
ホームページ >テクノロジー周辺機器 >AI >DeepMind の新しい研究: トランスフォーマーは人間の介入なしで自らを改善できる
DeepMind の新しい研究: トランスフォーマーは人間の介入なしで自らを改善できる

- 王林転載
- 2023-04-20 19:07:071242ブラウズ
現在、Transformers はシーケンス モデリング用の強力なニューラル ネットワーク アーキテクチャになっています。事前トレーニングされたトランスフォーマーの注目すべき特性は、キュー調整またはコンテキスト学習を通じて下流のタスクに適応する能力です。大規模なオフライン データセットで事前トレーニングした後、大規模トランスフォーマーはテキスト補完、言語理解、画像生成の下流タスクに効率的に一般化することが示されています。
最近の研究では、オフライン強化学習 (RL) を逐次予測問題として扱うことで、トランスフォーマーがオフライン データからポリシーを学習できることが示されました。 Chen et al. (2021) の研究では、トランスフォーマーが模倣学習を通じてオフライン RL データからシングルタスク ポリシーを学習できることが示され、その後の研究では、トランスフォーマーが同一ドメイン設定とクロスドメイン設定の両方でマルチタスク ポリシーを抽出できることが示されました。これらの研究はすべて、一般的なマルチタスク ポリシーを抽出するためのパラダイムを示しています。つまり、まず大規模で多様な環境相互作用データ セットを収集し、次に逐次モデリングを通じてデータからポリシーを抽出します。模倣学習を通じてオフライン RL データからポリシーを学習するこの方法は、オフライン ポリシー蒸留 (Offline Policy Distillation) またはポリシー蒸留 (Policy Distillation、PD) と呼ばれます。
PD はシンプルさとスケーラビリティを提供しますが、その大きな欠点の 1 つは、生成されたポリシーが環境との対話を追加しても徐々に改善されないことです。たとえば、Google のジェネラリスト エージェントである Multi-Game Decision Transformers は、多くの Atari ゲームをプレイできるリターン条件付きポリシーを学習しましたが、DeepMind のジェネラリスト エージェントである Gato は、コンテキスト タスク推論を通じてさまざまな問題の解決策を学習しました。残念ながら、どちらのエージェントも試行錯誤を通じて状況に応じてポリシーを改善することはできません。したがって、PD メソッドは強化学習アルゴリズムではなくポリシーを学習します。
最近の DeepMind の論文で、研究者らは、PD が試行錯誤によって改善できなかった理由は、トレーニングに使用されたデータが学習の進行状況を示すことができなかったためであると仮説を立てました。現在の方法は、学習を含まないデータ (例: 蒸留による固定エキスパート ポリシー) からポリシーを学習するか、学習を含むデータ (例: RL エージェントのリプレイ バッファ) からポリシーを学習しますが、後者のコンテキスト サイズ (小さすぎる) ポリシーの改善点を把握できません。

論文アドレス: https://arxiv.org/pdf/2210.14215.pdf ##研究者らの主な観察は、RL アルゴリズムのトレーニングにおける学習の逐次的な性質により、原理的には強化学習自体を因果系列予測問題としてモデル化できるということです。具体的には、トランスフォーマーのコンテキストが学習更新によってもたらされるポリシー改善を含めるのに十分な長さである場合、固定ポリシーを表すことができるだけでなく、状態に焦点を当ててポリシー改善アルゴリズムを表すこともできるはずです。 、前のエピソードのアクション、報酬。
これにより、任意の RL アルゴリズムを模倣学習を通じてトランスフォーマーなどの十分に強力なシーケンス モデルに蒸留でき、これらのモデルをコンテキスト RL アルゴリズムに変換できる可能性が開かれます。 研究者らは、RL アルゴリズム学習履歴における因果シーケンス予測損失を最適化することにより、コンテキスト戦略を学習するための改良された演算子であるアルゴリズム蒸留 (AD) を提案しました。以下の図 1 に示すように、AD は 2 つの部分で構成されます。まず、多数の個別タスクに関する RL アルゴリズムのトレーニング履歴を保存することによって、大規模なマルチタスク データセットが生成されます。次に、トランスフォーマー モデルが、以前の学習履歴をコンテキストとして使用してアクションを因果的にモデル化します。ポリシーはソース RL アルゴリズムのトレーニング中に改善され続けるため、AD はトレーニング履歴の任意の時点でのアクションを正確にモデル化するために、改善された演算子を学習する必要があります。重要なのは、トレーニング データの改善を捉えるために、トランスフォーマー コンテキストが十分に大きい (つまり、エピソード全体にわたって) 必要があることです。
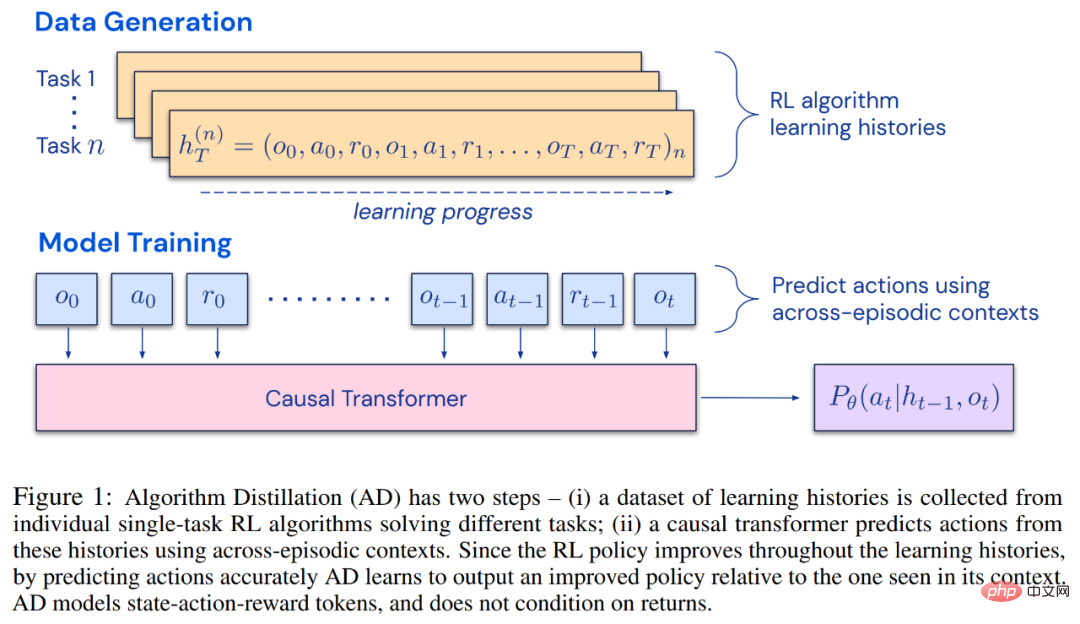 研究者らは、勾配ベースの RL アルゴリズムを模倣するのに十分な大きさのコンテキストを持つ因果変換器を使用することで、AD が新しいタスクを完全に強化できると述べました。文脈の中で勉強してください。私たちは、DMLab のピクセルベースの Watermaze など、探索を必要とする多くの部分的に観察可能な環境で AD を評価し、AD が文脈探索、時間的信頼度の割り当て、一般化が可能であることを示しました。さらに、AD によって学習されたアルゴリズムは、トランスフォーマーのトレーニング ソース データを生成したアルゴリズムよりも効率的です。
研究者らは、勾配ベースの RL アルゴリズムを模倣するのに十分な大きさのコンテキストを持つ因果変換器を使用することで、AD が新しいタスクを完全に強化できると述べました。文脈の中で勉強してください。私たちは、DMLab のピクセルベースの Watermaze など、探索を必要とする多くの部分的に観察可能な環境で AD を評価し、AD が文脈探索、時間的信頼度の割り当て、一般化が可能であることを示しました。さらに、AD によって学習されたアルゴリズムは、トランスフォーマーのトレーニング ソース データを生成したアルゴリズムよりも効率的です。
最後に、AD は、模倣損失を使用してオフライン データを順次モデル化することで、コンテキスト強化学習を実証する最初の手法であることは注目に値します。
強化学習エージェントは、その有効期間中、複雑なアクションを適切に実行する必要があります。知的エージェントの場合、その環境、内部構造、実行に関係なく、過去の経験に基づいて完成したものとみなすことができます。それは次の形式で表現できます:
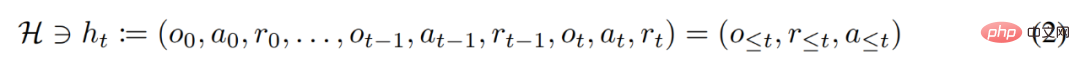
研究者はまた、「長い歴史に条件付けされた」戦略をアルゴリズムとみなして、次のように結論付けました。

として表します。学習履歴はアルゴリズム  で表されるため、特定のタスク
で表されるため、特定のタスク  生成されました。
生成されました。 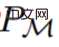
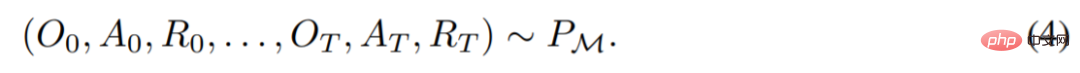 #研究者は、O、A、R などの確率変数を表すためにラテン語の大文字を使用し、それに対応する小文字の o、α を使用します。 、r 。彼らは、アルゴリズムを長期的な履歴条件付きポリシーとみなすことにより、学習履歴を生成するアルゴリズムは、アクションの行動複製を実行することによってニューラル ネットワークに変換できるという仮説を立てました。次に、この研究では、エージェントに行動クローンを使用したシーケンス モデルの生涯学習を提供し、長期履歴を行動分布にマッピングするアプローチを提案しています。
#研究者は、O、A、R などの確率変数を表すためにラテン語の大文字を使用し、それに対応する小文字の o、α を使用します。 、r 。彼らは、アルゴリズムを長期的な履歴条件付きポリシーとみなすことにより、学習履歴を生成するアルゴリズムは、アクションの行動複製を実行することによってニューラル ネットワークに変換できるという仮説を立てました。次に、この研究では、エージェントに行動クローンを使用したシーケンス モデルの生涯学習を提供し、長期履歴を行動分布にマッピングするアプローチを提案しています。
実際の実装
実際には、この研究ではアルゴリズム蒸留 (AD) を 2 段階のプロセスとして実装します。まず、多くの異なるタスクに対して個別の勾配ベースの RL アルゴリズムを実行することによって、学習履歴データセットが収集されます。次に、複数のエピソードのコンテキストを含むシーケンス モデルがトレーニングされ、歴史上のアクションが予測されます。具体的なアルゴリズムは次のとおりです。
実験
実験では、使用する環境が、からは取得できない多くのタスクをサポートしている必要があります。推論は観察から簡単に行うことができ、エピソードは十分に短いため、エピソード間の因果変換を効率的にトレーニングできます。この研究の主な目的は、以前の研究と比較して、AD 強化がコンテキスト内でどの程度学習されるかを調査することでした。実験ではAD、ED(Expert Distillation)、RL^2などを比較しました。
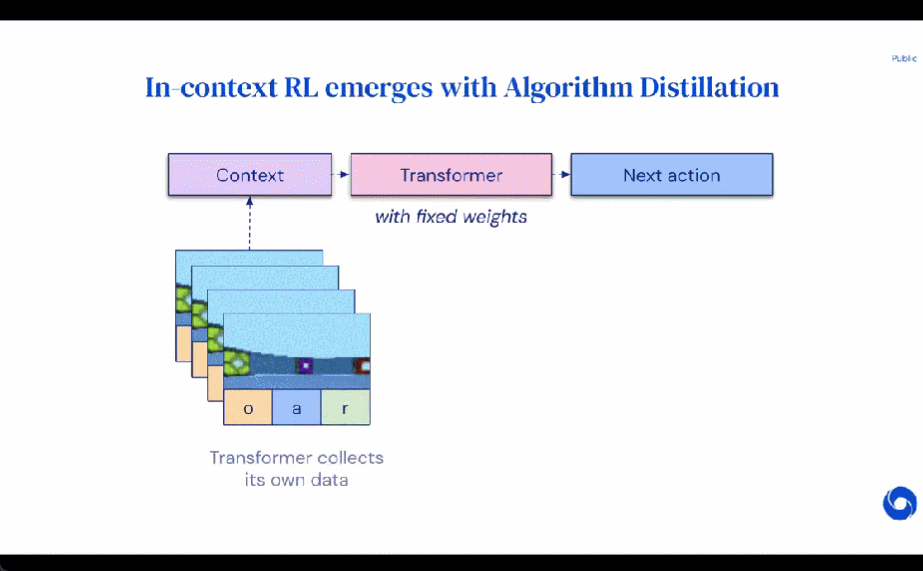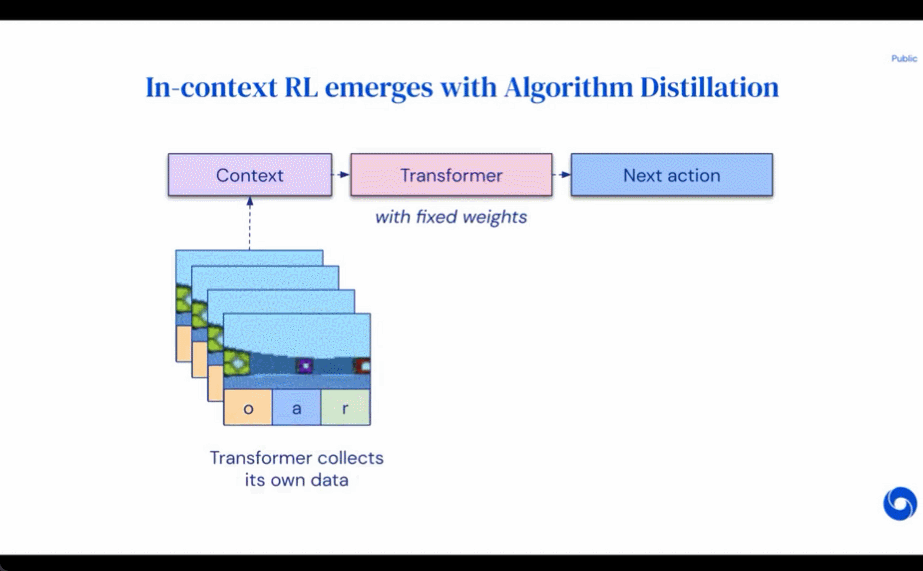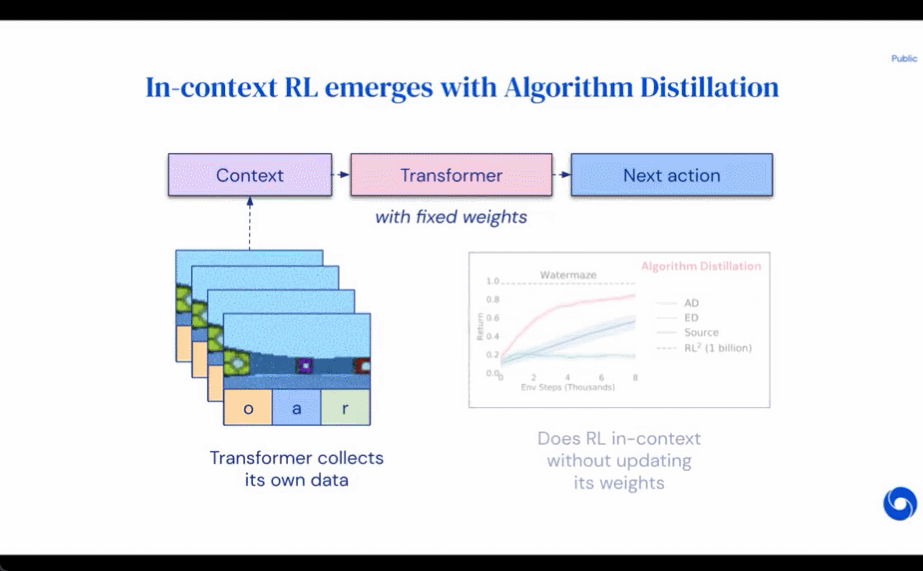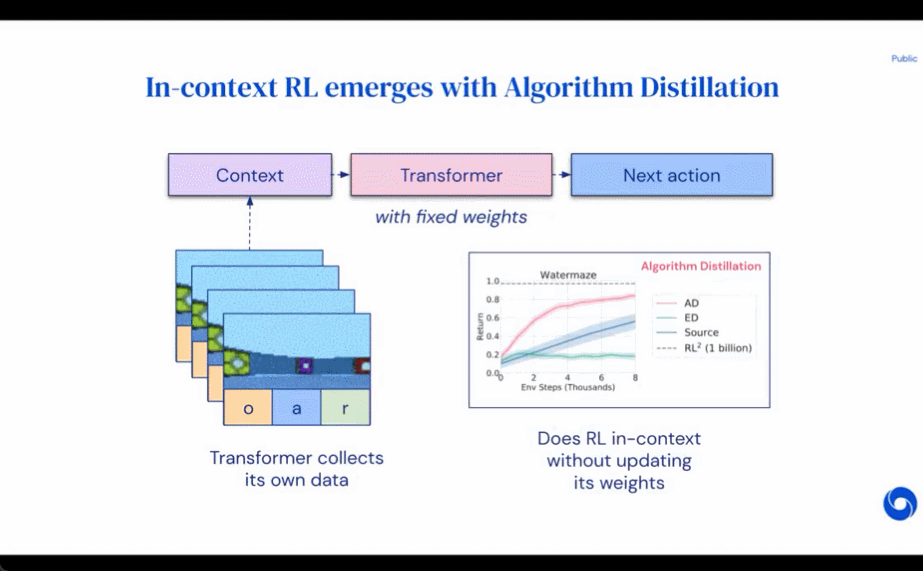
AD、ED、RL^2 の評価結果を図 3 に示します。この研究では、AD と RL^2 の両方が、トレーニング分布からサンプリングされたタスクに関して状況に応じて学習できるのに対し、ED は学習できないことがわかりました。ただし、分布内で評価される場合、ED はランダムな推測よりも優れています。
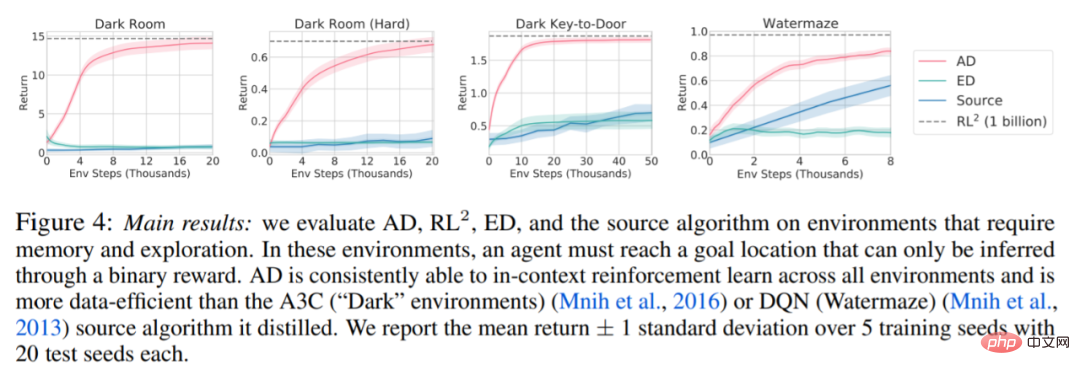
以下の図 4 に関して、研究者は一連の質問に答えました。 AD は文脈強化学習を示しますか?結果は、AD 文脈強化学習はあらゆる環境で学習できるのに対し、ED はほとんどの状況で文脈を探索して学習できないことを示しています。
#AD はピクセルベースの観察から学習できますか?結果は、AD が文脈依存 RL を介してエピソード回帰を最大化するのに対し、ED は学習に失敗することを示しています。
AD ソース データを生成したアルゴリズムよりも効率的な RL アルゴリズムを学習することは可能ですか?結果は、AD のデータ効率がソース アルゴリズム (A3C および DQN) よりも大幅に高いことを示しています。
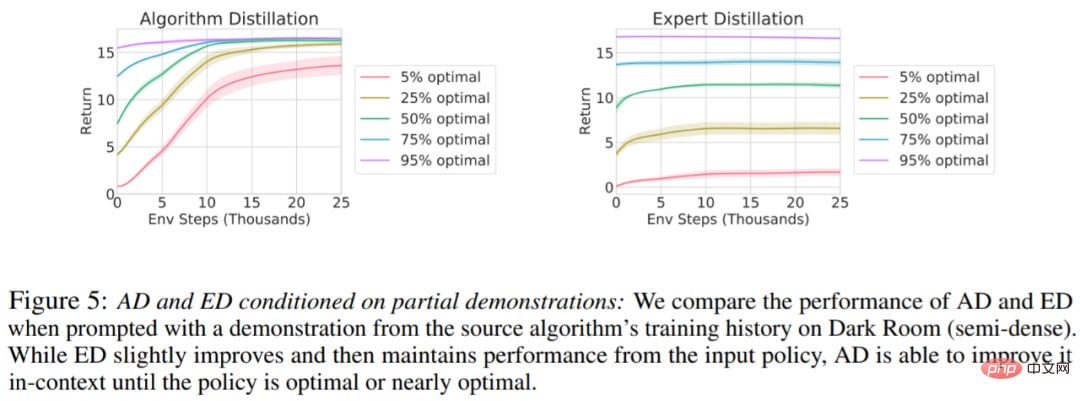
デモで AD を高速化することはできますか?この質問に答えるために、この調査では、ソース アルゴリズムの履歴に沿ったさまざまな時点でのサンプリング戦略をテスト セット データに保持し、この戦略データを使用して AD と ED のコンテキストを事前に設定し、両方のメソッドを実行します。暗室のコンテキストでの結果を図 5 にプロットします。 ED は入力ポリシーのパフォーマンスを維持しますが、AD は最適に近づくまでコンテキスト内の各ポリシーを改善します。重要なのは、入力戦略が最適化されるほど、AD は最適化に達するまで高速に改善されます。
詳細については、原論文を参照してください。
以上がDeepMind の新しい研究: トランスフォーマーは人間の介入なしで自らを改善できるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。