
ホームページ >バックエンド開発 >Python チュートリアル >Python Web クローラーの HTTP プロトコルの原理は何ですか?
Python Web クローラーの HTTP プロトコルの原理は何ですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-20 22:01:231952ブラウズ
HTTP の基本原則
この記事では、HTTP の基本原則を詳しく見て、ブラウザに URL を入力してから Web ページのコンテンツを取得するまでの間に何が起こるかを理解します。これらの内容を理解することで、クローラーの基本原理をさらに理解することができます。
URI と URL
ここでは、まず URI と URL について学びます。URI の完全名は、統一リソース識別子である、Uniform Resource Identifier です。URL の完全名は、Universal Resource Locator です。 、これは統合リソースロケーターです。
URL は URI のサブセットです。つまり、すべての URL が URI ですが、すべての URI が URL であるわけではありません。では、URL ではない URI とはどのようなものでしょうか? URI には、Universal Resource Name の略である URN と呼ばれるサブクラスも含まれています。 URN はリソースに名前を付けるだけで、リソースの検索方法は指定しません。たとえば、urn:isbn:0451450523 は書籍の ISBN を指定します。これにより書籍を一意に識別できますが、書籍の検索場所は指定されません。これが URN です。 URL、URN、URI の関係。
しかし、現在のインターネットでは URN はほとんど使用されていないため、ほとんどすべての URI は URL です。一般的な Web リンクは URL または URI と呼ばれます。私は個人的には URL と呼んでいます。
ハイパーテキスト
次に、もう 1 つの概念について学びましょう。ハイパーテキスト、英語名はハイパーテキストです。ブラウザで見る Web サイトです。
Web ページはハイパーテキストによって解析され、そのWeb ページのソース コードは一連の HTML コードであり、画像を表示する img や表示段落を指定する p などの一連のタグが含まれています。ブラウザがこれらのタグを解析すると、私たちが通常見る Web ページが形成されます。Web ページのソース コード HTML はハイパーテキストと呼ばれます。
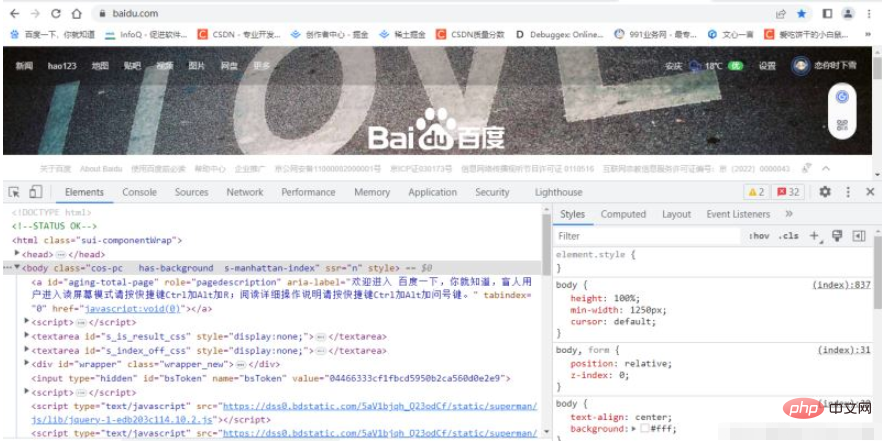
項目の「チェック」を選択します (またはショートカット キー F12 を直接押します)。開発者ツールを開きます。ブラウザの [要素] タブに現在の
Web ページのソース コードが表示されます。図に示すように、これらのソース コードはすべてハイパーテキストです。
チャネルです。簡単に言えば、HTTP の安全なバージョン、つまり SSL を追加したものです。 HTTP へのレイヤー。HTTPS と呼ばれます。
の 2 種類に分類できます。
- 情報セキュリティ チャネルを確立して、データ送信のセキュリティを確保します。
- Web サイトの信頼性を確認する HTTPS を使用する Web サイトでは、Web サイトが認証された後、ブラウザのアドレス バーにある鍵マークをクリックすると、実際の情報が表示されます。 CA に合格することもできます。代理店が発行したセキュリティ シールを確認してください。
HTTP リクエスト プロセス
- Apple はすべての ioS を義務付けています。すべてのアプリは 2017 年 1 月 1 日までに HTTPS 暗号化を使用する必要があります。そうしないと、アプリはアプリ ストアに掲載されません。
- 2017 年 1 月にリリースされた Chrome 56 以降、Google は HTTPS で暗号化されていない URL リンクに対するリスク警告を表示するようになりました。つまり、アドレスの目立つ位置にユーザーに通知するようになりました。 「この Web ページは許可されていません。安全性」というバー。
- Tencent WeChat ミニ プログラムの公式要件文書では、バックグラウンドでのネットワーク通信に HTTPS リクエストを使用することが求められており、条件を満たさないドメイン名やプロトコルはリクエストできません。
ブラウザに URL を入力し、Enter キーを押して、ブラウザのページ コンテンツでそれを確認します。実際、このプロセスは、ブラウザーが Web サイトが存在するサーバーにリクエストを送信し、リクエストを受信した後、Web サイトのサーバーがリクエストを処理および解析し、対応する応答を返し、それをブラウザーに返します。応答にはページのソース コードとその他のコンテンツが含まれており、ブラウザーはそれを解析して Web ページを表示します。 ここでのクライアントは私たち自身の PC またはモバイル ブラウザを表し、サーバーはアクセスする Web サイトが配置されているサーバーです。リクエストはクライアントからサーバーに送信され、リクエスト メソッド (リクエスト メソッド)、リクエストされた URLリクエスト
(リクエスト URL) の 4 つの部分に分けることができます。 、リクエストヘッダー、リクエスト本文。
一般的なリクエスト メソッドには GET と POST の 2 つがあります。
ブラウザに URL を直接入力し、Enter キーを押します。これにより GET リクエストが開始され、リクエスト パラメータが URL に直接含まれます。たとえば、Baidu での Python の検索は、https://www baidu. com/ というリンクを持つ GET リクエストです。URL にはリクエストのパラメータ情報が含まれています。ここでのパラメータ wd は、検索するキーワードを表します。 POST リクエストは、ほとんどの場合、フォームの送信時に開始されます。たとえば、ログイン フォームの場合、ユーザー名とパスワードを入力した後、[ログイン] ボタンをクリックすると通常 POST リクエストが開始され、データは通常フォームの形式で送信され、URL には反映されません。
GET リクエスト メソッドと POST リクエスト メソッドには次の違いがあります。
GET リクエストのパラメータは URL に含まれており、データを確認できます。 URL には、POST にはこれらのデータは含まれません。データはフォームを通じて送信され、リクエスト本文に含まれます。
GET リクエストによって送信されるデータは最大でも 1024 バイトのみですが、POST メソッドには制限がありません。
一般的に、ログインするときは、機密情報が含まれるユーザー名とパスワードを送信する必要があります。GET を使用してリクエストすると、パスワードが URL に公開され、問題が発生します。パスワード漏洩の可能性があるので、こちらからPOSTで送信するのがベストです。ファイルの内容が比較的大きいため、ファイルをアップロードする場合も POST メソッドが使用されます。
通常遭遇するリクエストのほとんどは GET または POST リクエストですが、GET、HEAD、
POST、PUT、DELETE、OPTIONS、CONNECT、TRACE などのリクエスト メソッドもいくつかあります。
- #リクエストされた URL
请求的网址,即统一资源定 位符URL,它可以唯一确定 我们想请求的资源。
- リクエスト ヘッダー
请求头,用来说明服务器要使用的附加信息,比较重要的信息有Cookie . Referer. User-Agent等。
- リクエスト本文
请求体一般承载的内容是 POST请求中的表单数据,而对于GET请求,请求体则为空。レスポンス
サーバーからクライアントに返されるレスポンスは、次の 3 つの部分に分けることができます。 レスポンス ステータス コード( 応答ステータス コード) 応答ヘッダーと応答本文。
- # レスポンスステータスコード
-
响应状态码表示服务器的响应状态,如200代表服务器正常响应,404代表页面未找到,500代表 服务器内部发生错误。在爬虫中,我们可以根据状态码来判断服务器响应状态,如状态码为200,则 证明成功返回数据,再进行进一步的处理, 否则直接忽略。
- レスポンスヘッダー
-
响应头包含了服务器对请求的应答信息,如Content-Type、Server、 Set-Cookie 等。
- 応答本文
-
##
最重要的当属响应体的内容了。响应的正文数据都在响应体中,比如请求网页时,它的响应体 就是网页的HTML代码;请求- -张图片时 ,它的响应体就是图片的二进制数据。我们做爬虫请 求网页后,要解析的内容就是响应体.
以上がPython Web クローラーの HTTP プロトコルの原理は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。