることができます。
異なる月に獲得したユーザー、異なるチャネルからの新規ユーザー、異なる特性を持つユーザー (WeChat 上で少なくとも 10 人の友人と通信する WeChat 上のユーザーなど) などのユーザー分析レベルと組み合わせる毎日)。
コホート分析は、時間次元での行動の違いを発見するために、異なる特性を持つこれらの人々のグループを比較分析します。
したがって、コホート分析は主に次の 2 つの点で使用されます。
同じ経験サイクル内の異なるコホート グループのデータ指標を比較して、商品の効果を検証する反復の最適化
同じコホート グループのさまざまなエクスペリエンス サイクル (ライフ サイクル) のデータ指標を比較し、長期エクスペリエンスの問題を発見します
グループ化ロジック を決定する工程と、コホート分析の 主要データ指標 を決定する工程に大きく分けられます。
- 同様の行動特性を持つグループ
- 同じ期間のグループ
- #顧客獲得月別 (週または日ごとにグループ化)
- #顧客獲得チャネル別
- ユーザーが Web サイトにアクセスした回数や購入回数など、ユーザーが完了した特定のアクションに応じたカテゴリ。
- 主要なデータ指標に関しては、保持、収益、自己伝播係数などの時間次元に基づく必要があります。
以下はあるeコマース企業の営業データです。このデータは、Python コホート分析を使用して実証します。 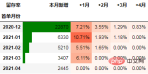
コホート分析ケースの詳細な説明:
データは、e コマース ユーザーの支払いログです。ログ フィールドには、日付、支払い金額、ユーザー ID が含まれます。鈍感になった。
データの読み取りimport pandas as pd df = pd.read_csv('日志.csv', encoding="gb18030") df.head()
分析方向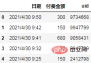
主要なデータ インジケーター:
このデータでは、分析できるデータ インジケーターが少なくとも 3 つあります:
維持率- 一人当たりの支払額
- 一人当たりの購入数
- データの前処理
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
df.head()
各月の各ユーザーの支払い総額を計算します: 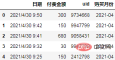
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额","sum"),
月付费次数=("uid","count"),
)
order.head()
各ユーザーの最初の購入月をコホート グループとして計算し、元のデータにマッピングします: 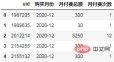
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order.head()
各購入レコードの時刻と最初の購入時刻の間の月差を計算し、月差ラベルをリセットします: 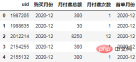
order["标签"] = (order.购买月份-order.首单月份).apply(lambda x:"同期群人数" if x.n==0 else f"+{x.n}月")
order.head()
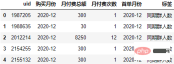 両方の月が期間タイプです、減算後、オブジェクト型の列が取得され、この列の各要素の型は pandas._libs.tslibs.offsets.MonthEnd
両方の月が期間タイプです、減算後、オブジェクト型の列が取得され、この列の各要素の型は pandas._libs.tslibs.offsets.MonthEnd
MonthEnd 型には、特定の差を返すことができる属性 n があります。整数。分析できるデータ指標が少なくとも 3 つあると前述しました: 定着率コホート分析
- お一人様あたりの支払金額
- お一人様あたりの購入数
从留存率角度进行同期群分析
通过数据透视表可以一次性计算所需的数据:
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number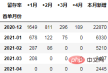
注意:rename_axis(columns=None)用于删除列标签的轴名称。rename_axis(columns=“留存率”)则设置轴名称为留存率。
将 本月新增 列移动到第一列:
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number
具体过程是先通过pop删除该列,然后插入到0位置,并命名为指定的列名。
在本次的分析中,留存率的具体计算方式为:+N月留存率=+N月付款用户数/首月付款用户数
cohort_number.iloc[:, 1:] = cohort_number.iloc[:, 1:].divide(cohort_number.本月新增, axis=0) cohort_number
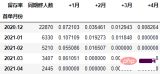
以百分比形式显示,并设置颜色:
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
out1
至此计算完毕。
从人均付款金额角度进行同期群分析
要从从人均付款金额角度考虑,需要考虑同期群基期这个整体。具体计算方式是先计算各月的付款总额,然后除以基期的总人数:
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out2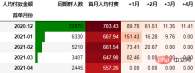
可以看到,12月份的同期群首月新用户人均消费为703.43元,然后逐月递减,到+4月后这些用户人均消费仅11.41元。而随着版本的迭代发展,新增用户的首月消费并没有较大提升,且接下来的消费趋势反而不如12月份。由此可见产品的发展受到了一定的瓶颈,需要思考增长营收的出路了。
一般来说, 通过同期群分析可以比较好指导我们后续更深入细致的数据分析,为产品优化提供参考。
从人均购买次数角度进行同期群分析
依然按照上面一样的套路:
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out3
可以得到类似上述一致的结论。
每月总体付费情况
下面我们看看每个月的总体消费情况:
order.groupby("购买月份").agg(
付费人数=("uid", "count"),
人均付款金额=("月付费总额", "mean"),
月付费总额=("月付费总额", "sum")
)
可以看到总体付费人数和付费金额都在逐月下降。
将结果导出网页或截图
对于Styler类型,我们可以调用render方法转化为网页源代码,通过以下方式即可将其导入到一个网页文件中:
with open("out.html", "w") as f:
f.write(out1.render())
f.write(out2.render())
f.write(out3.render())如果你的电脑安装了谷歌游览器,还可以安装dataframe_image,将这个表格导出为图片。
安装:pip install dataframe_image
import dataframe_image as dfi dfi.export(obj=out1, filename='留存率.jpg') dfi.export(obj=out2, filename='人均付款金额.jpg') dfi.export(obj=out3, filename='人均购买次数.jpg')
dfi.export的参数:
obj : 被导出的Datafream对象
filename : 文件保存位置
fontsize : 字体大小
max_rows : 最大行数
max_cols : 最大列数
table_conversion : 使用谷歌游览器或原生’matplotlib’, 只要写非’chrome’的值就会使用原生’matplotlib’
chrome_path : 指定谷歌游览器位置
整体完整代码
import pandas as pd
import dataframe_image as dfi
df = pd.read_csv('日志.csv', encoding="gb18030")
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额", "sum"),
月付费次数=("uid", "count"),
)
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order["标签"] = (
order.购买月份-order.首单月份).apply(lambda x: "同期群人数" if x.n == 0 else f"+{x.n}月")
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number.iloc[:, 1:] = cohort_number.iloc[:,1:].divide(cohort_number.同期群人数, axis=0)
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
outs = [out1, out2, out3]
with open("out.html", "w") as f:
for out in outs:
f.write(out.render())
display(out)
dfi.export(obj=out1, filename='留存率.jpg')
dfi.export(obj=out2, filename='人均付款金额.jpg')
dfi.export(obj=out3, filename='人均购买次数.jpg')
以上がコホート分析にPythonを適用する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 numpyアレイは、アレイモジュールを使用して作成された配列とどのように異なりますか?Apr 24, 2025 pm 03:53 PM
numpyアレイは、アレイモジュールを使用して作成された配列とどのように異なりますか?Apr 24, 2025 pm 03:53 PMnumpyarraysarasarebetterfornumeroperations andmulti-dimensionaldata、whilethearraymoduleissuitable forbasic、1)numpyexcelsinperformance and forlargedatasentassandcomplexoperations.2)thearraymuremememory-effictientivearientfa
 Numpyアレイの使用は、Pythonで配列モジュール配列の使用と比較してどのように比較されますか?Apr 24, 2025 pm 03:49 PM
Numpyアレイの使用は、Pythonで配列モジュール配列の使用と比較してどのように比較されますか?Apr 24, 2025 pm 03:49 PMNumPyArraySareBetterforHeavyNumericalComputing、whilethearrayarayismoreSuitableformemory-constrainedprojectswithsimpledatatypes.1)numpyarraysofferarays andatiledance andpeperancedatasandatassandcomplexoperations.2)thearraymoduleisuleiseightweightandmemememe-ef
 CTypesモジュールは、Pythonの配列にどのように関連していますか?Apr 24, 2025 pm 03:45 PM
CTypesモジュールは、Pythonの配列にどのように関連していますか?Apr 24, 2025 pm 03:45 PMctypesallowsinging andmanipulatingc-stylearraysinpython.1)usectypestointerfacewithclibrariesforperformance.2)createc-stylearraysfornumericalcomputations.3)passarraystocfunctions foreffientientoperations.how、how、becuutiousmorymanagemation、performanceo
 Pythonのコンテキストで「配列」と「リスト」を定義します。Apr 24, 2025 pm 03:41 PM
Pythonのコンテキストで「配列」と「リスト」を定義します。Apr 24, 2025 pm 03:41 PMInpython、「リスト」は、「リスト」、自由主義的なもの、samememory効率が高く、均質な偶然の瞬間の想起された「アレイ」の「アレイ」の「アレイ」の均質な偶発的な想起されたものです
 Pythonリストは可変ですか、それとも不変ですか? Pythonアレイはどうですか?Apr 24, 2025 pm 03:37 PM
Pythonリストは可変ですか、それとも不変ですか? Pythonアレイはどうですか?Apr 24, 2025 pm 03:37 PMpythonlistsandarraysaraybothmutable.1)listsareflexibleandsupportheTeterdatabutarlessmemory-efficient.2)Arraysaremorememory-efficientiant forhomogeneousdative、ressivelessatile、ressing comerttytytypecodeusageodoavoiderorors。
 Python vs. C:重要な違いを理解しますApr 21, 2025 am 12:18 AM
Python vs. C:重要な違いを理解しますApr 21, 2025 am 12:18 AMPythonとCにはそれぞれ独自の利点があり、選択はプロジェクトの要件に基づいている必要があります。 1)Pythonは、簡潔な構文と動的タイピングのため、迅速な開発とデータ処理に適しています。 2)Cは、静的なタイピングと手動メモリ管理により、高性能およびシステムプログラミングに適しています。
 Python vs. C:プロジェクトのためにどの言語を選択しますか?Apr 21, 2025 am 12:17 AM
Python vs. C:プロジェクトのためにどの言語を選択しますか?Apr 21, 2025 am 12:17 AMPythonまたはCの選択は、プロジェクトの要件に依存します。1)迅速な開発、データ処理、およびプロトタイプ設計が必要な場合は、Pythonを選択します。 2)高性能、低レイテンシ、および緊密なハードウェアコントロールが必要な場合は、Cを選択します。
 Pythonの目標に到達する:毎日2時間のパワーApr 20, 2025 am 12:21 AM
Pythonの目標に到達する:毎日2時間のパワーApr 20, 2025 am 12:21 AM毎日2時間のPython学習を投資することで、プログラミングスキルを効果的に改善できます。 1.新しい知識を学ぶ:ドキュメントを読むか、チュートリアルを見る。 2。練習:コードと完全な演習を書きます。 3。レビュー:学んだコンテンツを統合します。 4。プロジェクトの実践:実際のプロジェクトで学んだことを適用します。このような構造化された学習計画は、Pythonを体系的にマスターし、キャリア目標を達成するのに役立ちます。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

Dreamweaver Mac版
ビジュアル Web 開発ツール

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。
ホットトピック
 7690
7690 15163914139352128725122929
15163914139352128725122929