



文字列内の部分文字列
Java では String が不変であることは誰もが知っていますが、その内容を変更すると、新しい文字列が生成されます。文字列内のデータの一部を使用したい場合は、substring メソッドを使用できます。
以下はJava11におけるStringのソースコードです。
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = length() - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
if (beginIndex == 0) {
return this;
}
return isLatin1() ? StringLatin1.newString(value, beginIndex, subLen)
: StringUTF16.newString(value, beginIndex, subLen);
}
public static String newString(byte[] val, int index, int len) {
if (String.COMPACT_STRINGS) {
byte[] buf = compress(val, index, len);
if (buf != null) {
return new String(buf, LATIN1);
}
}
int last = index + len;
return new String(Arrays.copyOfRange(val, index << 1, last << 1), UTF16);
}上記のコードに示すように、部分文字列が必要な場合、substring はコンストラクターの Arrays.copyOfRange 関数を通じて構築される新しい文字列を生成します。
この関数は Java7 以降では問題ありませんが、Java6 ではメモリ リークの危険性があるため、このケースを検討して、ラージ オブジェクトの再利用によって発生する可能性のある問題を確認できます。 Java6 のコードは次のとおりです。
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > count) {
throw new StringIndexOutOfBoundsException(endIndex);
}
if (beginIndex > endIndex) {
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
}
return ((beginIndex == 0) && (endIndex == count)) ?
this :
new String(offset + beginIndex, endIndex - beginIndex, value);
}
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}ご覧のとおり、部分文字列を作成するとき、必要なオブジェクトをコピーするだけでなく、値全体を参照します。元の文字列が比較的大きい場合、使用されなくなってもメモリは解放されません。
たとえば、記事のコンテンツは数メガバイトになる可能性がありますが、必要なのは概要情報だけであり、大きなオブジェクト全体を維持する必要があります。
長年働いているインタビュアーの中には、部分文字列がまだ JDK6 にあるという印象を持っている人もいますが、実際には、Java はすでにこのバグを修正しています。面接中にこの質問に遭遇した場合は、念のため、改善プロセスに関する質問に答えてください。
これが意味するのは、比較的大きなオブジェクトを作成し、このオブジェクトに基づいて他の情報を生成する場合、この時点で、この大きなオブジェクトとの参照関係を忘れずに削除する必要があるということです。
大規模なコレクション オブジェクトの拡張
オブジェクトの拡張は、StringBuilder、StringBuffer、HashMap、ArrayList などの Java では一般的な現象です。要約すると、List、Set、Queue、Map などを含む Java コレクション内のデータは制御できません。容量が不足すると拡張操作が行われますが、拡張操作ではデータの再編成が必要となるため、スレッドセーフではありません。
まず StringBuilder の拡張コードを見てみましょう:
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}容量が足りない場合は、メモリを 2 倍にして Arrays.copyOf を使用してソース データをコピーします。
以下はHashMapの展開コードですが、展開後のサイズも2倍になります。拡張動作は非常に複雑で、負荷係数の影響に加えて、元のデータを再ハッシュする必要があり、ネイティブの Arrays.copy メソッドが使用できないため、速度が非常に遅くなります。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int) Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}List のコードは自分で確認できますが、ブロック化されており、拡張戦略は元の長さの 1.5 倍になります。
コレクションはコード内で非常に頻繁に使用されるため、特定のデータ項目の上限がわかっている場合は、適切な初期化サイズを設定するとよいでしょう。たとえば、HashMap には 1024 個の要素が必要で、7 個の拡張が必要なので、アプリケーションのパフォーマンスに影響します。この質問は面接で頻繁に聞かれるため、これらの拡張操作がパフォーマンスに与える影響を理解する必要があります。
ただし、負荷係数 (0.75) を持つ HashMap のようなコレクションの場合、初期サイズ = 必要な数/負荷係数 1 であることに注意してください。基礎となる構造がよくわからない場合は、次のようにすることもできます。まあデフォルトのままにしておきます。
次に、データの構造的次元と時間的次元からアプリケーションレベルでの最適化について説明します。
適切なオブジェクト粒度を維持する
実際の事例を共有しましょう。私たちは非常に高い同時実行性を備えたビジネス システムを持っており、ユーザーの基本データを頻繁に使用する必要があります。
下図に示すように、ユーザーの基本情報は別サービスに保存されているため、ユーザーの基本情報を利用するたびにネットワーク連携が必要になります。さらに受け入れがたいのは、ユーザーの性別属性だけが必要な場合でも、すべてのユーザー情報をクエリして取得する必要があることです。
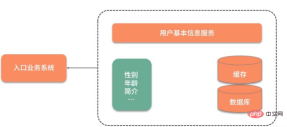
データ クエリを高速化するために、データは最初にキャッシュされて Redis に置かれました。クエリのパフォーマンスは大幅に向上しましたが、それでも毎回クエリを実行する必要があります。冗長なデータが大量にあります。
元の Redis キーは次のように設計されています:
type: string
key: user_${userid}
value: jsonこの設計には 2 つの問題があります:
特定のフィールドの値をクエリするには、すべてのフィールドをクエリする必要があります。 json データ 自分で解析してください;
フィールドの 1 つの値を更新するには、json 文字列全体を更新する必要があり、コストがかかります。
この種の大粒度の JSON 情報は、分散した方法で最適化できるため、すべての更新とクエリに焦点を絞ったターゲットが設定されます。
次に、Redis 内のデータは、json 構造の代わりにハッシュ構造を使用して次のように設計されています。
type: hash
key: user_${userid}
value: {sex:f, id:1223, age:23}このようにして、hget コマンドまたは hmget コマンドを使用して目的のデータを取得できます。情報の流れをスピードアップするために。
ビットマップはオブジェクトを小さくします
上記の操作に加えて、さらに最適化することはできますか?たとえば、ユーザーの性別データは、ギフトを配布したり、異性の友人を推薦したり、清掃活動を実行するためにユーザーを定期的に循環させたりするなど、ユーザーのステータス情報 (ユーザーのステータス情報 (ユーザーのステータス情報) を保存するために頻繁に使用されます)。オンラインかどうか、チェックインしたかどうか、最近情報が送信されたかどうかなどを確認して、アクティブ ユーザーをカウントします。次に、yes と no の 2 つの値の演算を Bitmap 構造を使用して圧縮できます。
这里还有个高频面试问题,那就是 Java 的 Boolean 占用的是多少位?
在 Java 虚拟机规范里,描述是:将 Boolean 类型映射成的是 1 和 0 两个数字,它占用的空间是和 int 相同的 32 位。即使有的虚拟机实现把 Boolean 映射到了 byte 类型上,它所占用的空间,对于大量的、有规律的 Boolean 值来说,也是太大了。
如代码所示,通过判断 int 中的每一位,它可以保存 32 个 Boolean 值!
int a= 0b0001_0001_1111_1101_1001_0001_1111_1101;
Bitmap 就是使用 Bit 进行记录的数据结构,里面存放的数据不是 0 就是 1。还记得我们在之前 《分布式缓存系统必须要解决的四大问题》中提到的缓存穿透吗?就可以使用 Bitmap 避免,Java 中的相关结构类,就是 java.util.BitSet,BitSet 底层是使用 long 数组实现的,所以它的最小容量是 64。
10 亿的 Boolean 值,只需要 128MB 的内存,下面既是一个占用了 256MB 的用户性别的判断逻辑,可以涵盖长度为 10 亿的 ID。
static BitSet missSet = new BitSet(010_000_000_000);
static BitSet sexSet = new BitSet(010_000_000_000);
String getSex(int userId) {
boolean notMiss = missSet.get(userId);
if (!notMiss) {
//lazy fetch
String lazySex = dao.getSex(userId);
missSet.set(userId, true);
sexSet.set(userId, "female".equals(lazySex));
}
return sexSet.get(userId) ? "female" : "male";
}这些数据,放在堆内内存中,还是过大了。幸运的是,Redis 也支持 Bitmap 结构,如果内存有压力,我们可以把这个结构放到 Redis 中,判断逻辑也是类似的。
再插一道面试算法题:给出一个 1GB 内存的机器,提供 60亿 int 数据,如何快速判断有哪些数据是重复的?
大家可以类比思考一下。Bitmap 是一个比较底层的结构,在它之上还有一个叫作布隆过滤器的结构(Bloom Filter),布隆过滤器可以判断一个值不存在,或者可能存在。
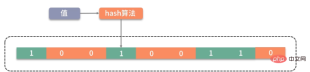
如图,它相比较 Bitmap,它多了一层 hash 算法。既然是 hash 算法,就会有冲突,所以有可能有多个值落在同一个 bit 上。它不像 HashMap一样,使用链表或者红黑树来处理冲突,而是直接将这个hash槽重复使用。从这个特性我们能够看出,布隆过滤器能够明确表示一个值不在集合中,但无法判断一个值确切的在集合中。
Guava 中有一个 BloomFilter 的类,可以方便地实现相关功能。
上面这种优化方式,本质上也是把大对象变成小对象的方式,在软件设计中有很多类似的思路。比如像一篇新发布的文章,频繁用到的是摘要数据,就不需要把整个文章内容都查询出来;用户的 feed 信息,也只需要保证可见信息的速度,而把完整信息存放在速度较慢的大型存储里。
数据的冷热分离
数据除了横向的结构纬度,还有一个纵向的时间维度,对时间维度的优化,最有效的方式就是冷热分离。
所谓热数据,就是靠近用户的,被频繁使用的数据;而冷数据是那些访问频率非常低,年代非常久远的数据。
同一句复杂的 SQL,运行在几千万的数据表上,和运行在几百万的数据表上,前者的效果肯定是很差的。所以,虽然你的系统刚开始上线时速度很快,但随着时间的推移,数据量的增加,就会渐渐变得很慢。
冷热分离是把数据分成两份,如下图,一般都会保持一份全量数据,用来做一些耗时的统计操作。

由于冷热分离在工作中经常遇到,所以面试官会频繁问到数据冷热分离的方案。下面简单介绍三种:
数据双写
把对冷热库的插入、更新、删除操作,全部放在一个统一的事务里面。由于热库(比如 MySQL)和冷库(比如 Hbase)的类型不同,这个事务大概率会是分布式事务。在项目初期,这种方式是可行的,但如果是改造一些遗留系统,分布式事务基本上是改不动的,我通常会把这种方案直接废弃掉。
写入 MQ 分发
通过 MQ 的发布订阅功能,在进行数据操作的时候,先不落库,而是发送到 MQ 中。单独启动消费进程,将 MQ 中的数据分别落到冷库、热库中。使用这种方式改造的业务,逻辑非常清晰,结构也比较优雅。像订单这种结构比较清晰、对顺序性要求较低的系统,就可以采用 MQ 分发的方式。但如果你的数据库实体量非常大,用这种方式就要考虑程序的复杂性了。
使用 Binlog 同步
针对 MySQL,就可以采用 Binlog 的方式进行同步,使用 Canal 组件,可持续获取最新的 Binlog 数据,结合 MQ,可以将数据同步到其他的数据源中。
思维发散
对于结果集的操作,我们可以再发散一下思维。可以将一个简单冗余的结果集,改造成复杂高效的数据结构。这个复杂的数据结构可以代理我们的请求,有效地转移耗时操作。
たとえば、一般的に使用されるデータベース インデックスは、データの再編成と高速化の一種です。 B ツリーは、データベースとディスク間のやり取りの数を効果的に削減でき、B ツリーと同様のデータ構造を通じて最も一般的に使用されるデータにインデックスを付け、限られた記憶領域に保存します。
RPC でよく使用されるシリアル化もあります。一部のサービスでは、XML ベースのプロトコルである SOAP プロトコル WebService を使用しますが、大規模なコンテンツの送信は遅く、非効率的です。現在の Web サービスのほとんどは対話に json データを使用しており、json は SOAP よりも効率的です。
また、Google の protobuf は誰もが聞いたことがあるはずですが、バイナリ プロトコルでデータを圧縮するため、パフォーマンスが非常に優れています。 protobuf がデータを圧縮すると、サイズは json の 1/10、xml の 1/20 にすぎませんが、パフォーマンスは 5 ~ 100 倍向上します。
protobuf の設計は学ぶ価値があり、tag|length|value の 3 つのセクションを通じて非常にコンパクトにデータを処理し、解析と送信速度が非常に高速です。
以上がJava で大きなオブジェクトを扱う方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 高度なJavaプロジェクト管理、自動化の構築、依存関係の解像度にMavenまたはGradleを使用するにはどうすればよいですか?Mar 17, 2025 pm 05:46 PM
高度なJavaプロジェクト管理、自動化の構築、依存関係の解像度にMavenまたはGradleを使用するにはどうすればよいですか?Mar 17, 2025 pm 05:46 PMこの記事では、Javaプロジェクト管理、自動化の構築、依存関係の解像度にMavenとGradleを使用して、アプローチと最適化戦略を比較して説明します。
 適切なバージョン化と依存関係管理を備えたカスタムJavaライブラリ(JARファイル)を作成および使用するにはどうすればよいですか?Mar 17, 2025 pm 05:45 PM
適切なバージョン化と依存関係管理を備えたカスタムJavaライブラリ(JARファイル)を作成および使用するにはどうすればよいですか?Mar 17, 2025 pm 05:45 PMこの記事では、MavenやGradleなどのツールを使用して、適切なバージョン化と依存関係管理を使用して、カスタムJavaライブラリ(JARファイル)の作成と使用について説明します。
 カフェインやグアバキャッシュなどのライブラリを使用して、Javaアプリケーションにマルチレベルキャッシュを実装するにはどうすればよいですか?Mar 17, 2025 pm 05:44 PM
カフェインやグアバキャッシュなどのライブラリを使用して、Javaアプリケーションにマルチレベルキャッシュを実装するにはどうすればよいですか?Mar 17, 2025 pm 05:44 PMこの記事では、カフェインとグアバキャッシュを使用してJavaでマルチレベルキャッシュを実装してアプリケーションのパフォーマンスを向上させています。セットアップ、統合、パフォーマンスの利点をカバーし、構成と立ち退きポリシー管理Best Pra
 キャッシュや怠zyなロードなどの高度な機能を備えたオブジェクトリレーショナルマッピングにJPA(Java Persistence API)を使用するにはどうすればよいですか?Mar 17, 2025 pm 05:43 PM
キャッシュや怠zyなロードなどの高度な機能を備えたオブジェクトリレーショナルマッピングにJPA(Java Persistence API)を使用するにはどうすればよいですか?Mar 17, 2025 pm 05:43 PMこの記事では、キャッシュや怠zyなロードなどの高度な機能を備えたオブジェクトリレーショナルマッピングにJPAを使用することについて説明します。潜在的な落とし穴を強調しながら、パフォーマンスを最適化するためのセットアップ、エンティティマッピング、およびベストプラクティスをカバーしています。[159文字]
 Javaのクラスロードメカニズムは、さまざまなクラスローダーやその委任モデルを含むどのように機能しますか?Mar 17, 2025 pm 05:35 PM
Javaのクラスロードメカニズムは、さまざまなクラスローダーやその委任モデルを含むどのように機能しますか?Mar 17, 2025 pm 05:35 PMJavaのクラスロードには、ブートストラップ、拡張機能、およびアプリケーションクラスローダーを備えた階層システムを使用して、クラスの読み込み、リンク、および初期化が含まれます。親の委任モデルは、コアクラスが最初にロードされ、カスタムクラスのLOAに影響を与えることを保証します


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

