
ホームページ >Java >&#&チュートリアル >JavaのFileクラスとIOストリームの紹介と分析例
JavaのFileクラスとIOストリームの紹介と分析例

- 王林転載
- 2023-04-20 20:28:091087ブラウズ
IO ストリーム:
IO ストリームの概要:
IO : インプット/アウトプット (Input/Output)
#ストリーム: データ伝送の抽象的な概念および一般用語です。つまり、デバイス間のデータ伝送はストリームと呼ばれます。ストリームの本質はデータ伝送です。IO ストリームは、デバイス間のデータ伝送の問題に対処するために使用されます。一般的なアプリケーション: ファイルのコピー、ファイルのアップロード、ファイルのダウンロード、つまり、送信に関するすべてのことにストリームが関係します。
IO フロー システム図:
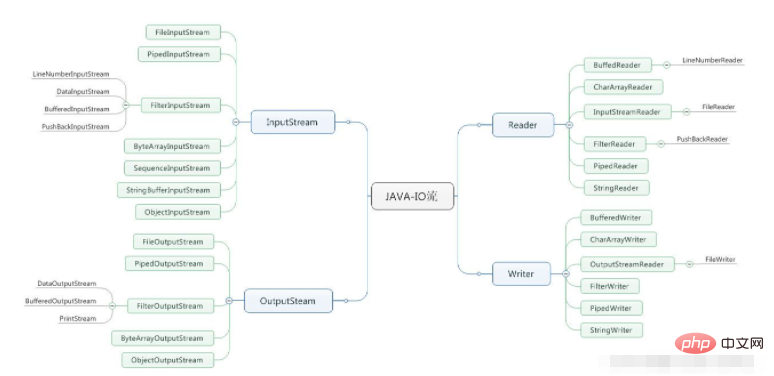
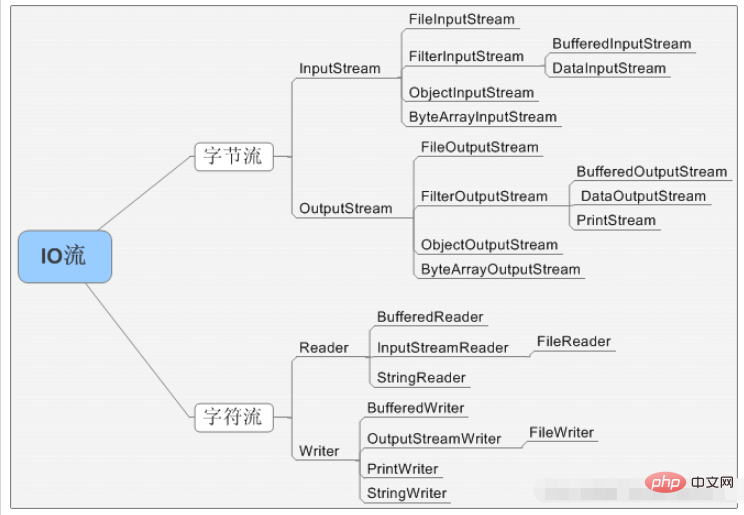 ##IO はファイルを含む操作であるため、ファイル操作のテクノロジと切り離せない必要があります:
##IO はファイルを含む操作であるため、ファイル操作のテクノロジと切り離せない必要があります:
File クラス:
File クラスは、ディスク ファイル自体を表す java.io パッケージ内の唯一のオブジェクトです。 File クラスは、ファイルを操作するためのいくつかのメソッドを定義します。主に、ファイル名、ファイル パス、アクセス許可、変更日などのディスク ファイルに関連する情報を取得または処理するために使用され、サブディレクトリ階層を参照することもできます。
File クラスは、ファイルおよびファイル システムの処理に関連する情報を表します。 File クラスには、ファイルから情報を読み取ったり、ファイルに情報を書き込む機能はなく、ファイル自体のプロパティを記述するだけです。したがって、読み取りおよび書き込み操作のために IO とペアになります。
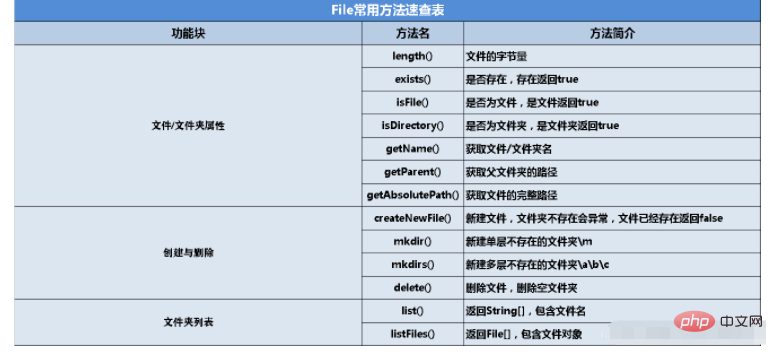
まず、File クラスの一般的に使用されるメソッドの概要図を見てみましょう。
public class test01 {
public static void main(String[] args) throws IOException {
//先建立一个File对象,并传入路径
File file1 = new File("G://abc.txt");
//创建空文件,如果没有存在则新建一个,并且返回True,如果存在了就返回false
System.out.println(file1.createNewFile());
}

File file2 = new File("G://a");
System.out.println(file2.mkdir());
//创建一个目录,如果没有存在则新建一个,并且返回True,如果存在了就返回false
File file3 = new File("G://a//b//c");
System.out.println(file3.mkdirs());
//创建多级目录,如果没有存在则新建一个,并且返回True,如果存在了就返回false

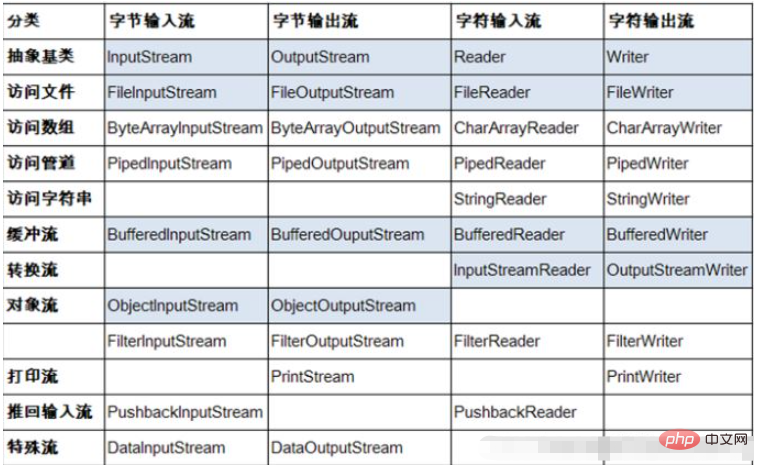
まず、一般的に使用される 4 つのストリームを紹介します:
- バイト入力ストリーム:
- InputStream
- OutputStream
- Reader
- Writer
ASCII コード
では、英語 1 文字 (大文字、小文字に関係なく) が 1 バイト、中国語 1 文字が 2 バイトとなります。
UTF-8 エンコードでは、英語の 1 単語は 1 バイト、中国語の 1 単語は 3 バイトになります。
Unicode エンコードでは、英語の 1 単語は 1 バイト、中国語の 1 単語は 2 バイトです。 つまり、コンピュータはデータを 1 つずつ読み取ることがわかりますが、ファイルに数字や英語が含まれている場合は、1 バイトを占有するため、正常に読み取ることができます。
では、それが漢字の場合はどうなるでしょうか?少なくとも2バイトを占めますので、漢字を分割して読むと必ず表示に問題が生じます。
概要:Windows に付属のメモ帳ソフトウェアでデータを開いて、内部のコンテンツを読み取ることができる場合は文字ストリームを使用し、それ以外の場合はバイト ストリームを使用します。どのタイプのストリームを使用すればよいかわからない場合は、バイト ストリームを使用してください。
以下は、4 つのストリームに対応するメソッド名の概要表です。
 バイト出力ストリーム:
バイト出力ストリーム:
public class test01 {
public static void main(String[] args) {
try{
//创建输出流对象:
OutputStream fos = null;
fos = new FileOutputStream("G://abc.txt");
String str = "今天的博客是IO流";
//先将需要写入的字符打散成数组:
byte[] words = str.getBytes();
//使用写入的功能
fos.write(words);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
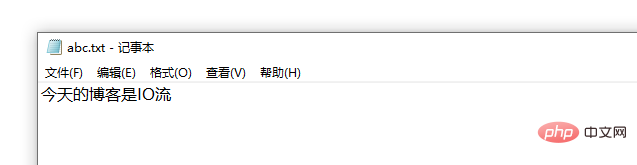 バイト入力ストリーム (ファイルからコンソールへの読み取り):
バイト入力ストリーム (ファイルからコンソールへの読み取り):
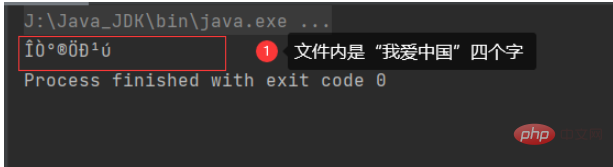
ファイルに中国語の文字が含まれており、バイト入力ストリームを使用すると、表示が確実に文字化けすることがわかっています。 「I love China」という 4 つの単語については、次のコードを使用します:
public class test02 {
public static void main(String[] args) {
//创建字节输入流对象:
InputStream fis = null;
try{
fis = new FileInputStream("G://abc.txt");
int data;
//fis.read()取到每一个字节通过Ascll码表转换成0-255之间的整数,没有值返回-1
while((data=fis.read())!=-1){
//(char) data 将读到的字节转成对应的字符
//中文的字符是2+个字节组成
System.out.print((char) data);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
try{
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}出力結果は次のとおりです:
 # #次に、ファイル内の情報を英語と数字に変更します。
# #次に、ファイル内の情報を英語と数字に変更します。
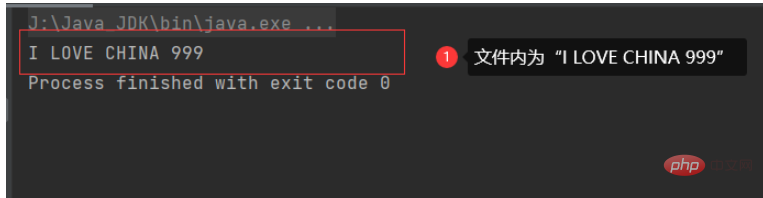 結論: 中国語の文字を含むファイルは、バイト ストリームを使用して読み取ることはできません
結論: 中国語の文字を含むファイルは、バイト ストリームを使用して読み取ることはできません
字符输出流:
我们使用字符输出流给abc.txt文件里面写几句话:
public class test03 {
public static void main(String[] args) {
try{
//使用字符输出流的FileWriter写入数据
Writer fw = new FileWriter("G://abc.txt");
fw.write("我们在学Java");
fw.write("一起加油");
fw.close(); //关闭资源
} catch (IOException e) {
e.printStackTrace();
}
}
}
也没用问题,我们发现,使用字符流写中文汉字更方便。
字符输入流:
可以设置缓存流提高获取值的效率:
public class test04 {
public static void main(String[] args) throws IOException {
//创建字符输入流对象:
Reader fr = null;
try{
fr = new FileReader("G:/abc.txt");
//借助字符流对象创建了字符缓存区 把字符一个一个的取到后先放到缓存区
//然后一起再读写到程序内存来,效率更高
BufferedReader br = new BufferedReader(fr);
//先去缓存区一行一行的读取
String line = br.readLine();
while(line != null){
System.out.println(line);
line = br.readLine();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
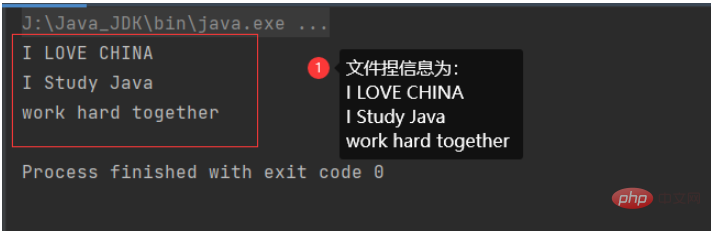
}当文件内的信息为多行的时候:
字节流和字符流总结:
IO是文件的输入和输出,我们要想去对文件或者写,或者通过程序发送消息给另外的用户都要用到流。
IO流分 字节流和字符流,字节流是以字节为单位IO,字符流是以字符为单位IO;通常读写图片、视频音频等用字节 流,如果读写文件的内容比如中文建议用字符流。
以上がJavaのFileクラスとIOストリームの紹介と分析例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。