
ホームページ >テクノロジー周辺機器 >AI >疎な特徴と密な特徴
疎な特徴と密な特徴

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-21 11:19:081855ブラウズ
機械学習では、特徴とは、物体、人、または現象の測定可能かつ定量化可能な属性または特性を指します。特徴は、疎な特徴と密な特徴の 2 つのカテゴリに大別できます。
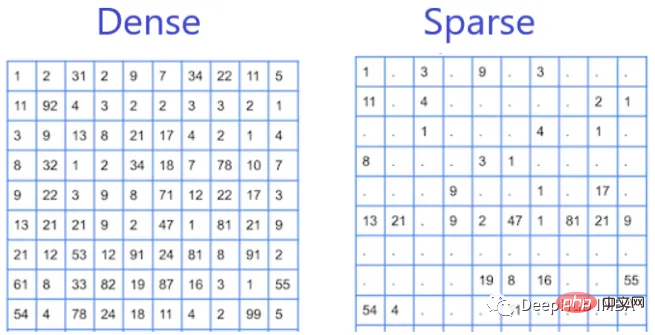
疎な特徴
疎な特徴とは、データ セット内に不連続に現れる特徴であり、その値のほとんどはゼロです。スパースな特徴の例には、テキスト ドキュメント内の特定の単語の有無や、トランザクション データセット内の特定のアイテムの出現などが含まれます。これらは、データセット内にゼロ以外の値がほとんどなく、ほとんどの値がゼロであるため、スパース特徴と呼ばれます。
スパース特徴は、自然言語処理 (NLP) およびレコメンダー システムで一般的であり、データはスパース行列として表現されることがよくあります。疎な特徴の操作は、多くの場合ゼロまたはゼロに近い値が含まれるため、より困難になる可能性があります。そのため、計算コストが高くなり、トレーニング プロセスが遅くなります。スパース特徴は、特徴空間が大きく、ほとんどの特徴が無関係または冗長である場合に効果的です。このような場合のスパース特徴はデータの次元を削減するのに役立ち、より高速かつ効率的なトレーニングと推論が可能になります。
高密度の特徴
高密度の特徴は、データ セット内に頻繁または定期的に出現する特徴であり、ほとんどの値はゼロ以外です。密な特徴の例には、人口統計データ セット内の個人の年齢、性別、収入などがあります。これらは、データセット内にゼロ以外の値が多数含まれるため、密な特徴と呼ばれます。
画像認識や音声認識では密な特徴が一般的であり、データは密なベクトルとして表されることがよくあります。密な特徴は、ゼロ以外の値の密度が高いため、一般に扱いやすく、ほとんどの機械学習アルゴリズムは密な特徴ベクトルを処理するように設計されています。特徴空間が比較的小さく、各特徴が当面のタスクにとって重要である場合には、密な特徴がより適している可能性があります。
違い
疎な特徴と密な特徴の違いは、データセット内での値の分布にあります。疎な特徴にはゼロ以外の値がほとんどありませんが、密な特徴にはゼロ以外の値が多くあります。疎な特徴と密な特徴ではアルゴリズムのパフォーマンスが異なる可能性があるため、この分布の違いは機械学習アルゴリズムに影響を与えます。
アルゴリズムの選択
特定のデータセットの特徴タイプがわかったので、データセットに疎な特徴が含まれている場合、またはデータセットに密な特徴が含まれている場合、どのアルゴリズムを使用する必要があるでしょうか。
一部のアルゴリズムは疎データに適していますが、他のアルゴリズムは密データに適しています。
- スパース データの場合、一般的なアルゴリズムには、ロジスティック回帰、サポート ベクター マシン (SVM)、デシジョン ツリーなどがあります。
- 高密度データの場合、一般的なアルゴリズムには、フィードフォワード ネットワークや畳み込みニューラル ネットワークなどのニューラル ネットワークが含まれます。
ただし、アルゴリズムの選択は、データの疎さや密度だけでなく、データセットのサイズ、特徴の種類、問題の複雑さなどにも依存することに注意してください。必ずさまざまなアルゴリズムを試して、特定の問題に対するパフォーマンスを比較してください。
以上が疎な特徴と密な特徴の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。