
ホームページ >Java >&#&チュートリアル >Java スレッドの例外処理メカニズムとは何ですか?
Java スレッドの例外処理メカニズムとは何ですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-21 21:37:061371ブラウズ
まえがき
Java プログラムを開始するということは、基本的に Java クラスの main メソッドを実行することです。無限ループ プログラムを作成して実行し、jvisualvm を実行して観察します。
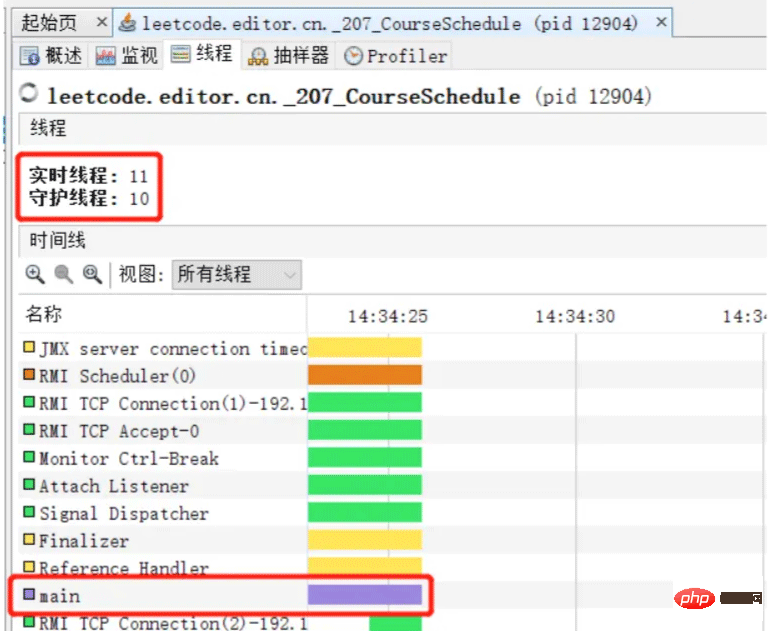
この中に合計 11 個のスレッドがあることがわかります。 Java プロセスには、10 個のデーモン スレッドと 1 個のユーザー スレッドがあります。 main メソッドのコードは、main という名前のスレッドで実行されます。 Java プロセスで実行されているすべてのスレッドがデーモン スレッドである場合、JVM は終了します。
CompletableFuture.runAsync を使用して時間のかかるタスクを非同期に処理するときに、タスクの処理中に例外が発生しましたが、ログには例外に関する情報がありませんでした。 。久しぶりにスレッドにおける例外処理の仕組みを見直し、スレッドの動作原理について理解を深めたので記録します。
javac を通じてクラス バイトコード ファイルにコンパイルされ、次にJVM クラス ファイルをロードして解析し、メイン クラスの main メソッドから実行を開始します。スレッドが動作中に uncaughtException をスローすると、JVM は例外処理のためにスレッド オブジェクトの dispatchUncaughtException メソッドを呼び出します。
// Thread类中
private void dispatchUncaughtException(Throwable e) {
getUncaughtExceptionHandler().uncaughtException(this, e);
}ソース コードは理解しやすいので、まず UncaughtExceptionHandler 例外ハンドラーを取得し、この例外ハンドラーの uncaughtException メソッドを呼び出して例外を処理します。 (以下では、UncaughtExceptionHandler を表すために、省略形 ueh が使用されています)
ueh とは何ですか?実際、これは Thread 内で定義されたインターフェイスであり、例外処理に使用されます。
@FunctionalInterface
public interface UncaughtExceptionHandler {
/**
* Method invoked when the given thread terminates due to the
* given uncaught exception.
* <p>Any exception thrown by this method will be ignored by the
* Java Virtual Machine.
* @param t the thread
* @param e the exception
*/
void uncaughtException(Thread t, Throwable e);
} Thread オブジェクトの getUncaughtExceptionHandler メソッドを見てみましょう。
public UncaughtExceptionHandler getUncaughtExceptionHandler() {
return uncaughtExceptionHandler != null ?
uncaughtExceptionHandler : group;
} まず、現在の Threadオブジェクトには設定があります カスタム ueh オブジェクトがある場合は、例外が処理されます。それ以外の場合は、現在の Thread オブジェクトが属するスレッド グループ (ThreadGroup)例外を処理します。オープン ソース コードをクリックすると、ThreadGroup クラス自体が Thread.UncaughtExceptionHandler インターフェイスを実装していることが簡単にわかります。これは、ThreadGroup 自体が例外であることを意味します。ハンドラ。
public class ThreadGroup implements Thread.UncaughtExceptionHandler {
private final ThreadGroup parent;
....
} main メソッドで例外をスローするとします。main スレッドにカスタム ueh オブジェクト セットがない場合、ハンドオーバーは例外は、main スレッドが属する ThreadGroup によって処理されます。 ThreadGroup が例外をどのように処理するかを見てみましょう:
public void uncaughtException(Thread t, Throwable e) {
if (parent != null) {
parent.uncaughtException(t, e);
} else {
Thread.UncaughtExceptionHandler ueh =
Thread.getDefaultUncaughtExceptionHandler();
if (ueh != null) {
ueh.uncaughtException(t, e);
} else if (!(e instanceof ThreadDeath)) {
System.err.print("Exception in thread \""
+ t.getName() + "\" ");
e.printStackTrace(System.err);
}
}
}ソース コードのこの部分も比較的短いです。 1 つ目は、現在の ThreadGroup に親の ThreadGroup があるかどうかを確認することです。存在する場合は、例外処理のために親の ThreadGroup を呼び出します。それ以外の場合は、静的メソッド Thread.getDefaultUncaughtExceptionHandler() を呼び出して、default ueh オブジェクトを取得します。
default ueh オブジェクトが空でない場合は、このデフォルトの ueh オブジェクトが例外処理を実行します。それ以外の場合は、例外が ThreadDeath、現在のスレッドの 名と例外スタック情報 を 標準エラー出力 (System.err) を通じてコンソールに直接出力します。 。
main メソッドを実行して、スレッドの状況を確認します。
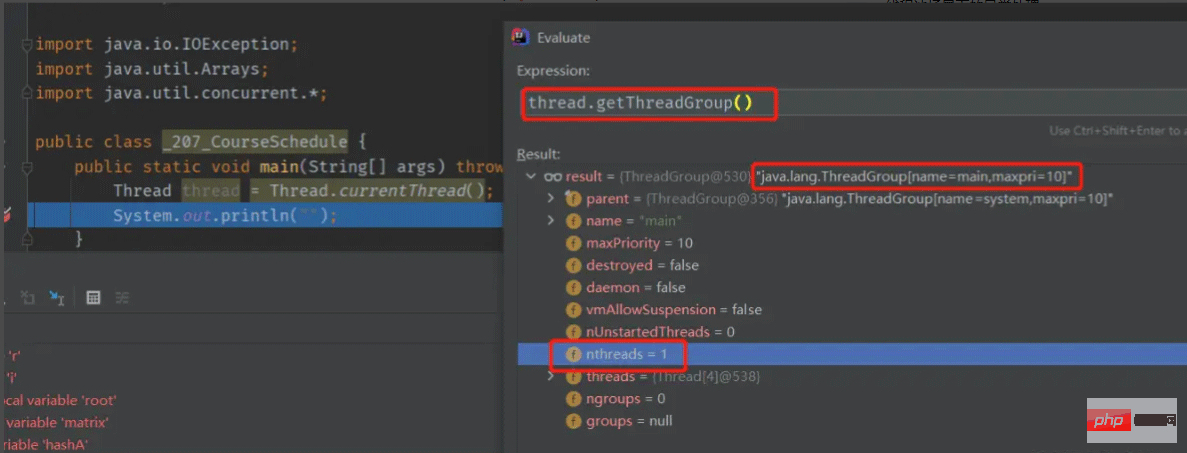
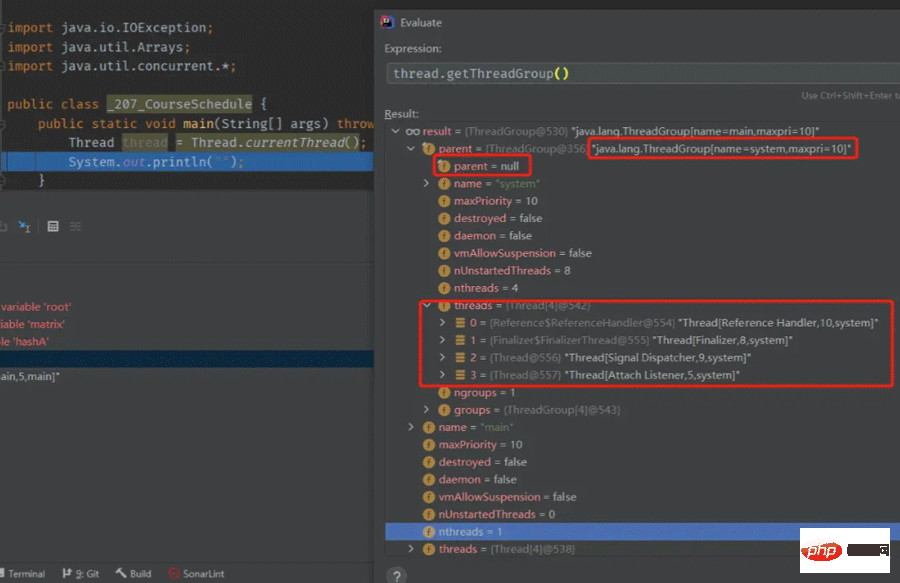
main スレッドは、main という名前の ThreadGroup に属しており、この main# の ThreadGroup であることがわかります。 ##、その親 ThreadGroup は system という名前ですが、この system の ThreadGroup には親がなく、ルート スレッドグループ。
スレッドでスローされたキャッチされなかった例外は、最終的に例外処理のために system という名前の ThreadGroup に渡されることがわかります。 、default の ueh オブジェクトが設定されていないため、例外情報は System.err を通じてコンソールに出力されます。 次に、最も簡単な方法で
スレッドにサブスレッド (new Thread) を作成し、サブスレッドに-thread スレッドに例外をスローしてそれを観察できるコードを作成します<pre class="brush:java;"> public static void main(String[] args) {
Thread thread = new Thread(() -> {
System.out.println(3 / 0);
});
thread.start();
}</pre><p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/168208422948065.png" class="lazy" alt="Java スレッドの例外処理メカニズムとは何ですか?"></p>
<p>子线程中的异常信息被打印到了控制台。异常处理的流程就是我们上面描述的那样。</p>
<h4>小结</h4>
<p>所以,正常来说,如果没有对某个线程设置特定的<code>ueh对象;也没有调用静态方法Thread.setDefaultUncaughtExceptionHandler设置全局默认的ueh对象。那么,在任意一个线程的运行过程中抛出未捕获异常时,异常信息都会被输出到控制台(当异常是ThreadDeath时则不会进行输出,但通常来说,异常都不是ThreadDeath,不过这个细节要注意下)。
如何设置自定义的ueh对象来进行异常处理?根据上面的分析可知,有2种方式
对某一个
Thread对象,调用其setUncaughtExceptionHandler方法,设置一个ueh对象。注意这个ueh对象只对这个线程起作用调用静态方法
Thread.setDefaultUncaughtExceptionHandler()设置一个全局默认的ueh对象。这样设置的ueh对象会对所有线程起作用
当然,由于ThreadGroup本身可以充当ueh,所以其实还可以实现一个ThreadGroup子类,重写其uncaughtException方法进行异常处理。
若一个线程没有进行任何设置,当在这个线程内抛出异常后,默认会将线程名称和异常堆栈,通过System.err进行输出。
线程池场景下的异常处理
在实际的开发中,我们经常会使用线程池来进行多线程的管理和控制,而不是通过new来手动创建Thread对象。
对于Java中的线程池ThreadPoolExecutor,我们知道,通常来说有两种方式,可以向线程池提交任务:
executesubmit
其中execute方法没有返回值,我们通过execute提交的任务,只需要提交该任务给线程池执行,而不需要获取任务的执行结果。而submit方法,会返回一个Future对象,我们通过submit提交的任务,可以通过这个Future对象,拿到任务的执行结果。
我们分别尝试如下代码:
public static void main(String[] args) {
ExecutorService threadPool = Executors.newSingleThreadExecutor();
threadPool.execute(() -> {
System.out.println(3 / 0);
});
} public static void main(String[] args) {
ExecutorService threadPool = Executors.newSingleThreadExecutor();
threadPool.submit(() -> {
System.out.println(3 / 0);
});
}容易得到如下结果:
通过execute方法提交的任务,异常信息被打印到控制台;通过submit方法提交的任务,没有出现异常信息。
我们稍微跟一下ThreadPoolExecutor的源码,当使用execute方法提交任务时,在runWorker方法中,会执行到下图红框的部分
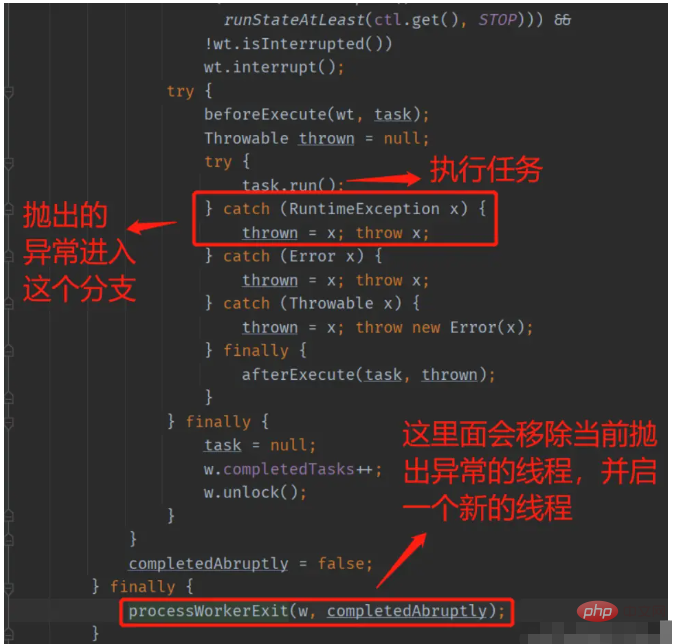
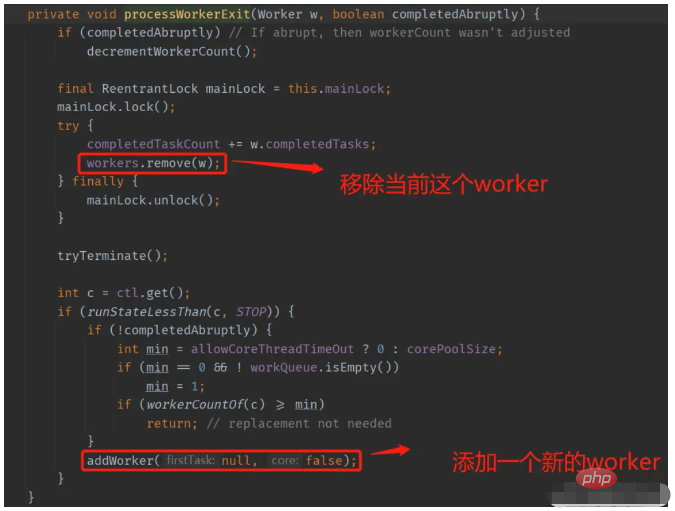
在上面的代码执行完毕后,由于异常被throw了出来,所以会由JVM捕捉到,并调用当前子线程的dispatchUncaughtException方法进行处理,根据上面的分析,最终异常堆栈会被打印到控制台。
多扯几句别的。
上面跟源码时,注意到Worker是ThreadPoolExecutor的一个内部类,也就是说,每个Worker都会隐式的持有ThreadPoolExecutor对象的引用(内部类的相关原理请自行补课)。每个Worker在运行时(在不同的子线程中运行)都能够对ThreadPoolExecutor对象(通常来说这个对象是在main线程中被维护)中的属性进行访问和修改。Worker实现了Runnable接口,并且其run方法实际是调用的ThreadPoolExecutor上的runWorker方法。在新建一个Worker时,会创建一个新的Thread对象,并把当前Worker的引用传递给这个Thread对象,随后调用这个Thread对象的start方法,则开始在这个Thread中(子线程中)运行这个Worker。
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}ThreadPoolExecutor中的addWorker方法
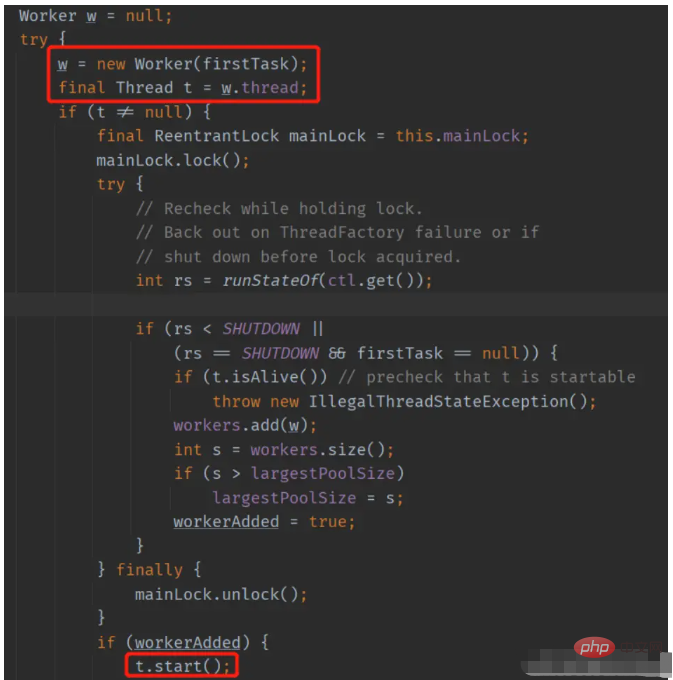
再次跟源码时,加深了对ThreadPoolExecutor和Worker体系的理解和认识。
它们之间有一种嵌套依赖的关系。每个Worker里持有一个Thread对象,这个Thread对象又是以这个Worker对象作为Runnable,而Worker又是ThreadPoolExecutor的内部类,这意味着每个Worker对象都会隐式的持有其所属的ThreadPoolExecutor对象的引用。每个Worker的run方法, 都跑在子线程中,但是这些Worker跑在子线程中时,能够对ThreadPoolExecutor对象的属性进行访问和修改(每个Worker的run方法都是调用的runWorker,所以runWorker方法是跑在子线程中的,这个方法中会对线程池的状态进行访问和修改,比如当前子线程运行过程中抛出异常时,会从ThreadPoolExecutor中移除当前Worker,并启一个新的Worker)。而通常来说,ThreadPoolExecutor对象的引用,我们通常是在主线程中进行维护的。
反正就是这中间其实有点骚东西,没那么简单。需要多跟几次源码,多自己打断点进行debug,debug过程中可以通过IDEA的Evaluate Expression功能实时观察当前方法执行时所处的线程环境(Thread.currentThread)。
扯得有点远了,现在回到正题。上面说了调用ThreadPoolExecutor中的execute方法提交任务,子线程中出现异常时,异常会被抛出,打印在控制台,并且当前Worker会被线程池回收,并重启一个新的Worker作为替代。那么,调用submit时,异常为何就没有被打印到控制台呢?
我们看一下源码:
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
} protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}通过调用submit提交的任务,被包装了成了一个FutureTask对象,随后会将这个FutureTask对象,通过execute方法提交给线程池,并返回FutureTask对象给主线程的调用者。
也就是说,submit方法实际做了这几件事
将提交的
Runnable,包装成FutureTask调用
execute方法提交这个FutureTask(实际还是通过execute提交的任务)将
FutureTask作为返回值,返回给主线程的调用者
关键就在于FutureTask,我们来看一下
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
} // Executors中
public static <T> Callable<T> callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter<T>(task, result);
} static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
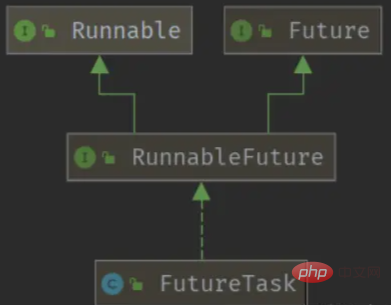
}通过submit方法传入的Runnable,通过一个适配器RunnableAdapter转化为了Callable对象,并最终包装成为一个FutureTask对象。这个FutureTask,又实现了Runnable和Future接口
于是我们看下FutureTask的run方法(因为最终是将包装后的FutureTask提交给线程池执行,所以最终会执行FutureTask的run方法)
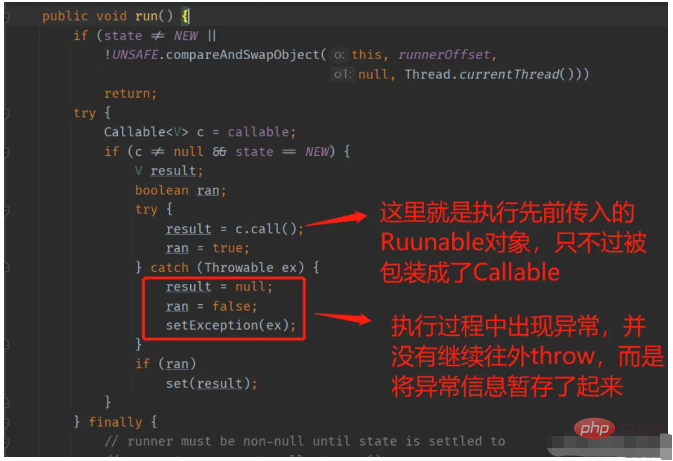
protected void setException(Throwable t) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = t;
UNSAFE.putOrderedInt(this, stateOffset, EXCEPTIONAL); // final state
finishCompletion();
}
}可以看到,异常信息只是被简单的设置到了FutureTask的outcome字段上。并没有往外抛,所以这里其实相当于把异常给生吞了,catch块中捕捉到异常后,既没有打印异常的堆栈,也没有把异常继续往外throw。所以我们无法在控制台看到异常信息,在实际的项目中,此种场景下的异常信息也不会被输出到日志文件。这一点要特别注意,会加大问题的排查难度。
那么,为什么要这样处理呢?
因为我们通过submit提交任务时,会拿到一个Future对象
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}我们可以在稍后,通过Future对象,来获知任务的执行情况,包括任务是否成功执行完毕,任务执行后返回的结果是什么,执行过程中是否出现异常。
所以,通过submit提交的任务,实际会把任务的各种状态信息,都封装在FutureTask对象中。当最后调用FutureTask对象上的get方法,尝试获取任务执行结果时,才能够看到异常信息被打印出来。
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
} private V report(int s) throws ExecutionException {
Object x = outcome;
if (s == NORMAL)
return (V)x;
if (s >= CANCELLED)
throw new CancellationException();
throw new ExecutionException((Throwable)x); // 异常会通过这一句被抛出来
}小结
通过
ThreadPoolExecutor的execute方法提交的任务,出现异常后,异常会在子线程中被抛出,并被JVM捕获,并调用子线程的dispatchUncaughtException方法,进行异常处理,若子线程没有任何特殊设置,则异常堆栈会被输出到System.err,即异常会被打印到控制台上。并且会从线程池中移除当前Worker,并另启一个新的Worker作为替代。通过
ThreadPoolExecutor的submit方法提交的任务,任务会先被包装成FutureTask对象,出现异常后,异常会被生吞,并暂存到FutureTask对象中,作为任务执行结果的一部分。异常信息不会被打印,该子线程也不会被线程池移除(因为异常在子线程中被吞了,没有抛出来)。在调用FutureTask上的get方法时(此时一般是在主线程中了),异常才会被抛出,触发主线程的异常处理,并输出到System.err
其他
其他的线程池场景
比如:
使用
ScheduledThreadPoolExecutor实现延迟任务或者定时任务(周期任务),分析过程也是类似。这里给个简单结论,当调用scheduleAtFixedRate方法执行一个周期任务时(任务会被包装成FutureTask(实际是ScheduledFutureTask,是FutureTask的子类)),若周期任务中出现异常,异常会被生吞,异常信息不会被打印,线程不会被回收,但是周期任务执行这一次后就不会继续执行了。ScheduledThreadPoolExecutor继承了ThreadPoolExecutor,所以其也是复用了ThreadPoolExecutor的那一套逻辑。使用
CompletableFuture的runAsync提交任务,底层是通过ForkJoinPool线程池进行执行,任务会被包装成AsyncRun,且会返回一个CompletableFuture给主线程。当任务出现异常时,处理方式和ThreadPoolExecutor的submit类似,异常堆栈不会被打印。只有在CompletableFuture上调用get方法尝试获取结果时,异常才会被打印。
以上がJava スレッドの例外処理メカニズムとは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。